测试稳定性在DevOps中的核心意义
摘要:本文探讨DevOps测试环节中熔断、降级与自愈三大稳定性保障机制。熔断通过智能断路器预防测试雪崩,降级确保核心测试流程持续运行,自愈实现自动化问题恢复。文章详细解析了各机制的原理与实践场景,包括工具链选择、关键参数配置和团队协作要点,并强调三者的协同作用能构建韧性测试体系。随着混沌工程与AI技术的融合,测试稳定性保障将向"预测性自愈"阶段演进,推动测试人员向质量工程师转型
在快速迭代的DevOps环境中,测试环节的稳定性直接决定交付质量和团队效率。频繁的构建失败、环境波动或依赖服务异常可能导致测试阻塞,进而拖延发布周期。熔断、降级与自愈机制通过动态干预和自动化响应,为测试流程构建起一道“安全网”,本文将系统解析这三类机制的原理、实践场景与落地策略。
一、熔断机制:预防测试雪崩的智能断路器
1.1 核心概念与测试场景映射
熔断机制源自微服务架构的Circuit Breaker模式,其核心是通过监控关键指标(如失败率、超时比例)主动切断异常链路的调用。在测试领域中,典型的应用场景包括:
-
依赖服务不可用:当被测系统依赖的第三方API持续超时,熔断器自动暂停相关测试用例执行,避免资源浪费和虚假失败。
-
环境资源过载:例如测试数据库响应缓慢时,熔断可暂停数据密集型测试,防止整体测试套件因局部问题而崩溃。
1.2 实践落地要点
Core要点:工具链包含Hystrix、Resilience4j;关键参数定义策略不容马虎:
-
阈值配置:如连续失败次数≥5次或错误率>40%时触发熔断。
-
半开状态试验:熔断后定期尝试少量请求,若恢复则自动闭合。
某电商团队在商品搜索测试中引入熔断后,因依赖的搜索引擎不稳定导致的阻塞时间减少70%。
二、降级机制:保障核心测试流程的弹性策略
2.1 从“全面检测”到“重点保障”
降级机制指在系统压力或异常情况下,暂时关闭非核心功能测试,确保核心业务流程的验证持续进行。例如:
-
性能测试降级:当负载生成器资源不足时,优先执行关键接口的压力测试,跳过边缘场景。
-
兼容性测试降级:在发布窗口紧张时,暂缓老旧浏览器版本覆盖,聚焦主流环境。
2.2 实施路径与权衡原则
(数据支撑可参照下图示意):
xychart-beta title “测试降级策略效果对比” x-axis [“全量测试”, “降级模式”] y-axis “通过率(%)” 0 --> 100 bar [62, 89] line [65, 88]
需重点把控:
-
用例分级:根据业务影响划分P0(核心流程)、P1(重要功能)、P2(边缘场景)。
-
开关标准化:通过特性开关(Feature Toggles)动态控制测试套件的执行范围。
三、自愈机制:自动化恢复测试链路的未来方向
3.1 从被动处理到主动愈合
自愈机制通过AIOps、智能监控和自动化脚本实现问题的检测、诊断与恢复。在测试环节的具体体现包括:
-
环境自愈:自动检测测试环境脏数据/配置漂移,触发环境重置流程。
-
** flaky测试处理**:对间歇性失败的测试用例自动标记、隔离并重新验证。
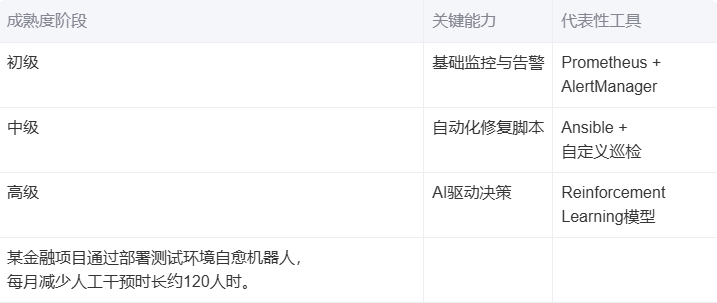
3.2 技术栈与成熟度演进
四、综合实践:三大机制的协同设计
4.1 链路闭环构建
-
监控 → 熔断 → 降级 → 自愈 形成连贯响应链:
-
监控系统检测到测试依赖服务异常(如响应时间>2s)
-
熔断器切断对该服务的调用,标记关联测试为“跳过”
-
降级策略启动,仅执行不依赖该服务的P0用例
-
自愈脚本尝试重启服务或切换备用节点,恢复后自动重试失败用例
-
4.2 团队协作与文化适配
-
测试左移:在用例设计阶段明确熔断/降级边界条件
-
运维右移:与SRE团队共同制定自愈剧本的验收标准
结语:走向韧性测试体系
熔断、降级与自愈机制共同构成了DevOps测试稳定性的“铁三角”。它们的价值不仅在于技术实现,更在于推动测试人员从用例执行者向质量工程师的转型——通过预设弹性策略,在面对不可避免的异常时,仍能保障交付流水线的顺畅流动。未来,随着混沌工程与AI技术的深度集成,测试稳定性保障将进一步提升至“预测性自愈”的新阶段。
精选文章

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)