【昇腾CANN训练营·工具篇】波形之美:使用System Profiling进行板级总线与功耗分析
摘要:2025年昇腾CANN训练营第二季提供全场景算子开发课程,助力开发者技能提升。本期重点介绍SystemProfiling技术,通过硬件级性能分析突破算子优化瓶颈。文章详解如何采集NPU硬件指标(HBM带宽、频率功耗等),并指导解读波形数据诊断内存、算力等瓶颈。结合Roofline模型分析,帮助开发者从系统架构视角优化性能,实现从代码逻辑到硬件物理的思维跃迁。该技术是AI系统调优的关键技能,为
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

前言
在算子优化达到一定瓶颈后,我们往往会发现代码改无可改。这时候,视线必须从“代码逻辑”转向“硬件物理”。
-
算力墙 (Compute Wall):AI Core 频率是否跑满?
-
内存墙 (Memory Wall):HBM 带宽是否饱和?
-
功耗墙 (Power Wall):芯片是否因为过热而触发了热保护(Throttling)?
普通的 MSProf Timeline 只能告诉你“什么时间在跑什么算子”,但无法告诉你“跑的时候硬件状态如何”。System Profiling 就是为了回答这个问题而生的。它像一个心电图机,实时记录 NPU 的脉搏。
本期文章将教你如何采集和解读这些波形,找出系统级的性能瓶颈。
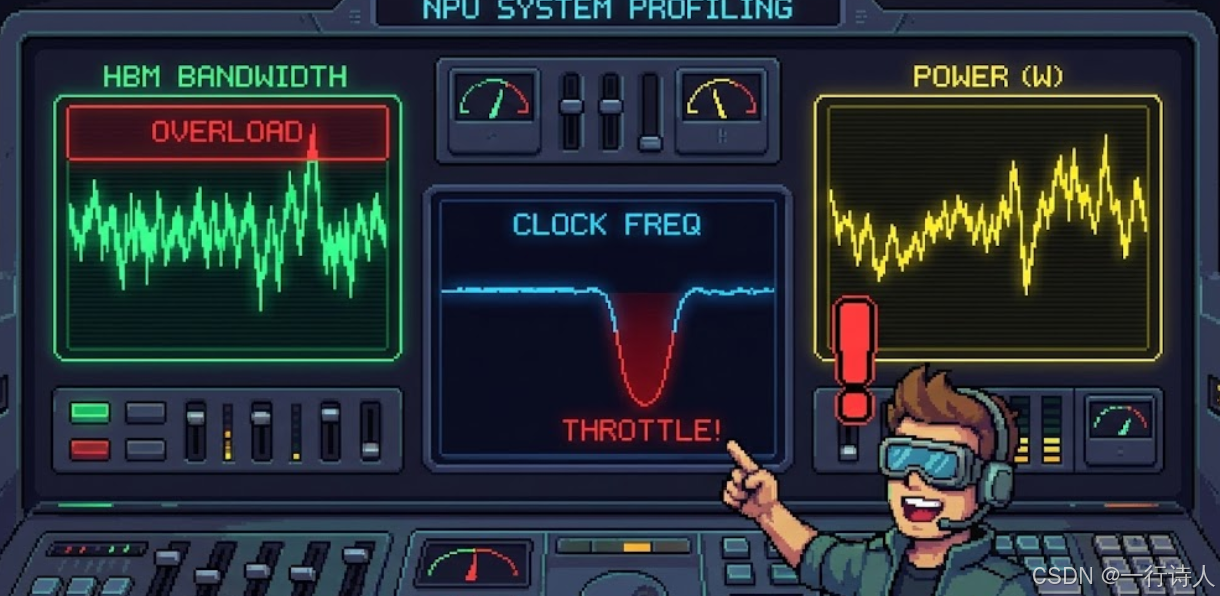
一、 核心图解:给 NPU 做“心电图”
代码 Profiling 关注的是逻辑流,System Profiling 关注的是物理流。
二、 采集实战:开启全知之眼
System Profiling 依然使用 msprof 工具,但参数完全不同。它不需要插桩代码,而是基于硬件计数器(PMU)进行采样。
2.1 采集命令
我们需要使用 --sys-hardware-mem (内存带宽) 和 --sys-cpu-profiling (CPU利用率) 等开关。
# 启动系统级采集
# -d: 指定设备 ID
# --sys-hardware-mem=on: 采集存储系统带宽 (HBM/DDR)
# --sys-cpu-profiling=on: 采集 Host/Device CPU 利用率
# --sys-io-profiling=on: 采集 NIC/RoCE 网络带宽 (多卡训练必备)
msprof --output=./sys_prof_data \
--sys-hardware-mem=on \
--sys-cpu-profiling=on \
--application="./my_inference_app"
采集完成后,会生成一系列 CSV 文件,建议导入 MindStudio 或使用 Excel/Python 进行可视化。
三、 波形解读:读懂硬件的“求救信号”
拿着生成的波形图,我们该看什么?
3.1 HBM 带宽利用率 (Memory Bandwidth)
这是最关键的指标。
-
现象:波形一直顶在 100%(或接近理论峰值,如 910B 的 1.x TB/s)。
-
诊断:Memory Bound。
-
此时优化 Vector/Cube 指令基本无效。
-
对策:必须减少 IO。使用算子融合(Fusion),或者启用 FlashAttention 这种 IO-Aware 算法。
-
-
现象:带宽利用率很低,但算子耗时很长。
-
诊断:Latency Bound(延迟瓶颈)或 Random Access(随机访存)。
-
说明数据搬运极其细碎(Gather/Scatter),没有形成突发传输(Burst)。
-
对策:参考第二十四期,进行数据重排或 Padding。
-
3.2 频率与功耗 (Frequency & Power)
-
现象:AI Core 频率波形突然出现“断崖式”下跌,几秒后恢复。
-
诊断:Thermal Throttling (热节流)。
-
算子功耗太高,或者散热环境不好,导致芯片过热保护。
-
对策:检查机房散热,或者优化算子逻辑,避免长时间高密度的无效计算。
-
3.3 AI CPU vs AI Core 抢占
-
现象:AI Core 利用率波形出现规律性的“凹槽”,而此时 AI CPU 利用率波形升高。
-
诊断:调度阻塞。
-
说明模型中混入了 AI CPU 算子(如 NMS),阻塞了 AI Core 的流水线。
-
对策:参考第三十期,尝试将 AI CPU 算子迁移到 AI Core,或实现异步流水线。
-
四、 进阶:Roofline Model (屋顶线模型) 分析
将 System Profiling 的带宽数据 ($BW$) 和算子 Profiling 的计算量 ($FLOPs$) 结合,我们可以绘制 Roofline Model。
$$ \text{Arithmetic Intensity (AI)} = \frac{\text{FLOPs}}{\text{Bytes}} $$ $$ \text{Performance} = \min(\text{Peak GFLOPS}, \text{Peak BW} \times \text{AI}) $$
-
如果你的算子落在屋顶的斜坡部分:受限于带宽,请优化访存。
-
如果你的算子落在屋顶的平顶部分:受限于算力,请优化指令并行或 Tiling。
Ascend C 的工具链通常会自动生成这个图,帮助你一目了然地定位瓶颈。
五、 总结
System Profiling 是从“软件工程师”进阶到“系统架构师”的必修课。
-
宏观视野:不要只盯着代码行,要盯着总线和电压。
-
瓶颈转移:优化往往是按下的葫芦浮起瓢。解决了算力瓶颈,带宽就成了瓶颈;解决了带宽,散热可能成问题。
-
数据说话:波形不会撒谎。
掌握了这一招,你就拥有了对 AI 系统的“全知视角”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)