2025年智能问答系统演进:从关键词匹配到语义理解的跨越
对于技术团队而言,现在正是布局智能问答系统的黄金窗口期。建议从垂直场景切入,逐步构建企业的知识中枢。像PandaWiki这类开源工具,已经大幅降低了技术落地的门槛,使更多组织能够享受到AI带来的效率革命。在信息爆炸的2025年,智能问答系统已经成为企业服务、技术支持和知识管理的标配基础设施。本文将带你深入解析智能问答系统的技术演进、核心能力与行业实践。其采用的"检索+生成"混合架构,在保证回答质量
·
在信息爆炸的2025年,智能问答系统已经成为企业服务、技术支持和知识管理的标配基础设施。但你是否真正了解现代问答系统的技术内核?本文将带你深入解析智能问答系统的技术演进、核心能力与行业实践。
一、智能问答系统的三次技术革命
1.0时代:关键词匹配(2010-2018)
- 代表技术:正则表达式、布尔检索
- 典型问题:"Python安装报错"只能匹配包含完整关键词的文档
- 局限性:无法处理同义词、错别字、语义关联
2.0时代:机器学习(2018-2023)
- 代表技术:BERT、TF-IDF
- 重大突破:理解"怎么装Python"和"Python安装教程"是同类问题
- 现存问题:需要大量标注数据,冷启动困难
3.0时代:大模型驱动(2023-至今)
- 代表技术:GPT-4、LLaMA等百亿参数模型
- 核心优势:
- 零样本学习:无需训练即可回答新问题
- 多轮对话:保持上下文连贯性
- 多模态理解:处理文本、表格、代码片段混合内容
以开源项目PandaWiki为例,其采用的混合引擎架构就体现了3.0时代的技术特征:
- 语义检索层:快速定位相关文档
- 大模型推理层:生成精准回答
- 后处理层:确保回答合规可控
二、现代问答系统的五大核心能力

1. 精准的意图识别
- 区分"产品价格"和"定价策略"是两类不同问题
- 处理模糊表达:"这个东西多少钱"能关联到具体产品
2. 动态知识更新
- 自动检测文档变更(如API版本更新)
- 增量学习新知识而不影响已有能力
3. 可控的输出生成
- 通过提示工程(prompt engineering)控制:
- 回答风格(严谨/活泼)
- 信息密度(简明/详细)
- 安全边界(规避敏感话题)
4. 多源知识融合
- 同时查询:
- 结构化数据(数据库)
- 非结构化文档(PDF/PPT)
- 实时数据(API接口)
5. 可解释的推理过程
- 显示答案来源文档
- 展示推理逻辑链
- 提供置信度评分

PandaWiki的问答界面展示答案来源与置信度
三、行业落地的最佳实践
技术文档场景
- 问题特点:专业术语多、逻辑严谨
- 解决方案:
- 建立术语词典
- 启用代码理解模式
- 配置技术文档专用提示词模板
客服中心场景
- 问题特点:口语化表达、情绪识别
- 解决方案:
- 训练方言识别模型
- 集成情感分析模块
- 设置紧急问题转人工规则
教育培训场景
- 问题特点:引导式学习、错题分析
- 解决方案:
- 构建知识图谱
- 实现错题归因
- 生成个性化学习路径
四、技术选型的关键指标
评估问答系统时建议关注:
- 准确率:TOP1答案的正确率(建议>85%)
- 响应时间:P99延迟应<1秒
- 多轮能力:至少保持10轮上下文
- 冷启动成本:从零搭建到可用的时间
- 运维复杂度:日常维护所需资源
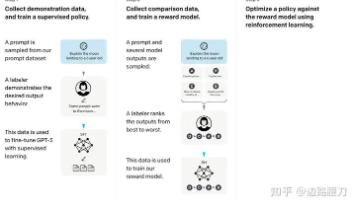
开源方案如PandaWiki在这几个维度表现均衡,特别适合需要快速部署且注重可控性的场景。其采用的"检索+生成"混合架构,在保证回答质量的同时,也避免了纯生成式模型的幻觉问题。
五、未来发展趋势
- 多模态问答:直接解析图表、视频中的信息
- 主动问答:系统预判用户可能的问题
- 个性化适配:根据用户画像调整回答方式
- 自优化体系:通过用户反馈自动迭代模型
智能问答系统正在从"能回答"向"懂需求"进化。随着技术的持续突破,未来3年内我们或将看到:
- 医疗领域的诊断级问答系统
- 法律领域的条款解释专家
- 教育领域的个性化辅导助手
对于技术团队而言,现在正是布局智能问答系统的黄金窗口期。建议从垂直场景切入,逐步构建企业的知识中枢。像PandaWiki这类开源工具,已经大幅降低了技术落地的门槛,使更多组织能够享受到AI带来的效率革命。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)