英特尔 Arc Pro B60 Battlematrix测评:192GB 显存赋能本地 AI 部署
通过在单系统中最高支持八块 GPU,实现总计 192GB 的显存容量,Battlematrix 旨在为 AI 推理工作负载提供一个相对于其他专业 GPU 生态更具成本效益的选择。
英特尔推出的“Project Battlematrix”项目,为构建易于获取的 AI 基础设施提供了一项颇具吸引力的解决方案。它通过创新的多 GPU 设计,将海量 GPU 内存容量带入了工作站规格的机箱。该平台基于代号“Battlemage”的 Arc Pro B60 专业显卡打造,主要瞄准那些希望本地部署大语言模型、以避免云订阅费用并消除数据隐私顾虑的企业与机构。通过在单系统中最高支持八块 GPU,实现总计 192GB 的显存容量,Battlematrix 旨在为 AI 推理工作负载提供一个相对于其他专业 GPU 生态更具成本效益的选择。
Battlematrix 与传统工作站配置的关键区别在于其双 GPU 板卡设计:它将两颗完整的 B60 GPU 集成在一块 PCB 上,这需要主板支持 PCIe 通道拆分。这种高密度设计使得原本需要服务器主板才能实现的配置成为可能,而每个 Arc Pro B60 GPU 配备的 24GB GDDR6 显存,使其特别适合处理需要大内存的 Transformer 模型。早期测试已显示出其令人期待的潜力,尽管目前软件优化水平尚落后于硬件能力。
本次测试基于早期软件和驱动程序版本(包括英特尔 LLM Scaler 的开发分支)进行。此外,下面的测试平台使用了 AMD EPYC 处理器,而非英特尔的至强平台。英特尔将 Battlematrix 定位为采用至强 6 处理器的全英特尔解决方案,因此未来采用英特尔 CPU 的系统可能会表现出比目前结果更优的性能。请各位理解这些结果为初步数据,预计软件成熟度与平台优化将在 2026 年期间持续提升。
Arc Pro B60规格和架构
英特尔 Arc Pro B60 与面向游戏市场的英特尔 Arc B580 共享相同的芯片基础,两者均采用台积电 5nm 工艺制造的晶粒。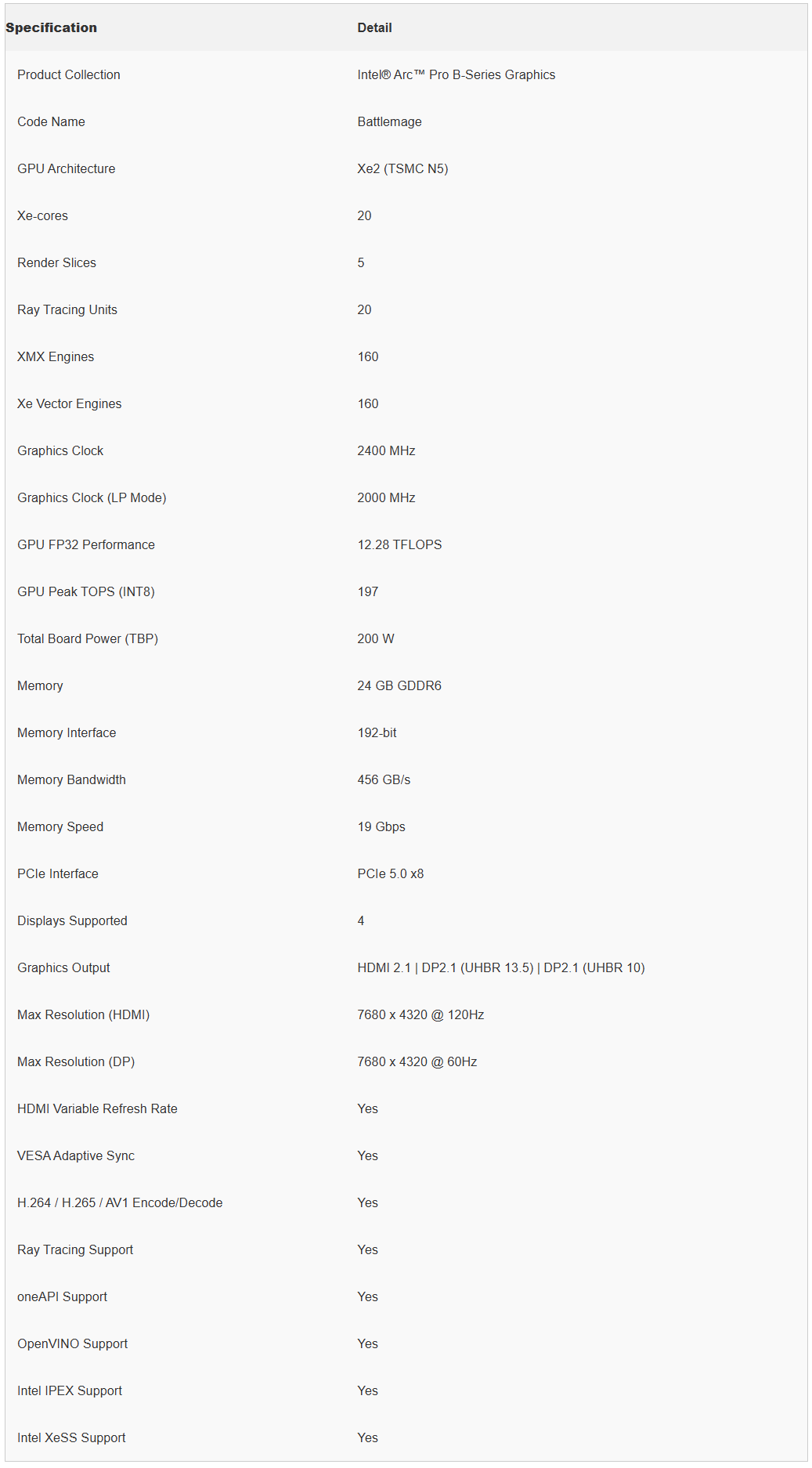
这款 272mm² 的芯片集成了 196 亿个晶体管和 20 个 Xe2 核心,标称每个 GPU 可提供 12.28 TFLOPS 的 FP32 计算性能及 197 TOPS 的 INT8 AI 性能。其关键差异在于内存配置:B580 配备 12GB GDDR6,而 B60 将此容量翻倍至 24GB。
每个 B60 GPU 的核心频率为 2400MHz,通过 192 位内存接口实现 456GB/s 的带宽。其架构中,每个 GPU 包含 160 个专为加速 AI 推理中矩阵运算而设计的 XMX AI 引擎。
双 GPU 设计与 PCIe 通道拆分
以铭瑄 Arc Pro B60 Dual 48G Turbo 为例,这款产品体现了英特尔的密度策略:两颗完整 GPU 集成于一张双槽显卡,各自通过独立的 PCIe 5.0 x8 接口连接。与传统上将双芯片桥接为单一 GPU 的设计不同,此卡上的每个 B60 GPU 在系统中均作为独立设备呈现,因此需要主板支持 PCIe x8/x8 通道拆分。一个物理的 x16 插槽在电气上被拆分为两个 x8 连接,确保每个 GPU 获得专用带宽。
PCIe 5.0 x8 为每个 GPU 提供 128GB/s 的双向带宽,等同于 PCIe 4.0 x16。该双芯卡长度为 300mm,采用双槽鼓风机式散热设计,通过一个额定功率 600W 的 12V-2×6 供电接口获取电力,整卡最大功耗为 400W。
每张双芯卡提供四组显示输出:两组 DisplayPort 2.1 UHBR20 和两组 HDMI 2.1a 端口,每组对应一个 GPU,便于为虚拟桌面环境或多用户系统配置独立的显示输出。需要注意的一点是,每个 GPU 的两个显示输出无法同时使用。
八 GPU Battlematrix 系统配置
根据英特尔的参考规范,Battlematrix 可在单台工作站机箱内最多支持八颗 Arc Pro B60 GPU,即安装四张双芯显卡。此配置可提供:
● 总计 192GB 系统显存(8 × 24GB)
● 1280 个 XMX AI 引擎
● 总计 1576 INT8 TOPS 的 AI 算力
● 3.6TB/s 的聚合内存带宽
该平台需要配备四个支持通道拆分的 PCIe 5.0 x16 插槽的主板。Battlematrix 规范还将包含至强 6 处理器;但关于该配置的其他详细信息目前尚未公布。
应用场景与价值定位
英特尔的 Project Battlematrix 主要面向三大市场:需要本地化基础设施的 AI 开发团队、在涉及敏感代码库的工作流程中引入 AI 辅助的软件工程组织,以及寻求更具成本效益的云推理服务替代方案的企业。
私有 AI 与智能体开发
Battlematrix 平台的主要优势在于能够支持需要超长上下文窗口和海量参数的大语言模型开发工作流。对于构建智能体系统的开发团队而言,充足的显存余量尤为重要。典型的 RAG 智能体实现需要在 GPU 内存中同时维护多个组件:基础语言模型、用于向量检索的嵌入模型以及重排序模型。此外,智能体工作流涉及多步推理、工具调用和自我修正,通过迭代会产生庞大的上下文窗口。
未来的 VDI 与虚拟化游戏应用
英特尔的路线图包括为 Arc Pro B60 GPU 引入 SR-IOV(单根 I/O 虚拟化) 支持,从而将其转变为真正的多用户图形平台。SR-IOV 技术允许将单个物理 GPU 划分为多个虚拟 GPU,每个虚拟 GPU 可直接分配给不同的虚拟机,并享有独立的硬件访问通道和内存空间。
这将解锁免授权费的虚拟桌面基础设施应用场景。单台八 GPU Battlematrix 系统可支持数十个并发用户,为 CAD 设计、视频编辑或中度游戏等应用提供专属的 GPU 加速。传统 VDI 方案除硬件成本外,还需支付高昂的软件授权费,且通常强制使用更昂贵的专业级或数据中心级 GPU。英特尔承诺的免授权虚拟化方案将消除此项运营开支。
定价与价值分析
英特尔宣布 Arc Pro B60 的定价约为每 GPU 600 美元。对于初期测试和开发,单卡或双卡配置(600 至 1200 美元)提供了较低的入门门槛。一张 48GB 显存的双芯卡,足以运行多数量化模型,并覆盖相当一部分流行的开源大语言模型应用。
单卡和双卡配置为小型团队、独立开发者和家庭实验室爱好者提供了极高的经济性。以 600 美元获得 24GB GPU 显存,或以 1200 美元获得 48GB,该平台的价格显著低于通常售价至少翻倍的专业 GPU 替代品。对于预算有限的项目,还是比较有吸引力的。
vLLM 在线服务基准测试表现
vLLM 是目前最流行的高吞吐量大语言模型推理与服务平台。vLLM 在线服务基准测试工具通过模拟生产环境的并发请求,来评估实际的推理服务性能。它可配置请求速率、输入/输出长度、并发客户端数量等参数,并测量关键指标,包括吞吐量、首令牌延迟和每个输出令牌时间,以帮助用户了解 vLLM 在不同负载下的表现。
测试平台配置:
● 服务器:超微Supermicro AS-4125GS-TNRT
● 处理器:双路 AMD EPYC 9374F
● 内存:512GB 三星 DDR5 (4800 MT/s)
● GPU:4x MS-Intel ARC Pro B60 Dual 48G Turbo(共8颗GPU)
量化支持与当前限制
这些 GPU 本应在低精度推理(尤其是 INT4 量化)上表现出色。然而,由于我们测试所用的是英特尔 LLM Scaler 的极早期开发版本,只有那些最初使用 MXFP4 微缩放格式训练的 GPT OSS 模型能够正常运行。其他量化格式,包括标准 INT4、FP8 和 AWQ,均无法启动。这一限制严重影响了我们全面测试 GPU 性能的能力,不过预计随着软件栈的成熟,将支持更广泛的量化格式。
我们对大多数模型进行了两种配置的测试:完整的八 GPU Battlematrix 系统,以及刚好能容纳模型所需的最少 GPU 数量。这种对比揭示了有趣的扩展特性,特别是在低批次大小下的通信开销问题。
微缩放数据类型说明
微缩放是一种先进的量化技术,它对小块权重应用精细的缩放因子,而非对整个大参数组进行统一量化。MXFP4 格式使用分块浮点表示法实现此技术,每个微缩放块共享一个共同的指数作为缩放因子,从而在实现 4 位精度的同时保持了良好的数值精度。MXFP4 的一个关键优势是,将模型量化为 INT4 不会像从更高精度格式(如 BF16)量化那样严重损害输出质量。需要注意的是,GPT OSS 模型在 B60 上是以 INT4 量化运行的,因为当前硬件尚不支持原生的 MXFP4。
OpenAI GPT-OSS 200亿参数模型
这个 200 亿参数模型清晰地展示了通信开销的影响。在批次大小为 1 时,单 GPU 配置能为每个用户提供 49.22 tok/s 的吞吐,而分布在所有八个 GPU 上时仅为 22.83 tok/s,单 GPU 性能领先超过 2 倍。然而,八 GPU 配置在高并发下表现出色,在批次大小为 16 时实现了 511.99 tok/s 的总吞吐。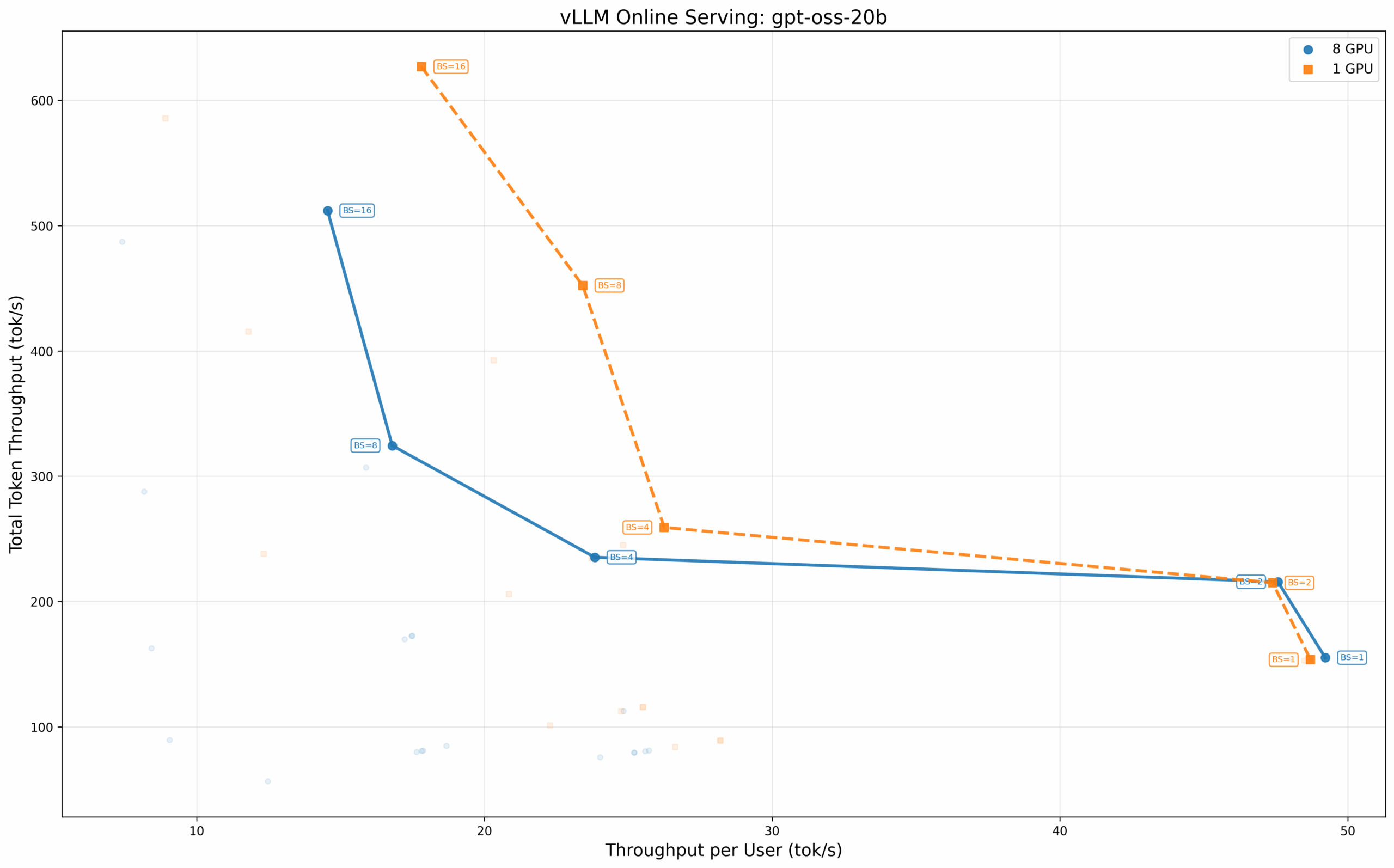
有趣的是,使用最少 GPU(TP=4)的配置在批次大小 16 时,反而实现了更高的总吞吐量:626.84 tok/s,高于八 GPU 配置的 511.99 tok/s。这个反直觉的结果说明,对于能够轻松适配在较少 GPU 上的模型和上下文长度,增加更多硬件会带来通信开销,却无法获得成比例的性能提升。
OpenAI GPT-OSS 1200亿参数模型
更大的 1200 亿参数模型至少需要 4 个 GPU,因此无法进行单 GPU 对比。四 GPU 和八 GPU 配置之间的性能表现更为接近,在批次大小为 1 时,每个用户的吞吐量几乎相同(均为 16.28 tok/s)。八 GPU 配置通过数据并行,在较高批次大小时提供了有限的性能增益。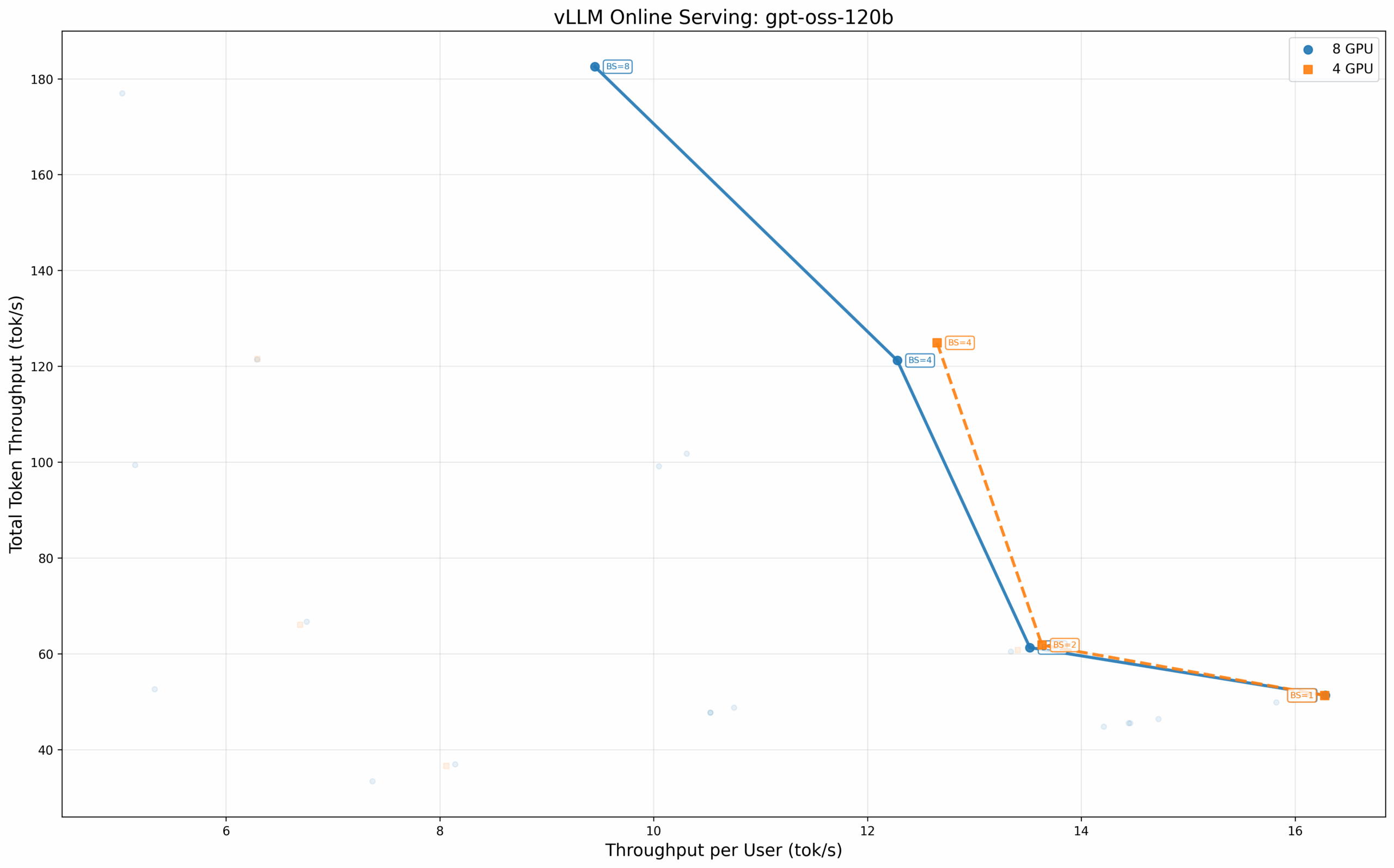
混合专家模型:Qwen3 Coder 300亿-A3B
稀疏 MoE 架构在推理时仅激活其庞大参数池的一个子集。Qwen3 Coder 300亿-A3B 模型每令牌从其完整的 300 亿参数中激活约 30 亿参数,这使其成为本地编码助手部署的热门选择。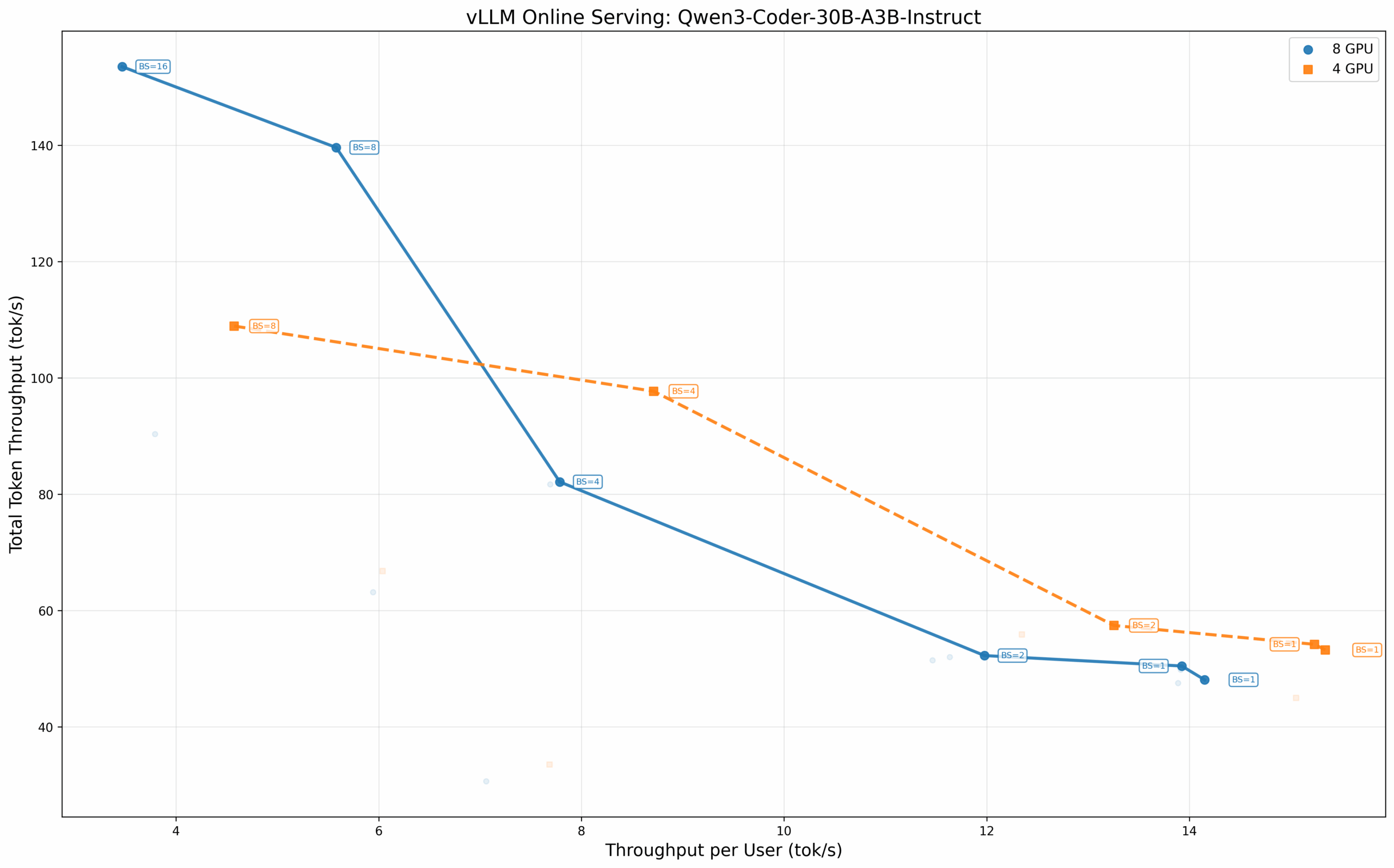
在 BF16 精度下测试,四 GPU 配置在低批次大小时再次显示出优势。在批次大小为 1 时,TP=4 配置的每个用户吞吐量为 15.34 tok/s,高于 TP=8 配置的 14.15 tok/s。
稠密模型测试
稠密模型采用传统的 LLM 架构,推理时会使用所有参数和激活值,因此计算密集度高于稀疏模型。由于测试期间 INT4 量化无法正常工作,这些模型均以 BF16 精度运行。
Llama 3.1 80亿参数 Instruct 模型
这个紧凑的 80 亿参数模型可以轻松适配单 GPU,但我们仍测试了多种配置以分析扩展行为。结果印证了前述模式:在批次大小为 8 时,四 GPU 配置的总吞吐量为 240.48 tok/s,优于八 GPU 配置的 227.90 tok/s。批次大小为 1 时的单用户吞吐量则几乎相同(22.37 tok/s vs. 22.83 tok/s)。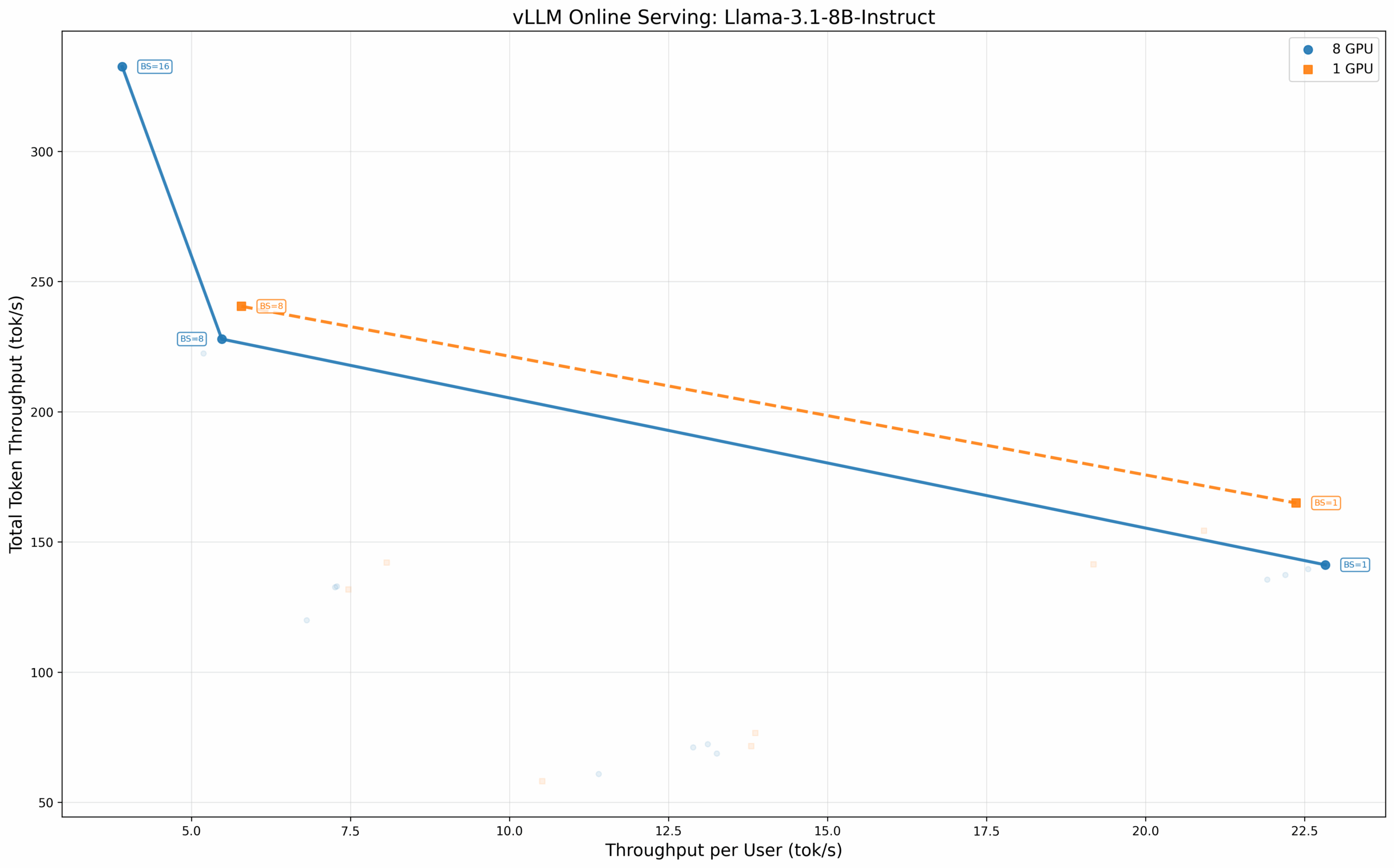
Mistral Small 3.1 240亿参数 Instruct 模型
240 亿参数的 Mistral 模型代表了要求更高的工作负载。在 BF16 精度下,该模型在较高批次大小时展现了良好的吞吐量扩展能力,在批次大小为 256 时,八 GPU 配置的总吞吐量达到 574.16 tok/s。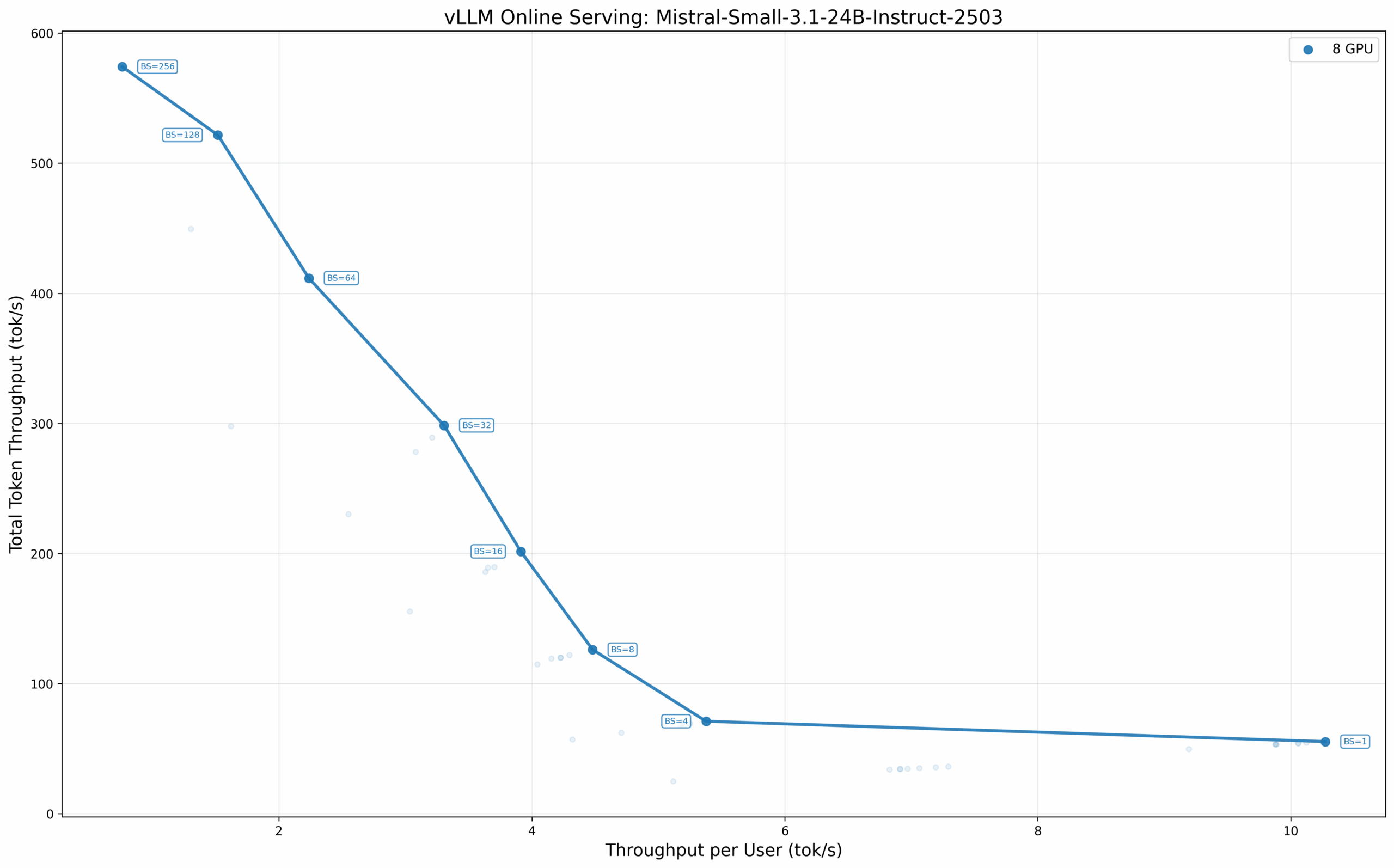
核心发现
所有测试模型均呈现出一个一致规律:在我们的测试配置(256个输入/输出令牌)下,对于低批次大小场景,使用恰好能容纳模型的最少 GPU 数量,其单用户性能优于将模型分布到全部八个 GPU 上。即使拥有 PCIe 5.0 的高带宽,GPU 间通信引入的延迟开销,在单用户或低并发场景下,也超过了并行计算带来的收益。
这一发现对实际部署具有指导意义。运行单用户编码助手或低并发智能体工作流的组织,可以采用较小的 GPU 配置来获得可接受的性能。而完整的八 GPU Battlematrix 系统,其最大优势在于批量推理、合成数据生成或高并发在线服务等场景,这些场景更看重总吞吐量而非单请求延迟,尤其是在运行需要大量显存的大型模型时。
总结
英特尔 Arc Pro B60 Battlematrix 是一个令人兴奋的平台,它以工作站的价位,实现了对大容量 GPU 显存的便捷获取。其双芯显卡设计巧妙解决了密度难题,每 GPU 24GB 的显存配置精准契合了 LLM 推理的需求,而极具竞争力的定价则为成熟的专业 GPU 生态系统提供了一个强有力的价值替代选项。对于将数据主权和成本效率置于绝对性能之上的组织,该平台值得认真考量。
在有限的测试过程中,体验出乎意料的顺畅。硬件安装和驱动配置简单,设置支持 Battlemage 的 vLLM 开发分支(LLM-Scaler)也相当直接。当然,软件生态的成熟度仍是当前的主要瓶颈。 不过,英特尔通过 LLM Scaler 等项目对框架优化的持续投入,以及不断的驱动程序更新,表明了其长期耕耘 Arc 系列 GPU 生态、打造高价值解决方案的决心。
八 GPU Battlematrix 完整配置与英伟达 DGX Spark 等顶级方案的性能对决尚属未知。但真正的亮点或许在于其单卡和双卡配置:600至1200美元的入门价位,极大地降低了企业和开发者探索私有 AI 基础设施的门槛。
我们将持续关注驱动程序更新和软件框架的演进,并开展进一步的测试,敬请期待~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 29
29 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)