ZFNet反卷积网络(Deconvnet):让CNN“黑盒”变透明的核心技术
ZFNet之所以能在AlexNet的基础上实现性能突破,核心并非单纯调整了网络参数,而是通过Deconvnet实现了对CNN的“可解释性优化”——它让研究者从“盲目调参”转向“基于特征理解的设计”。它不参与训练,却是训练的“观察者”和“指导者”;它依赖CNN的参数,却是CNN的“反向镜像”和“解码器”;它的价值不止于可视化,更是CNN设计的“方法论工具”。在如今大模型盛行的时代,Deconvnet
在深度学习计算机视觉的发展史上,2012年AlexNet的横空出世,彻底拉开了深度CNN在图像任务中应用的序幕。但AlexNet的成功背后,始终存在一个关键问题:CNN是“黑盒”——我们能看到网络的输入和输出,却无法直观理解中间层究竟学习到了什么特征,这些特征与原始图像的像素有何关联。
直到2013年,Matthew Zeiler和Rob Fergus提出的ZFNet(Zeiler & Fergus Network),通过创新性地引入反卷积网络(Deconvnet),首次实现了对CNN中间层特征的“反向解码”,让研究者得以“看见”网络的内部工作机制。这一突破不仅让ZFNet在ILSVRC 2013竞赛中斩获冠军,更奠定了CNN可解释性研究的重要基础。
一、Deconvnet的核心定位:不是“参与者”,而是“观察者”
很多初学者会误以为Deconvnet是ZFNet中参与训练的“子网络”,但实际上它的角色更像一个**“特征探针”**——不参与模型训练,却能为训练和网络优化提供关键洞察。
1. 不参与训练,但对训练至关重要
- 无独立可学习参数:Deconvnet不包含自己的权重,也不参与反向传播(BP)过程中的梯度更新,所有“计算工具”都来自已训练好的CNN。
- 训练中的核心作用:
- 「监控特征演化」:在训练过程中,通过Deconvnet可视化不同epoch的中间层特征,判断网络是否陷入“无效学习”(比如特征重复、梯度消失)。
- 「指导网络改进」:ZFNet正是通过Deconvnet发现了AlexNet的缺陷——AlexNet第一层卷积核尺寸过大(11×11),导致低层特征包含过多冗余信息。随后ZFNet将第一层卷积核调整为7×7,步长从4减为2,大幅提升了特征提取效率。
- 「验证特征有效性」:通过可视化确认中间层是否真的学习到了有意义的特征(如边缘、纹理、部件),而非随机噪声。
2. 必须与CNN“绑定”:一层对一层的镜像结构
Deconvnet无法独立工作,它是为CNN量身打造的“反向镜像”——CNN有多少层,Deconvnet就对应多少层,每一层的结构都与CNN对应层形成“反向映射”关系。
这种绑定的核心逻辑是:
CNN通过“卷积→池化→激活”将输入图像压缩为抽象特征;而Deconvnet则通过“反池化→整流→滤波”,将抽象特征“解压缩”回输入像素空间,从而建立“特征-像素”的对应关系。
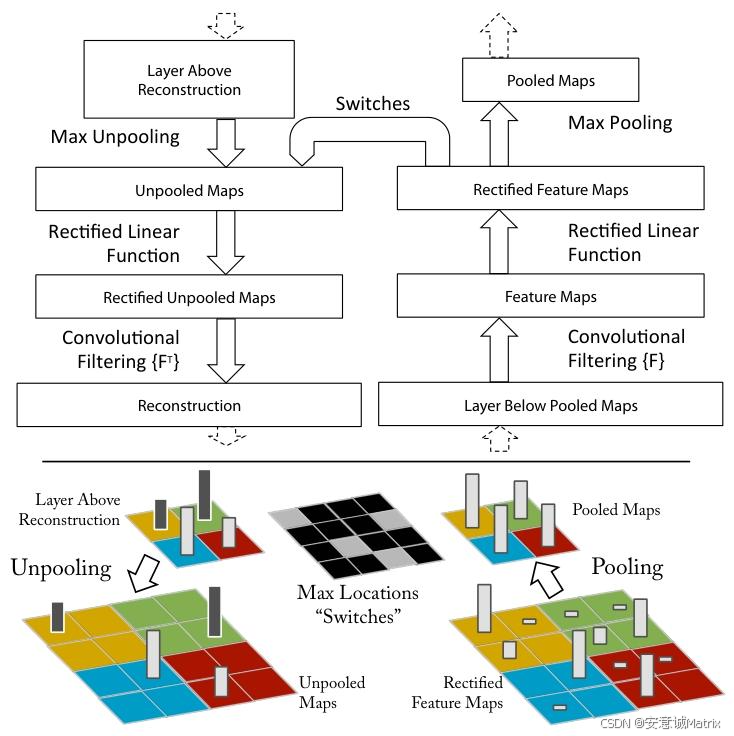
二、Deconvnet核心原理:三步实现“特征反向解码”
Deconvnet的工作流程围绕“如何准确还原CNN的正向过程”展开,每一步都针对性地解决CNN正向传播中丢失的信息(如空间位置、尺寸),最终实现特征到像素的映射。
1. 第一步:反池化(Unpooling)——找回池化丢失的空间位置
CNN的池化层(如Max Pooling)会通过“取最大值”压缩特征图尺寸,同时丢失大量空间位置信息(比如最大值在池化窗口中的具体位置)。Deconvnet的反池化,就是要“复原”这些位置信息。
-
关键操作:记录“开关变量”
在CNN正向传播时,Deconvnet会同步记录每个池化窗口中“最大值的坐标”(称为“开关变量”,Switch Variables)。例如,在2×2池化窗口中,若最大值位于左上角(1,1),则开关变量会标记该位置。 -
反池化过程:
当Deconvnet处理上层特征时,会将特征值“放回”到开关变量记录的坐标位置,其余位置补0。这样就能近似恢复池化前的特征图尺寸和空间结构,为后续的特征重构打下基础。举个例子:CNN池化后得到1×1的特征值(假设为5),对应的开关变量记录其来自2×2窗口的(2,2)位置。反池化时,会生成2×2的特征图,仅(2,2)位置为5,其余为0。
2. 第二步:整流(Rectification)——保持特征的“非负属性”
CNN中使用ReLU激活函数(f(x)=max(0,x)f(x)=\max(0,x)f(x)=max(0,x)),确保所有特征图都是“非负的”(只有激活的区域有值,未激活的区域为0)。为了让Deconvnet重构的特征与CNN特征属性一致,必须保留这一特性。
- 操作逻辑:
对反池化后的特征图,再次应用ReLU激活函数。这一步的目的是“过滤负数值”——如果反池化后出现负特征(可能由后续滤波引入),ReLU会将其置0,确保重构特征符合CNN的激活逻辑。
3. 第三步:滤波(Filtering)——用“转置卷积”映射回像素空间
CNN的卷积层通过“卷积核(Filter)”提取特征,而Deconvnet的滤波层则通过“转置卷积核”实现反向映射。这里的“转置”并非数学上的矩阵转置,而是对CNN卷积核进行“垂直+水平翻转”。
- 为什么要翻转卷积核?
CNN的卷积操作本质是“卷积核与特征图的互相关(Cross-Correlation)”,而严格的卷积需要先翻转卷积核。Deconvnet为了准确反向还原这一过程,会将CNN的卷积核先翻转(垂直翻转一次,水平翻转一次),再用翻转后的核对整流后的特征图进行卷积。 - 最终效果:
通过转置卷积,特征图的尺寸会逐步扩大(对应CNN卷积的尺寸缩小),直到最终映射回与原始输入图像相同的尺寸,完成“从抽象特征到像素图像”的重构。
三、Deconvnet的实际应用:如何“看见”CNN的特征?
以ZFNet的某一层卷积特征为例,使用Deconvnet进行可视化的完整流程如下:
- 选择目标特征:从训练好的ZFNet中,选取感兴趣的中间层(如第2层卷积层),并选中该层中一个激活较强的特征图(比如该特征图对应“边缘检测”)。
- 特征掩码(Masking):为了单独观察该特征图的贡献,将该层其他所有特征图的数值置为0,仅保留目标特征图。
- Deconvnet反向传播:将处理后的特征图输入Deconvnet,依次执行“反池化→整流→滤波”,逐层向上(向输入层方向)传播。
- 可视化结果:最终得到与原始输入尺寸相同的“重构图像”。这张图像上亮度较高的区域,就是原始图像中“激活了目标特征”的像素区域——比如若目标特征是“水平边缘”,则重构图像中水平边缘区域会明显变亮。
四、Deconvnet的价值:不止于可视化,更是CNN设计的“指南针”
Deconvnet的创新之处,远不止“让CNN变透明”这一点。它的核心价值在于,为研究者提供了**“从结果反推原因”的工具**——通过可视化,我们能直接判断CNN的设计是否合理,进而指导网络优化:
- 发现网络缺陷:比如AlexNet的第一层11×11卷积核,通过Deconvnet可视化发现其低层特征包含大量背景噪声,说明核尺寸过大,因此ZFNet将其调整为7×7,大幅提升了低层特征的纯度。
- 验证特征有效性:如果某一层的Deconvnet重构图像中,亮度区域与目标任务无关(比如分类任务中,重构图像亮区不在物体上而在背景上),说明该层特征学习无效,需要调整网络结构(如增加正则化、更换激活函数)。
- 奠定可解释性基础:Deconvnet开创了CNN可视化的先河,后续的Grad-CAM、CAM等可视化方法,本质上都是在Deconvnet的“反向映射”思想上的延伸。
五、总结:Deconvnet为何是ZFNet的“灵魂”?
ZFNet之所以能在AlexNet的基础上实现性能突破,核心并非单纯调整了网络参数,而是通过Deconvnet实现了对CNN的“可解释性优化”——它让研究者从“盲目调参”转向“基于特征理解的设计”。
回顾Deconvnet的核心特性:
- 它不参与训练,却是训练的“观察者”和“指导者”;
- 它依赖CNN的参数,却是CNN的“反向镜像”和“解码器”;
- 它的价值不止于可视化,更是CNN设计的“方法论工具”。
在如今大模型盛行的时代,Deconvnet的思想依然重要——无论模型规模多大,“理解模型如何工作”都是优化性能、避免过拟合的关键。而ZFNet的Deconvnet,正是这一思想的经典开端。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)