GPT-5.1-Codex-Max 架构深度解析:原生“压缩”机制如何重塑智能体编程?
OpenAI最新发布的GPT-5.1-Codex-Max在AI编程领域实现重大突破,通过创新的"原生压缩(Compaction)"机制有效解决了Transformer架构的长上下文处理难题。该模型在SWE-Bench和Terminal-Bench基准测试中表现优异,分别以77.9%和58.1%的准确率领先竞品。其核心优势在于将AI从"副驾驶"升级为"自主工程师",能够维持24小时以上的持续编码状态
OpenAI最新发布的GPT-5.1-Codex-Max不仅是性能的提升,更是架构的革新。本文将深度剖析其核心的“原生压缩(Compaction)”机制,探讨其如何打破Transformer长上下文的 O(n2)O(n2) 算力诅咒,并结合SWE-Bench与Terminal-Bench基准测试数据,分析从“Copilot”到“Autonomous Engineer”的技术跨越。
1. 引言:从无状态补全到有状态工程
在过去的几年里,AI编程工具主要扮演“副驾”(Copilot)的角色,依赖于短时记忆和“一问一答”的无状态交互。然而,面对跨越数百万Token的代码重构或复杂的Bug调试,传统模型往往会因为上下文窗口溢出或“指令漂移”(Instruction Drift)而失效。
GPT-5.1-Codex-Max的发布,标志着智能体式编码(Agentic Coding)时代的正式到来。它不再仅仅是一个代码生成器,而是一个具备长时记忆、自主规划、工具使用能力的“自主工程师”。
2. 核心技术突破:原生“压缩”(Compaction)机制
这是该模型最令人兴奋的技术亮点。众所周知,标准Transformer架构的自注意力机制(Self-Attention)计算复杂度为:
Complexity=O(n2)Complexity=O(n2)
其中 nn 为序列长度。随着上下文窗口的扩大,计算成本呈指数级增长。以往的RAG或稀疏注意力机制并未从根本上解决模型在连续任务流中的状态维持问题。
GPT-5.1-Codex-Max 引入了原生的Compaction机制,其工作原理类似于操作系统的内存分页与交换,但更加智能化。
Compaction 流程图解(Mermaid):
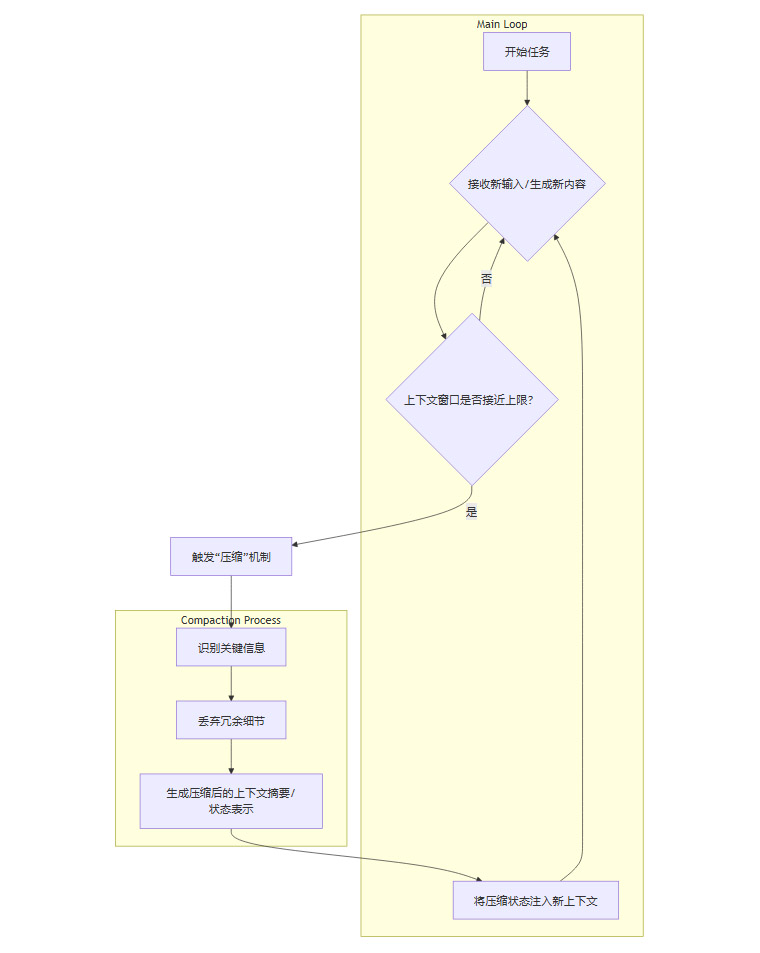
该机制带来的三大收益:
- 突破物理限制: 将看似无限的任务流切分为可管理的记忆片段,实现24小时+的持续运行。
- Token效率提升30%: 这种有损但保真的状态压缩,远比单纯的文本摘要更紧凑。
- 降低延迟: 始终维持在高效的上下文长度区间内运行。
3. 性能实证:硬核基准测试
在衡量真实软件工程能力的 SWE-Bench Verified 和系统交互能力的 Terminal-Bench 2.0 中,GPT-5.1-Codex-Max 均展现了统治力。
| 基准测试 | 测试维度 | GPT-5.1-Codex-Max | Gemini 3 Pro | 优势 |
|---|---|---|---|---|
| SWE-Bench Verified | 真实GitHub Issue解决能力 | 77.9% | 76.2% | +1.7% |
| Terminal-Bench 2.0 | 终端环境交互、Shell命令执行 | 58.1% | 54.2% | +3.9% |
数据解读:
- SWE-Bench 的领先意味着它在理解复杂代码库、定位Bug和编写通过测试的代码方面更接近人类高级工程师。
- Terminal-Bench 的大幅领先则证明了其作为“Agent”操作工具、读取日志、自我修正环境错误的能力。
4. 总结与展望
GPT-5.1-Codex-Max 的出现,意味着开发者可以将形如“重构整个支付模块”的高阶目标直接交付给AI,而无需手动拆解为几十个Prompt。这种端到端的交付能力,正是AI从工具走向伙伴的关键一步。
技术尝鲜通道
想要体验最新的智能体编程能力?
👉 API 对接指南 (小镜AI开放平台): https://open.xiaojingai.com/register?aff=xeu4

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献82条内容
已为社区贡献82条内容

所有评论(0)