解析CLIP:从“看标签”到“读描述”
本文介绍了OpenAI开发的CLIP模型如何突破传统计算机视觉的局限,实现"看图说话"的多模态AI能力。CLIP通过对比学习将4亿个互联网图文对映射到同一语义空间,使模型能理解图像语义并进行零样本学习。相比传统监督学习方法,CLIP具有无需标注、类别灵活、泛化能力强等优势,在30多个视觉任务中表现优异。这项技术革新表明,语言可作为强大的监督信号,大数据+大模型是实现AI进步的关
当AI学会“看图说话”
想象一下,如果你给一个从未见过“博美犬”的人看一张照片,并告诉他:“这是一只毛茸茸的小型犬,耳朵尖尖的,看起来像狐狸。”他很可能下次就能认出博美犬。这种通过语言描述来学习视觉概念的能力,对人类来说很自然,但对机器来说却长期是个难题。
传统的计算机视觉系统就像是一个只会背诵标签的学生:你给它看过一万张标着“猫”的图片,它才能认出猫。但如果你问它“这是什么动物?”,它却无法理解这个问题。直到2021年,OpenAI发布了CLIP(Contrastive Language–Image Pre-training)模型,才真正让机器学会了“看图说话”,也开启了多模态AI的新篇章。
一、背景知识:计算机视觉的“监督困境”
在CLIP出现之前,主流的计算机视觉模型(如ResNet、EfficientNet等)大多依赖有监督学习,尤其是在ImageNet这样的数据集上预训练。ImageNet包含1000个类别,每张图片都有一个“黄金标签”。这种方法的局限性非常明显:
-
类别固定:模型只能识别训练时见过的类别,新增类别需要重新标注和训练。
-
标注成本高:高质量标注需要大量人力,且容易出错。
-
缺乏语义理解:模型知道这是“猫”,但不知道猫“可爱”“毛茸茸”“会抓老鼠”。
与此同时,自然语言处理领域却因为无监督预训练(如BERT、GPT)而突飞猛进。这些模型从海量文本中学习语言规律,无需人工标注,就能完成翻译、问答、写作等任务。那么问题来了:计算机视觉能否也走同样的路?
CLIP模型:

二、为什么会做CLIP?——动机与愿景
CLIP的诞生,源自一个朴素而大胆的想法:如果能用互联网上无穷无尽的“图片-描述”对来训练模型,是否就能让机器像人一样,通过语言理解图像?
此前已有一些尝试(如Visual N-Grams、VirTex等),但效果远不及有监督模型。主要瓶颈在于:
-
数据规模不够大
-
训练效率低
-
模型表达能力有限
CLIP团队敏锐地意识到,如果能把对比学习(Contrastive Learning)和大规模多模态数据结合起来,或许能突破这个瓶颈。他们的目标不是做一个更好的分类器,而是做一个能理解图像语义、并能用语言交互的通用视觉系统。
三、CLIP是什么?——对比学习与多模态嵌入
CLIP是一个预训练模型,就像BERT、GPT、ViT等预训练模型一样。首先使用大量无标签数据训练这些模型,然后训练好得模型就能实现,输入一段文本(或者一张图像),输出文本(图像)的向量表示。
CLIP和BERT,GPT,ViT的区别在于,CLIP是多模态的,包含图像处理以及文本处理两个方面的内容,而BERT,GPT是单模态的,VIT是单模态图像的。
CLIP的核心思想非常简单:拉近匹配的图文对,推开不匹配的图文对。
具体来说,CLIP同时训练两个编码器:
-
图像编码器:可以是ResNet或Vision Transformer(ViT)
-
文本编码器:使用Transformer结构
训练时,模型会看到一批(图像,文本)对。它的任务不是预测文本内容,而是判断哪个文本与哪个图像是一对。通过对比学习,模型学会将相关的图像和文本映射到嵌入空间中相近的位置。
四、CLIP如何帮助我们?——零样本学习与强大泛化
CLIP最令人惊艳的能力是零样本学习:你不需要给它任何训练样本,只需要用文字描述任务,它就能尝试完成。
例如:
-
你想让它识别“新冠病毒的电子显微镜图像”,只需输入这个描述。
-
你想让它判断“这张图片是否适合儿童观看”,它也能尝试回答。
在实际测试中,CLIP在超过30个数据集上表现优异,包括:
-
图像分类(ImageNet、CIFAR)
-
场景识别(SUN397)
-
动作识别(Kinetics700)
-
OCR(手写数字、场景文本)
-
地理定位(根据图片猜测拍摄国家)
更值得一提的是,CLIP在分布外泛化方面表现突出。传统模型在训练集和测试集分布不一致时性能大幅下降,而CLIP因为训练数据来自开放的互联网,见过更多样的图像,因此更稳健。
五、CLIP怎么做?——技术细节与工程实践
1. 数据集:WIT(WebImageText)
CLIP使用了自建的4亿个图文对数据集,来源包括网页、社交媒体、图库等。这是其成功的关键之一。
2. 高效的对比学习目标
CLIP采用InfoNCE损失,鼓励模型为真实配对赋予高相似度,为随机配对赋予低相似度。这种方式比生成式目标(如预测字幕)更高效。
3. 提示工程(Prompt Engineering)
CLIP团队发现,直接使用类别名(如“狗”)效果不如使用完整句子(如“一张狗的照片”)。他们为不同任务设计了提示模板,进一步提升零样本性能。
4. 可扩展的架构
CLIP支持多种骨干网络,并且模型性能随计算量和数据量增长而稳定提升,符合“缩放定律”。
CLIP 在零样本传输方面比我们的图像标题基线要高效得多,如下图所示:
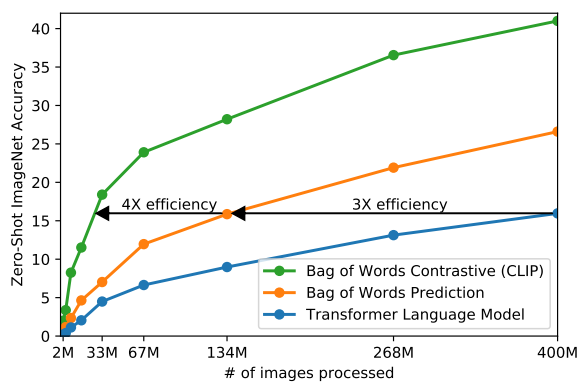
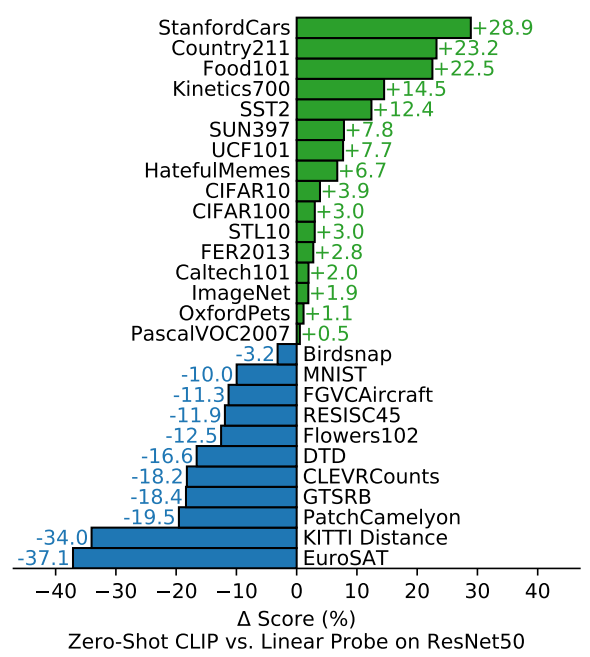
零样本 CLIP 与完全监督的基线相比具有竞争力。在 27 个数据集评估套件中,零样本 CLIP 分类器的性能优于安装在 16 个数据集上的 ResNet-50 特征上的完全监督线性分类器。如下图所示:
可视化香蕉的分布变化,该类在 7 个自然分布变化数据集中的 5 个数据集中共享。将最佳零样本 CLIP 模型 的性能与在 ImageNet 验证集 ResNet-101 上具有相同性能的模型进行了比较。如下图所示:

六、意义与启示:迈向通用多模态AI
CLIP不仅是技术上的突破,更是方法论上的革新。它告诉我们:
-
语言是强大的监督信号:无需人工标注,自然语言本身就能指导视觉学习。
-
规模是关键:大数据+大模型+大计算,是当前AI进步的主要驱动力。
-
零样本学习是可行的:模型可以通过语义理解泛化到新任务,而不是死记硬背。
当然,CLIP也有局限性:
-
对抽象、逻辑任务(如计数)表现欠佳
-
仍存在数据偏见和社会伦理问题
-
计算成本高昂
但这些并不妨碍它成为AI多模态理解的一个重要里程碑。
结语:当视觉与语言相遇
CLIP的出现,让我们离“通用人工智能”更近了一步。一个既能看懂世界,又能用语言描述世界的模型,不仅是技术工具,更是未来人机交互、内容理解、知识检索的基础设施。
正如论文作者所说:
“我们展示了从自然语言监督中学习可迁移视觉模型的可能性。”
而这,只是一个开始。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)