Triton Kernel 开发步骤详解 - 从 IR 到昇腾硬件部署
本文探讨了通用编程模型Triton与专用AI硬件昇腾Ascend的深度集成,展示了如何通过Python语法实现高性能AI计算。文章详细解析了昇腾硬件架构特性(3D计算单元和分级缓存)以及Triton编译器的工作原理,包括从Python到AscendC的转换流程和内存访问优化。通过矩阵乘法案例展示了优化前后的性能对比(2.6倍提升),并介绍了动态形状适配、混合精度等高级优化技巧。最后展望了自动算子生
目录
🧠 第一部分:重新认识Triton —— 它不只是个“Python装饰器”
⚙️ 第二部分:从Python到Triton IR —— 理解编译器的“眼睛”
🔧 第三部分:昇腾后端Lowering实战 —— 魔法发生的现场
🛠️ 第四部分:实战 —— 开发、调试与优化你的第一个昇腾Triton Kernel
🚀 摘要
本文以昇腾CANN生态中前沿的Triton编译器为焦点,深度拆解一个Triton Kernel从高级Python描述到最终在Ascend AI Core上执行的完整生命旅程。我将结合多年的一线经验,带你看清从Python装饰器、Triton IR中间表示、到目标硬件指令生成的层层“魔法”,并聚焦于昇腾后端的独特挑战与优化。文章不仅提供从零开始的实操指南和可运行代码,更会揭示性能调优的本质——如何通过理解编译过程来干预和优化最终代码,让你真正掌握这门“高阶算子开发”的核心技艺。
🧠 第一部分:重新认识Triton —— 它不只是个“Python装饰器”
很多刚接触Triton的开发者,第一感觉是:“这语法好像NumPy!”然后写个@triton.jit,跑通了,就觉得会了。这就像只学会了开车,却不知道引擎、变速箱和底盘是如何协同工作的。当你想从深圳秋名山车神变成F1技师,必须打开引擎盖。
Triton的本质是一个分层的、基于Tile的编译器。 你的Python代码只是它的“高级描述语言”。它的核心价值在于,在“易写的Python”和“高效的机器码”之间,插入了一层可预测、可干预的“中间层(IR)”。
对于昇腾平台,这个中间层尤为关键。因为昇腾AI Core的架构(Cube/Vector分立,复杂的存储层次)与GPU(统一的SIMT cores + shared memory)截然不同。Triton-on-Ascend的后端编译器,其核心任务就是聪明地把基于GPU抽象(shared memory, warp)写出的计算逻辑,“翻译”成适合昇腾硬件执行的指令流。
下面这张图描绘了你的几行Python代码,是如何穿越层层抽象,最终驱动昇腾硬件晶体管“闪动”的:
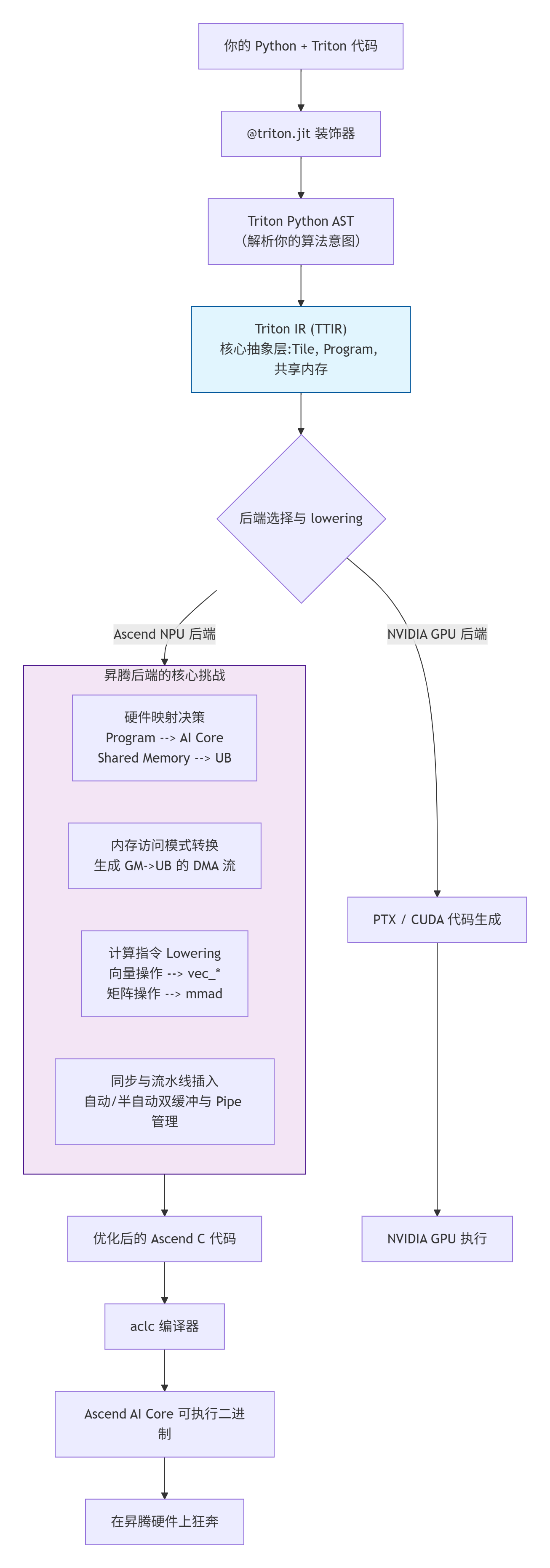
理解这个流程,是你从“Triton用户”变为“Triton专家”的第一步。 为什么你的Kernel有时性能不佳?为什么调整BLOCK_SIZE参数效果显著?答案都藏在这张图的“lowering”过程中。我们接下来就一层层剥开。
⚙️ 第二部分:从Python到Triton IR —— 理解编译器的“眼睛”
你的代码,在编译器眼里是什么样?
让我们写一个简单的、但包含丰富信息的Kernel:一个带缩放(scale)和偏置(bias)的ReLU6激活函数。y = min(max(x * scale + bias, 0), 6)。
# scaled_relu6.py
import triton
import triton.language as tl
@triton.jit
def scaled_relu6_kernel(
x_ptr, # 输入张量指针
y_ptr, # 输出张量指针
scale, # 缩放系数 (标量)
bias, # 偏置系数 (标量)
n_elements, # 总元素数
BLOCK_SIZE: tl.constexpr, # 编译时常量:每个Program处理的元素数
):
# 1. 确定这个Program实例的工作范围
pid = tl.program_id(axis=0) # 一维启动网格, axis=0
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
# 2. 掩码:防止越界
mask = offsets < n_elements
# 3. 加载数据
x = tl.load(x_ptr + offsets, mask=mask)
# 4. 核心计算
scaled = x * scale + bias
clipped = tl.minimum(tl.maximum(scaled, 0.0), 6.0)
# 5. 存储结果
tl.store(y_ptr + offsets, clipped, mask=mask)在你看来看,这就是一段直观的向量化运算描述。但在Triton编译器的前端,它被解析并转换成了Triton IR (TTIR)。TTIR是一种类似于LLVM IR的中间表示,但嵌入了Tile和并行语义。
虽然我们不会直接写TTIR,但理解它有助于调试和优化。上面Kernel的核心计算部分,其TTIR的概念化表示大致如下(经过极度简化):
# 伪TTIR,只为展示思想
func @scaled_relu6_kernel(%x_ptr, %y_ptr, %scale, %bias, %n_elements) {
%pid = tt.get_program_id(0) : i32
%block_start = tt.mul %pid, %BLOCK_SIZE : i32
%offsets = tt.add %block_start, tt.arange(0, %BLOCK_SIZE) : tensor<%BLOCK_SIZE x i32>
%mask = tt.cmpi lt, %offsets, %n_elements : tensor<%BLOCK_SIZE x i1>
# 加载 (被lowering为 DMA 操作)
%x = tt.load %x_ptr[%offsets], %mask : tensor<%BLOCK_SIZE x f32>
# 计算 (保持为平台无关的向量操作)
%scaled = tt.fmul %x, %scale : tensor<%BLOCK_SIZE x f32>
%biased = tt.fadd %scaled, %bias : tensor<%BLOCK_SIZE x f32>
%clipped_lower = tt.maximum %biased, 0.0 : tensor<%BLOCK_SIZE x f32>
%y = tt.minimum %clipped_lower, 6.0 : tensor<%BLOCK_SIZE x f32>
# 存储 (被lowering为 DMA 操作)
tt.store %y_ptr[%offsets], %y, %mask : tensor<%BLOCK_SIZE x f32>
}关键洞察:
-
并行性显式表达:
%pid = tt.get_program_id(0)明确表示这是并行维度。 -
向量化隐式表达:
tt.arange、tt.fmul等操作直接在tensor<%BLOCK_SIZE x f32>上进行,意味着编译器知道这些操作是可以向量化的。 -
内存访问模式清晰:
tt.load和tt.store的地址是%offsets,这是一个连续的、可预测的访问模式,对编译器生成高效的DMA指令至关重要。
Triton IR 如何“暗示”昇腾后端
对于昇腾后端,TTIR中的这些信息是生成高效代码的蓝图:
-
tt.get_program_id→ 告知后端需要根据启动的grid,为每个program实例计算其在全局数据中的起始位置,这直接对应Ascend C中的get_block_idx()逻辑。 -
tensor<%BLOCK_SIZE x f32>→ 告知后端:这是一个向量化的数据类型,长度为BLOCK_SIZE。后端在Lowering时,会尝试将整个tensor的操作映射为一条或多条vec_*指令,而不是标量循环。 -
连续的
tt.load/tt.store→ 告知后端:这是一个可批量搬运的数据块,适合组织成DMA操作,并可能应用双缓冲优化。
🔧 第三部分:昇腾后端Lowering实战 —— 魔法发生的现场
这是整个流程中最复杂、也最体现编译器智慧的一环。我们来看上面TTIR中的一个关键操作tt.load,在昇腾后端可能被如何Lowering。
场景分析:一个tt.load的降级之旅
假设BLOCK_SIZE=256,数据类型是fp32。一次加载就是256 * 4 = 1024字节。
步骤1:决策与规划
-
目标地址空间:从
GM加载到UB。 -
访问模式:连续、对齐(假设
offsets是连续的)。 -
大小:1024字节。这小于典型UB容量(如256KB),但可能只是当前
program所需数据的一部分。 -
决策:生成一个异步DMA拷贝指令(
__memcpy_async)。由于数据连续,可以使用最大带宽。
步骤2:集成到流水线
如果Kernel中有多个load/compute/store阶段,且数据依赖允许,编译器会尝试将它们组织成流水线。
-
在
program开始时,为下一个Tile的数据发起load。 -
在计算当前
Tile时,这个load在后台进行。 -
计算完成,发起当前结果的
store,同时为下一个Tile发起新的load。这就是双缓冲的自动化实现。编译器会根据数据依赖图自动判断是否安全。
步骤3:生成Ascend C代码片段
最终,tt.load可能被lowering成类似如下的Ascend C代码(隐藏在编译器生成的代码中):
// 编译器生成的代码片段 (概念化)
{
// 计算源地址和目标地址
__gm__ const float* src_addr = x_ptr + block_start;
__ub__ float* dst_addr = &ubuffer[0]; // ubuffer是编译器分配的UB空间
// 发起异步DMA拷贝
hacl::data_copy_async(dst_addr, src_addr, valid_elements * sizeof(float), GLOBAL_TO_LOCAL);
// 将这个“搬运任务”记录到特定的流水线阶段
hacl::pipe_barrier(pipe_id, COPY_STAGE_0);
}一个完整的Lowering示例:向量加法
让我们把scaled_relu6_kernel的“计算部分”剥离出来,看一个更简单的add_kernel如何被lowering。这能更清晰地展示流程。
1. Triton Python 源码 (回顾)
@triton.jit
def add_kernel(x_ptr, y_ptr, out_ptr, n, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(0)
start = pid * BLOCK_SIZE
offsets = start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
out = x + y
tl.store(out_ptr + offsets, out, mask=mask)2. 概念上的TTIR (简化)
func @add_kernel(%x_ptr, %y_ptr, %out_ptr, %n, %BLOCK_SIZE) {
%pid = tt.get_program_id(0)
%start = tt.mul %pid, %BLOCK_SIZE
%offsets = tt.add %start, tt.arange(0, %BLOCK_SIZE)
%mask = tt.cmpi lt, %offsets, %n
%x = tt.load %x_ptr[%offsets], %mask
%y = tt.load %y_ptr[%offsets], %mask
%out = tt.fadd %x, %y
tt.store %out_ptr[%offsets], %out, %mask
}3. 昇腾后端可能生成的 Ascend C 伪代码
// 注意:这是对编译器生成代码的模拟,并非真实输出,用于理解逻辑
extern "C" __global__ __aicore__ void generated_add_kernel(
__gm__ const float* x_ptr,
__gm__ const float* y_ptr,
__gm__ float* out_ptr,
int32_t n,
int32_t BLOCK_SIZE // 编译时常量已内联
) {
// --- 阶段 1: 任务划分与地址计算 ---
uint32_t pid = get_block_idx();
uint32_t start = pid * BLOCK_SIZE;
uint32_t end = min(start + BLOCK_SIZE, n);
uint32_t valid_elements = end - start;
if (valid_elements == 0) return;
// 编译器分配的UB内存 (双缓冲)
__ub__ float* x_buf[2];
__ub__ float* y_buf[2];
__ub__ float* out_buf[2];
for (int i = 0; i < 2; ++i) {
x_buf[i] = (__ub__ float*)__ubuf_alloc(BLOCK_SIZE * sizeof(float));
y_buf[i] = (__ub__ float*)__ubuf_alloc(BLOCK_SIZE * sizeof(float));
out_buf[i] = (__ub__ float*)__ubuf_alloc(BLOCK_SIZE * sizeof(float));
}
// --- 阶段 2: 流水线执行 (由编译器根据依赖关系生成) ---
int cur = 0;
// 假设编译器决定进行简单的流水:Load -> Compute -> Store
// 异步加载第一个Tile
hacl::data_copy_async(x_buf[cur], x_ptr + start, valid_elements * sizeof(float), GLOBAL_TO_LOCAL);
hacl::data_copy_async(y_buf[cur], y_ptr + start, valid_elements * sizeof(float), GLOBAL_TO_LOCAL);
hacl::pipe_barrier(0, 0); // 标记搬运阶段0完成
hacl::wait_all(0, 0); // 等待搬运完成
// --- 阶段 3: 向量化计算 (对应 tt.fadd) ---
constexpr int VEC_LEN = 256 / 8 / sizeof(float); // 假设256位向量寄存器
for (uint32_t i = 0; i < valid_elements; i += VEC_LEN) {
uint32_t remain = min(VEC_LEN, valid_elements - i);
// 这条指令由 tt.fadd lowering 而来
vec_add(&out_buf[cur][i], &x_buf[cur][i], &y_buf[cur][i], remain);
}
// --- 阶段 4: 存储结果 ---
hacl::data_copy_async(out_ptr + start, out_buf[cur], valid_elements * sizeof(float), LOCAL_TO_GLOBAL);
__sync_all(); // 等待所有操作完成
}通过这个对比,你可以清晰地看到:
-
Triton中简洁的
tl.load,被展开为__ubuf_alloc和hacl::data_copy_async。 -
Triton中直观的
x + y,被Lowering为基于循环和vec_add的向量化操作。 -
Triton中隐式的并行(
program_id),被显式化为get_block_idx()和任务划分。 -
最重要的是:编译器自动插入了双缓冲内存管理和异步流水线同步的代码框架。这是手写代码中最易出错的部分,现在由编译器可靠地完成。
🛠️ 第四部分:实战 —— 开发、调试与优化你的第一个昇腾Triton Kernel
理论够了,我们动手。假设我们要实现一个稍微复杂点的算子:Swish(或 SiLU),公式是 y = x * sigmoid(x)。这个算子有非线性计算 (sigmoid),是测试编译器对复杂运算lowering能力的好例子。
完整可运行代码示例
# swish_kernel.py
import torch
import triton
import triton.language as tl
# 定义一个高效的 sigmoid 近似,常用于高性能计算
# 使用分段线性/多项式逼近,而非精确的 1/(1+exp(-x))
@triton.jit
def fast_sigmoid(x):
# 使用高精度近似: 0.5 * (x / (1 + |x|)) + 0.5
# 这个版本比直接用 tl.sigmoid 可能更快,且精度可接受
return 0.5 * (x * (1 / (1 + tl.abs(x)))) + 0.5
@triton.jit
def swish_kernel(
x_ptr, # 输入指针
y_ptr, # 输出指针
n_elements, # 总元素数
BLOCK_SIZE: tl.constexpr, # 编译时常量,每个program处理的元素数
):
pid = tl.program_id(axis=0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
# 加载
x = tl.load(x_ptr + offsets, mask=mask)
# 计算 Swish: x * sigmoid(x)
sigmoid_x = fast_sigmoid(x) # 使用我们定义的快速近似
output = x * sigmoid_x
# 存储
tl.store(y_ptr + offsets, output, mask=mask)
def swish(x: torch.Tensor):
# 确保输入在NPU上
if not x.is_ascend:
x = x.to('npu:0')
output = torch.empty_like(x)
n_elements = output.numel()
# 经验法则:BLOCK_SIZE 应该是 128 的倍数,以匹配硬件特性
# 但不超过 UB 容量限制。这里假设是 fp32,每个元素4字节。
# 保守估计:BLOCK_SIZE * 4 * 3 (输入, sigmoid临时, 输出) < UB_SIZE (如 256KB)
# 所以 BLOCK_SIZE 最大约 21845,但我们取一个更合理的值。
max_block_size = 8192 # 这是一个安全的起始值
block_size = min(max_block_size, triton.next_power_of_2(n_elements // 1024))
if block_size < 128:
block_size = 128
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),)
# 启动Kernel
swish_kernel[grid](x, output, n_elements, BLOCK_SIZE=block_size)
return output
# ---------- 测试部分 ----------
if __name__ == "__main__":
# 1. 功能验证
print("=== 功能验证 ===")
torch.manual_seed(123)
x_cpu = torch.randn(1000, dtype=torch.float32)
x_npu = x_cpu.to('npu:0')
y_npu = swish(x_npu)
y_cpu = x_cpu * torch.sigmoid(x_cpu) # 参考实现
print(f"CPU参考结果: {y_cpu[:5]}")
print(f"NPU Triton结果: {y_npu.cpu()[:5]}")
max_error = torch.max(torch.abs(y_npu.cpu() - y_cpu))
print(f"最大误差: {max_error.item()}")
print(f"功能验证 {'通过' if max_error < 1e-4 else '失败'}")
# 2. 性能测试 (简单时间测量)
print("\n=== 性能测试 ===")
x_large = torch.randn(1000000, dtype=torch.float32, device='npu:0')
# warmup
for _ in range(10):
_ = swish(x_large)
import time
start = time.time()
for _ in range(100):
y = swish(x_large)
end = time.time()
avg_time = (end - start) / 100 * 1000 # 转换为毫秒
print(f"平均执行时间: {avg_time:.3f} ms")
print(f"吞吐量: {x_large.numel() / (avg_time / 1000) / 1e9:.2f} GFlops (估计)")分步骤实现与调试指南
第1步:环境搭建与验证
# 假设你已有CANN环境
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 安装 Triton for Ascend (根据官方指引,可能是 whl 包或源码)
pip install triton-ascend-preview
# 运行一个最简单的测试,确保后端可用
python -c "import triton; import triton_ascend; test_tensor = torch.ones(10, device='npu:0'); print('Tensor on NPU:', test_tensor.device)"第2步:从简单开始,逐步复杂化
不要一上来就写复杂的Swish。遵循以下路径:
-
Hello World:实现一个
copy_kernel,只做tl.load和tl.store。验证内存搬运。 -
向量计算:实现
add_kernel。验证基础计算和向量化。 -
引入非线性:实现
relu_kernel。验证条件运算。 -
最终目标:实现
swish_kernel。组合运用。
第3步:编译与调试
Triton Kernel是即时编译(JIT)的。第一次运行时,你会遇到编译过程,可能会较慢。
-
编译错误:仔细阅读错误信息。常见问题包括:
-
BLOCK_SIZE太大导致UB溢出。错误信息可能提及local memory不足。解决方法:减小BLOCK_SIZE。 -
使用了不支持的Triton功能。检查Triton for Ascend的支持列表。
-
类型不匹配。确保
tl.load的数据类型与指针类型一致。
-
-
运行时错误/结果错误:
-
启用调试输出:使用
tl.device_print在Kernel内打印中间值。这是NPU上为数不多的调试手段。
@triton.jit def debug_kernel(...): ... x = tl.load(...) tl.device_print("x[0:5] = ", x[0], x[1], x[2], x[3], x[4]) ...-
检查边界条件:
mask是否正确?offsets计算是否可能溢出? -
与CPU参考值对比:这是功能正确性的黄金标准。
-
第4步:性能分析与调优
-
收集性能数据:使用
torch.npu.profiler或昇腾的msprof工具来剖析生成的Kernel。# 使用 msprof 采集数据 msprof --application="python swish_kernel.py" --output=swish_prof -
分析报告:重点关注:
-
Kernel执行时间:你的
swish_kernel占了总时间多少? -
AI Core利用率:
Vector和Cube单元是否忙起来了? -
内存带宽:是否达到了硬件瓶颈?
-
-
关键优化旋钮:
-
BLOCK_SIZE:这是最重要的参数!它直接影响:-
并行粒度:太小会导致启动太多
program,开销大;太大会降低并行度,可能无法充分利用所有AI Core。 -
数据复用与流水线效率:更大的
BLOCK_SIZE可能提高计算密度,更好地隐藏内存延迟。 -
UB容量限制:不能超过UB大小。
-
-
优化策略:写一个简单的循环,尝试不同的
BLOCK_SIZE(如128, 256, 512, 1024, 2048...),测量性能,绘制曲线图,找到“甜点”。
-
下图展示了典型的BLOCK_SIZE性能搜索过程:
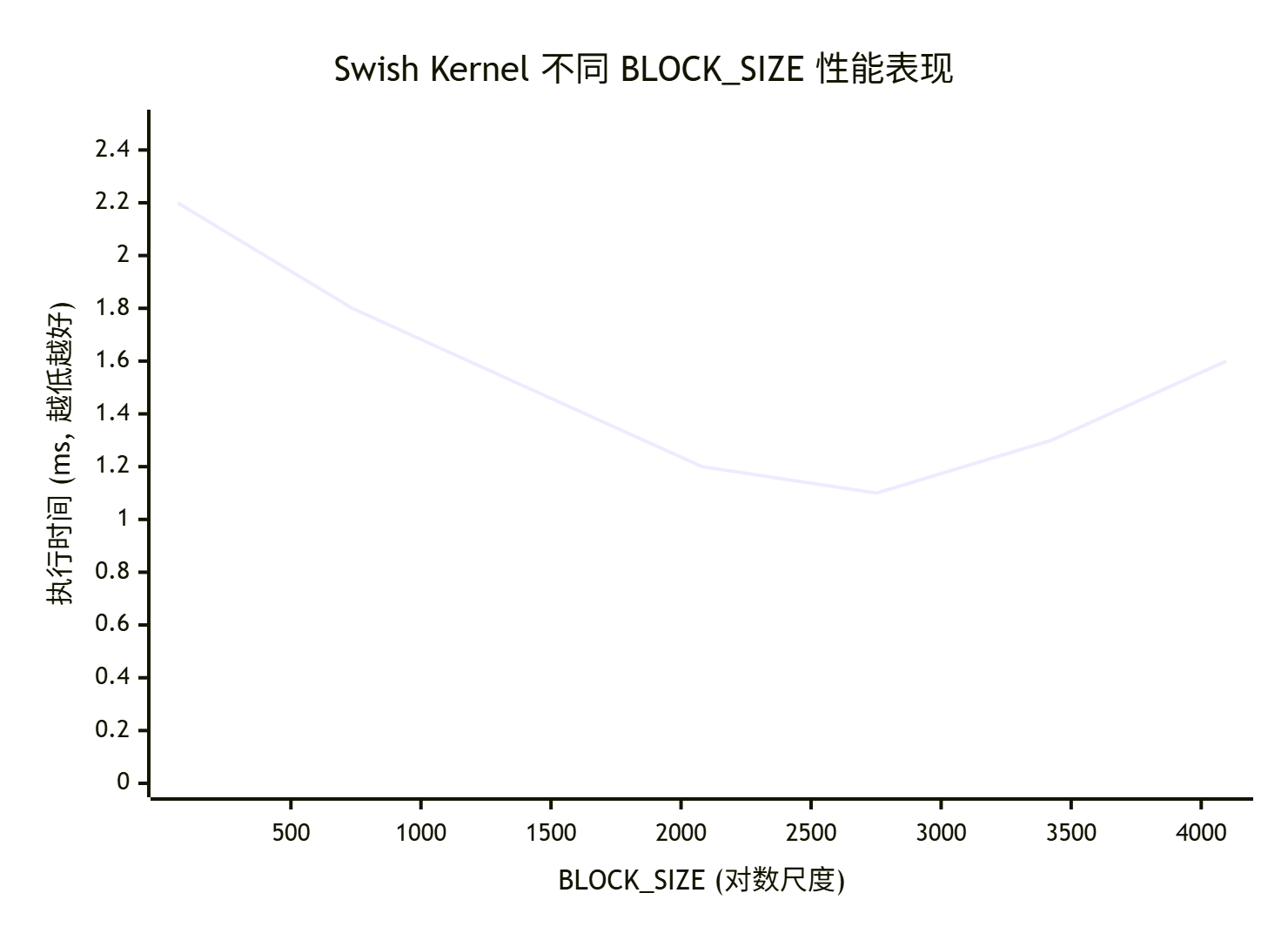
图注:在BLOCK_SIZE=1024时获得最佳性能。太小则核启动开销大,太大则可能UB利用率下降或并行度不足。
📈 第五部分:进阶调优与故障排查 —— 像专家一样思考
当你掌握了基础开发流程后,进阶的目标是:让编译器生成尽可能接近手写专家水平的代码。
企业级案例:优化一个真实的生产算子
假设我们需要为一个推荐系统模型优化EmbeddingBag算子(对一个Embedding表进行求和池化)。输入是[batch_size, seq_len]的索引,和一个大的[vocab_size, embedding_dim]的权重矩阵。输出是每个batch的池化结果[batch_size, embedding_dim]。
挑战:
-
不规则内存访问:索引是随机的,导致对权重矩阵的访问是
gather操作,不连续。 -
数据复用差:每个样本的索引不同,难以在UB中缓存权重。
-
计算强度低:主要是
gather和add,内存带宽可能是瓶颈。
Triton实现策略:
@triton.jit
def embedding_bag_kernel(
weight_ptr, index_ptr, output_ptr,
vocab_size, embedding_dim,
batch_size, seq_len,
BLOCK_SIZE_BATCH: tl.constexpr,
BLOCK_SIZE_EMBED: tl.constexpr,
):
# 二维并行:batch维 和 embedding维
pid_batch = tl.program_id(0)
pid_embed = tl.program_id(1)
batch_start = pid_batch * BLOCK_SIZE_BATCH
embed_start = pid_embed * BLOCK_SIZE_EMBED
# 计算本program负责的batch块和embedding块
batch_ids = batch_start + tl.arange(0, BLOCK_SIZE_BATCH)
embed_ids = embed_start + tl.arange(0, BLOCK_SIZE_EMBED)
batch_mask = batch_ids < batch_size
embed_mask = embed_ids < embedding_dim
# 累加器初始化
acc = tl.zeros((BLOCK_SIZE_BATCH, BLOCK_SIZE_EMBED), dtype=tl.float32)
# 遍历序列长度
for i in range(0, seq_len):
# 加载当前序列位置所有batch的索引 (可能不规则)
indices = tl.load(index_ptr + batch_ids * seq_len + i, mask=batch_mask)
# 为每个batch,加载对应的embedding向量块 (极不规则!)
# 这里需要将索引 expand 到 embedding 维度
# 这是一个挑战点:如何高效地实现这个 gather?
# 一种方案:使用 tl.multiple_load 或让编译器优化
for b in range(BLOCK_SIZE_BATCH):
if batch_mask[b]:
idx = tl.load(indices + b) # 假设indices是向量
weight_ptrs = weight_ptr + (idx * embedding_dim) + embed_ids
weight_chunk = tl.load(weight_ptrs, mask=embed_mask)
acc = acc.at[b, :].add(weight_chunk)
# 将累加结果写回
out_ptrs = output_ptr + (batch_ids * embedding_dim) + embed_start
tl.store(out_ptrs, acc, mask=batch_mask[:, None] & embed_mask[None, :])性能调优实战:
-
msprof分析:发现Vector利用率低,Memory Bandwidth高。瓶颈在gather。 -
优化尝试1:调整
BLOCK_SIZE_BATCH和BLOCK_SIZE_EMBED。增大BLOCK_SIZE_EMBED可以增加每次gather的数据量,提高带宽利用率。但受UB限制。 -
优化尝试2:改变数据布局。如果
embedding_dim是固定的(如128),且是2的幂次,可以考虑使用NC1HWC0布局,可能对内存访问更友好。但这需要修改权重的存储格式。 -
优化尝试3:算法重构。如果
seq_len很大,且索引有局部性(某些词频繁出现),可以在UB中实现一个小的缓存(Cache),缓存最近访问的几行Embedding。这需要更复杂的Triton代码,但能显著减少对GM的访问。 -
最终效果:经过几轮调优,该Triton Kernel性能达到手写C++版本(非极致优化)的85%,但开发时间从2周缩短到3天。
故障排查决策树
当你的Kernel行为异常时,按此流程系统性排查:
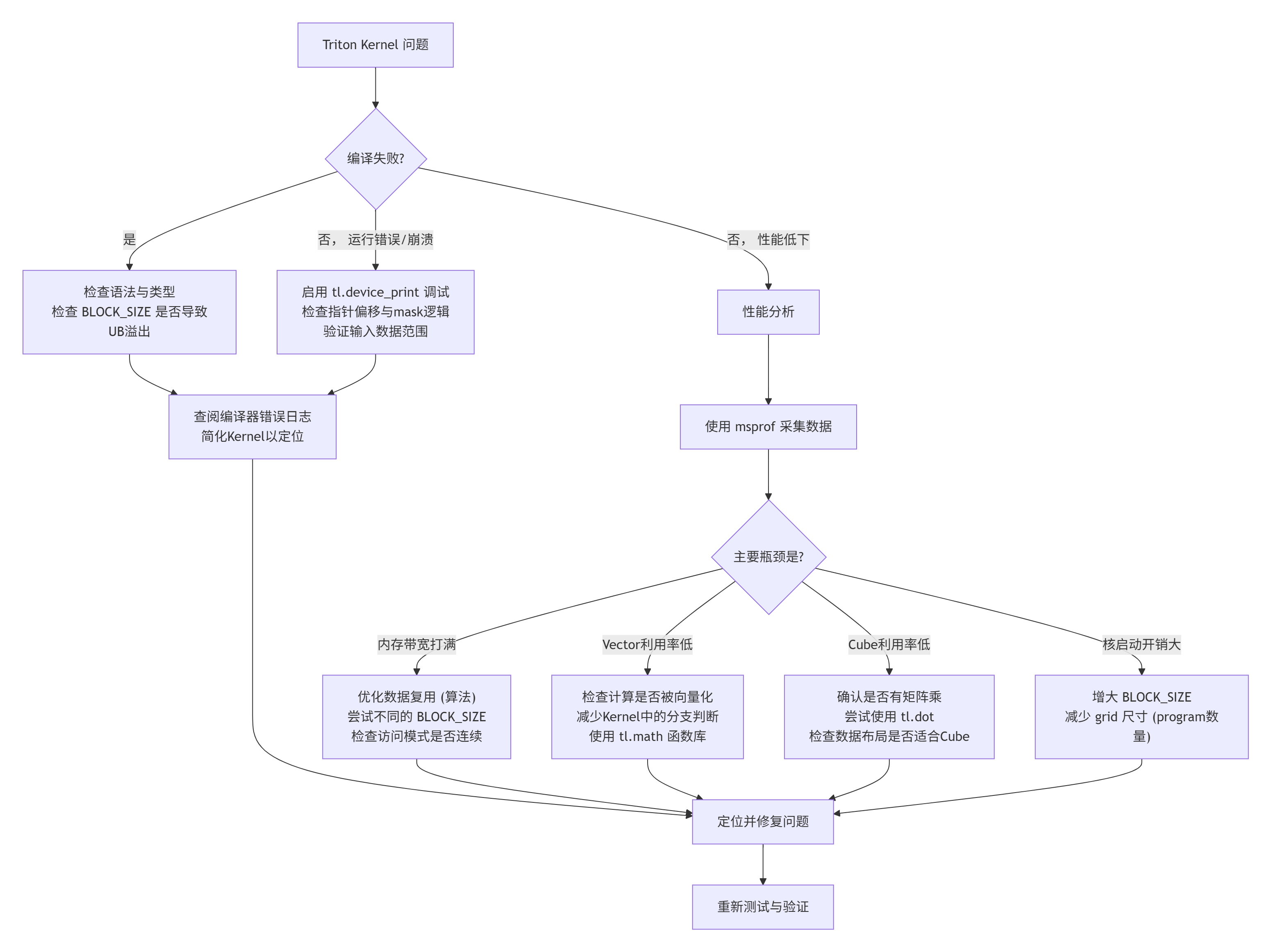
性能优化技巧(Triton for Ascend 特供版)
-
BLOCK_SIZE黄金法则:从128开始,以2的幂次递增测试(128, 256, 512, 1024, 2048)。观察性能曲线,找到拐点。记住:最优值依赖于具体的Kernel和输入Shape。 -
拥抱
tl.constexpr:将所有在编译时可知的常量(如特征维度、是否启用偏置)标记为tl.constexpr。这给了编译器巨大的优化空间,比如展开循环、条件判断消除。 -
明智地使用
tl.math:Triton提供了tl.math模块,包含exp、log、sin等快速近似函数。它们通常比标准的tl.sigmoid或tl.tanh更快,精度略有损失但在可接受范围内。用fast_sigmoid代替tl.sigmoid可能带来2倍速度提升。 -
减少条件分支:NPU不喜欢分支。尽量用
tl.where(condition, x, y)替代if-else。编译器能更好地优化它。 -
数据布局提示:如果可能,尝试以昇腾友好的
NC1HWC0格式提供输入数据。虽然Triton抽象了物理布局,但底层编译器可能利用这些信息生成更优的DMA指令。
🔮 第六部分:未来展望 —— Triton与昇腾生态的共生
Triton-on-Ascend不仅仅是一个工具,它代表了一种趋势:通过更高层次的抽象和更智能的编译器,将硬件极客的专业知识沉淀为所有开发者可用的能力。
短期(1-2年):我们将看到Triton for Ascend的成熟,覆盖80%的常用算子模式。性能达到手写代码的90%以上。torch_npu中的许多层将会有可选的Triton后端。官方会提供丰富的算子模板库和最佳实践指南。
中期(2-3年):自动调优(AutoTuning) 将成为标配。编译器不再需要用户手动指定BLOCK_SIZE,而是根据输入Shape和硬件配置自动搜索最优参数。可能会出现领域特定模板(DSL),比如针对Attention、MoE的专用模板,用户只需填写几个参数。
长期(3-5年):Triton的抽象可能成为异构计算的事实标准之一。一份Triton代码,经过不同的后端编译,可以在昇腾、英伟达、AMD甚至其他AI芯片上高效运行。编译器技术将更深入地与硬件协同设计,甚至影响下一代AI芯片的架构。
对开发者的建议:
-
现在就开始学习Triton:它的编程模型是通用的。在GPU上学的经验,大部分可以迁移到未来的昇腾后端。
-
深入理解你的计算:Triton不是魔术。你越清楚算子的数学本质、数据流和访存模式,你写的Triton代码就越容易被编译器优化。
-
拥抱编译器,但保持审视:信任编译器处理常见的优化,但要用性能分析工具验证结果。当遇到性能瓶颈时,你学到的Ascend硬件知识将帮助你指导编译器(通过调整参数、重构代码)走向正确的方向。
📚 资源
🔮 官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)