AAAI 2026 Oral 精选:无需训练缓解大模型幻觉,多模态地图生成颠覆传统方案!
AAAI人工智能会议(AAAI Conference on Artificial Intelligence)是人工智能领域的重要国际会议,是CCF-A类推荐会议。AAAI2026将于2026年1月20日-27日在新加坡举办。今年共有23680篇论文投稿,最终4167篇论文接收,录用率17.6%。目前部分论文已公开,小编精选十几篇CV方向论文,希望对大家有所帮助,有需要自取即可。
AAAI人工智能会议(AAAI Conference on Artificial Intelligence)是人工智能领域的重要国际会议,是CCF-A类推荐会议。AAAI2026将于2026年1月20日-27日在新加坡举办。今年共有23680篇论文投稿,最终4167篇论文接收,录用率17.6%。
目前部分论文已公开,小编精选十几篇CV方向论文,希望对大家有所帮助,有需要自取即可。

【论文1】UniMapGen: A Generative Framework for Large-Scale Map Construction from Multi-modal Data(AAAI2026:Oral)
关键词:Large-scale Map Construction, Multi-modal Data, Generative Framework, Discrete Sequence Representation
1.研究方法
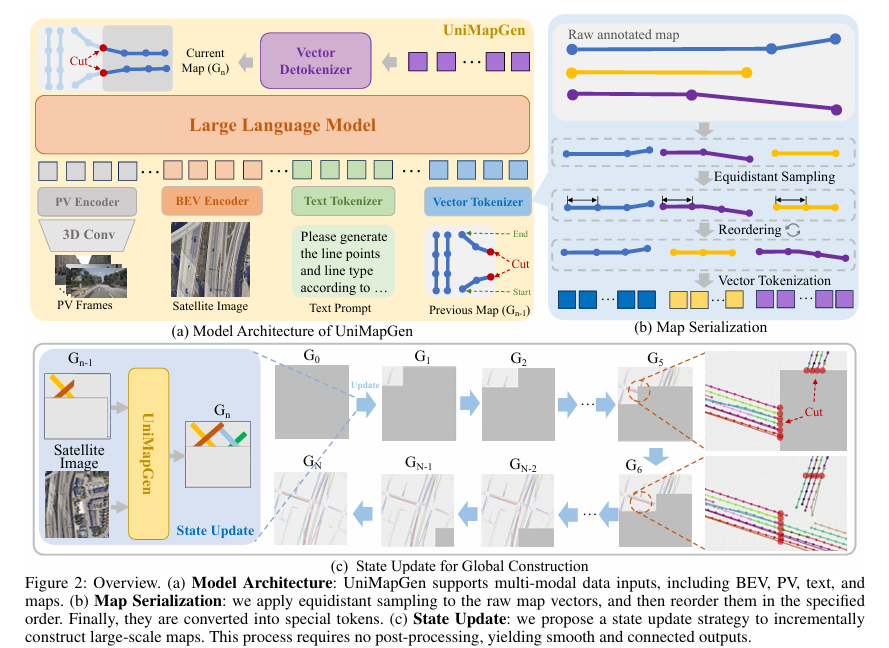
本文提出一种面向大规模地图构建的新型生成式框架 UniMapGen,核心创新包括将车道线转化为离散序列表征并设计迭代生成策略,相较于传统基于感知的方法可输出更完整、平滑的地图向量;构建支持多模态输入的灵活架构,能动态融合鸟瞰图(BEV)、透视视图(PV)与文本提示等输入形式,有效弥补卫星数据存在的遮挡、过时等固有缺陷;提出针对性的状态更新策略,通过迭代复用前一状态的地图上下文,保障大规模地图的全局连续性与一致性。实验表明,UniMapGen 在 OpenSatMap 数据集上实现当前最优性能,且具备强大的推理能力,能够精准推断被遮挡道路,并补全数据集中标注缺失的道路信息。
2.论文创新点
- 提出离散序列化表征与迭代生成策略:将车道线转化为离散序列,通过迭代生成模式输出更完整、平滑的地图向量,突破传统基于感知方法的向量生成局限。
- 设计多模态灵活融合架构:支持动态融合鸟瞰图(BEV)、透视视图(PV)与文本提示等输入,针对性解决卫星数据遮挡、过时等固有缺陷。
- 提出状态更新策略保障全局一致性:通过迭代复用前一状态地图上下文,实现大规模地图的全局连续性与一致性,避免传统 patch 处理导致的断裂问题。
- 具备强推理与补全能力:可精准推断被遮挡道路,补全数据集中标注缺失的道路信息,在 OpenSatMap 数据集上达成当前最优性能。
论文链接:https://arxiv.org/pdf/2509.22262
代码链接:https://github.com/Yujianyuan/unimapgen.github.io
【论文2】Causal Tracing of Object Representations in Large Vision Language Models: Mechanistic Interpretability and Hallucination Mitigation(AAAI2026:Oral)
关键词:Large Vision-Language Models (LVLMs), Mechanistic Interpretability, Hallucination Mitigation, Fine-grained Cross-modal Causal Tracing (FCCT), Intermediate Representation Injection (IRI), Multi-head Self-Attention
1.研究方法
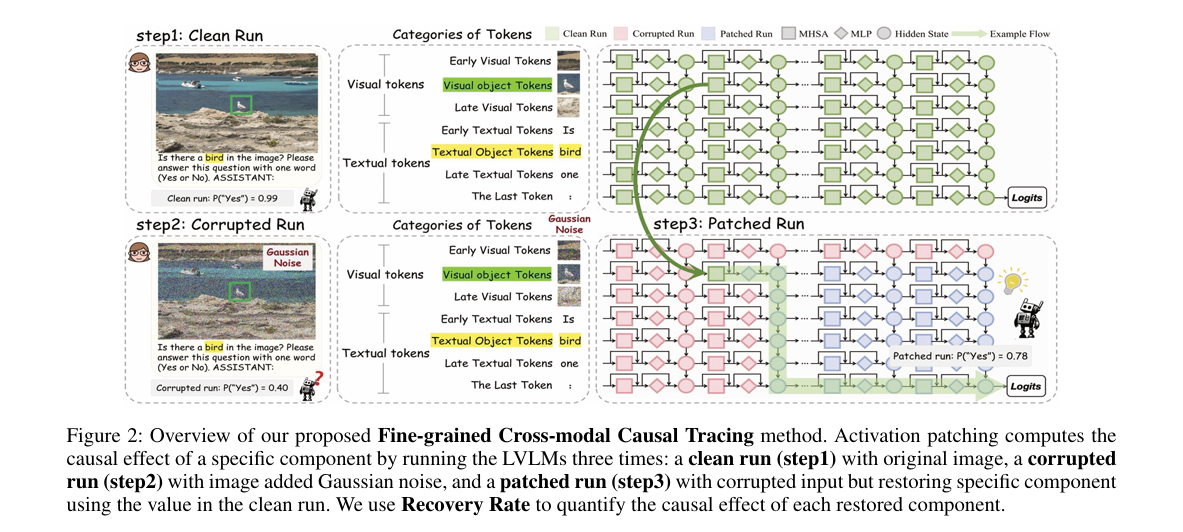
研究团队提出细粒度跨模态因果追踪(FCCT)框架,系统量化视觉对象感知的因果效应,涵盖视觉与文本标记、多头自注意力(MHSA)等三大核心模型组件及所有解码器层。该框架首次揭示,中间层最后一个标记的 MHSA 在跨模态信息聚合中起关键作用,前馈网络(FFNs)则呈现三阶段层级演进特征。基于此,团队提出无训练推理时技术 —— 中间表示注入(IRI),通过在特定组件和层精准干预跨模态表示,强化视觉对象信息流。在五个主流基准测试和多款 LVLMs 上的实验表明,IRI 在保持推理速度和基础性能的同时,有效提升了模型感知能力并减轻幻觉问题,达到当前最优性能。
2.论文创新点
- 提出细粒度跨模态因果追踪(FCCT)框架,首次全面覆盖视觉与文本标记、MHSA/FFNs/隐藏状态三大核心组件及所有解码器层,系统量化视觉对象感知的因果效应,填补现有LVLMs机制可解释性分析不全面的空白。
- 借助FCCT首次揭示LVLMs关键机制:中间层最后一个标记的MHSA在跨模态信息聚合中起核心作用,FFNs对视觉对象表示的存储与传递呈现三阶段层级演进特征。
- 基于FCCT的发现,提出无训练推理时技术——中间表示注入(IRI),通过在特定组件和层精准干预并按因果效应(恢复率)自适应调整跨模态表示,强化视觉对象信息流。
- IRI在五大主流基准测试及多款LVLMs上验证有效,既实现幻觉缓解的当前最优性能,又保持推理速度与模型基础能力,且具备模型无关性与良好泛化性。
论文链接:https://arxiv.org/pdf/2511.05923

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 23
23 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)