大模型注意力综述(1)Efficient Attention Mechanisms for Large Language Models: A Survey
高效注意力机制综述:线性与稀疏方法助力长序列建模 本文系统梳理了Transformer架构中自注意力机制的优化方法,重点解决其二次复杂度带来的计算瓶颈。研究聚焦两大技术路线:线性注意力通过核近似、循环公式或快速权重实现线性复杂度;稀疏注意力则采用固定模式、块状路由或聚类策略减少计算量。文章详细分析了各类方法的算法原理、硬件适配性及其在大规模预训练模型中的应用,包括纯高效架构与混合设计。通过连接理论
论文地址:Efficient Attention Mechanisms for Large Language Models: A Survey
摘要
基于Transformer的架构已成为大语言模型的主流骨干。然而,自注意力机制的二次时间与内存复杂度,仍然是实现高效长上下文建模的根本障碍。为解决这一局限,近期研究引入了两大类高效注意力机制。线性注意力方法通过核近似、循环公式或快速权重动态实现线性复杂度,从而以降低的计算开销实现可扩展推理。相比之下,稀疏注意力技术将注意力计算限制在基于固定模式、块状路由或聚类策略选择的词元子集上,在保持上下文覆盖的同时提升效率。本综述对这些进展进行了系统而全面的概述,整合了算法创新与硬件层面的考量。此外,我们分析了高效注意力如何被整合到大规模预训练语言模型中,包括完全基于高效注意力的架构以及结合了局部与全局组件的混合设计。通过将理论基础与实际部署策略相结合,本工作旨在为推进可扩展且高效的语言模型设计提供基础性参考。
一、介绍
基于Transformer的架构[60]已成为现代大语言模型事实上的骨干网络选择。尽管它们取得了成功,但标准的自注意力机制仍然是一个显著的计算瓶颈,其时间和内存复杂度相对于输入序列长度呈二次方增长。这一限制对LLM扩展到处理更长上下文,同时保持强大性能和高效率,构成了重大挑战。
为解决此问题,出现了两个主要方向来降低softmax注意力的时间和空间复杂度。第一种机制是线性注意力[17, 22, 49, 52, 69, 71],它试图通过将softmax注意力重新参数化或近似为线性操作来降低注意力复杂度。第二种候选方案是稀疏注意力[8, 21, 33, 55, 72],它将注意力计算限制在基于固定或动态稀疏模式的完整键空间的子集上。虽然两种方法都旨在提高效率,但它们在公式化、设计选择和硬件影响方面存在显著差异。
本综述全面回顾了高效注意力机制的最新发展,同时关注算法原理和系统级实现。基于此,我们还研究了采用这些高效注意力的预训练LLM。
我们将线性注意力方法分为三大范式。首先,核化线性注意力 使用特征空间中的内积来近似softmax核,通过随机特征映射[9, 41]或固定正定映射[22]实现线性复杂度。其次,带遗忘机制的循环线性注意力 引入了位置感知的循环,通过数据无关[52]或数据相关的衰减[17, 69]实现长序列建模,这些衰减控制着过去信息如何随时间消退。第三,快速权重和基于元学习的公式 将线性注意力重新解释为在线优化的记忆更新过程,其中如DeltaNet[49, 71]和TTT[50, 51]等模型将快速学习动态直接纳入状态演化中。我们还研究了线性注意力的硬件友好表示——包括并行、循环和分块形式——重点介绍了它们在计算复杂度、内存占用以及与训练或推理工作流的兼容性方面各自的权衡。
我们将稀疏注意力分为固定模式稀疏性、块稀疏性和基于聚类的稀疏性。固定模式稀疏性采用静态的词元级掩码,如滑动窗口、膨胀位置或指定的全局词元,提供了简单性和硬件友好性[4, 8, 14, 64]。块稀疏性在块粒度上选择或路由注意力,或者通过启发式评分[33, 55, 65],或者通过可训练的门控[15, 72]实现,从而支持结构化的内存访问和高效的GPU利用率。基于聚类的稀疏性使用基于内容或位置感知的分组方法(如k-means或LSH)来组织键值对,有助于以减少的内存开销实现语义感知的检索[7, 24, 31]。最后,我们还讨论了双向稀疏设计将稀疏模式扩展到编码器风格的模型。这些方法在稀疏粒度、选择机制以及与硬件原语(如FlashAttention[10])的适配性方面有所不同,共同代表了现代Transformer中高效长上下文建模的基础。
近期有努力将高效注意力机制整合到工业级预训练语言模型中。这些包括纯高效架构——例如线性注意力和状态空间模型,以及结合了局部和全局注意力模式的混合设计。像EAGLE[38]、Falcon Mamba[78]和MiniCPM4[57]这样的模型展示了纯线性或稀疏方法在数十亿参数规模上的可扩展性,提供了强大性能与恒定时间推理。同时,混合模型[5, 26, 28, 32, 53, 56, 66]交错使用稠密、稀疏和局部注意力,以平衡计算效率与上下文建模能力,反映了现代LLM中朝着组合式、硬件感知的注意力设计发展的趋势。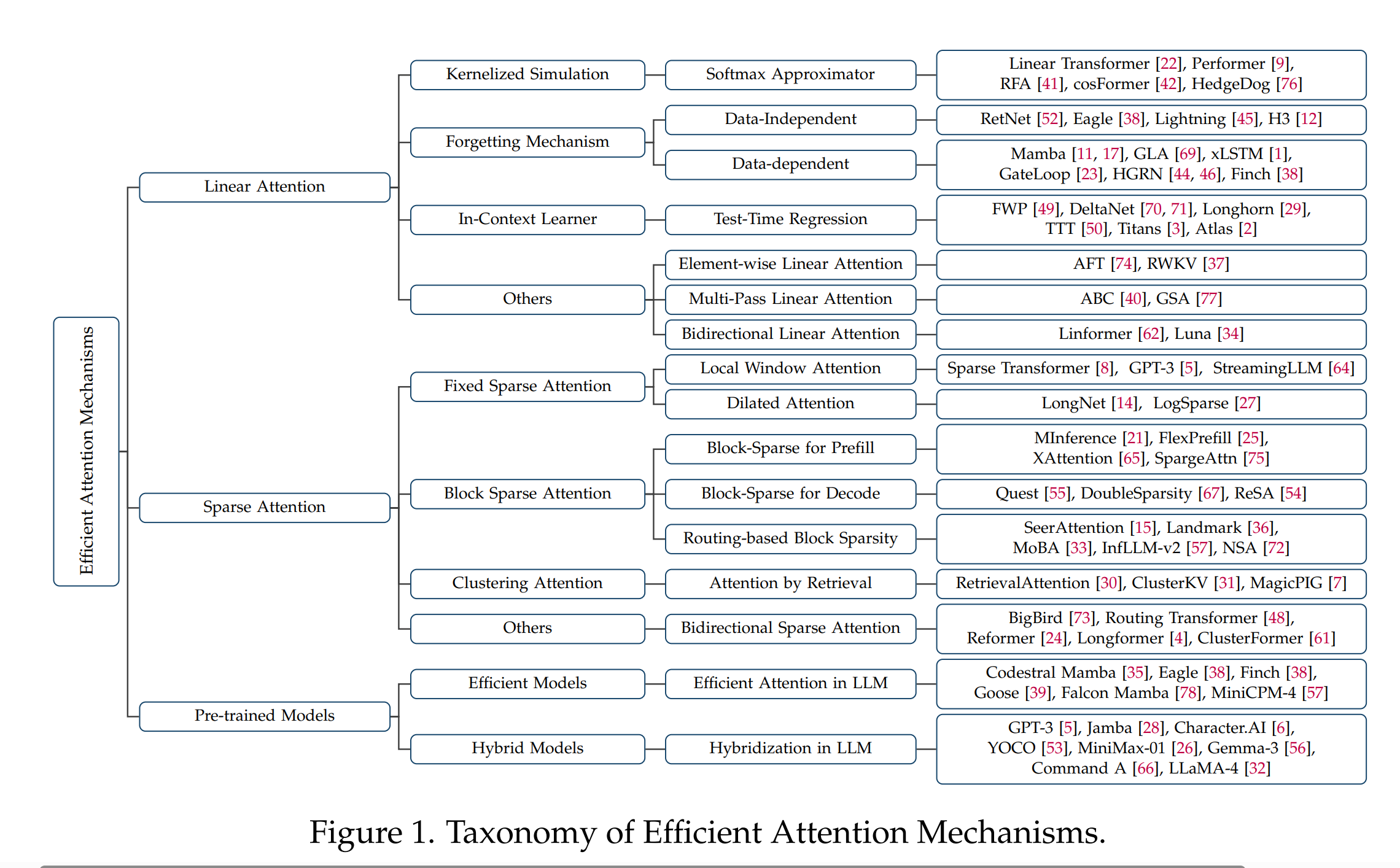
我们的目标是提供一个统一的框架,用于理解在算法和硬件约束下注意力机制的演变,以及这些设计如何被整合到可扩展的LLM架构中。通过将理论见解与实际实现联系起来,我们希望本综述能为致力于高效和可部署模型设计的研究人员和实践者提供有价值的参考。
为组织本综述,我们将讨论安排如下:
- 第2节介绍线性注意力,涵盖其在不同模型世代中的演变、相关的设计原理以及对硬件实现的影响。
- 第3节介绍稀疏注意力,对稀疏模式进行分类,分析部署场景,并提供实用的系统级设计建议。
- 第4节回顾了包含高效注意力机制的预训练语言模型,包括统一的高效架构以及整合了局部、稀疏和稠密注意力的混合模型。
- 第5节对未来方向进行了展望,讨论了算法和硬件对齐研究中的开放性挑战和潜在进展。
简要总结
本段是一篇关于高效注意力机制综述论文的引言部分,系统性地概述了文章的结构、分类和核心内容。
-
问题背景:再次强调Transformer自注意力的二次复杂度是LLM处理长上下文的核心瓶颈。
-
两大技术路线:明确区分了线性注意力和稀疏注意力两大主流解决方案,并指出它们在方法和硬件影响上存在本质不同。
-
线性注意力的三大范式(核心分类1):
- 核化线性注意力:通过数学上的核近似来模拟Softmax,实现线性化。
- 循环线性注意力:引入带遗忘机制的循环结构,适用于流式长序列处理。
- 快速权重/元学习线性注意力:将注意力视为动态内存的在线更新过程。
- 还讨论了这些方法在硬件上的不同实现形式(并行、循环、分块)及其权衡。
-
稀疏注意力的三大类型(核心分类2):
- 固定模式稀疏:使用预设的、静态的注意力模式(如局部窗口、膨胀窗口、全局词元)。
- 块稀疏:在更大的块粒度上选择注意力区域,通常依赖评分或可学习门控。
- 基于聚类的稀疏:根据语义相似性(如k-means, LSH)动态地对词元进行分组,只关注相关组。
- 同样考虑了与硬件优化(如FlashAttention)的适配性。
-
在预训练模型中的应用:
- 介绍了业界如何将高效注意力用于构建实际的大模型。
- 分为纯高效架构(完全基于线性或状态空间模型)和混合架构(结合稠密、稀疏、局部等多种注意力)。
-
文章目标与结构:
- 目标:提供一个统一框架,连接算法理论与硬件实践,指导可扩展LLM的设计。
- 结构:清晰列出了后续章节(线性注意力、稀疏注意力、预训练模型、未来展望)。
核心思想:这篇综述的引言展现了该领域研究的系统化和成熟化。它不仅仅是罗列方法,而是从根本原理上对高效注意力进行了清晰的分类学构建,并始终强调算法与硬件的协同设计。这为读者理解和比较各种复杂技术提供了一个强大的心智模型和导航图。
2. 线性注意力机制
2.1 核化线性注意力机制
传统线性注意力方法旨在以与序列长度呈线性缩放的方式逼近基于softmax的注意力机制。其核心思想是使用基于核的注意力权重逼近方法替代计算开销较大的softmax运算。在标准自注意力机制中,每个输出都是值向量𝑉的加权和,权重由查询-键相似度的softmax函数给出:
Attn ( Q , K , V ) = softmax ( Q K ⊤ ) V (1) \text{Attn}(Q, K, V) = \text{softmax}(QK^\top)V \tag{1} Attn(Q,K,V)=softmax(QK⊤)V(1)
其中,𝑄、𝐾、𝑉 ∈ ℝ(𝐿×𝑑)(𝐿为序列长度,𝑑为每个注意力头的模型维度)。对于查询向量𝑞_𝑖和键向量𝑘_𝑗,softmax函数产生的权重与exp(𝑞_𝑖⊤𝑘_𝑗)成正比。而核化线性注意力机制则通过寻找一个特征映射𝜙(·),使得softmax核可以通过诱导特征空间中的简单点积来逼近:exp(𝑞^⊤𝑘) ≈ 𝜙(𝑞)^⊤𝜙(𝑘) [59]。基于该特征映射𝜙,注意力机制可重写为:
O = ϕ ( Q ) ( ϕ ( K ) ⊤ V ) ϕ ( Q ) ( ϕ ( K ) ⊤ 1 ) (2) O = \frac{\phi(Q) \left( \phi(K)^\top V \right)}{\phi(Q) \left( \phi(K)^\top \mathbf{1} \right)} \tag{2} O=ϕ(Q)(ϕ(K)⊤1)ϕ(Q)(ϕ(K)⊤V)(2)
由于exp(·)的值域为非负,𝜙(·)通常被设计为输出非负值;同时,为了模拟softmax概率分布,还引入了归一化除数。这种重构将计算复杂度从𝑂(𝐿²𝑑)降低至𝑂(𝐿𝑑²)(若采用合适的特征降维方法,复杂度可进一步降至𝑂(𝐿𝑑)),原因是无需显式构建计算开销巨大的𝐿×𝐿维度注意力矩阵。
Linear Transformer [22] 使用固定的正特征映射替代softmax核。在实际应用中,其设置𝜙(𝑥) = ELU(𝑥) + 1。ELU(·)函数在整个定义域内可微,相比朴素的ReLU(·)函数表现更优。
Performer [9] 提出了FAVOR+——一种无偏逼近softmax核的随机特征方案。该方法通过采样随机特征映射𝜙,使得𝔼[𝜙(𝑄)𝜙(𝐾)⊤] = exp(𝑄𝐾⊤),仅需𝑂(𝑁)次运算即可得到全softmax注意力的可证明无偏估计量。具体而言,Performer采用正正交随机特征,以减少逼近过程中的方差。
Random Feature Attention(RFA)[41] 是基于softmax核的随机傅里叶特征构建的线性注意力机制。与Performer类似,RFA利用随机映射和三角激活函数逼近softmax;此外,RFA在随机投影前对查询向量和键向量进行归一化处理,以进一步降低方差。RFA还存在一个变体RFA-Gate,其增加了可选的门控机制以实现近期偏差(recency bias)。
cosFormer [42] 提出使用余弦函数逼近softmax核。基于三角恒等式cos(𝑎+𝑏) = cos𝑎cos𝑏 − sin𝑎sin𝑏,cosFormer将余弦重加权注意力𝑆_𝑖𝑗 = 𝑄’_𝑖𝐾’_𝑗 cos(𝜋/2 × (𝑖−𝑗)/𝑀)分解为线性注意力形式。
HedgeDog [76] 采用尖峰核(spiky kernel)𝜙(𝑥) = exp(𝑊𝑥 + 𝑏),其研究发现Transformer与Linear Transformer之间的性能差距源于后者缺乏尖峰特性和单调性。HedgeDog在注意力熵和单调性方面表现更优。
简要总结
该段落聚焦核化线性注意力机制,核心是通过核函数逼近替代传统自注意力的softmax运算,解决其𝑂(𝐿²)的高复杂度问题,实现与序列长度的线性缩放(复杂度降至𝑂(𝐿𝑑²)或更低)。
关键要点如下:
- 核心逻辑:通过特征映射𝜙(·)将查询-键相似度的指数运算(exp)转化为特征空间的点积,避免显式构建大尺寸注意力矩阵;
- 设计原则:特征映射需保证输出非负(匹配exp值域),并通过归一化模拟softmax概率分布;
- 代表性方法:
- Linear Transformer:使用ELU+1的固定正特征映射;
- Performer:基于随机特征的无偏逼近,采用正正交特征降低方差;
- RFA:结合随机傅里叶特征与归一化,变体支持门控机制;
- cosFormer:利用余弦函数分解注意力,转化为线性形式;
- HedgeDog:采用尖峰核,优化注意力熵和单调性。
本质是通过核逼近、随机特征、函数分解等技术,在降低计算复杂度的同时,尽可能保留传统softmax注意力的性能。
2.2 带遗忘机制的线性注意力机制
近期的一类研究从循环神经网络(RNN)或连续状态空间模型(state-space models)的视角解读注意力机制。传统线性注意力机制通常不具备位置感知能力——循环顺序不会影响输出结果,而现代线性注意力机制则更接近具备状态跟踪和隐藏记忆的RNN。因此,这类模型明确融入了循环、门控或状态动态特性,以线性复杂度处理长序列。衰减因子是实现遗忘机制的核心要素。
2.2.1 数据无关衰减(Data-Independent Decay)
Retentive Networks(RetNet)[52] 提出了一种记忆保留机制(retention mechanism),通过固定衰减系数的循环式更新替代注意力运算。在RetNet层中,每个时间步𝑡会维护一个状态向量𝑠_𝑡,该向量通过指数遗忘聚合历史输入信息。其循环关系可表示为:
S t = γ S t − 1 + k t ⊤ v t (3) S_t = \gamma S_{t-1} + k_t^\top v_t \tag{3} St=γSt−1+kt⊤vt(3)
其中,𝛾 ∈ (0, 1) 是一个可学习的衰减因子(每个记忆头对应一个),𝑘_t^\top v_t 是当前token的新贡献(𝑣_𝑡是输入𝑥_𝑡的值投影,𝑘_𝑡是键投影)。输出通过线性“查询”投影得到:𝑜_𝑡 = 𝑞_𝑡 · 𝑠_𝑡(·表示点积)。展开公式(3)可得到记忆保留的显式表达式:
o t = q t S t = ∑ n = 1 t γ t − n q t k t ⊤ v t (4) o_t = q_t S_t = \sum_{n=1}^t \gamma^{t-n} q_t k_t^\top v_t \tag{4} ot=qtSt=n=1∑tγt−nqtkt⊤vt(4)
该式表明,到时间步𝑡时,第𝑛个token的贡献会被因子𝛾^(𝑡−𝑛)进行指数衰减。关键在于,𝛾是数据无关衰减——它是该层的固定参数(多头记忆中通常每个头对应一个),而非输入内容的函数。这使得RetNet具备类似RNN的𝑂(1)记忆更新特性,同时通过等价的矩阵形式支持训练时的并行计算(例如,可证明公式(3)等价于“记忆矩阵”形式:Retention(𝑋) = (𝑄𝐾⊤ ⊙ 𝐷)𝑉,其中𝐷_𝑡,𝑛 = 𝛾^(𝑡−𝑛)(𝑡 ≥ 𝑛)实现衰减和因果掩码)。
RetNet的记忆保留机制与其他数据无关循环模型存在共性:
- Eagle [38] 基于外积记忆改进了RWKV的设计,其本质等价于线性注意力机制。在RWKV系列中,衰减因子被参数化为𝛾 = exp(−exp(𝑤)),其中𝑤是数据无关的可学习因子。
- 实践中,RetNet和Eagle均通过固定衰减遗忘旧信息,实现了线性推理复杂度和具有竞争力的性能。RetNet为每个头设置固定标量𝛾(通常每层包含多个记忆头,各头𝛾值不同,形成多尺度衰减),而Eagle通过可学习标量𝑤参数化衰减因子。
Lightning Attention [43, 45] 同样提出了一种线性注意力层,为每个头配备固定标量衰减,以实现与序列长度无关的计算速度。其隐藏状态更新本质上为𝑠_𝑡 = 𝜆𝑠_𝑡−1 + 𝑘_t^\top v_t(𝜆为模型学习或设定的常数),与RetNet的𝛾设计思路一致,但更优化了硬件效率。
H3 [12] 将循环状态空间模型(SSM)[18] 引入线性注意力,通过SSM实现可学习的、数据无关的指数衰减,用于键值外积隐藏状态。尽管线性注意力可通过分块计算实现高效训练,但H3的SSM计算需要显式状态扩展,因此限制了头维度,导致模型表达能力受限。
综上,数据无关衰减方法通过预设速率维护随时间衰减的持久状态,实现了𝑂(1)循环更新和每步恒定内存占用,但牺牲了部分适应性——这也推动了近期模型中数据相关机制的引入。
2.2.2 数据相关衰减(Data-Dependent Decay)
固定衰减虽简洁高效,但可能无法充分利用输入流中的信息。门控或数据相关方法将遗忘因子本身设计为当前输入的可学习函数。这类循环更新的一般形式为:
S t = G t S t − 1 + k t ⊤ v t (5) S_t = G_t S_{t-1} + k_t^\top v_t \tag{5} St=GtSt−1+kt⊤vt(5)
其中,𝑆_𝑡−1是前一状态,𝐺_𝑡是由token 𝑥_𝑡决定的门控张量。若𝐺_𝑡的某一分量接近0,则该分量对应的历史状态在时间步𝑡被大幅遗忘;若𝐺_𝑡≈1,则历史状态被保留。与RetNet中固定的𝛾不同,此处𝐺_𝑡通过𝑥_𝑡随时间步𝑡动态变化。在大语言模型设计中,该策略的两个典型代表是Mamba [11, 17] 和门控线性注意力(Gated Linear Attention, GLA)[69]。
- Mamba是一种循环状态空间模型,其状态衰减率具备输入依赖性。每个Mamba层的基础状态演化与S4 [18] 类似,但状态矩阵被设计为动态可调。𝐺_𝑡是一个取值范围在0~1的分组向量,作为动态遗忘门,弥合了注意力机制与纯SSM之间的差距。实证结果表明,Mamba2在语言建模任务上可超越规模相当甚至更大的Transformer,凸显了数据相关衰减在长序列建模中的优势。
- GLA直接在线性注意力中引入门控机制,将门控函数嵌入线性化注意力层以提升表达能力,通过可学习的逐元素遗忘门𝐺_𝑡修改记忆循环过程。
此外,还有多个模型采用了类似的内容相关门控循环设计:
- xLSTM [1] 用门信号的指数变换(含归一化)替代标准sigmoid遗忘门,实现对细胞状态的平滑、输入条件化衰减。
- GateLoop [23] 基于记忆保留机制应用头级门控,在维持高效硬件实现的同时,实现了简单有效的数据相关衰减。
- HGRN [44] 在线性RNN中引入门控循环,HGRN2 [46] 进一步在框架中添加状态扩展(等价于线性注意力中的键值外积)。
- Finch [38] 在Eagle基础上采用数据相关门控,由于Eagle与记忆保留机制(Retention)存在关联且包含其他正交改进,Finch与上述模型也存在深度联系。
综上,数据相关衰减模型通过基于内容的门控增强线性注意力或RNN式架构,实现对信息流动的精准控制。论文结果表明,这类模型在语言任务上通常能达到甚至超越Transformer的性能,同时可扩展至极长输入序列。
简要总结
该段落围绕“带遗忘机制的线性注意力”展开,核心是通过衰减因子实现对历史信息的选择性遗忘,在保持线性复杂度的同时提升长序列建模能力,分为两大技术路线:
1. 数据无关衰减(固定衰减)
- 核心特点:衰减因子是模型固定参数(或数据无关的可学习参数),不依赖输入内容,统一遗忘历史信息。
- 代表模型:RetNet(多尺度固定𝛾)、Eagle(参数化固定衰减)、Lightning Attention(硬件优化的固定衰减)、H3(SSM实现的固定衰减)。
- 优势:计算简单(𝑂(1)循环更新)、内存高效、支持并行训练;劣势:适应性有限,无法根据输入内容动态调整遗忘策略。
2. 数据相关衰减(动态门控)
- 核心特点:遗忘因子是输入内容的可学习函数(通过门控张量𝐺_𝑡实现),动态决定保留/遗忘历史信息。
- 代表模型:Mamba(动态遗忘门+SSM)、GLA(线性注意力门控)、xLSTM(指数变换门控)、GateLoop(头级门控)等。
- 优势:适应性强,能根据输入内容灵活调整遗忘策略,长序列建模性能更优;劣势:相比固定衰减,计算复杂度略有提升,但仍保持线性缩放。
核心结论
遗忘机制是现代线性注意力的关键创新:数据无关衰减追求高效简洁,数据相关衰减追求性能与适应性,两者均实现了“线性复杂度+长序列处理”的目标,且数据相关衰减模型在语言任务中已展现出超越Transformer的潜力。
2.3 作为上下文学习器的线性注意力机制
线性注意力机制除了能提升计算效率外,另一项重大突破在于其可用于强化上下文学习能力。上下文学习指模型无需对预训练权重进行显式梯度更新,就能根据给定提示词快速适配并学习相关知识的能力。
大型Transformer模型本身就具备上下文学习能力,它会将提示词当作一种训练数据来解读。而近期的技术创新则直接将快速学习规则融入注意力机制,把序列处理过程切实转化为在线训练过程。快速权重编程器(FWP)[49] 证明了现有线性注意力机制与快速权重编程器之间存在正式的等价关系。在快速权重编程器范式中,一个慢速神经网络负责对另一个网络的“快速权重”进行编程,其实现方式通常是借助自主生成的键值模式的加性外积。本节将以元学习的视角,探讨DeltaNet[70,71]、Longhorn[29]、测试时训练层(TTT)[50,51]、Titans[3]等多个代表性模型。这些模型通过快速权重更新等机制,成为了线性注意力机制用作上下文学习器的典型范例。 Table 1. Update rule among different Linear Attention variants. Each model is a recurrence on matrix memory 𝑆𝑡
Table 1. Update rule among different Linear Attention variants. Each model is a recurrence on matrix memory 𝑆𝑡
.
2.3.1 学习目标
从元学习的角度来看,这类模型设定了推理过程中需优化的隐性学习目标。设𝑞_𝑡、𝑘_𝑡、𝑣_𝑡分别为时间步𝑡的查询向量、键向量和值向量,上下文记忆𝑆_𝑡通过如下目标函数进行优化:
L t ( S ) = 1 2 ∥ f S ( k t ) − v t ∥ 2 (6) L_t(S) = \frac{1}{2}\left\|f_S(k_t) - v_t\right\|^2 \tag{6} Lt(S)=21∥fS(kt)−vt∥2(6)
DeltaNet融入了经典的增量规则,其中映射关系满足𝑓_𝑆(𝑘_𝑡)=𝑆𝑘_𝑡。它的更新规则为Font metrics not found for font: .,该规则通过最小化当前记忆检索结果 𝑆 𝑡 − 1 𝑘 𝑡 𝑆_{𝑡−1}𝑘_𝑡 St−1kt与新值 𝑣 𝑡 𝑣_𝑡 vt之间的误差推导得出。这一设计标志着模型朝着在线学习键值映射的方向迈进,能够依据即时上下文对记忆内容进行有效优化。
测试时训练(TTT)[51]通过不同的建模架构对元学习目标进行了泛化,其映射关系定义如下:
f S ( k t ) = { LN ( S k t ) + k t , TTT-线性型 LN ( MLP S ( k t ) ) + k t , TTT-多层感知机型 (7) f_S(k_t) = \begin{cases} \text{LN}(Sk_t) + k_t, & \text{TTT-线性型} \\ \text{LN}\left(\text{MLP}_S(k_t)\right) + k_t, & \text{TTT-多层感知机型} \end{cases} \tag{7} fS(kt)={LN(Skt)+kt,LN(MLPS(kt))+kt,TTT-线性型TTT-多层感知机型(7)
其中的上下文网络 𝑓 𝑆 𝑓_𝑆 fS增强了模型的上下文元学习能力。但由于 𝑓 𝑆 𝑓_𝑆 fS的梯度计算远比简单线性投影复杂,因此无法用简洁的规则来描述其在线更新过程。
- 批量更新:当 𝑓 𝑆 𝑓_𝑆 fS以神经网络形式工作时,批量更新可解决训练并行性方面的难题。通常情况下,上下文记忆的元学习批量大小为1,这对通用测试时训练模型来说并不适用。对此,测试时训练借鉴了分块并行的思路,将一整个数据块视为一个批次。在批次内不更新模型状态(即 𝑆 𝑆 S保持恒定),待批次处理完成后,再利用该批次中所有样本的累积梯度或更新信号对 𝑆 𝑆 S执行一次更新。这种策略既能保证并行计算的效率,又能满足复杂架构的训练需求。
- 动量机制:Titans[3]引入了优化领域常用的动量机制,以此强化记忆更新能力,其相关公式如下:
{ M t = ( 1 − α t ) M t − 1 + S t o t = q t M t (8) \begin{cases} M_t = (1 - \alpha_t)M_{t-1} + S_t \\ o_t = q_tM_t \end{cases} \tag{8} {Mt=(1−αt)Mt−1+Stot=qtMt(8)
这一动量项通过对状态 𝑆 𝑆 S做指数移动平均,实现记忆的逐步累积。从元学习的角度来讲,该机制能让更新规则在长序列处理过程中逐渐变得更稳定、更稳健。 - 权重衰减:权重衰减是训练过程中的另一种正则化技术,它与线性注意力模型中的遗忘机制相对应。门控型DeltaNet[70]和Titans在记忆更新过程中引入了权重衰减机制,将其作为可学习的遗忘门,以此削弱陈旧数据或含噪数据带来的影响。这与RetNet[52]、Mamba[17]等架构中的选择性状态保留机制原理相通,而实践已证明这种衰减机制对提升语言建模性能至关重要,其对应的更新公式为:
S n = γ n S t − 1 + η t ( v t − S t − 1 k t ) k t ⊤ (9) S_n = \gamma_nS_{t-1} + \eta_t(v_t - S_{t-1}k_t)k_t^\top \tag{9} Sn=γnSt−1+ηt(vt−St−1kt)kt⊤(9)
综上,这些线性注意力机制的创新之处在于,将元学习原理明确融入模型架构,从而拓展了上下文学习的边界。借助快速权重更新、复杂的记忆管理技术以及在线学习规则,这类模型正逐步打破训练与推理之间的明确界限。这一变革推动出效率更高、适应性更强的大型语言模型,使其能够直接从上下文信息中学习并运用知识。
简要总结
该段落核心是阐述线性注意力机制如何以元学习为核心支撑,成为高效的上下文学习器,核心要点如下:
- 核心定位:线性注意力机制不只是提升计算效率,更关键的是能强化上下文学习能力,且多个模型已验证其与快速权重编程器的等价性,可通过快速权重更新实现上下文学习。
- 核心学习目标:通过最小化记忆检索结果与新值的误差优化上下文记忆 𝑆 𝑆 S,不同模型围绕该目标衍生出差异化优化策略。
- 四大关键优化手段
- 增量规则(DeltaNet):通过经典增量规则推导记忆更新公式,实现键值映射的在线学习与记忆优化;
- 批量更新(TTT):以数据块为批次处理数据,平衡并行计算效率与复杂架构的训练需求;
- 动量机制(Titans):通过指数移动平均累积记忆,提升长序列处理时更新规则的稳定性;
- 权重衰减(Gated DeltaNet、Titans):模拟遗忘机制过滤无效数据,与主流模型的状态保留机制相通,保障语言建模性能。
- 核心价值:此类模型通过融合元学习理念,模糊了训练与推理的边界,让大型语言模型无需复杂权重调整,就能直接从上下文中高效学习知识,大幅提升了模型的适应性与实用性。
2.4 其他设计方案探讨
2.4.1 逐元素线性注意力机制
无注意力Transformer(Attention-Free Transformer, AFT)[74]采用了一种简洁的权重项 e x p ( K t ′ + w t , t ′ ) exp(K_{t^\prime} + w_{t,t^\prime}) exp(Kt′+wt,t′),以此替代传统的 e x p ( Q K ⊤ ) exp(QK^\top) exp(QK⊤),其输出公式如下:
O t = σ q ( Q t ) ⊙ ∑ t ′ = 1 t e x p ( K t ′ + w t , t ′ ) ⊙ V t ′ ∑ t ′ = 1 t e x p ( K t ′ + w t , t ′ ) (10) O_t = \sigma_q(Q_t) \odot \frac{\sum_{t^\prime=1}^t exp(K_{t^\prime} + w_{t,t^\prime}) \odot V_{t^\prime}}{\sum_{t^\prime=1}^t exp(K_{t^\prime} + w_{t,t^\prime})} \tag{10} Ot=σq(Qt)⊙∑t′=1texp(Kt′+wt,t′)∑t′=1texp(Kt′+wt,t′)⊙Vt′(10)
其中, w t , t ′ w_{t,t^\prime} wt,t′是可学习的成对位置偏置。在无注意力Transformer的各类变体中,简化版无注意力Transformer(AFT-Simple)移除了 w t , t ′ w_{t,t^\prime} wt,t′,实现了线性化的推理模式。由于键(K)和值(V)的运算为逐元素运算,其循环状态维度为 R d R^d Rd,而非外积状态对应的 R d × d R^{d×d} Rd×d。
循环权重知识向量(RWKV)[37]在简化版无注意力Transformer的基础上加入了衰减机制。具体来说,该模型通过指数衰减公式 w t , i = − ( t − i ) w w_{t,i}=-(t - i)w wt,i=−(t−i)w改进了无注意力Transformer的位置偏置。这种指数形式的设计,既能保留模型的循环特性,又能有效融入位置偏置信息。
逐元素线性注意力机制具备显著的推理优势,但同时存在状态维度受限的问题,其性能表现不及基于矩阵的状态维度设计。此外,尽管逐元素记忆的运算速度远超外积记忆,但整体端到端的性能提升却十分有限。这是因为在采用外积记忆的模型中,其他组件的耗时占比超过了95%[52],逐元素记忆带来的速度提升被大幅抵消。
2.4.2 多轮线性注意力机制
有限记忆控制注意力机制(Attention with Bounded - memory Control, ABC)将线性注意力机制视作一个有限记忆模块,其计算公式如下:
{ K ~ n = ∑ i = 1 n K i ⊗ ϕ i V ~ n = ∑ i = 1 n V i ⊗ ϕ i O n = s o f t m a x ( Q n K ~ n ⊤ ) V ~ n (11) \begin{cases} \tilde{K}_n = \sum_{i=1}^n K_i \otimes \phi_i \\ \tilde{V}_n = \sum_{i=1}^n V_i \otimes \phi_i \\ O_n = softmax(Q_n\tilde{K}_n^\top)\tilde{V}_n \end{cases} \tag{11} ⎩
⎨
⎧K~n=∑i=1nKi⊗ϕiV~n=∑i=1nVi⊗ϕiOn=softmax(QnK~n⊤)V~n(11)
式中, K ~ n \tilde{K}_n K~n和 V ~ n \tilde{V}_n V~n是在线更新的、维度受限的键向量与值向量。在实际应用时,该机制可简化为两轮线性注意力机制。
门控槽注意力机制(Gated Slot Attention, GSA)[77]进一步将门控线性注意力(GLA)融入有限记忆控制注意力机制框架[40]之中。由于 K ~ n \tilde{K}_n K~n和 V ~ n \tilde{V}_n V~n本质上构成了隐性的线性注意力机制,门控槽注意力机制将门控形式引入参数更新过程,优化后的公式如下:
{ K ~ n = D i a g ( α n ) K ~ n − 1 + ( 1 − α n ) ⊗ K n V ~ n = D i a g ( α n ) V ~ n − 1 + ( 1 − α n ) ⊗ V n (12) \begin{cases} \tilde{K}_n = Diag(\alpha_n)\tilde{K}_{n - 1} + (1 - \alpha_n) \otimes K_n \\ \tilde{V}_n = Diag(\alpha_n)\tilde{V}_{n - 1} + (1 - \alpha_n) \otimes V_n \end{cases} \tag{12} {K~n=Diag(αn)K~n−1+(1−αn)⊗KnV~n=Diag(αn)V~n−1+(1−αn)⊗Vn(12)
多轮线性注意力机制是提升线性注意力表达能力的有效手段,但它也会带来额外的计算开销。这使得模型架构设计需要在训练效率与模型性能之间做出权衡。
2.4.3 双向线性注意力机制
双向注意力机制在BERT[13]等编码器式架构中发挥着关键作用。单向与双向注意力机制在线性表达式上的核心差异,体现在推理瓶颈和计算模式两个方面。纯编码器模型的计算复杂度通常为 O ( N 2 ) O(N^2) O(N2),而且模型中的每个标记都能获取全局信息。因此,双向线性注意力机制往往会设置一个固定长度的全局标记池,这样既能保留softmax函数的使用,又能降低计算复杂度。
例如,线性Transformer(Linformer)[62]通过额外的矩阵投影操作,将键向量和值向量的数量压缩至固定长度。月神模型(Luna)[34]则对线性Transformer的设计进行了拓展,在模型的各层中对全局标记池进行编码处理。
尽管双向线性注意力机制对纯编码器架构十分适用,但将其应用于因果场景时却面临巨大挑战。这是因为基于全局池化的方法计算成本过高,所以这类架构并不适用于大型语言模型。
简要总结
该部分围绕线性注意力机制的三类特殊设计展开,分别分析了各类设计的核心逻辑、代表模型、优势与局限,具体要点如下:
- 逐元素线性注意力机制
- 核心思路:通过键和值的逐元素运算简化计算,调整位置偏置设计适配模型需求。
- 代表模型:AFT(成对可学习位置偏置)、AFT - Simple(移除位置偏置实现线性推理)、RWKV(添加指数衰减优化位置偏置)。
- 优势:推理速度快,循环状态维度小;局限:状态维度受限导致性能不及矩阵型设计,端到端性能提升不明显。
- 多轮线性注意力机制
- 核心思路:以多轮运算强化线性注意力的表达能力,部分融入门控机制优化更新过程。
- 代表模型:ABC(简化为两轮线性注意力的有限记忆模块)、GSA(给ABC加入门控机制改进更新规则)。
- 优势:能有效提升线性注意力的表达能力;局限:增加了计算开销,需在训练效率和性能间做权衡。
- 双向线性注意力机制
- 核心思路:通过固定长度的全局标记池,在保留softmax函数的同时降低纯编码器模型的计算复杂度。
- 代表模型:Linformer(矩阵投影压缩键值长度)、Luna(跨层编码全局标记池)。
- 优势:适配纯编码器架构,可让标记获取全局信息;局限:基于全局池化的方式计算成本高,难以适配因果场景和大型语言模型。
核心结论
这三类设计从不同维度优化了线性注意力机制,但均存在取舍:逐元素设计追求推理效率却牺牲部分性能,多轮设计提升表达能力却增加计算成本,双向设计适配编码器却不适用于大型语言模型。这些设计为不同场景下的模型选型提供了多样化方向,具体需结合场景的效率、性能需求灵活选择。
2.5 硬件实现
并行表示法
我们将带门控衰减的因果线性注意力机制定义如下:
Q = ϕ ( X W Q ) Q = \phi(XW_Q) Q=ϕ(XWQ), K = ϕ ( X W K ) K = \phi(XW_K) K=ϕ(XWK), V = X W V V = XW_V V=XWV, γ = f γ ( X ) \gamma = f_\gamma(X) γ=fγ(X)
D n m = { ∏ i = m + 1 n γ i , n ≥ m 0 , n < m D_{nm}= \begin{cases} \prod_{i=m+1}^n \gamma_i, & n \geq m \\ 0, & n < m \end{cases} Dnm={∏i=m+1nγi,0,n≥mn<m, O ( X ) = L N ( ( Q K ⊤ ⊙ D ) V ) O(X) = LN((QK^\top \odot D)V) O(X)=LN((QK⊤⊙D)V) (公式13)
其中, W Q W_Q WQ、 W K W_K WK、 W V W_V WV均为 d × d d×d d×d维矩阵,函数 f γ f_\gamma fγ用于控制衰减的速率。 N × N N×N N×N维矩阵 D D D对含衰减模式的因果掩码进行编码,以此保障信息的单向流动。
当衰减与数据无关时, f γ ( ⋅ ) f_\gamma(·) fγ(⋅)为介于 ( 0 , 1 ] (0,1] (0,1]区间内的常数。需要说明的是,在线性注意力机制之后添加组归一化层已是必不可少的操作,因此公式2中核化线性注意力机制所采用的显式分母便无需额外设置。
这种并行表示法简洁易懂,但存在两个缺陷。其一,该形式仍保持着平方级的计算复杂度,与基于softmax的注意力机制一致;其二,在表示2.3节中指令遵循式线性注意力机制时,其计算复杂度还会进一步增加。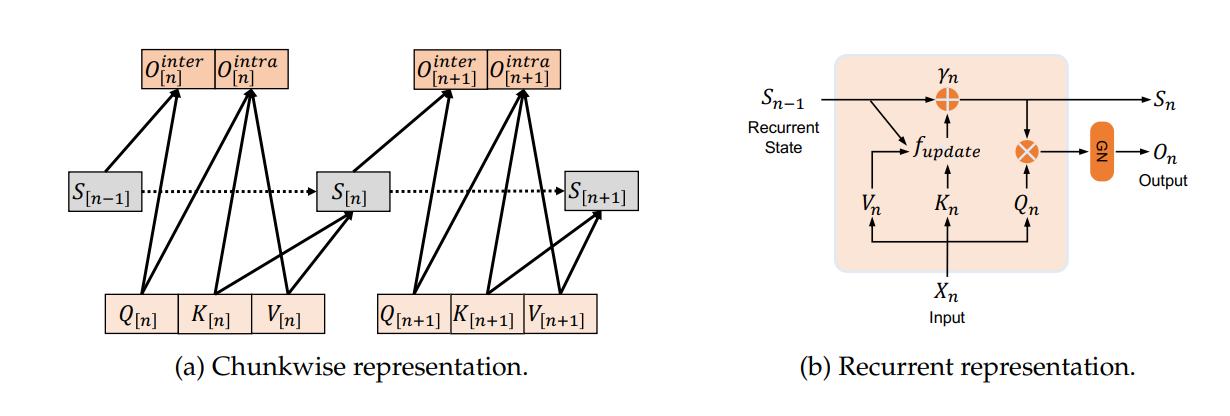
Figure 2. Dual form of Linear Attention.
循环表示法
上述并行表达式可等价转化为适用于逐步骤解码的循环表示形式(如图2b所示)。在每个时间步 n n n,输出结果计算方式如下:
S n = f u p d a t e ( S n − 1 , K n , V n ) S_n = f_{update}(S_{n-1}, K_n, V_n) Sn=fupdate(Sn−1,Kn,Vn), O n = Q n S n O_n = Q_nS_n On=QnSn
f u p d a t e ( S n − 1 , K n , V n ) = { γ n S n − 1 + K n ⊤ V n , 带衰减的线性注意力机制 γ n S n − 1 + η n ( V n − S n − 1 K n ) K n ⊤ , 指令遵循式线性注意力机制 f_{update}(S_{n-1}, K_n, V_n)= \begin{cases} \gamma_nS_{n-1} + K_n^\top V_n, & \text{带衰减的线性注意力机制} \\ \gamma_nS_{n-1} + \eta_n(V_n - S_{n-1}K_n)K_n^\top, & \text{指令遵循式线性注意力机制} \end{cases} fupdate(Sn−1,Kn,Vn)={γnSn−1+Kn⊤Vn,γnSn−1+ηn(Vn−Sn−1Kn)Kn⊤,带衰减的线性注意力机制指令遵循式线性注意力机制 (公式14)
该循环表示法通过维护单个状态向量 S n S_n Sn,能够以恒定内存占用实现高效的自回归生成。尽管它将计算复杂度从平方级降至线性级,但在训练过程中会产生巨大的内存开销。这是因为状态向量 S n S_n Sn需要存储键向量 K n K_n Kn与值向量 V n V_n Vn的外积,这种存储开销对于长序列而言是难以承受的。因此,循环表示法通常仅适用于解码阶段。
分块循环表示法
分块循环表示法兼具线性复杂度与硬件友好型并行计算的双重优势。如图2a所示,以带衰减的线性注意力机制为例,设定块大小为 B B B,用 x [ i ] x[i] x[i]表示第 i i i个数据块,块内累积衰减量定义如下:
β ( i − 1 ) B + j = ∏ k = ( i − 1 ) B + 1 ( i − 1 ) B + j γ k \beta_{(i-1)B+j} = \prod_{k=(i-1)B+1}^{(i-1)B+j}\gamma_k β(i−1)B+j=∏k=(i−1)B+1(i−1)B+jγk, D [ i ] ( j , k ) = { β ( i − 1 ) B + k β ( i − 1 ) B + j , j ≤ k 0 , 其他情况 D[i]_{(j,k)}= \begin{cases} \frac{\beta_{(i-1)B+k}}{\beta_{(i-1)B+j}}, & j \leq k \\ 0, & \text{其他情况} \end{cases} D[i](j,k)={β(i−1)B+jβ(i−1)B+k,0,j≤k其他情况 (公式15)
块级记忆状态 R i R_i Ri的计算方式为:
R i = K [ i ] ⊤ ( V [ i ] ⊙ β i B β [ i ] ) + β i B R i − 1 R_i = K[i]^\top\left(V[i] \odot \frac{\beta_{iB}}{\beta[i]}\right) + \beta_{iB}R_{i-1} Ri=K[i]⊤(V[i]⊙β[i]βiB)+βiBRi−1 (公式16)
第 i i i个数据块的输出结果为:
O [ i ] = ( Q [ i ] K [ i ] ⊤ ⊙ D [ i ] ) V [ i ] + ( Q [ i ] R i − 1 ) ⊙ β [ i ] O[i] = (Q[i]K[i]^\top \odot D[i])V[i] + (Q[i]R_{i-1}) \odot \beta[i] O[i]=(Q[i]K[i]⊤⊙D[i])V[i]+(Q[i]Ri−1)⊙β[i] (公式17)
该表达式将循环计算与并行计算进行了统一:第一项用于捕捉块内各元素间的依赖关系,第二项则通过单次矩阵向量乘法传递块间记忆信息。凭借高效性与可并行性,分块循环表示法常用于模型的训练阶段与预填充阶段。
针对指令遵循式线性注意力机制,研究人员借助豪斯霍尔德变换构建了适配硬件的分块循环表示法。但对于张量列车变换、泰坦架构等更为复杂的变体模型,构建明确的分块形式仍面临较大挑战。这类架构通常会通过设置较大的批次规模来完成内存更新,依靠固定超参数间接模拟分块计算过程。
核级优化是保障模型高性能运行的关键。被广泛应用的快速线性注意力库为众多常用线性注意力模块提供了基于特里顿语言的实现方案;此外,开发者还提供了基于统一计算设备架构或瓦片编程语言的自定义实现方式,可进一步提升模型运行速度。
核心内容总结
该部分围绕线性注意力机制的硬件落地,提出了并行、循环、分块循环三种表示法,同时提及核级优化手段,以此平衡计算复杂度、内存开销与硬件适配性,具体要点如下:
-
并行表示法
特性 具体说明 核心优势 形式简洁,易于理解,适配基础并行计算场景 主要缺陷 计算复杂度为 O ( N 2 ) O(N^2) O(N2),与传统softmax注意力机制一致;适配指令遵循式线性注意力时复杂度会额外增加 关键作用 为注意力机制提供基础的硬件实现数学表达 -
循环表示法
特性 具体说明 核心优势 将计算复杂度降至 O ( N ) O(N) O(N),通过单状态向量实现恒定内存占用的自回归生成 主要缺陷 训练时需存储键值向量外积,长序列场景下内存开销极大 适用场景 仅适配模型解码阶段,满足逐步骤生成的高效计算需求 -
分块循环表示法
特性 具体说明 核心优势 融合线性复杂度与并行计算能力,通过分块拆分块内、块间依赖,兼顾计算效率与硬件适配性 适用场景 适配训练与预填充阶段,是兼顾性能与开销的主流硬件实现方式 局限 难以适配张量列车变换等复杂架构,需通过批次规模调整间接模拟分块逻辑 -
核级优化
为进一步提升硬件运行效率,主流优化路径包括依托快速线性注意力库的特里顿语言实现方案,以及基于统一计算设备架构、瓦片编程语言的自定义开发方案,以此适配不同硬件的计算特性,最大化挖掘硬件算力。
3. 稀疏注意力机制
稀疏注意力机制利用注意力计算中固有的稀疏特性,通过以下公式逼近全注意力机制:
Attn ( Q , K , V ) = softmax ( Q K ⊤ [ S ] ) V [ S ] (18) \text{Attn}(Q, K, V) = \text{softmax}(QK^\top[S])V[S] \tag{18} Attn(Q,K,V)=softmax(QK⊤[S])V[S](18)
其中, S ( t ) S(t) S(t) 是查询向量 Q ( t ) Q(t) Q(t) 所关注的索引子集。不同方法会设计差异化的 S ( t ) S(t) S(t) 选择准则,同时兼顾选择准确性与硬件效率,最终在预填充阶段(prefilling)将计算复杂度降至亚线性或线性,或在解码阶段(decoding)控制固定计算开销。
3.1 固定模式稀疏注意力机制
部分研究利用标记级稀疏性的结构化模式,构建固定模式的稀疏掩码用于注意力计算。
局部窗口注意力(Local Window Attention)
局部窗口注意力将每个查询的交互范围限制在固定大小的滑动窗口 w w w 内的相邻标记,在保留局部上下文信息的同时,降低了内存占用和计算量。
- 稀疏Transformer(Sparse Transformer)[8] 首次采用局部窗口(行)注意力,其中窗口大小 w w w 接近 N \sqrt{N} N,随后通过额外的列注意力补充全局信息传播,汇总历史位置信息。
- GPT-3 [5] 同样采用了与稀疏Transformer类似的稀疏注意力模式。
- StreamingLLM [64] 发现输入序列中大量注意力分数会分配给初始标记(称为“注意力槽”(attention sink)),因此提出一种简单的固定模式注意力机制:仅保留注意力槽标记和滑动窗口内的标记。例如,对于长度为 n n n 的输入序列,StreamingLLM中查询标记 q t q_t qt 对应的选中标记子集 S ( t ) S(t) S(t) 定义为:
S ( t ) = { j ∣ 0 ≤ j ≤ s ∨ t − w ≤ j ≤ t } , ∀ t ∈ [ 1 , n ] (19) S(t) = \{ j \mid 0 \leq j \leq s \lor t - w \leq j \leq t \}, \forall t \in [1, n] \tag{19} S(t)={j∣0≤j≤s∨t−w≤j≤t},∀t∈[1,n](19)
其中, s s s 为注意力槽标记数量, w w w 为滑动窗口大小。为提升硬件效率,块粒度的StreamingLLM [19] 以块为单位保留注意力槽标记和局部标记,实现高效的内存加载与计算。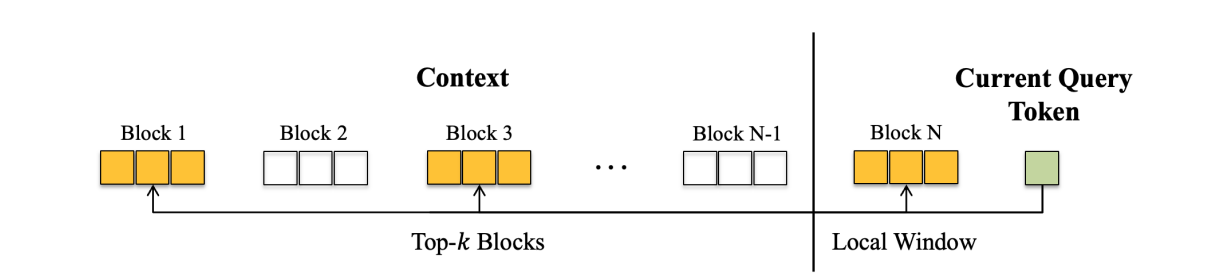
Figure 3. Block-sparse attention: the long sequence is divided into several blocks, and each
token attends only to its local window and the top-k related blocks.
扩张注意力(Dilated Attention)
LongNet [14] 引入扩张注意力作为长上下文训练与推理的固定稀疏模式。该机制随着距离增长呈指数级扩大注意力范围,将注意力复杂度从 O ( n 2 ) O(n^2) O(n2) 降至 O ( n ) O(n) O(n)。具体实现如下:
- 沿序列维度将输入划分为长度为 w w w 的段;
- 从每个段中以间隔 r r r 选择扩张稀疏索引,第 i i i 段的选中索引为:
I ^ i = [ i w , i w + r , i w + 2 r , . . . , ( i + 1 ) w − 1 ] (20) \hat{I}_i = [iw, iw + r, iw + 2r, ..., (i+1)w - 1] \tag{20} I^i=[iw,iw+r,iw+2r,...,(i+1)w−1](20) - 将稀疏化后的段 Q I ^ i Q_{\hat{I}_i} QI^i、 K I ^ i K_{\hat{I}_i} KI^i、 V I ^ i V_{\hat{I}_i} VI^i( i ∈ { 0 , 1 , . . . , n w } i \in \{0, 1, ..., \frac{n}{w}\} i∈{0,1,...,wn})并行输入注意力层,得到注意力输出 O O O;
- 结合不同段大小和扩张率 { r i , w i } k \{r_i, w_i\}_k {ri,wi}k 的注意力输出,最终注意力计算为:
O = ∑ i = 1 K α i O ∣ r i , w i , α i = s i ∑ j s j (21) O = \sum_{i=1}^K \alpha_i O|_{r_i, w_i}, \quad \alpha_i = \frac{s_i}{\sum_j s_j} \tag{21} O=i=1∑KαiO∣ri,wi,αi=∑jsjsi(21)
其中, s i s_i si 表示 O ∣ r i , w i O|_{r_i, w_i} O∣ri,wi 对应的注意力softmax分母(即归一化因子)。
LogSparse [27] 采用指数级稀疏注意力方案,每个位置仅关注 l o g N logN logN 个标记,可视为指数扩张注意力的一种实例。
简要总结
该部分聚焦固定模式稀疏注意力机制,核心是通过预设的结构化稀疏掩码筛选查询关注的标记子集,在保留关键上下文的同时降低计算复杂度,关键要点如下:
1. 核心设计逻辑
- 本质:通过固定规则(如窗口范围、扩张间隔、注意力槽选择)定义标记交互的稀疏模式,避免全注意力的 O ( n 2 ) O(n^2) O(n2) 复杂度;
- 目标:平衡性能(保留局部/全局关键信息)与效率(亚线性/线性复杂度、硬件友好)。
2. 两类代表性方法
| 方法类型 | 核心思路 | 代表模型 | 优势 | 关键参数/公式 |
|---|---|---|---|---|
| 局部窗口注意力 | 限制查询仅与滑动窗口内的相邻标记交互,部分补充全局信息传播 | 稀疏Transformer、GPT-3、StreamingLLM | 保留局部上下文,计算/内存高效;StreamingLLM解决长序列“注意力槽”问题 | 窗口大小 w w w、注意力槽大小 s s s(公式19) |
| 扩张注意力 | 以固定间隔从各段选择标记,呈指数级扩大注意力范围,兼顾局部与远程交互 | LongNet、LogSparse | 支持超长序列( O ( n ) O(n) O(n) 复杂度),覆盖远程依赖 | 段长度 w w w、扩张间隔 r r r(公式20);多尺度融合(公式21) |
3. 核心结论
固定模式稀疏注意力通过结构化稀疏设计实现效率提升:
- 局部窗口类方法适合侧重局部上下文的场景(如通用语言建模),StreamingLLM的“注意力槽”设计进一步优化了长序列推理的稳定性;
- 扩张类方法适合需要捕捉远程依赖的超长序列场景(如长文档处理),通过多尺度扩张率融合平衡局部与全局信息;
- 两类方法均为硬件友好型设计,无需动态筛选标记,适合大规模部署,但灵活性依赖预设模式的合理性。
3.2 块稀疏注意力机制
给定长度为 n n n的输入序列和块大小 b b b,可将 Q 、 K 、 V ∈ R n × d Q、K、V ∈ ℝ^{n×d} Q、K、V∈Rn×d分别划分为 n b \frac{n}{b} bn个块,每个块的尺寸为 b × d b×d b×d。核心目标是逼近一个块级掩码 M ∈ { 0 , 1 } n b × n b M ∈ \{0,1\}^{\frac{n}{b}×\frac{n}{b}} M∈{0,1}bn×bn,用于筛选需参与计算的关键块(如图3所示)。注意力计算如下:
Attn ( Q , K , V ) i = ∑ j = 1 n b M i j ⋅ softmax ( Q i K j T ) V j (22) \text{Attn}(Q, K, V)_i = \sum_{j=1}^{\frac{n}{b}} M_{ij} · \text{softmax}(Q_i K_j^T) V_j \tag{22} Attn(Q,K,V)i=j=1∑bnMij⋅softmax(QiKjT)Vj(22)
块级选择对现代GPU上的高效计算至关重要。
3.2.1 预填充阶段的块稀疏注意力机制
预填充阶段(prefill)的块稀疏注意力方法,通过逼近覆盖大部分注意力分数的Top-K块(保证高召回率),将注意力计算复杂度从 O ( n 2 ) O(n^2) O(n2)降至 O ( K ) O(K) O(K)。其优化目标为:
{ S = softmax ( Q K T − c ( 1 − M ) ) min ∣ S ( M ) − S dense ∣ (23) \begin{cases} S = \text{softmax}(QK^T - c(1 - M)) \\ \min |S(M) - S_{\text{dense}}| \end{cases} \tag{23} {S=softmax(QKT−c(1−M))min∣S(M)−Sdense∣(23)
其中, M M M为上述块级稀疏掩码, c c c为大常数(如 1 e 5 1e5 1e5),确保不重要的注意力权重经softmax后趋近于0。该机制的目标是在尽可能保留注意力权重信息的前提下,以最小开销实现显著加速。
- MInference [21] 发现注意力权重存在三种模式:流式(A形)模式、竖线模式和块稀疏模式。它离线为每个注意力头确定最优模式,并在推理时基于分配的模式动态构建稀疏索引。
- FlexPrefill [25] 提出上下文感知的稀疏注意力机制,可实时动态调整注意力模式和计算预算。
- XAttention [65] 提出块稀疏注意力框架,利用反对角线评分预测注意力块的重要性,能高效识别并剪枝非必要块,实现高稀疏度和显著计算收益。
- SpargeAttn [75] 同样为预填充阶段设计块级稀疏注意力,通过两阶段在线过滤实现:第一阶段快速预测注意力图以跳过部分矩阵乘法,第二阶段应用softmax感知过滤器进一步消除不必要计算。
3.2.2 解码阶段的块稀疏注意力机制
解码阶段(decode)的块稀疏注意力方法,在每个解码步骤动态选择包含最关键标记的 K 、 V K、V K、V向量子集 S S S,从而减少内存加载并提升效率。
-
Quest [55] 通过计算注意力权重的上界来逼近每个块的重要性。对于块 K i K_i Ki,它按维度逐元素维护键的最小值和最大值 m i m_i mi和 M i M_i Mi:
m i , d = min ( K i , d ) , M i , d = max ( K i , d ) (24) m_{i,d} = \min(K_{i,d}), \quad M_{i,d} = \max(K_{i,d}) \tag{24} mi,d=min(Ki,d),Mi,d=max(Ki,d)(24)
其中, min ( ⋅ ) \min(·) min(⋅)和 max ( ⋅ ) \max(·) max(⋅)对每个维度 d d d逐元素应用。给定查询 q q q,块 i i i的逼近注意力分数为:
s c o r e i = ∑ j = 1 d max ( q j × M i , j , q j × m i , j ) (25) score_i = \sum_{j=1}^d \max(q_j × M_{i,j}, q_j × m_{i,j}) \tag{25} scorei=j=1∑dmax(qj×Mi,j,qj×mi,j)(25)
随后选择分数最高的Top-K块作为稀疏子集 S S S用于注意力计算:
S = argtopk ( s c o r e , k ) (26) S = \text{argtopk}(score, k) \tag{26} S=argtopk(score,k)(26) -
DoubleSparsity [67] 通过降低 Q K T QK^T QKT乘积的矩阵乘法维度,高效逼近关键标记。它首先离线计算 Q K T QK^T QKT中的异常通道 C C C,然后基于逼近注意力分数 s ^ \hat{s} s^选择Top-K标记作为稀疏子集 S S S:
Q label = Q [ C ] , s ^ = Q label K label T , S = argtopk ( s ^ , k ) (27) Q_{\text{label}} = Q[C], \quad \hat{s} = Q_{\text{label}} K_{\text{label}}^T, \quad S = \text{argtopk}(\hat{s}, k) \tag{27} Qlabel=Q[C],s^=QlabelKlabelT,S=argtopk(s^,k)(27) -
ReSA [54] 结合无训练块稀疏估计与GQA(分组查询注意力)共享,进一步提升效率;此外,ReSA还引入校正阶段以控制KV缓存累积误差,在长序列生成任务中表现出优势。
3.2.3 基于路由的块稀疏注意力机制
基于路由的块稀疏注意力机制通过可训练的MLP层学习每个标记块的重要性,该MLP层在推理时充当门控网络,筛选关键块。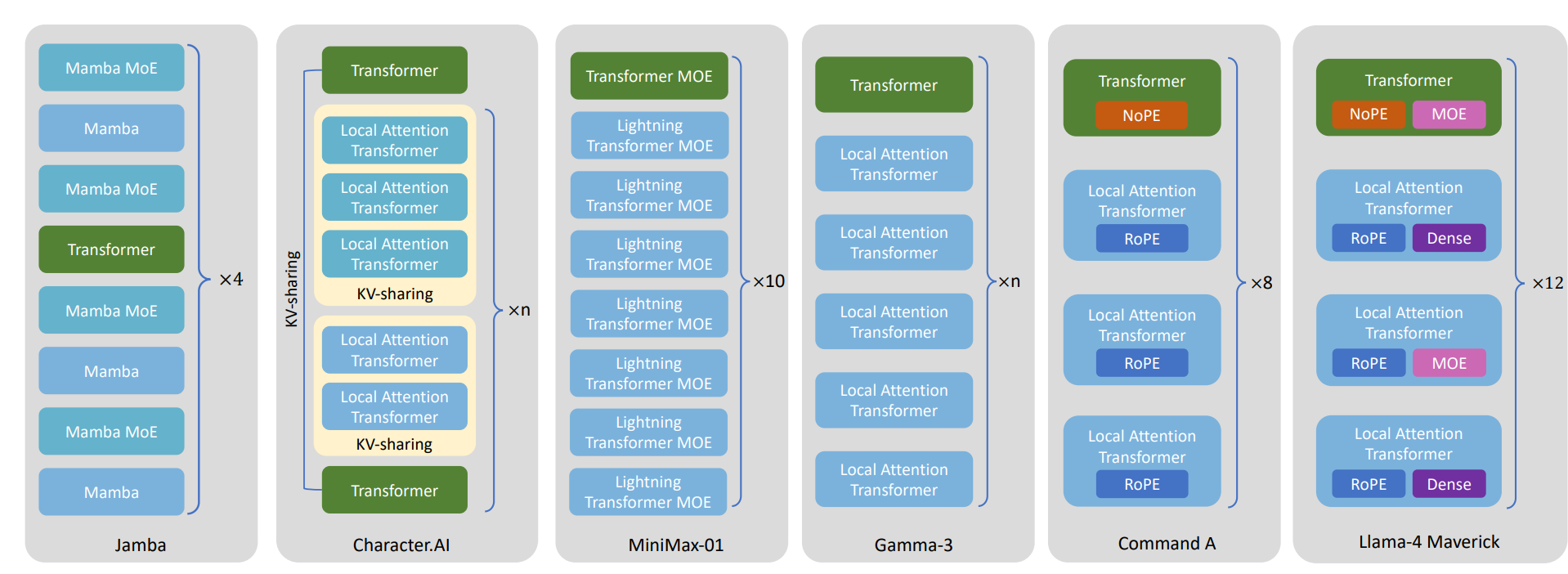
Figure 4. Architecture of different stacked models.
预训练模型上的可学习稀疏性
- SeerAttention [15,16] 通过自蒸馏方式在预训练LLM上训练门控网络。为获取每个块的重要性分数,它首先对 Q Q Q和 K K K沿序列维度进行池化(记为 P k P_k Pk和 P q P_q Pq),然后将下采样后的 Q 、 K Q、K Q、K输入可学习线性层 W q W_q Wq和 W k W_k Wk;投影后的 W q P q ( Q ) W_q P_q(Q) WqPq(Q)与 W k P k ( K ) W_k P_k(K) WkPk(K)的矩阵乘积经softmax操作作为门控过程:
s c o r e = softmax ( ( W q P q ( Q ) ) ⋅ ( W k P k ( K ) ) ) (28) score = \text{softmax}((W_q P_q(Q)) · (W_k P_k(K))) \tag{28} score=softmax((WqPq(Q))⋅(WkPk(K)))(28)
可学习线性层通过自蒸馏方式训练,以对齐原始LLM的2D最大池化结果,蒸馏损失计算为:
g t = MaxPool2D ( softmax ( Q K T ) ) , l o s s = D K L ( g t ∥ s c o r e ) gt = \text{MaxPool2D}(\text{softmax}(QK^T)), \quad loss = D_{KL}(gt \parallel score) gt=MaxPool2D(softmax(QKT)),loss=DKL(gt∥score)
推理时,门控分数通过Top-K或阈值筛选预测块级稀疏性,实现稀疏计算与效率提升。
训练感知的稀疏注意力
- Landmark [36] 提出使用特殊的“地标标记”(landmark tokens)代表每个块,并训练注意力机制通过这些地标标记直接检索Top-K块,但未在大规模预训练模型上进行实验。
- MoBA [33] 将可训练稀疏注意力融入预训练阶段,提出“块注意力混合体”(Mixture of Block Attention):借鉴MoE(混合专家模型)的Top-K机制作为门控,决定每个查询标记的关键块。块的重要性分数通过查询标记 q q q与块 K i K_i Ki沿标记维度的均值池化结果的内积计算:
s i = ⟨ q , P mean ( K i ) ⟩ (29) s_i = \langle q, P_{\text{mean}}(K_i) \rangle \tag{29} si=⟨q,Pmean(Ki)⟩(29)
随后选择分数最高的Top-K块用于 q q q的注意力计算。值得注意的是,MoBA的Top-K块选择不具备可微性,因此预训练阶段仍以无训练模式估计稀疏模式,兼顾高效推理与加速训练。 - NSA [72] 引入训练感知的混合粒度稀疏注意力机制,包含三个分支 C ∈ { c m p (压缩) , s l c (选择) , w i n (滑动窗口) } C ∈ \{cmp(压缩), slc(选择), win(滑动窗口)\} C∈{cmp(压缩),slc(选择),win(滑动窗口)}。NSA利用可微压缩分支学习块选择分数,最终注意力输出为:
o = ∑ c ∈ C g c ⋅ Attn ( q , K c , V c ) , g c ∈ [ 0 , 1 ] (30) o = \sum_{c∈C} g_c · \text{Attn}(q, K_c, V_c), \quad g_c ∈ [0,1] \tag{30} o=c∈C∑gc⋅Attn(q,Kc,Vc),gc∈[0,1](30)
对于压缩分支 c = c m p c=cmp c=cmp,块 i i i的键 K i ∈ R d k × b K_i ∈ ℝ^{d_k×b} Ki∈Rdk×b通过可学习MLP层 ϕ \phi ϕ压缩为单个键 K i cmp ∈ R d k × 1 K_i^{\text{cmp}} ∈ ℝ^{d_k×1} Kicmp∈Rdk×1;对于选择分支 c = s l c c=slc c=slc,基于块重要性分数 p p p(直接来自压缩分支)选择Top-K块。 - InfLLM-v2 [57] 采用与MoBA类似的训练感知Top-K块稀疏注意力机制;为提升Top-K块选择准确性,它将块划分为带重叠的小粒度核,并对每个块内的核重要性分数进行聚合。
3.2.4 系统级设计选择
训练感知稀疏注意力机制[33,57,72]开始考虑核实现与高效执行。为高效实现块稀疏注意力,通常采用FlashAttention [10] 的高效分块(tiling)机制进行注意力计算,这对硬件资源的优化利用提出了要求并带来了机遇,包括:
- 为避免内存访问不一致,SeerAttention [15] 和MInference [21] 中将块大小 b b b通常设置为较大值(至少64);
- 为匹配GPU张量核心上分组矩阵乘法(Grouped Matrix Multiplication)指令的最小要求,NSA [72] 和InfLLM-v2 [57] 中将查询组内的KV头数量设置为至少16;
- 为减少内存访问,NSA [72] 和InfLLM-v2 [57] 强制查询组间共享选中的块,具体通过对查询组内的块级重要性分数进行池化实现。
简要总结
该部分详细阐述块稀疏注意力机制的设计与应用,核心是将序列划分为固定大小的块,通过筛选关键块降低计算/内存开销,按应用阶段和设计思路分为四大类,关键要点如下:
1. 核心设计逻辑
- 本质:以“块”为单位进行稀疏筛选(而非单个标记),适配GPU的分块计算特性,平衡稀疏性与硬件效率;
- 目标:在预填充(降低 O ( n 2 ) O(n^2) O(n2)至 O ( K ) O(K) O(K))和解码(减少KV缓存加载)阶段均实现高效计算,同时保留关键注意力信息。
2. 四大技术分支
| 分支类型 | 应用场景 | 核心思路 | 代表模型 | 关键创新/优势 |
|---|---|---|---|---|
| 预填充块稀疏注意力 | 预填充阶段 | 离线/动态预测关键块,高召回率覆盖重要注意力分数 | MInference、FlexPrefill、XAttention、SpargeAttn | 适配长序列预填充,支持动态调整模式/预算 |
| 解码块稀疏注意力 | 解码阶段 | 动态计算块重要性上界/逼近分数,筛选关键KV块 | Quest、DoubleSparsity、ReSA | 减少解码时KV缓存加载,ReSA解决缓存累积误差 |
| 基于路由的块稀疏注意力 | 预训练+推理 | 可训练门控网络/蒸馏学习块重要性,支持混合粒度筛选 | SeerAttention、MoBA、NSA、InfLLM-v2 | 稀疏模式可学习,适配预训练模型,NSA支持多策略融合 |
| 系统级设计 | 工程实现 | 优化块大小、KV头数量、块共享策略,适配GPU硬件特性 | 基于FlashAttention的衍生设计 | 解决内存访问不一致、硬件指令适配问题,提升落地效率 |
3. 关键技术亮点
- 块级筛选:相比单标记稀疏,块稀疏更适配GPU分块计算,减少内存访问开销;
- 多阶段适配:预填充阶段侧重高召回率,解码阶段侧重动态高效,路由式侧重可学习性;
- 硬件感知设计:通过调整块大小、KV头数量、块共享等策略,最大化GPU张量核心利用率;
- 训练与推理平衡:MoBA、NSA等通过非可微筛选或混合分支,兼顾预训练效率与推理性能。
4. 核心结论
块稀疏注意力机制通过“块级稀疏+硬件适配”实现高效计算,覆盖预填充和解码全流程:
- 预填充阶段通过高召回率块筛选降低长序列计算复杂度;
- 解码阶段通过动态块选择减少KV缓存开销;
- 路由式设计通过可学习门控提升稀疏模式的适应性,系统级优化确保硬件高效执行;
- 该机制已成为LLM长序列处理的核心优化方向之一,在兼顾性能与效率方面表现突出。
3.3 聚类注意力机制
与块稀疏注意力机制类似,聚类注意力机制(Clustering Attention)的核心目标是为解码阶段筛选最关键的标记,但通过特定数据结构对标记进行组织,以提升语义关联性或采样效率。
- RetrievalAttention [30]:采用近似最近邻搜索(Approximate Nearest Neighbor Search, ANNS)选择关键的K个聚类。为解决注意力机制中查询向量与键向量的分布外(out-of-distribution)问题,该方法引入了一种注意力感知的向量搜索算法,能够动态适配查询向量的分布特性。
- ClusterKV [31]:以语义聚类为粒度选择标记,克服了Quest等页面级检索方法存在的内部碎片问题。在预填充阶段后,通过K-means算法对标记进行聚类;标记𝑖与𝑗的语义相似度通过键向量的余弦相似度衡量,定义为:
D ( i , j ) = 1 − ⟨ k i , k j ⟩ ∣ k i ∣ ⋅ ∣ k j ∣ D(i,j) = 1 - \frac{\langle k_i, k_j \rangle}{|k_i| \cdot |k_j|} D(i,j)=1−∣ki∣⋅∣kj∣⟨ki,kj⟩
(其中 ⟨ ⋅ , ⋅ ⟩ \langle \cdot, \cdot \rangle ⟨⋅,⋅⟩表示向量内积, ∣ ⋅ ∣ | \cdot | ∣⋅∣表示向量模长)。语义聚类通过其质心 μ 1 , μ 2 , . . . , μ C ∈ R d \mu_1, \mu_2, ..., \mu_C ∈ ℝ^d μ1,μ2,...,μC∈Rd表示。在每个解码步骤,基于查询标记 q q q与聚类质心 μ i \mu_i μi的注意力权重(即 q μ i T q\mu_i^T qμiT)排序选择聚类。 - MagicPIG [7]:利用局部敏感哈希(Locality Sensitive Hashing, LSH)采样高效逼近注意力计算。它通过LSH将相似的查询向量和键向量映射到同一个哈希桶,并将存储和部分计算卸载到CPU,以缓解KV缓存瓶颈;此外,该方法还引入了“Oracle Top-K采样”策略,相比暴力Top-K采样更具效率优势。
3.4 双向稀疏注意力机制
双向稀疏注意力机制基于编码器式架构构建,通过静态模式或块级稀疏性加速注意力计算,适配双向上下文建模需求。
块级稀疏性在双向稀疏注意力中应用广泛:
- BigBird [73]:采用块级随机注意力,通过随机块连接作为“桥梁”缩短标记间的间接路径,提升双向信息传递效率;
- Longformer [4]:采用静态全局-局部混合注意力,同样依赖块级稀疏性,并额外添加全局链接和随机链接,既支持结构化计算,又能实现内存高效的并行处理。
聚类类方法也被应用于双向稀疏注意力:
- Reformer [24]:利用局部敏感哈希(LSH)将相似标记分配到同一个桶中,减少无关标记间的交互;
- Routing Transformer [48]:每层执行在线K-means聚类,动态分组相关标记;
- ClusterFormer [61]:引入可微聚类模块,与下游任务目标联合训练,提升聚类对任务的适应性。
这些方法通过将语义相关的标记分组减少计算量,同时借助可学习的适应性保留模型性能,实现双向注意力的高效计算。
核心总结
该部分聚焦两类稀疏注意力的细分方向——聚类注意力(面向解码阶段) 和双向稀疏注意力(面向编码器架构),核心是通过“标记的结构化组织”提升稀疏筛选的效率与语义精准度,关键要点如下:
1. 聚类注意力机制(解码阶段优化)
| 模型名称 | 核心技术手段 | 核心优势 | 解决的关键问题 |
|---|---|---|---|
| RetrievalAttention | ANNS + 注意力感知向量搜索 | 适配查询-键向量分布差异,检索精度高 | 查询与键的分布外(OOD)问题 |
| ClusterKV | K-means聚类(余弦相似度度量)+ 质心排序 | 语义粒度合理,避免页面级检索的内部碎片 | 块级检索的标记分布碎片化问题 |
| MagicPIG | LSH哈希映射 + CPU卸载 + Oracle Top-K采样 | 缓解KV缓存瓶颈,采样效率优于暴力Top-K | 解码阶段KV缓存存储压力与采样低效问题 |
2. 双向稀疏注意力机制(编码器架构适配)
| 技术路线 | 代表模型 | 核心设计 | 核心目标 |
|---|---|---|---|
| 块级稀疏 + 混合链接 | Longformer(全局-局部混合)、BigBird(随机块链接) | 块级稀疏降低复杂度,全局/随机链接保障双向信息传递 | 编码器双向建模的高效计算 |
| 聚类分组 + 可学习适配 | Reformer(LSH分桶)、Routing Transformer(在线K-means)、ClusterFormer(可微聚类) | 相似标记分组减少计算,可学习聚类提升任务适应性 | 兼顾双向语义关联性与计算效率 |
3. 核心结论
- 聚类注意力:通过ANNS、K-means、LSH等聚类/检索技术,将标记按语义或相似度结构化组织,既保证关键信息不丢失,又提升采样效率,是解码阶段KV缓存优化的重要方向;
- 双向稀疏注意力:针对编码器的双向全局信息需求,结合块稀疏性或聚类技术,在降低 O ( n 2 ) O(n^2) O(n2)复杂度的同时,通过全局链接、可微聚类等设计保留双向交互能力,适配BERT类架构的长序列处理;
- 共性逻辑:两类方法均摒弃了“无差别稀疏筛选”,转而通过“语义结构化”提升稀疏性的合理性——在效率提升的同时兼顾语义关联性,是稀疏注意力机制从“单纯降复杂度”向“精准降复杂度”演进的核心趋势。
这段文本聚焦采用高效注意力机制的预训练大语言模型,分为纯高效注意力模型和混合高效注意力模型两类,下面为你提供精准翻译和核心要点提炼,方便快速掌握不同模型的注意力机制设计逻辑:
4. 采用高效注意力机制的预训练大语言模型
4.1 采用纯高效注意力机制的预训练模型
早期线性注意力机制的研究多局限于小规模模型,而近期技术突破已实现其向百亿参数级模型的成功扩展,使其成为标准Transformer架构极具可行性的高效替代方案。这类模型完全基于线性注意力机制或其架构等效形式(如状态空间模型、循环神经网络)构建,即便扩展到大规模体量,仍能保持其标志性的推理高效性。
- 基于RWKV的模型:RWKV项目一直致力于研发具备扩展性的循环神经网络架构,该架构兼具Transformer的可并行训练特性与传统循环神经网络的高效推理能力。例如,EAGLE(RWKV - 5)系列引入矩阵值状态以提升模型容量;后续的Finch(RWKV - 6)和Goose(RWKV - 7)等版本则融入动态循环机制和高效的状态演化机制(如增量规则),从而实现更复杂、数据驱动的状态转换。
- 基于Mamba的模型:Mamba架构凭借其数据依赖选择机制大获成功,引发了各大研究机构对该架构的广泛应用与扩展研究。Falcon Mamba基于纯Mamba架构构建,在各类通用语言基准测试中展现出可媲美主流Transformer模型的性能,同时保留了固定时间复杂度的推理特性。基于Mamba - 2架构开发的Codestral Mamba则专注于代码生成领域,不仅在相关基准测试中取得顶尖成绩,还支持25.6万个标记的上下文窗口,充分印证了状态空间模型在复杂结构化领域的扩展性与实用性。
- 基于稀疏性的模型:MiniCPM - 4创新推出两阶段稀疏注意力机制,能依据语义相似度为每个查询标记动态筛选相关的键值块。该模型采用块稀疏注意力的变体InfLLM - v2替代标准注意力机制,并借助轻量级的对数求和指数近似算法实现高效的Top - K筛选,使其能够灵活适配超长序列任务。这些技术的融合,让MiniCPM - 4在兼顾细粒度上下文感知能力的同时,有效控制了内存与计算开销,成为长上下文建模的优选方案之一。
4.2 采用混合高效注意力机制的预训练模型
随着长上下文建模需求的增长以及计算范式的多样化,学界开始广泛探索混合注意力机制。这类机制融合全局与局部注意力组件,常通过交错设置专用层,在计算成本与模型性能之间寻求平衡。
- 稀疏混合模型:GPT - 3受稀疏Transformer启发,采用密集注意力层与局部带状稀疏注意力层交错排布的混合注意力机制。密集注意力层保障全上下文建模效果,稀疏层则通过固定或跨步模式减少关注标记数量。依托这一设计,GPT - 3以2048个标记的固定上下文窗口实现了模型的大规模扩展,巧妙平衡了建模能力与计算效率。
- 线性 - 全量混合模型:Jamba和MiniMax - 01通过融合线性注意力层与全量注意力层,在吞吐量与语义表达能力之间达成高效平衡。MiniMax - 01的多数层采用闪电注意力机制,每间隔8层插入基于Softmax的全量注意力层;Jamba采用相似的层级配比,每8层Mamba块中嵌入1层Transformer层。两者均通过减少高算力消耗的全量注意力层的使用,实现了更快的解码速度与更优的长序列处理性能。
- 局部 - 全量混合模型:Gemma 3、Command A和LLaMA - 4 - Maverick均采用局部注意力层与全局注意力层交替设置的结构,其核心设计思路是少用全局层(如每4 - 6层设置一次)以提升效率。三者的局部层均采用滑动窗口模式,差异主要体现在位置编码策略上:Gemma 3通过调节旋转位置编码的基准频率(局部层设为1万,全局层设为100万)增强长距离依赖捕捉能力;Command A与LLaMA - 4 - Maverick则将基于旋转位置编码的局部层与剔除位置嵌入的全量注意力层相结合,以此强化长序列建模性能。
- 进阶混合模型:Character.AI采用滑动窗口局部注意力层与稀疏全局注意力层交错的结构,每6层设置一次全局注意力层,并创新性地在多个非相邻层复用全局注意力层的键值表征。这种键值共享机制大幅降低了内存占用与延迟,助力高效长上下文处理。YOCO与Phi - 4 - mini - flash采用双解码器架构,分离预填充与生成两个阶段。自解码器在预填充和生成阶段均采用RetNet、滑动窗口注意力等线性注意力机制,交叉解码器仅在生成阶段启动。模型全程使用单层全局键值缓存,实现了线性时间复杂度的预填充,且解码过程高效,GPU内存消耗极低。
综上,近期研究趋势清晰指向注意力机制的混合化发展。各类架构为实现局部细节把控与全局上下文融合的平衡提供了独特思路,为未来注意力机制的创新奠定了坚实基础。
核心要点提炼
| 模型类别 | 代表模型 | 注意力机制设计核心 | 核心优势 |
|---|---|---|---|
| 纯高效注意力模型 | RWKV系列 | 融合Transformer并行训练与传统RNN高效推理的循环架构 | 兼顾训练效率与推理速度,迭代版本通过状态优化提升建模能力 |
| 纯高效注意力模型 | Falcon Mamba、Codestral Mamba | 基于Mamba的状态空间模型架构 | 推理速度快,Codestral Mamba适配25.6万标记长上下文,适配代码生成场景 |
| 纯高效注意力模型 | MiniCPM - 4 | 两阶段稀疏注意力+InfLLM - v2+对数求和指数近似 | 平衡长序列上下文感知与内存、计算开销 |
| 混合高效注意力模型 | GPT - 3 | 密集与局部带状稀疏注意力层交错 | 以固定窗口实现大规模扩展,平衡建模能力与计算效率 |
| 混合高效注意力模型 | Jamba、MiniMax - 01 | 线性注意力层与全量注意力层按比例交错 | 减少高算力消耗,提升解码速度与长序列性能 |
| 混合高效注意力模型 | Gemma 3、Command A等 | 局部与全局注意力层交替,差异化位置编码 | 少用全局层降低开销,通过编码优化强化长距离依赖捕捉 |
| 混合高效注意力模型 | Character.AI、YOCO等 | 键值复用、双解码器等进阶设计 | 大幅降低长上下文处理的内存与延迟,适配不同阶段的建模需求 |
5. 展望
本综述全面概述了高效注意力机制的研究现状,重点围绕其算法基础、实际落地实现以及在大规模预训练语言模型中的融合应用展开。通过将线性注意力与稀疏注意力归类为明确的技术范式,我们提炼出支撑模型可扩展性、计算效率与长上下文处理能力的核心设计原则。同时,本文还分析了这些机制在最先进(SOTA)模型中的部署方式——既可以作为独立架构存在,也可作为混合设计的组成部分,实现局部计算与全局计算的平衡。
展望未来,我们指出以下几个有望塑造该领域未来研究方向的关键议题:
混合模型的架构层面理解
尽管以往线性注意力的研究多聚焦于独立的线性架构,但混合模型的构建往往是将现成的线性注意力模块与密集型或局部型组件简单组合。然而,更强的线性骨干网络是否能直接转化为混合模型性能的提升,这一问题仍不明确。未来的研究应将混合模型视为一类独立的架构类型进行探索,深入理解其组件构成、交互效应及优化动态。
无损稀疏注意力与上下文扩展
稀疏注意力机制始终面临精度与计算收益之间的权衡挑战:完全训练的稀疏模型性能往往不及密集型模型,而训练后稀疏逼近(post-training sparse approximation)因缺乏端到端训练,也存在诸多局限。一个重要的研究前沿是开发“无损稀疏注意力机制”——在保持密集注意力的表达能力与精度的同时,能够扩展到更长的上下文长度。此外,稀疏预算(sparse budget)与上下文长度之间的关系尚未被充分理解:固定的Top-K策略在长序列场景下可能出现性能退化,因此亟需更具适应性的稀疏选择策略。
稀疏与混合注意力的机制性洞察
尽管实证研究多次表明,混合注意力模型仅需更少的注意力计算量就能达到甚至超越密集型模型的性能,但这种有效性背后的根本原因尚未被充分探究。此外,一个尤为重要的研究方向是:在合成基准测试中表现优异的稀疏模式,是否能泛化到真实世界任务中?同时,还需明确基于稀疏性的泛化能力边界。
随着基于注意力机制的模型持续演进,我们预计架构创新、理论洞察与硬件感知设计将进一步融合。我们希望本综述能为未来高效、高性能语言建模系统的研究奠定坚实基础。
核心要点提炼
1. 综述核心贡献总结
- 系统梳理了高效注意力机制的两大核心范式(线性注意力、稀疏注意力),明确其设计原则与落地路径;
- 分析了高效注意力在LLM中的两种部署模式:独立架构(纯线性/稀疏)与混合架构(融合局部/全局、密集/稀疏);
- 为该领域后续研究提供了结构化的知识框架与明确的探索方向。
2. 三大未来研究方向(关键议题+核心挑战+潜在突破点)
| 研究方向 | 核心议题 | 现存挑战 | 潜在突破点 |
|---|---|---|---|
| 混合模型的架构层面理解 | 混合模型的组件交互机制、优化逻辑;线性骨干强度与混合性能的关联 | 组件组合多为“简单拼接”,缺乏对混合架构本质的理论支撑 | 将混合模型视为独立架构类,建立组件交互的数学模型;探索自适应组件配比策略 |
| 无损稀疏注意力与上下文扩展 | 如何在保持密集注意力精度的前提下,实现长序列的高效稀疏计算;稀疏预算的动态适配 | 固定稀疏策略(如Top-K)在长序列下性能退化;无损稀疏设计缺乏理论指导 | 开发端到端训练的自适应稀疏机制;建立稀疏预算与上下文长度的量化关系模型 |
| 机制性洞察挖掘 | 混合/稀疏模型“低计算量却高性能”的内在原因;稀疏模式的泛化能力边界 | 实证结果丰富但理论解释不足;合成基准与真实任务的稀疏模式泛化性存在差距 | 从注意力流、梯度传播等角度解析机制有效性;构建真实场景下的稀疏模式评估体系 |
3. 领域发展核心趋势
- 架构融合化:独立线性/稀疏架构与密集型架构的边界逐渐模糊,混合设计成为平衡性能与效率的主流方向;
- 理论与实证并重:未来研究将从“单纯追求性能提升”转向“性能+机制解释”,强化理论对架构设计的指导;
- 硬件-算法协同优化:高效注意力机制的设计将更紧密结合硬件特性(如GPU张量核心、内存访问模式),实现算法创新与硬件效率的深度协同;
- 长上下文与无损性并重:突破“长上下文必然导致精度损失”的瓶颈,成为稀疏/混合注意力的核心目标。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 47
47 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)