面向具身操作的视觉-语言-动作模型的综述阅读
具身智能面临"大脑与身体脱节"的核心挑战:大模型虽具备语义理解能力,却无法感知物理执行限制。早期模仿学习存在泛化能力差、数据依赖性强等问题。当前VLA模型发展呈现三个阶段特征:萌芽期(2023前)尝试语言引入但动作离散化;探索期(2023-2024)采用大模型架构但存在实时性不足;快速发展期(2024起)采用分层架构平衡智能与实时性。模型架构包含观测编码、特征推理和动作解码三大
论文链接:https://arxiv.org/pdf/2508.15201v1
用最简洁的话概括,具身智能 (Embodied AI) 就是:
“有身体、能感知、并能物理干预现实世界的 AI。”
一.背景:
1.传统机器人系统为何难以适配开放环境下的多样性任务与复杂交互行为?
传统的机器人系统通常由多个不同的模块组合构成,基于逻辑编排的决策模块和基于搜索或优化的规划与控制模块很难应对开放环境下多样性任务需求以及复杂的交互行为。
2.为什么大模型(LLM和VLM)无法理解机器人的执行能力?
随着大语言模型(Large Language Model, LLM) 和视觉语言模型(Vision Language Model, VLM)的兴起,以Transformer结构为核心的基础模型展现出了强大的泛化能力。这种模式存在语义理解与物理执行的割裂。大模型主要承担环境理解和规划层功能,无法理解机器人的执行能力。然而大模型规划的动作需依赖预编程的下层控制器,导致机器人任务理解与执行出现脱节,无法实现复杂的动作行为。
这段话描述了当前具身智能领域(Embodied AI)面临的一个核心痛点:“大脑(大模型)太聪明,但身体(机器人控制器)跟不上,且两者语言不通。”
为了让你理解为什么大模型(LLM)“无法理解机器人的执行能力”,我们可以通过一个通俗的类比和三个技术层面的原因来解释。
一、 通俗类比:“纸上谈兵的将军”与“甚至不会走路的士兵”
想象一下这样一个场景:
-
大模型(LLM/VLM)是“将军”:他熟读兵法(海量互联网文本),博古通今,能制定完美的战略(规划)。比如他下令:“去把桌上的水杯拿给我。”
-
下层控制器是“士兵”的肌肉:它是一些预先写好的死板程序(比如 PID 控制、逆运动学算法),只懂具体的数字指令,不懂人话。
这时候问题来了:
将军(大模型)并没有长在士兵的身体里。他不知道士兵的手臂其实只有 50 厘米长(够不着水杯),也不知道士兵的手指今天坏了一根(抓不住重物)。
将军只负责发号施令:“伸手 -> 抓取 -> 收回”。
但由于他不了解士兵身体的物理限制(关节角度限制、电机扭矩上限),这个命令在物理世界中可能是根本无法执行的,或者会导致机器人动作僵硬、甚至撞坏自己。这就是所谓的“割裂”。
二、 技术层面:为什么大模型不懂“执行能力”?
从技术原理上讲,主要有以下三个原因导致了大模型无法理解机器人的执行能力:
1. 训练数据的“次元壁” (文本 vs. 信号)
-
大模型学的是“道理”:LLM 是用互联网上的文本、代码、图片训练出来的。它知道“苹果是红色的”、“抓取需要先张开手”。
-
机器人执行需要的是“感觉”:机器人的底层执行依赖的是本体感知数据(关节的力矩、电机的电流、传感器的精确数值)。
-
结果:大模型从未在训练数据中见过“当我的手臂伸到 30 度时,重力会让我的手抖动”这种物理世界的底层反馈。它只懂逻辑,不懂物理手感。
2. 输出接口的“高低之别” (高层指令 vs. 电机控制)
-
大模型输出的是语义:大模型输出通常是函数调用,比如 robot.pick_up(apple)。它认为只要调用了这个函数,动作就完成了。
-
底层控制器负责的是过程:实际执行 pick_up 需要底层的传统算法去计算几十个关节每毫秒该转多少度。
-
盲区:大模型把底层控制器当成了一个完美的黑盒。它不知道这个黑盒其实很笨,如果苹果很滑,或者位置稍微偏了一点,底层控制器就会报错或失败,而大模型对此一无所知。
3. 缺乏“具身反馈回路” (开环 vs. 闭环)
-
人类在拿东西时,如果感觉重了,大脑会瞬间命令肌肉增加力量(闭环反馈)。
-
在传统的大模型+机器人架构中,通常是单向的:大模型制定好计划 -> 扔给控制器去执行。如果执行过程中遇到了阻力、摩擦力变化,大模型通常无法实时感知并调整,它还在傻傻地等待任务完成。
3.为什么模仿学习“难以适应新任务或多变的环境”?
为什么机器人看过几百次示范,换个桌布或者换个杯子就不行了?这在学术界被称为 “泛化能力差” (Poor Generalization)。主要有以下 4 个深层原因:
1. 分布偏移(Distribution Shift)——“没见过的就不会”
• 训练时:机器人看到的是“白桌子+红苹果”。它学到的策略是“看到白色背景中间有个红点 -> 伸手”。
• 测试时:环境变成了“黑桌子+红苹果”。
• 结果:对于神经网络来说,输入的像素矩阵完全变了。虽然人眼看是一样的任务,但对机器来说,这是它从未见过的全新数据分布。它会感到困惑,不知道该输出什么动作。这也叫 Out-of-Distribution (OOD) 问题。
2. 虚假相关性(Spurious Correlations)——“它可能作弊了”
这是模仿学习中最滑稽也最头疼的问题。大模型/神经网络有时候“聪明”过头了,它会利用背景里的捷径来偷懒。
• 例子:你在训练机器人抓水杯时,如果不小心每次都在下午3点训练,阳光刚好照在桌子左上角。
• 机器的理解:它可能并没有学会“抓水杯”,而是学会了“只要看到左上角有亮光,我就往前伸手”。
• 后果:当你把窗帘拉上(多变环境),光斑消失了,机器人就突然瘫痪了,因为它依赖的那个(错误的)特征不见了。它并没有真正理解“水杯”这个物体的物理属性。
3. 缺乏因果推理与物理常识(Lack of Semantic Understanding)
• 传统方法:虽然繁琐,但它知道“这是杯子,杯子有碰撞体积,手不能穿过去”。
• 模仿学习(早期):它学的是像素到电机的映射。它不知道自己在抓杯子,它只知道“当图像显示这个花纹时,我的第3个关节要转动5度”。
• 后果:如果你让它去抓一个没见过的“蓝杯子”(新任务),它脑子里没有“杯子”这个概念,只有“红色像素块”的记忆,所以它无法把抓红杯子的经验迁移到蓝杯子上去。
4. 数据依赖性与采样效率
• 早期的模仿学习高度依赖人类专家的示教数据(Demonstration)。
• 如果要适应“多变环境”,理论上你需要采集涵盖所有光照、所有桌子颜色、所有物体摆放位置的数据。
• 这在现实中是不可能的(成本太高)。数据不够全,模型就只能在这一亩三分地里跑,稍微走出去一点就“迷路”了。
总结:早期视觉模仿学习就像是一个靠背题库通过考试的学生。
二.VLA发展历程
第一阶段:萌芽阶段 (2023年7月之前)
这一阶段的核心是尝试将语言引入机器人控制,不再只是单纯的视觉模仿,但还没有完全形成“VLA大模型”的概念。
-
代表模型:
-
CLIPort: 结合了 CLIP 的语义理解和 Transporter Network 的空间操作能力。
-
RT-1 (Robotics Transformer 1): Google DeepMind 推出的基于 Transformer 的模型,输入图像和文本,输出离散化的动作 Token。
-
GATO: DeepMind 的通才智能体,一个模型同时玩游戏、聊天和控制机械臂。
-
VIMA: 引入多模态 Prompt,支持更复杂的任务描述。
-
-
使用它们的优点:
-
引入语义: 相比传统的 One-hot 编码,语言描述让机器人能处理更开放的任务(比如“拿那个红色的杯子”)。
-
统一框架: GATO 和 RT-1 证明了可以用处理序列数据(Sequence Modeling)的方式来处理机器人控制问题。
-
-
后来改进的原因 (局限性):
-
动作离散化导致精度低: RT-1 把动作强行变成离散的 Token(比如把转动角度分成256份),这损失了控制精度,动作不流畅。
-
缺乏物理常识: 这些模型大多从零训练或仅使用少量数据,没有大规模互联网数据的“世界知识”,泛化能力差。
-
模型容量限制: 早期架构(如 ResNet+CNN)难以通过单纯增加数据量来获得“涌现”能力。
-
第二阶段:探索阶段 (2023年中 - 2024年)
这一阶段的标志是 VLA 概念正式提出,开始直接借用或模仿 LLM/VLM(大语言/视觉语言模型)的架构和权重。
-
代表模型:
-
RT-2: 里程碑模型。直接继承了 PaLM-E (VLM) 的权重,把机器人动作当作一种特殊的“语言”输出。
-
Octo: 开源界的代表,使用轻量级 CNN+Transformer,引入了扩散策略(Diffusion Policy)。
-
RDT-1B / ACT: 引入扩散模型 (Diffusion Model) 替代传统的 Transformer 解码头。
-
OpenVLA / RoboFlamingo: 开源社区尝试复现 RT-2 的思路,继承 LLaMA 或 Flamingo 的权重。
-
-
使用它们的优点:
-
涌现出的推理能力: RT-2 继承了 VLM 的大脑,突然“懂了”很多没见过的物体和指令(比如“把快灭绝的动物捡起来”,它能认出恐龙玩具)。
-
解决多模态动作分布: RDT 和 ACT 引入扩散模型,解决了“平均值问题”。(注:如果前面有障碍物,机器人应该从左绕或从右绕,传统模型会取平均值直直撞上去,扩散模型则能生成合法的双峰分布。)
-
-
后来改进的原因 (局限性):
-
推理速度太慢: RT-2 这种巨型模型跑一次推理要很久,无法满足机器人 10Hz-50Hz 的实时控制需求。
-
虚假遗忘 (Catastrophic Forgetting): 当用机器人数据微调大模型时,大模型原本的通用能力(常识)会迅速退化。
-
数据量级不匹配: 机器人数据(1M级别)远少于互联网文本数据(Billion级别),导致模型难以训练透彻。
-
第三阶段:快速发展阶段 (2024年底 - 2025年/未来)
这一阶段的核心是分层架构和视频数据利用,试图平衡“聪明”与“手快”的矛盾。
-
代表模型及趋势:
-
分层系统 (System 1 & System 2): 如 HiRT, GR00T N1, TriVLA。
-
S2 (大脑): 用大 VLM 做规划,慢但聪明。
-
S1 (小脑): 用小模型做动作执行,快但简单。
-
-
视频生成/世界模型: 如 UniPi, GR-1, GR-2。利用互联网上的人类视频来预训练物理规律。
-
思维链增强 (CoT): 如 CoT-VLA。让机器人在动之前先“想”一步(输出推理文本)。
-
-
使用它们的优点:
-
兼顾泛化与实时性: 分层架构让“大脑”可以在云端慢思考,“小脑”在本地快执行,解决了实时控制问题。
-
数据飞轮: 利用视频生成模型(World Model)可以从海量人类视频中学习物理常识,不再受限于稀缺的机器人数据。
-
更强的长程任务能力: 思维链(CoT)让机器人能理解复杂任务的步骤,不再只是肌肉记忆。
-
-
当前面临的挑战 (未来的改进方向):
-
通信损耗: 大脑(S2)和小脑(S1)之间怎么沟通?用文字沟通会丢失空间精度,用向量沟通又难以解释。
-
“脑子会了手不会”: 视频预训练能让模型看懂物理规律,但迁移到具体机型的电机控制上仍有鸿沟(Sim-to-Real)。
-
| 阶段 | 核心问题 | 解决方案 | 为什么又不行了?(演进动力) |
| 萌芽 | 怎么让机器人听懂人话? | 引入语言编码器 (CLIP/T5) | 动作太僵硬(离散化),不懂物理常识。 |
| 探索 | 怎么让机器人有常识? | 继承 VLM 大模型权重 (RT-2),引入扩散模型 (Diffusion) | 大模型太慢,无法实时控制;且容易遗忘通用知识。 |
| 快速发展 | 怎么既聪明又快? | 分层架构 (大脑规划+小脑执行) + 视频预训练 | 大小脑之间配合难,训练数据依然不够多(开始转向世界模型和强化学习微调)。 |
三.VLA 模型架构
1. 观测编码 (Observation Encoder) —— “眼睛与感官”
这一部分负责把机器人看到(图像)、听到(语言)、摸到(触觉)的信息,转换成神经网络能理解的向量(Tokens)。
-
视觉编码 (Visual Encoder):
-
发展趋势: 从 CNN (如 ResNet, EfficientNet) 转向 Transformer (如 ViT)。
-
主流方案:
-
CNN流派: 早期模型如 RT-1、Octo 使用 ResNet/EfficientNet。优点是推理快,对纹理敏感。
-
ViT流派: 现代模型(如 RT-2, OpenVLA)倾向于使用在大规模互联网数据上预训练好的 ViT(如 SigLIP, DINOv2)。优点是语义理解能力更强,能泛化到没见过的物体。
-
-
3D感知: 为了解决二维图像缺乏深度信息的问题,部分模型(如 3D-VLA)引入了点云编码器(PointNet++等)来处理 3D 空间关系。
-
-
语言编码 (Language Encoder):
-
通常使用预训练好的 T5 或 BERT,将人类指令(如“把红苹果拿给我”)编码成文本 Embedding。
-
-
触觉/力觉编码 (Tactile/Force Encoder):
-
较新的方向(如 ForceVLA),通过简单的 MLP(多层感知机)或投影层,将力传感器数值映射到与视觉相同的特征空间。
-
2. 特征推理 (Reasoning Backbone) —— “大脑”
这是 VLA 的核心,负责处理多模态信息,理解当前情况,并规划下一步该怎么做。
-
Transformer (主流霸主):
-
原理: 利用自注意力机制(Self-Attention)处理长序列。
-
代表: RT-2。它把图像 Token 和文本 Token 拼在一起,通过层层网络“推理”出下一步的动作 Token。
-
问题: 计算量随序列长度平方增长,推理慢;容易出现“幻觉”。
-
-
Diffusion Transformer (DiT) (新贵):
-
原理: 结合了扩散模型(Diffusion)的生成能力和 Transformer 的架构。
-
代表: RDT-1B, GR00T。
-
优点: 能更好地处理多模态动作分布(比如前面有障碍物,它可以生成“从左绕”或“从右绕”两种合法的动作,而不是取平均值撞上去)。
-
-
Mamba / SSM (极速派):
-
原理: 状态空间模型,线性复杂度。
-
代表: RoboMamba。
-
优点: 推理速度极快,显存占用低,适合机器人实时控制。
-
-
MoE (混合专家):
-
原理: 只有一部分神经元参与计算(由路由网络决定激活哪个“专家”)。
-
代表: ForceVLA, ChatVLA。
-
优点: 在不增加计算成本的情况下扩大模型容量,减少不同任务之间的干扰。
-
3. 动作解码 (Action Decoder) —— “手脚”
这一部分负责把“大脑”想出来的抽象特征,还原成具体的电机指令(如关节角度、末端位置)。
-
离散动作 (Discrete Action):
-
做法: 把连续的动作(如手臂移动 1.23cm)强行切分成 256 个格子(Token)。
-
代表: RT-1, RT-2。
-
优点: 可以直接套用 LLM 生成文本的方式来生成动作。
-
缺点: 精度低,动作不细腻,像“机器人舞”。
-
-
连续动作 (Continuous Action):
-
做法: 直接回归预测具体的浮点数值。
-
确定性预测: 输出一个固定的平均值(容易导致动作僵硬)。
-
扩散策略 (Diffusion Policy): 目前最强方案(如 Octo, RDT)。通过“去噪”过程生成动作,支持多模态分布,动作极其丝滑。
-
-
动作分块 (Action Chunking):
-
做法: 一次预测未来 k 步的动作(如 ACT 算法),而不是只预测一步。
-
优点: 减少抖动,动作更连贯,缓解推理延迟问题。
-
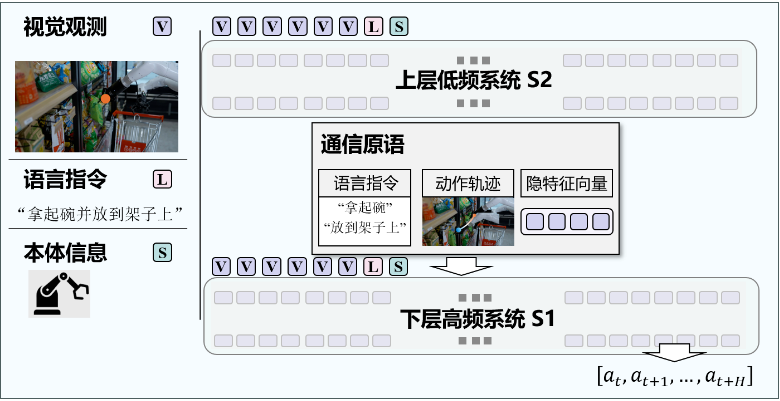
4. 分层系统 (Hierarchical System) —— “大小脑配合”
由于单一大模型(VLA)又慢又难训练,现在流行把它拆成两层。
-
上层策略 (System 2 - 大脑):
-
模型: 巨大的 VLM(如 GPT-4V, LLaMA-V)。
-
任务: 慢思考。负责理解复杂指令,进行长程规划(例如:“先把抽屉打开” -> “再把苹果放进去”)。
-
输出: 文本指令、路点(Waypoints)或隐空间向量。
-
-
下层策略 (System 1 - 小脑):
-
模型: 小型的动作策略网络(如 Diffusion Policy)。
-
任务: 快执行。接收上层的指令,结合当前的本体感知,高频(50Hz+)输出电机控制信号。
-
优点: 完美平衡了泛化能力(靠上层)和实时控制能力(靠下层)。
-
总结图示
| 模块 | 功能 | 早期/基础方案 | 前沿/主流方案 |
| 观测编码 | 感知世界 | ResNet (CNN) | SigLIP / DINOv2 (ViT), PointNet (3D) |
| 特征推理 | 思考决策 | Standard Transformer | DiT (Diffusion Transformer), Mamba, MoE |
| 动作解码 | 执行动作 | 离散 Token (Binning) | Diffusion Policy (扩散策略), Action Chunking |
| 整体架构 | 系统组织 | 单一端到端模型 (End-to-End) | 分层架构 (System 1 + System 2) |
四.VLA 训练数据
1. 互联网图文数据 (Internet Image-Text Data)
这是VLA模型构建通用常识和场景理解能力的基础。
-
特点:规模最大,成本最低,主要用于预训练VLM(视觉语言模型)部分,赋予模型语义理解能力。
-
作用:帮助机器人理解“什么是苹果”、“什么是桌子”以及基础的视觉问答推理。
-
局限:静态数据,缺乏动作和物理交互信息。
-
代表数据集:
-
COCO(目标检测、图像描述)
-
VQA系列(视觉问答)
-
CapsFusion(大规模图文对)
-
2. 视频数据 (Video Data)
主要指人类活动的视频数据,用于理解动态环境和物理过程。
-
特点:包含时序信息,记录了操作过程,但通常缺乏机器人的具体动作指令(Action Labels)。
-
作用:通过观察人类如何操作物体,模型可以学习到物理常识、任务流程和环境动态变化。需要通过视频预测或提取“潜在动作”来辅助训练。
-
代表数据集:
-
Ego-4D / Ego-Exo-4D(大规模第一/第三人称视角人类活动)
-
Something-Something V2(日常物品操作动作)
-
Kinetics-700(人类动作类别)
-
EPIC-KITCHENS(厨房场景操作)
-
3. 仿真数据 (Simulation Data)
在虚拟环境中生成的机器人操作数据,用于低成本获取大规模轨迹。
-
特点:自带完美的标注(包括动作指令、状态信息),生成成本低,可以进行大量重复和边缘情况的测试。
-
作用:弥补真实数据的不足,用于学习复杂的物理交互和长序列任务。
-
局限:存在“Sim-to-Real Gap”(仿真到现实的差距),即视觉渲染和物理动力学与真实世界不完全一致。
-
代表数据集:
-
RoboCasa(大规模厨房场景仿真)
-
SynGrasp-1B(抓取任务)
-
DexMimicGen(灵巧手操作)
-
4. 真实机器人采集数据 (Real Robot Data)
这是VLA模型最核心、最昂贵的数据,位于金字塔顶端。
-
特点:包含真实的视觉输入(RGB/RGB-D)、机器人本体状态(关节角度、末端位姿)和具体的控制指令。
-
作用:用于**微调(Fine-tuning)**模型,使其能够操控真实的硬件完成任务。这是实现具身智能“落地”的关键。
-
采集方式:主要通过人类遥操作(Teleoperation)采集,也有少部分自主探索。
-
代表数据集:
-
Open X-Embodiment (OXE):谷歌整合的包含22种机器人、100多万条轨迹的超大规模数据集,是目前的标准基座。
-
RT-1 / RT-2 数据集。
-
Bridge Data V2(厨房场景通用数据)。
-
RH20T(包含力觉、音频的多模态数据)。
-
DROID(大规模野外/多场景采集)。
-
五.VLA 预训练
1. 单一领域数据训练 (Single-domain Data Pre-training)
这是最直接、最朴素的方法,类似于“从零开始”或者仅在机器人圈子里打转。
-
核心逻辑:不依赖或者很少依赖通用的互联网大模型权重,直接使用大规模机器人轨迹数据(如 Open X-Embodiment 数据集)对模型进行监督训练。
-
流程:
-
收集大量机器人操作数据(视觉+动作)。
-
设计一个 Transformer 或 CNN 架构。
-
直接进行从视觉输入到动作输出的训练。
-
-
代表模型:Octo(从零训练 CNN+Transformer)、RDT(双臂操作模型)。
-
优缺点:
-
优点:模型结构更轻量,专注于动作控制。
-
缺点:由于机器人数据量远少于互联网文本数据,导致模型的视觉泛化能力和语义理解能力较差(比如它可能认不出没见过的物体,或者听不懂复杂的指令)。
-
2. 跨域数据分阶段训练 (Cross-domain Phased Training)
这是目前非常主流的方法,核心思想是**“站在巨人的肩膀上”**。
-
核心逻辑:利用已经训练好的强大基座模型(如 LLaMA、PaLI-X),先继承它们的“常识”,再教它们“干活”。
-
流程:
-
第一阶段(继承):加载预训练好的 LLM(大语言模型)或 VLM(视觉语言模型)权重。这些模型已经“读”过互联网海量图文,懂很多常识。
-
第二阶段(对齐/微调):使用机器人操作数据(图像-文本-动作)对模型进行训练,将其输出对齐到机器人动作空间。
-
-
代表模型:OpenVLA(继承 LLaMA 权重)、RT-2(继承 PaLM-E/PaLI-X 权重)。
-
优缺点:
-
优点:拥有极强的语义理解和推理能力,能听懂复杂指令。
-
缺点:容易出现**“灾难性遗忘” (Catastrophic Forgetting)**。即模型在学怎么拧螺丝的时候,可能把自己原本在互联网上学到的“苹果是红色的”这种通用知识给忘了,导致泛化能力下降。
-
3. 跨域数据联合训练 (Cross-domain Joint Training)
为了解决“学了新知识,忘了旧知识”的问题,研究者提出了“混合双打”的策略。
-
核心逻辑:同时喂给模型“互联网图文数据”和“机器人操作数据”,让它在保持通识的同时学习控制。
-
流程:
-
准备混合数据集:既包含 VQA(视觉问答)、图像描述等通用数据,也包含机器人轨迹数据。
-
在一个统一的架构下进行联合训练(Co-training)。
-
-
代表模型:GATO、ChatVLA-2、UP-VLA。
-
关键技术:为了防止两种任务互相打架(干扰),通常会引入 MoE(混合专家模型) 架构,让不同的“专家”网络负责处理不同的数据,或者通过共享注意力机制来平衡。
-
优缺点:
-
优点:极大提升了模型的泛化能力,避免了遗忘问题,让模型“既博学又手巧”。
-
缺点:训练成本高,数据配比和工程实现难度大。
-
4. 思维链增强 (Chain-of-Thought Enhancement)
这是一种提升模型“智商”的训练策略,受到 LLM 思维链(CoT)技术的启发。
-
核心逻辑:不让模型直接从“看到图像”跳到“输出动作”,而是强迫它先**“思考”**。
-
流程:
-
在训练数据中加入推理步骤。
-
普通训练:看到苹果 -> 伸手抓取。
-
CoT 训练:看到苹果 -> 思考(识别这是苹果 -> 目标是抓取 -> 苹果在右边 -> 应该先移动手臂) -> 伸手抓取。
-
-
代表模型:CoT-VLA、ECoT。
-
优缺点:
-
优点:打破了简单的“肌肉记忆”,让机器人面对未见过的场景时能通过推理解决问题,提高了长序列任务的成功率。
-
缺点:需要构建带有详细推理步骤的高质量数据集,推理速度可能变慢。
-
总结 VLA 预训练的演进:
从**“自己闭门造车”(单一领域数据) -> 到“拜名师学艺”(分阶段利用大模型权重) -> 再到“文武双修”(跨域联合训练) -> 最后追求“三思而后行”**(思维链增强)。目前的趋势是方法3和方法4的结合:既利用联合训练保持泛化性,又引入思维链提升推理能力。
六.VLA 后训练
1. 监督微调 (Supervised Fine-tuning, SFT)
这是目前最主流、最基础的方法。
-
核心逻辑:“照着学”。让模型模仿人类操作员的动作。
-
做法:
-
在预训练模型(如OpenVLA, Octo)的基础上,使用少量的、高质量的真实机器人数据进行微调。
-
这些数据通常通过人类遥操作(Teleoperation)采集(如使用VR手柄、主从机械臂)。
-
-
优点:
-
实现简单,训练稳定。
-
能快速将模型对齐到当前的机器人硬件和任务上。
-
-
缺点:
-
性能天花板:模型通常无法超越人类演示者的水平。
-
复合误差:一旦某一步走错,误差会累积,导致后续动作变形(因为训练时只见过正确的路)。
-
-
代表工作:OpenVLA, Octo, RT-2, ACT。
2. 强化微调 (Reinforcement Fine-tuning)
这是受到ChatGPT(RLHF)启发,旨在突破模仿学习上限的方法。
-
核心逻辑:“试错中进化”。模型自己在环境中尝试,做对了给奖励,做错了受惩罚。
-
做法:
-
离线到在线:先用收集好的策略数据训练(监督微调),然后通过与环境交互(或仿真环境)获得的反馈(奖励函数)来进一步更新权重。
-
常用算法:PPO(近端策略优化)、DPO(直接偏好优化)。
-
-
优点:
-
超越人类:可以通过自我博弈或探索,发现人类没教过的更优解。
-
鲁棒性强:对环境的细微变化适应性更好。
-
-
难点:
-
奖励难定义:在现实世界中,很难告诉机器人它刚才的动作“有70%好”(奖励函数稀疏)。
-
安全性:机器人在试错过程中可能会打坏东西或伤害自己(探索的代价高)。
-
-
代表工作:VLA-RL, GRAPE, RLDG, ReinboT。
3. 推理扩展 (Inference-time Expansion)
这是一种不需要更新模型权重,而是在“思考”阶段下功夫的方法。
-
核心逻辑:“三思而后行”。在执行动作前,先在脑子里(或模拟中)推演多种可能性,选最好的那个。
-
做法:
-
采样-验证:VLA模型生成多个候选动作序列。
-
评估:利用一个价值函数(Value Function)或视觉语言模型(VLM)来评估这些动作的成功率或安全性。
-
择优:选择得分最高的动作去执行。
-
-
优点:
-
即插即用:不需要重新训练庞大的VLA模型。
-
安全:可以在动作执行前过滤掉危险操作。
-
-
缺点:
-
速度慢:推理时间变长,难以满足高频实时控制(如每秒几十次的控制频率)。
-
-
代表工作:V-GPS (利用视觉预测评估), FOREWARN, RoboMonkey。
总结:三种后训练方法的对比
| 维度 | 监督微调 (SFT) | 强化微调 (RLFT) | 推理扩展 (Inference-time) |
| 比喻 | 老师手把手教,学生照做 | 学生自己做题,老师打分 | 动笔前先在草稿纸上演算 |
| 主要目标 | 适应特定机器人/任务 | 突破性能上限,自我进化 | 提高决策准确性和安全性 |
| 数据来源 | 人类专家演示 | 环境交互反馈 (Reward) | 模型自身生成的候选动作 |
| 训练成本 | 中等 | 高 (需要交互/奖励设计) | 无 (但推理成本高) |
| 当前痛点 | 泛化差,难以自我修正 | 现实世界训练不安全,收敛难 | 推理太慢,不适合高频控制 |
发展趋势:目前的趋势是将这三种方法结合。例如,先用SFT打底,再用RLFT在仿真器里提升能力,最后部署时加上推理扩展来保证安全。
七.VLA 模型评估
一、 评估的核心指标:泛化能力 (The "What")
VLA模型最核心的评估指标是泛化能力,即模型在面对未见过的场景时表现如何。文中将其细分为三个维度:
-
形态泛化 (Morphology Generalization):
-
模型能否适应不同的机器人本体(如不同的机械臂、不同的手爪)。
-
能否适应本体参数的变化(如关节长度、电机性能变化)。
-
-
任务泛化 (Task Generalization):
-
语义变化:理解不同的语言指令(如“拿起苹果” vs “把那个红色的水果给我”)。
-
物体变化:操作未见过的物体种类、颜色、位置或姿态。
-
-
环境泛化 (Environment Generalization):
-
能否适应背景、光照、相机角度的变化。
-
能否在布局杂乱或有遮挡的环境中工作。
-
二、 评估的三种主要方法 (The "How")
目前VLA的评估方法主要分为三类,各有优劣:
1. 基于真实环境评估 (Real-world Evaluation) —— “金标准”
这是最能反映模型真实能力的评估方式,但也最昂贵。
-
做法:在真实物理世界中布置场景,让机器人执行任务,统计任务成功率。
-
难点:
-
不可复现:环境很难完全重置,物体摆放的人为误差影响大。
-
效率低、成本高:需要人工监控,有损坏硬件的风险。
-
-
创新方案:
-
RoboArena:采用双盲A/B测试(类似于大语言模型的LMSYS Arena),让两个模型执行同一任务,通过成对比较计算Elo分数。
-
AutoEval:设计自动化装置(如自动复位机构)来减少人工干预。
-
2. 基于仿真器评估 (Simulator-based Evaluation) —— “实验室”
这是目前开发阶段最常用的方法。
-
做法:在物理引擎(如MuJoCo, PyBullet)中构建虚拟环境进行测试。
-
优势:安全、快速、可大规模并行、可完美复现。
-
劣势:Sim-to-Real Gap(仿真与现实的差距)。仿真器的渲染画质和物理接触特性(特别是柔性物体)与真实世界存在差异,导致仿真里表现好的模型在真机上可能失效。
-
代表基准:
-
CALVIN:长序列任务评估。
-
LIBERO:终身学习/多任务评估。
-
SimplerEnv:专门优化了视觉效果,使其更接近真实世界,用于评估泛化性。
-
3. 基于世界模型评估 (World Model-based Evaluation) —— “新趋势”
随着视频生成模型的发展,这种方法开始崭露头角。
-
做法:利用生成式视频模型(World Model)作为“模拟器”。VLA输出动作 -> 世界模型预测下一帧画面 -> VLA再输出动作... 如此循环,最后评估生成的视频是否达成了目标。
-
优势:不需要构建复杂的物理仿真环境,只需要视频数据即可训练评估器。
-
代表工作:WorldEval(利用视频生成模型评估OpenVLA等)。
-
局限:依赖于视频生成模型的物理一致性,可能会出现“物理幻觉”(比如物体凭空消失或穿模)。
三、 现有VLA模型的能力现状
根据文中(如表4、表6、表7)的测评结果:
-
头部模型:
(Pi-Zero) 和 OpenVLA 是目前表现较好的模型。
-
优势:在空间泛化(物体位置改变)和基础指令理解上表现不错。
-
短板:
-
跨任务/跨形态泛化极差:很难用一套参数控制完全不同的机器人。
-
精细操作弱:对于需要精确对齐(如插拔、堆叠)的任务,成功率依然较低。
-
长程任务弱:难以完成步骤繁多的复杂任务。
-
总结
VLA评估正在从单一的“成功率”向多维度的“泛化性测试”转变。目前的趋势是结合仿真器的大规模初筛和真实世界的精细验证(如RoboArena),同时探索利用世界模型进行低成本的自动化评估。
八.具身操作的 VLA 模型展望
1. 泛化能力的提升 (Generalization)
目前的 VLA 模型虽然继承了 VLM 的部分能力,但在面对复杂多变环境时仍显脆弱。未来的重点在于:
-
视觉鲁棒性: 解决模型对光照、背景干扰、视角变化、物体位置等视觉因素过分敏感的问题。
-
跨形态泛化 (Cross-Morphology): 实现真正的“通用机器脑”。目前的模型难以跨不同构型(不同自由度、不同尺寸)的机器人通用。未来目标是构建隐式共享空间或通用特征网络,使得一个模型能控制多种形态的机器人。
-
跨任务泛化: 实现对未训练过的对象和任务的零样本(Zero-shot)泛化,即建立语言、观测和动作之间高度耦合且泛化的关联。
2. 精细操作能力的突破 (Fine-grained Manipulation)
当前 VLA 在长程任务规划上表现出色,但在需要密集接触(Contact-rich)的任务上成功率较低。未来的突破点在于:
-
多模态融合(触觉与力觉): 单纯依靠视觉无法解决精细装配或盲操作问题。未来必须引入触觉和力觉信息,并解决这些异构数据与视听语言数据的对齐难题。
-
高频闭环控制: 现有的 VLA 推理速度较慢,难以满足接触式操作对高频实时响应的需求。
-
动作一致性: 解决由不同操作员遥操作习惯不同导致的数据不一致问题,通过强化学习等手段平滑动作分布。
3. 实时推理与部署架构 (Real-time Inference)
模型参数量大与机器人端侧算力有限是主要矛盾。未来的解决方案包括:
-
端云协同 (Cloud-Edge Collaboration): 采用分层架构(如 System 1 / System 2)。
-
云端(System 2): 运行大参数量的 VLM/VLA,负责复杂的语义理解、长程规划和推理。
-
端侧(System 1): 运行轻量化模型,负责高频、实时的动作生成和安全反射。
-
-
模型轻量化: 通过蒸馏、量化、裁剪等技术,让大模型能够适配机器人的有限算力。
-
异步分层机制: 解决模型推理耗时导致的动作执行延迟问题。
4. 训练与评估范式的演进
除了模型本身,训练和评估方法也将发生变革:
-
强化学习 (RL) 后训练: 从单纯的“模仿学习(监督微调)”转向“强化学习”。利用在线或离线 RL,让模型在交互中自我进化,突破人类示教数据的性能天花板。
-
数据飞轮 (Data Flywheel): 打通“采集-训练-部署-反馈”的闭环,利用部署在真实场景中的模型自动回流数据,解决高质量机器人数据稀缺的问题。
-
世界模型 (World Models): 构建高质量的世界模型作为“模拟器”,用于在仿真中评估 VLA 性能或生成合成数据,解决真实环境训练成本高、风险大的问题。
总结:
未来的 VLA 模型将不再仅仅是一个“会看图说话的控制器”,而是向着多模态感知(含触觉)、跨形态通用、具备高频精细操作能力、且能通过强化学习自我进化的通用具身智能大脑发展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)