门槛回归理论知识与软件操作教程,门槛回归分析结果解读
门槛回归是一种捕捉变量间关系随门槛变量变化而改变的统计方法。该方法通过识别门槛值(如单一门槛5.772),将数据划分为不同区间(门槛变量≤5.772和>5.772),分析核心解释变量对因变量的差异化影响。研究表明,当门槛变量超过5.772时,核心变量对Y的正向影响更强(系数1.503 vs 0.646)。分析时需先检验门槛效应显著性(p<0.05),再比较不同门槛模型(通过RSS、AI
门槛回归(Threshold Regression)是一种用于分析变量间关系在不同条件下发生变化的统计方法,其也称作门槛模型或者门限回归等。它能够识别出当某个变量(门槛变量)达到特定值(门槛值)时,变量间的关系会发生结构性改变。在现实生活中,很多现象都存在"门槛效应"。比如:
- 当温度低于0℃时,水会结冰,物理性质发生突变
- 当收入超过某个水平时,消费行为会发生改变
- 当经济增长率低于某个阈值时,各种经济政策的效果可能不同
传统线性回归假设变量间关系是固定不变的,而门槛回归则能捕捉到这种结构性变化,提供更准确的分析结果。门槛回归模型时,其涉及几个变量名词,分别下述:
|
名称 |
说明 |
|---|---|
|
因变量 |
也称被解释变量,即被影响的变量 |
|
自变量 |
也称解释变量,在门槛回归时也可能称为控制变量,即会影响到因变量的项 |
|
门槛变量 |
将其数据寻找出几个不同的‘门槛值’,然后对其可划分为不同区间研究‘核心解释变量’对于Y的影响,并在不同区间时影响情况的差别 |
|
核心解释变量 |
其也是自变量(解释变量),其对因变量Y的影响时,会因为门槛变量取值不同时,影响幅度可能不同有些研究中‘核心解释变量’就是‘门槛变量’ |
|
个体id和时间 |
面板数据时需要设置,让SPSSAU认识数据是面板数据如果不是面板数据则不需要设置SPSSAU支持面板和非面板两种数据进行门槛回归分析 |
|
门槛类型 |
SPSSAU提供单一门槛/双重门槛/三重门槛单一门槛时:有一个门槛值,将门槛变量划分为2个区间;双重门槛时:有2个门槛值,将门槛变量划分为3个区间;三重门槛时:有3个门槛值,将门槛变量划分为4个区间; |
|
网格搜索 |
其用于遍历寻找最优门槛值,该参数值越大越精细但运行越慢 |
|
Bootstrap次数 |
其用于自主抽样寻找门槛值的95%置信区间 |
1 背景
当前有一份面板数据(30*6=180),其中有3个控制变量即x1,x2和x3,门槛变量为threshold_var,核心解释变量为cor_var,因变量Y。
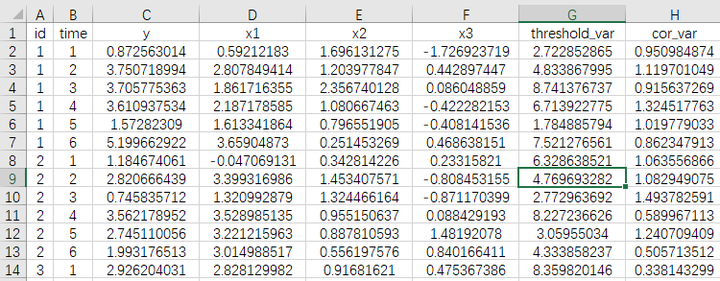
提示:
-
有时候核心解释变量就是门槛变量,此时整理数据时可直接复制一列即可;
-
控制变量可有可无,具体似研究而定
-
是否面板数据均可使用SPSSAU完成门槛模型
2 理论
门槛回归模型时,以基础的单一门槛模型为例(双门槛/三门槛完全类似),其数学模型如下: Y = β1 * X * I(Q ≤ γ) + β2 * X * I(Q > γ) + ε
上式中,Y即因变量(被解释变量),X为核心解释变量,Q为门槛变量,γ为门槛值,I(Q ≤ γ)表示门槛变量小于等于门槛值(如果小于等于则为1否则为0),I(Q > γ) 表示门槛变量大于门槛值(如果大于则为1否则为0),β1和β2为回归系数,ε为残差项。
当然实际中还有其它的自变量(也或者称控制变量)纳入模型中,并且可能考虑面板数据等,会有更多数学符号来标识,但其实质数学原理即为上述。
比如β1的回归系数大于0且呈现出显著性,则意味着‘小于等于门槛值前提时’,核心变量对于Y产生显著的正向影响;类似地如果β2的回归系数大于0且呈现出显著性,则意味着‘大于门槛值前提时’,核心变量对于Y产生显著的正向影响。
提示:分析上,首先应该关注于是否找到显著的门槛值,即应该使用单一/双门槛/三门槛,也或者不适用于门槛模型;接着再进一步分析;
分析上,有可能找到门槛值后,将门槛变量按门槛值划分为几组,并且使用新的变量来标识(可通过SPSSAU的数据编码功能完成),然后再进一步使用比如分组回归,也或者筛选出某个区间后进行分析,以进一步探讨稳健性等。
3 操作
本案例操作截图和说明分别如下:
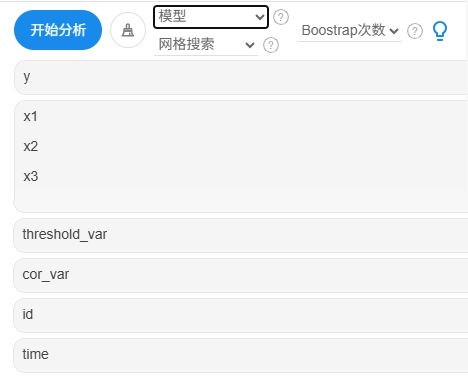
自变量X框可放入多项,如果实际研究中并没有则不放入。门槛变量需要放入,核心解释变量为1项,当前数据是面板格式,因而放入id和time到对应框中。
关于‘模型’:SPSSAU默认是进行‘单一门槛’,当然也可直接选择‘双重门槛’或‘三重门槛’; 从分析角度上看,通常首先判断是否有‘单一门槛’,如果有再进一步使用‘双重门槛’或者‘三重门槛’; 如果没有‘单一门槛’则通常意味着没有门槛效应。
关于‘网格搜索’和‘Bootstrap次数’:‘网格搜索’是用于算法遍历查找最优门槛值时的参数值,其意义并不大,但该参数值越大时,遍历会越精细化,通常默认就好,SPSSAU会自动判断网络搜索次数,并且在输出结果中展示该参数的具体值; 关于‘Bootstrap次数’,其是进行门槛值的置信区间时使用,通常默认即可。
4 SPSSAU输出结果
SPSSAU中进行门槛回归时,其共输出7个表格,分别说明如下:
|
项 |
名称 |
说明 |
|---|---|---|
|
1 |
门槛模型基本信息 |
基本参数情况说明等,包括风格搜索次数,Bootstrap抽样次数等信息 |
|
2 |
门槛估计值 |
核心结果表格,其展示计算得到的门槛值及其Bootstrap 95%置信区间 |
|
3 |
门槛模型检验 |
核心结果表格,其展示门槛值是否通过检验 |
|
4 |
门槛模型比较 |
如果进行多项门槛回归,并且需要对比模型优劣找出最佳门槛值时使用 |
|
5 |
门槛模型结果 |
门槛模型回归结果 |
|
6 |
门槛模型结果-简化格式 |
门槛模型结果的简化表格格式 |
|
7 |
样本缺失情况汇总 |
展示分析数据是否有缺失等 |
提示:
通常分析上,首先查看‘门槛模型检验’,用于判断模型是否有着‘门槛效应’,只有模型有着门槛效应后才能进一步分析,否则应该使用普通回归模型比如OLS回归等。
如果分析目的是多次对比各种门槛模型,那应该更多关于‘门槛模型比较’这个表格,其用于展示模型质量指标,包括RSS、MSE、R方、AIC和BIC等,RSS和MSE均为越小越好,R方一般越大越好,AIC和BIC这两个指标用于对比不同模型的优劣,该两个指标均为数值越小,模型越优,以及该两个指标相对更倾向于选择更简约的模型。
5文字分析

上表格展示门槛回归分析时的各项参数信息。网格搜索次数时,SPSSAU自动结合样本量信息等设置最优搜索次数,通常情况下200或300次较多;Bootstrap抽样次数时,SPSSAU自动结合样本量信息等设置最佳次数,通常情况下200或300次较多。
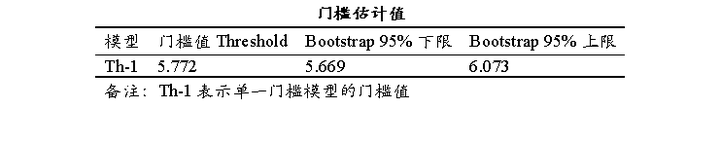
上表格展示门槛估计值结果及其Bootstrap自抽样置信区间;门槛值是结合门槛变量和网格搜索得到的估计值,其是模型中用于划分不同机制或状态的临界点;单一门槛模型时只会有1个门槛值(Th-1);双重门槛模型时会额外新出2个门槛值(Th-21和Th-22);三重门槛模型时会额外新出1个门槛值(Th-3);Bootstrap自抽样置信区间描述门槛值估计的不确定性范围,如果该置信区间范围越小(越窄)意味着该门槛值越精准,反之则意味着该门槛值越不稳定。
上表格展示出本案例时得到的门槛值为5.772,但该门槛值是否有意义,还需要查阅‘门槛模型检验’表格。
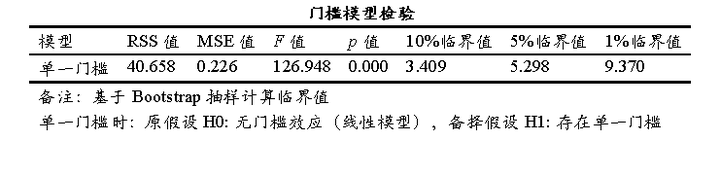
上表格展示门槛模型进行检验,提供假设检验结果及相关指标等;RSS值(Residual Sum of Squares,残差平方和),其用于衡量模型拟合优度,该值越小,表示模型的拟合效果越好,其可用于比较不同模型的拟合效果,RSS 较小的模型通常更优; MSE值(Mean Squared Error,均方误差),其为 RSS 值除以自由度计算得到,其进一步量化了模型预测值与实际值之间的平均差异,MSE 值越小,表示模型的预测精度越高;F值和p值,其用于检验模型的整体显著性,通常情况下p值小于0.05,则意味着该模型有意义;另外临界值也可用于在不同显著性水平下判断模型显著性的标准。
从上表可知,单一门槛回归模型呈现出0.001水平的显著性,意味着单一门槛模型构建具有有效性,也即说明门槛值为5.772具有统计意义,因此可按5.772分为两组,分别是门槛变量<5.772和门槛变量>=5.772。

上表格展示模型选择和质量评估,通过多个统计指标比较不同复杂度门槛模型的拟合效果;RSS (残差平方和)表示模型无法解释的变异部分,RSS = Σ(实际值 - 预测值)^2,该值越小,模型拟合越好,该指标随门槛数量增加通常递减(更复杂模型拟合更好);MSE (均方误差)表示平均预测误差,MSE = RSS/自由度,该值是衡量模型预测精度的标准化指标,该值越小,预测越准确,该指标消除了样本量影响,便于比较;
R方表示模型解释变异的比例,该值越大,模型解释力越强,需要注意复杂模型R方通常更高,但可能过拟合;AIC 和BIC 这两个指标用于对比不同模型的优劣,该两个指标均为数值越小,模型越优,以及该两个指标相对更倾向于选择更简约的模型。
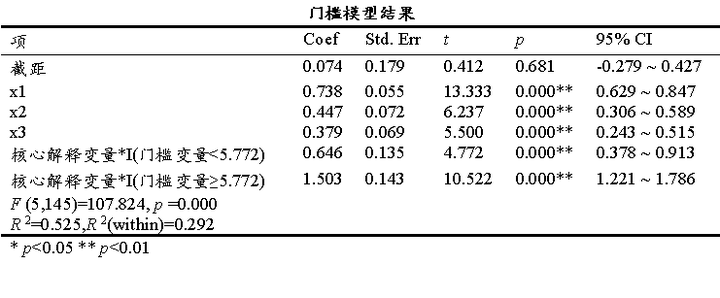
上展示门槛回归模型的估计结果,反映了不同门槛区间下变量的影响效应;门槛回归结果能够揭示传统线性模型无法捕捉的非线性关系,为政策制定和理论发展提供更精确的实证依据,表格中模型截距项通常无意义,自变量回归系数(若有)表示其对因变量的直接影响情况;
核心解释变量*I(门槛变量<5.772)表示门槛变量小于5.772时的情况,表格中显示其回归系数为0.646并且呈现出0.01水平的显著性,意味着核心解释变量在门槛变量小于5.772时,其会对Y产生显著的正向影响关系。
类似地,核心解释变量*I(门槛变量≥5.772) 表示门槛变量大于等于于5.772时的情况,表格中显示其回归系数为1.503并且呈现出0.01水平的显著性,意味着核心解释变量在门槛变量大于等于5.772时,其会对Y产生显著的正向影响关系。对比来看可以看出,门槛变量在更大的区间时,核心解释变量对于Y的影响幅度会更大,其回归系数均呈现出0.01水平的显著性,但其回归系数值会更大,即影响幅度更高。
6 剖析
涉及以下几个关键点,分别如下:
门槛模型应该设置那种? 门槛回归时建议先从‘单一门槛’开始,如果存在单一门槛,那么接着‘双重门槛’,再接着‘三重门槛’,但这并无固定标准,实际判断是否有门槛效应,应该是检验指标为准。
核心解释变量和门槛变量可以相同吗? 门槛回归研究时,有时核心解释变量就是门槛变量,这是正常的,上传数据时多复制一列完全相同的即可。
得到门槛值有什么意义? 门槛值得到后,可对数据分组(比如使用SPSSAU中数据处理里面的数据编码之范围编码),将数据分为不同组别,然后再进一步使用其它研究方法,比如分组回归;也或者可以考虑稳健性检验时,筛选出不同组别时进行某一分析,然后合并不同筛选且分析得到的结果,来对比结论的稳健性等。
SPSSAU中门槛回归的算法原理?
SPSSAU参考文献和Stata包xtthres完成算法,并且进行校检一致性,需要提示的是由于有网格搜索和Bootstrap抽样这两项,以及网格搜索的精度和边界判断等细节的不一致,结果会有小许gap,其是在基于完全相同算法前提时也一定会发生的正常现象。
Hansen, B. E. (1999). Threshold effects in non-dynamic panels: Estimation, testing, and inference. *Journal of Econometrics*, 93(2), 345-368.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献142条内容
已为社区贡献142条内容

所有评论(0)