第211期 小模型但大影响:小型语言模型如何重新定义现实世界中的人工智能
摘要: 本文系统解析Transformer架构的核心机制及其在小型语言模型中的应用。首先阐明语言模型的本质是上下文预测工具,通过对比传统RNN与Transformer的注意力机制,揭示后者如何通过自注意力实现高效上下文关联。重点剖析多头注意力、分组查询注意力(GQA)等优化技术如何平衡性能与效率,使小型模型(如Phi-3、Llama-3)在特定任务上媲美大模型。最后提出关键决策框架:需权衡专业场景
AI拉呱,专注于人工智领域与AI工具、前沿技术解读。AI技术书单+提示词+优秀项目(含源码)+教程 ==网盘链接:https://pan.quark.cn/s/e4ada86e0476
第一部分:基础认知——还没搞懂Transformer?从这里开始
首先要明确一点:语言模型本质上就是一款预测“下一个内容是什么”的软件。
其实你每天都在使用语言模型——手机的自动补全功能就是典型例子。当你输入“我正要去……”,手机会推荐“商店”“办公室”或“健身房”,这正是语言模型通过从数百万示例中学习到的模式来进行预测的结果。
这背后没有什么魔法,只是大规模的模式匹配而已。
从“笨拙的自动补全”到“真正的理解”:技术的演进
- 早期自动补全(1990年代-2010年代):仅关注最后一个词
当你输入“bank”(可译为“银行”或“河岸”),它会推荐“account”(账户)、“statement”(账单)、“transfer”(转账)。
问题:无法理解上下文语境。 - 现代语言模型(2020年代):能理解完整对话
当你输入“我喜欢在bank边钓鱼”,模型能理解你指的是“河岸”而非“银行”,并推荐“看日落”“钓鲈鱼”“周末去”等内容。
二者的核心区别是什么?是注意力机制(Attention)。
现代模型会“关注”句子中的所有词,而非仅盯着最后一个词。它能识别出“bank”在“钓鱼”语境下与在“储蓄”语境下的含义差异。
这种“关注上下文”的机制,正是Transformer架构的核心。而“语言模型”则定义了它的功能:预测文本内容。
接下来,我会用通俗的方式解释注意力机制的工作原理,保证不涉及线性代数。
Transformer架构:注意力就是一切
2017年,谷歌研究员发表了一篇题为《Attention Is All You Need》(注意力就是一切)的论文,彻底改变了人工智能领域。他们提出的Transformer架构,为模型理解语言提供了全新方式。
该架构解决的核心问题是:如何让模型识别出句子中相隔较远的词语之间的关联?
以这句话为例:“这只动物没有过马路,因为它太累了。”
句中的“它”指代什么?是“动物”还是“马路”?你很清楚答案是“动物”——马路不会感到疲惫。但模型如何做出正确判断呢?
传统方法(循环神经网络,RNNs)
- 逐词从左到右处理文本
- 当处理到“它”时,模型已部分“忘记”了“动物”这个词
- 类似患有短时记忆障碍的人阅读文本
- 结果:无法确定“它”的指代对象
Transformer方法
- 同时“查看”所有词语
- 计算词语之间的关联程度
- “它”对“动物”的注意力权重高,对“马路”的注意力权重低
- 类似将整个句子平铺在眼前,一览无余
- 结果:立即明确“它”指代“动物”
注意力机制的实际工作原理(无需数学知识)
可以将注意力机制比作剧院里的聚光灯。
核心设定
当你试图理解句中的“它”时,Transformer会生成三个关键“问题”:
- 查询(Query):“我要理解的是什么?”(此处即“它”这个词)
- 键(Key):“其他词包含什么信息?”(所有其他词都会“展示”自己的含义)
- 值(Value):“我应该提取的实际含义是什么?”(需要获取的核心内容)
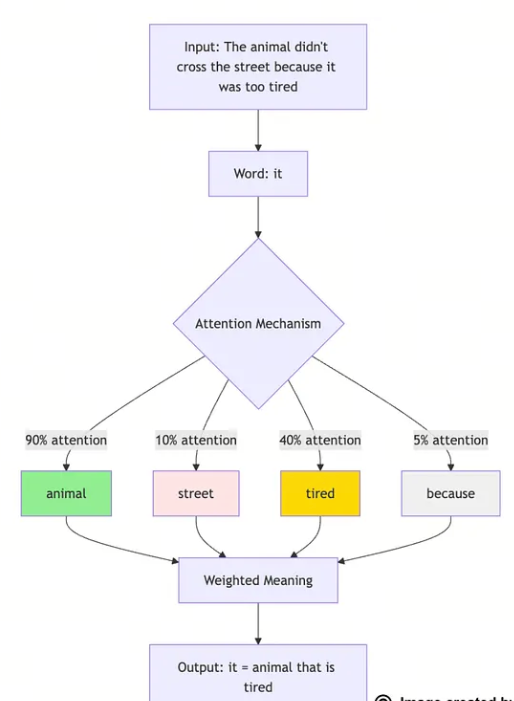
具体流程
- 第一步:“它”发出询问:“谁能告诉我,我指代的是什么?”
- 第二步:每个词返回关联度分数:
- “动物”→ 高关联度(90%)
- “马路”→ 低关联度(10%)
- “因为”→ 无关联度(0%)
- “累”→ 中等关联度(40%)
- 第三步:“它”计算加权平均值:
- 主要借鉴“动物”的含义(90%)
- 少量参考“累”的含义(40%)
- 忽略“马路”的含义(10%)
- 结果:“它”指代“动物”
这一过程会对每个词同时执行,且每个词都会“关注”所有其他词。这也是它被称为“自注意力(Self-Attention)”的原因——每个词都在关注其他所有词。
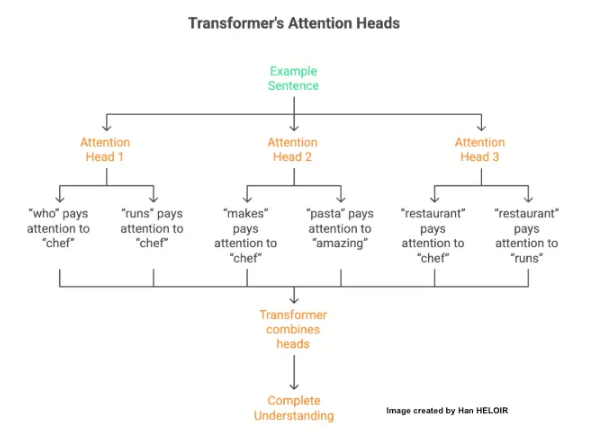
多头注意力:同时聚焦多维度信息
这正是Transformer的巧妙之处:一个注意力机制可聚焦语法,另一个可聚焦语义,再一个可聚焦词语间的关系。
以句子“经营餐厅的厨师做出了美味的意大利面”为例:
| 注意力头(Attention Head) | 聚焦方向 | 具体关联 |
|---|---|---|
| 注意力头1(语法聚焦) | 句子语法结构 | “who”(谁)关注“chef”(厨师,主语);“runs”(经营,动词)关注“chef”(厨师,主谓一致) |
| 注意力头2(语义聚焦) | 词语含义关联 | “makes”(制作,动词)关注“chef”(厨师,动作执行者);“pasta”(意大利面,名词)关注“amazing”(美味的,修饰词) |
| 注意力头3(关系聚焦) | 词语间逻辑关系 | “restaurant”(餐厅)关注“chef”(厨师)和“runs”(经营),明确“厨师经营餐厅”的逻辑 |
每个“注意力头”都专注于捕捉特定模式,Transformer会整合所有注意力头的结果,形成对句子的完整理解。
这一点对小模型尤为重要:
- Phi-3-mini:32个注意力头
- Qwen2-1.5B:16个注意力头
- TinyLlama-1.1B:32个注意力头
更多注意力头意味着能同时追踪更多关系,但即便只有16个注意力头,也能捕捉复杂模式——关键在于高效设计,而非单纯追求数量。
完整的Transformer模块(简化版)
Transformer不只是注意力机制,它由多个协同工作的层构成:
(原文标注:“注意力就是一切”——这是核心)
- 分词(TOKENIZATION):将文本拆分为基础单元,例如[“The”, “cat”, “sat”, “on”]
- 嵌入(EMBEDDING):将文本单元转换为模型可理解的数字(向量),例如“cat”→ [0.2, 0.8, 0.1, 0.9, …]
- 位置编码(POSITIONAL ENCODING):添加词语位置信息(位置至关重要,例如“狗咬 man”与“man咬狗”含义完全不同)
- 多头自注意力(MULTI-HEAD SELF-ATTENTION):每个词通过关注所有其他词,形成具有上下文感知的表示
- 前馈网络(FEED-FORWARD NETWORK):处理注意力输出,并应用已学习的转换规则
- 层归一化(LAYER NORMALIZATION):确保数据在处理过程中保持稳定
- 重复执行12-40次:每一层都会提取更深度的模式(重复次数取决于模型规模)
- 输出预测(OUTPUT PREDICTION):生成所有可能下一个词的概率分布,例如“mat”→ 45%、“chair”→ 30%、“floor”→ 15%……最终输出概率最高的“mat”
核心洞见:每一层都会深化模型对文本的理解。
- 早期层(1-6层):学习基础模式,如语法、常用短语、句子结构
- 中间层(7-20层):学习语义关系,即词语组合的含义
- 深层(20层以上):学习抽象概念,如逻辑、推理、领域知识
小模型的层数较少(6-32层),而大模型层数更多(40-80层以上)。但对于特定任务,针对特定领域优化的少量层,往往比训练通用内容的大量层更有效。
这正是小型语言模型的核心秘诀:深度并非一切,专业性才更重要。
为何Transformer能取代其他架构
| 对比维度 | Transformer出现前(RNN、LSTM等) | Transformer出现后 |
|---|---|---|
| 文本处理方式 | 逐词顺序处理(速度慢) | 所有词同时处理(速度快) |
| 长距离词语关联处理能力 | 难以捕捉长距离关联 | 通过注意力机制自然处理长距离关联 |
| 并行计算能力 | 难以并行(无法高效利用GPU) | 高度并行(GPU友好) |
| 早期信息保留能力 | 易“遗忘”句子早期信息 | 可平等关注所有前文词语 |
这也是为什么如今所有现代语言模型——无论是ChatGPT、Claude、Gemini,还是各类小型语言模型——都采用Transformer架构:它就是更优秀。
小型语言模型的效率突破
研究人员发现,无需96层结构和1750亿参数,通过以下方式即可实现高效模型:
- 采用24层结构,并搭配智能注意力模式
- 使用高质量的领域数据进行训练
- 针对特定硬件(手机、笔记本电脑)优化
- 应用高效注意力机制(如分组查询注意力Grouped-Query Attention、滑动窗口注意力Sliding Window)
结果:模型规模缩小10-100倍,但在特定任务上的表现可与大模型持平甚至超越。
对于定义清晰的任务,专业性永远比通用性更有效。
现代小型语言模型的注意力模式
现代小模型采用优化后的注意力机制,其演进过程如下:
-
标准多头注意力(Standard Multi-Head Attention, MHA)
- 每个注意力头都有独立的键(Key)、值(Value)和查询(Query),是2017年论文提出的原始方案
- 内存占用:高(每个头需存储独立参数)
- 性能质量:优秀
- 应用场景:GPT-2、早期BERT、学术研究模型
-
分组查询注意力(Grouped-Query Attention, GQA)
- 注意力头在组内共享键和值,内存占用减少4倍,而性能几乎不变
- 内存占用:中(组内参数共享)
- 性能质量:与MHA几乎持平
- 应用场景:Llama-3、Mistral、大多数现代小型语言模型
这是当前的“黄金平衡点”——几乎无性能损失,却能大幅提升效率。
-
多查询注意力(Multi-Query Attention, MQA)
- 所有注意力头共享相同的键和值,效率最高,但性能略有损失
- 内存占用:低(最大化参数共享)
- 性能质量:良好(轻微性能下降)
- 应用场景:PaLM、部分移动端模型
对于生产级小型语言模型,分组查询注意力(GQA)是默认选择,所有成功的模型均采用该机制。
至此,你对Transformer的理解已经超过了许多仅听说过这个概念的工程师。
接下来的问题是:你真的需要构建一个Transformer模型吗?让我们一起来分析。
第二部分:决策判断——“你真的需要构建小型语言模型吗?”
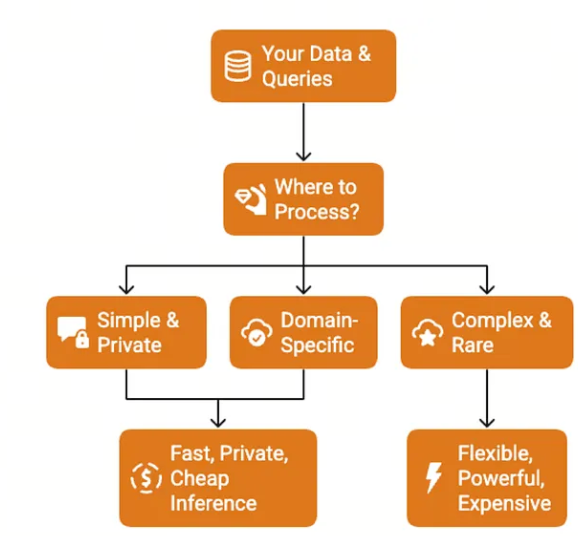
你已经了解了小型语言模型的工作原理,现在面临一个难题:你的使用场景是否需要构建一个小型语言模型?
大多数工程师会直接跳过决策环节,直奔实现步骤,这是错误的。选择小型语言模型还是云端API,会对你的架构设计、成本控制和团队精力分配产生重大影响。
让我们用系统化的方式做出决策。
决策树
(此处对应原文“Should you even build a SLM?”的决策树,核心逻辑为逐步判断是否需要小型语言模型)
现实信号
别再依赖清单了,判断是否需要小型语言模型,关键看是否出现这样的对话:“用API做的演示很完美,但因为[合规/成本/延迟]问题,我们根本无法落地。”
这就是核心信号:当API解决了技术问题,却引发了业务问题时,你就需要小型语言模型了。
例如,某金融科技初创公司曾使用OpenAI API构建欺诈检测助手,效果出色。但客户的安全团队提出质疑:“你们要把交易数据发送到OpenAI的服务器?”项目随即被叫停。最终,他们用本地部署的70亿参数模型,通过欺诈模式微调,重新构建了系统。
反观另一个案例:某内容营销团队为生成博客文章构建了小型语言模型,耗时两个月完成微调并部署。但后来发现,GPT-4生成的内容质量更优,且他们每月仅需20篇文章——若使用API,每月成本仅需50美元,而团队投入的开发时间成本远高于此。
混合策略的真相
大多数生产级系统不会“非此即彼”,而是采用混合策略:
先使用API——开发速度更快、维护更简单,且能在探索用户真实需求的过程中保持灵活性。收集实际使用数据,分析哪些查询是高频的、哪些是复杂的、哪些是高成本的。
然后,有选择地将部分功能迁移到小型语言模型。
例如,某客户支持初创公司起初用GPT-4处理所有查询。三个月后发现,80%的查询可归为六类:订单状态、退货申请、产品规格、物流信息、账户问题和常见FAQ。他们针对这六类场景微调了小型语言模型,现在小型语言模型处理常规查询的成本从每查询0.02美元降至0.0001美元,而API仅处理特殊边缘案例和复杂升级需求。
最终,他们的成本降低了85%,延迟缩短了70%,且无需提前三个月投入开发一个可能无用的系统。
你的决策节点
暂停阅读,坦诚回答这个问题:你是否面临小型语言模型或定制语言模型能解决的真实问题?
不是“微调模型听起来很酷吗?”,也不是“我想学习小型语言模型”,而是你是否存在API无法满足的合规要求、成本压力、延迟需求或专业领域需求?
- 如果是,继续阅读,下文将详细告诉你如何构建。
- 如果不是,直接使用API并落地产品,待遇到小型语言模型能解决的问题时再回来。
优秀的工程师知道“不该构建什么”,不要为了技术而技术。
第三部分:构建实践——动手搭建(无需博士学位)
你已决定构建小型语言模型或定制模型。接下来的内容,是大多数教程会忽略的部分:如何实现能脱离Jupyter笔记本、真正落地的系统。
我将介绍三种实现路径。大多数教程只讲微调,因为它最容易解释,但根据你的约束条件,可能需要不同的方案。下面先明确每种路径的核心含义。
三种路径(明智选择)
路径1:微调(首选方案)
- 核心定义:基于现有模型,教它处理你的特定任务。不改变模型的核心知识,仅在表层添加专业能力。
- 类比理解:就像心脏科医生先接受医学教育(预训练),再进行心脏专科培训(微调)。
- 适用场景:
- 拥有100-10000个示例数据
- 领域专业但使用自然语言
- 希望在几天内得到结果
- 优势:这是默认路径,所需数据、计算资源和专业知识最少。除非有特殊原因,否则优先选择此方案。
路径2:模型蒸馏(应对规模约束)
- 核心定义:将大模型压缩为小模型,同时尽可能保留性能。本质上是让GPT-4这类大模型“教”70亿参数小模型模仿其在特定任务上的表现。
- 适用场景:
- 现有大模型效果完美,但无法适配目标硬件
- 训练过程中可访问大模型
- 需要尽可能小的模型来完成任务
- 注意事项:比微调更复杂,需要更多专业知识。仅在微调无法满足约束条件时选择此方案。
路径3:从零训练(谨慎选择)
- 核心定义:字面意思,从随机初始化权重开始,用你的数据从头训练模型。
- 适用场景:
- 领域极特殊,预训练模型毫无参考价值(如高度专业的科学符号、专有编程语言、非通用文字体系)
- 拥有数十亿token的训练数据
- 可投入数月时间和大规模GPU集群
- 客观评估:极少需要采用此方案。即便对于专业领域,多语言模型或领域适配模型也能提供巨大的起步优势。只有拥有机器学习研究团队和充足计算预算时,才考虑从零训练。
在本部分剩余内容中,我们将聚焦微调——95%的人都应选择的路径。
微调实操指南
我们将以Mistral-7B(由Mistral AI训练的72亿参数通用知识模型)为例,演示如何将其适配到你的领域。
采用的技术是LoRA(Low-Rank Adaptation,低秩适配):无需更新全部72亿参数,只需添加小型“适配层”,仅训练总参数的1%-2%。
为什么有效:基础模型已掌握语言、推理和通用知识,我们只需教它你的领域特定模式和术语。
这种方法高效、快速,且能适配消费级GPU内存,大学生用游戏电脑就能运行。
下面开始实操。
步骤1:环境搭建
需要Python 3.10+和至少8GB显存的GPU。若本地无GPU,可使用Google Colab(免费 tier可用)或Runpod(云GPU,每小时仅0.30美元)。
# 安装依赖包
pip install transformers==4.38.0 peft==0.8.2 bitsandbytes==0.42.0 accelerate==0.26.1 datasets==2.16.1 scipy
这些包的核心作用:
- transformers:Hugging Face的模型加载与运行库
- peft:参数高效微调(Parameter-Efficient Fine-Tuning)库,处理LoRA适配层
- bitsandbytes:量化库,减少模型内存占用
- accelerate:分布式训练与内存优化工具
- datasets:数据加载与预处理库
- scipy:支持特定优化器操作
这五个库承担了所有核心工作,感谢开源社区的贡献。
步骤2:加载基础模型
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
model_name = "mistralai/Mistral-7B-Instruct-v0.2"
# 配置4位量化
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4", # NormalFloat4,神经网络优化格式
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True # 嵌套量化,进一步节省内存
)
# 加载量化后的模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto", # 自动使用可用GPU
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # 设置填充token
tokenizer.padding_side = "right" # 训练需右填充
关键说明:
- 72亿参数模型通过量化后,仅需约5GB内存即可加载,而无量化时需28GB,核心在于BitsAndBytesConfig的配置。
- nf4量化类型专为神经网络权重设计,比标准4位整数更能保持精度。
- 双重量化会压缩量化常数本身,额外节省约0.5GB内存,且对性能影响可忽略不计。
步骤3:数据准备(多数人会在这里出错)
这是大多数教程的薄弱环节——它们教你如何微调,却不解释有效的数据格式。
你的数据需为“指令-响应”对,每个示例需明确告诉模型:它会收到什么输入,你期望什么输出。
training_data = [
{
"instruction": "2型糖尿病的症状有哪些?",
"output": "常见症状包括口渴加剧、尿频、饥饿感增强、不明原因体重下降、疲劳、视力模糊、伤口愈合缓慢以及频繁感染。"
},
{
"instruction": "如何诊断高血压?",
"output": "高血压通过多次测量血压来诊断。在两次不同场合测量的血压值均≥130/80 mmHg时,通常可诊断为高血压。"
},
{
"instruction": "解释1型糖尿病和2型糖尿病的区别。",
"output": "1型糖尿病是一种自身免疫性疾病,患者体内无法产生胰岛素;2型糖尿病是一种代谢性疾病,患者体内出现胰岛素抵抗或胰岛素分泌不足。"
},
# 继续添加100-1000+个类似示例
]
数据量需求:
实际需求取决于任务复杂度:
- 简单分类任务:100-500个示例通常足够
- 特定领域问答:500-2000个示例可实现良好覆盖
- 复杂推理任务:2000-10000个示例可确保表现稳定
建议:从小规模开始,用200个示例微调并测试。若性能不足,针对性补充数据——找出模型的失败案例,添加覆盖这些场景的示例。不要在确认微调有效前,浪费时间收集10000个示例。
步骤4:数据格式化
模型对格式有特定要求,Mistral采用简洁的指令格式:
def format_instruction(example):
"""将数据转换为Mistral期望的格式"""
prompt = f"""[INST] {example['instruction']} [/INST] {example['output']}</s>"""
return prompt
# 格式化所有训练数据
formatted_data = [format_instruction(ex) for ex in training_data]
格式重要性:
Mistral在训练时就通过[INST]和[/INST]标签区分用户指令和助手响应,</s>token表示响应结束。微调时使用完全一致的格式,才能确保模型理解对话结构。
若跳过格式化或使用错误标签,模型会生成混乱的输出,无法正确遵循指令。很多工程师会因此浪费数天时间调试,最终才发现是提示格式错误。
步骤5:配置LoRA
现在设置实际用于训练的适配层:
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
# 准备量化模型以进行训练
model.gradient_checkpointing_enable() # 反向传播时节省内存
model = prepare_model_for_kbit_training(model)
# 配置LoRA
lora_config = LoraConfig(
r=16, # 秩(rank),控制适配层容量
lora_alpha=32, # 缩放因子(通常为秩的2倍)
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # 目标注意力层
lora_dropout=0.05, # 正则化防止过拟合
bias="none",
task_type="CAUSAL_LM" # 因果语言模型任务
)
# 为模型添加LoRA适配层
model = get_peft_model(model, lora_config)
# 计算实际训练的参数比例
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
total_params = sum(p.numel() for p in model.parameters())
print(f"可训练参数: {trainable_params:,} ({100 * trainable_params / total_params:.2f}%)")
# 输出示例: Trainable: 134,217,728 (1.86%)
参数解析:
- r=16(秩):控制适配层容量。秩越高,参数越多,学习复杂模式的能力越强,但也会增加内存占用和过拟合风险。Mistral-7B建议从16开始,性能不足可尝试32或64,过拟合则尝试8。
- lora_alpha=32:适配层贡献的缩放因子,计算公式为
缩放比例 = lora_alpha / r,32/16=2倍权重贡献,这是标准比例,无特殊原因无需修改。 - target_modules:目标适配的注意力层,Mistral的标准注意力投影层为Query、Key、Value和Output。仅适配这四层即可用极少参数实现优秀性能,若需添加前馈层(gate_proj、up_proj、down_proj),会增加训练时间和内存占用,仅在注意力层适配效果不足时考虑。
- lora_dropout=0.05:训练时随机“关闭”5%的适配层权重,防止过拟合(模型无法过度依赖单一模式)。若数据集较小(<500个示例),可增至0.1。
步骤6:训练配置
from transformers import Trainer, TrainingArguments, DataCollatorForLanguageModeling
from datasets import Dataset
# 转换为Hugging Face数据集格式
dataset = Dataset.from_dict({"text": formatted_data})
# 数据分词函数
def tokenize_function(examples):
return tokenizer(
examples["text"],
truncation=True,
max_length=512,
padding="max_length"
)
# 批量分词(删除原文本列)
tokenized_dataset = dataset.map(
tokenize_function,
batched=True,
remove_columns=["text"]
)
# 训练参数配置
training_args = TrainingArguments(
output_dir="./mistral-medical-lora", # 输出目录
num_train_epochs=3, # 数据集遍历次数
per_device_train_batch_size=2, # 单GPU批次大小(70亿模型需减小)
gradient_accumulation_steps=8, # 梯度累积,有效批次大小=2*8=16
learning_rate=2e-4, # 学习率
logging_steps=10, # 每10步记录一次日志
save_steps=100, # 每100步保存一次检查点
save_total_limit=3, # 仅保留最新3个检查点
warmup_steps=50, # 学习率预热步数
fp16=True, # 混合精度训练(更快,更省内存)
optim="paged_adamw_8bit", # 内存高效优化器
report_to="none", # 禁用wandb/tensorboard(如需可启用)
)
# 初始化训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False) # 非掩码语言模型
)
# 开始训练
trainer.train()
训练时长:
根据数据集大小和GPU性能,训练耗时1-4小时不等,训练过程中会输出类似如下日志:
Step 10: Loss: 2.34
Step 20: Loss: 1.76
Step 30: Loss: 1.42
Step 40: Loss: 1.18
损失值(Loss)分析:
损失值应逐步下降,需关注以下模式:
- 健康训练:损失值从约2.5稳步降至0.8-1.2,说明模型在学习。
- 未学习:损失值始终维持在2.0-2.5,可能是学习率过低(可尝试3e-4)或数据格式错误。
- 过拟合:损失值降至接近0(如0.1-0.3),模型在“死记硬背”训练数据,需减少epoch、增加dropout或补充多样化数据。
- 梯度爆炸:损失值突然变为NaN或极大值,可能是学习率过高(可尝试1e-4)或数据损坏。
步骤7:模型保存与测试
# 保存LoRA适配层(70亿模型仅需约100MB)
model.save_pretrained("./mistral-medical-lora")
tokenizer.save_pretrained("./mistral-medical-lora")
# 测试推理函数
def generate_response(instruction):
prompt = f"[INST] {instruction} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=200, # 最大生成token数
temperature=0.7, # 随机性控制(0=确定,1=灵活)
top_p=0.9, # 核采样阈值
do_sample=True, # 启用采样(而非贪心解码)
pad_token_id=tokenizer.eos_token_id
)
# 解码并提取响应部分([/INST]之后的内容)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
response = response.split("[/INST]")[-1].strip()
return response
# 测试模型
print(generate_response("2型糖尿病的病因是什么?"))
结果判断:
- 若模型输出合理内容:恭喜!你已在消费级硬件上完成70亿参数模型的微调。
- 若输出无意义内容:可能需要更多训练数据,或数据格式存在问题。
快速调试清单:
- 模型输出随机token?检查提示格式,确保
[INST]和[/INST]使用正确。 - 模型重复指令?将temperature提高到0.8-1.0,或检查响应提取逻辑。
- 模型输出简短不完整?将max_new_tokens增加到300-500。
- 模型拒绝回答?可能微调数据中包含过多“无法回答”的示例,需检查训练数据。
背后的原理:微调究竟做了什么?
让我们揭开神秘面纱:基础Mistral模型已具备生成连贯文本、遵循指令和通用推理的能力,你并没有教它这些基础技能。
你真正教会它的,是你的领域特定模式、术语和响应风格。例如,模型学会了在面对医疗问题时,需用医疗术语和结构化解释来回应,遵循你数据集中的模式和规范。
LoRA适配层是插入模型注意力机制的小型神经网络层。训练过程中,基础模型始终保持“冻结”状态——72亿参数未做任何修改,仅训练1.34亿个适配层参数。这正是微调高效且省内存的原因。
推理时,模型会结合冻结的基础知识与你的专业适配层:基础模型提供语言理解和推理能力,适配层则将这些能力导向你的特定领域。
类比理解:Mistral就像一位会说50种语言的专业翻译,而你的LoRA适配层,相当于教这位翻译掌握医疗领域的专业词汇和规范。翻译的核心能力(语言转换)未变,只是多了领域专长。
内存真相:训练 vs 推理
大多数教程不会提及:训练所需内存远大于推理。
推理时(仅运行模型)
- 4位量化的Mistral-7B:约5GB显存
- LoRA适配层:约100MB
- 激活内存:约500MB
- 总计:约5.5GB
训练时(反向传播与优化)
- 模型权重:约5GB
- 梯度:约3GB(仅针对可训练参数,但仍可观)
- 优化器状态:约4GB(Adam优化器需存储每个参数的动量和方差)
- 激活检查点:约2GB(通过梯度检查点减少后)
- 总计:约14GB
这就是为什么8GB显存的GPU训练70亿参数模型会很紧张。前文提供的配置(批次大小=2、梯度累积=8、启用梯度检查点)是为适配8GB显存优化的,但仍处于临界状态。
内存不足的解决方案:
- 将批次大小减至1
- 将梯度累积增至16
- 将max_length从512减至256
- 使用更小的秩(如r=8而非16)
- 考虑使用更小的模型(如30亿参数模型而非70亿)
第六部分:部署实战——教程不会告诉你的生产级秘诀
你已拥有微调后的模型,在笔记本电脑上运行良好。现在需要将其部署到生产环境。
而这正是大多数教程的终点——它们只展示“幸福路径”:在Jupyter笔记本中训练模型、运行几个测试查询、庆祝成功,然后让你自己摸索如何落地。
接下来,我会告诉你后续步骤。生产环境中真正的问题往往出现在这些场景:
- 模型对某些输入随机失败,你完全找不到原因
- 延迟波动剧烈,部分查询耗时5秒,部分仅300毫秒
- 内存占用逐渐攀升,最终服务器在凌晨3点崩溃
- 用户抱怨响应结果不一致
让我们逐一解决这些问题。
框架选择:找到你的“趁手武器”
你已拥有微调后的Mistral模型,如何在生产环境中实际运行?
推理框架有数十种,各有取舍,选对框架能避免后续数周的迁移工作。下面为你节省试错成本。
1. llama.cpp:实用派首选
- 核心定位:C++推理引擎,编译后为单一二进制文件,无Python依赖、无版本冲突、无conda环境莫名崩溃的问题。
- 核心优势:
- 能在CPU上高效运行
- 量化处理能力优于其他框架
- 跨平台(Linux、Mac、Windows,甚至树莓派)
- 技术成熟稳定,“只管干活不添麻烦”
- 适用场景:
- 部署到无GPU的服务器
- 边缘设备(物联网、移动设备、嵌入式系统)
- 优先考虑可靠性而非前沿功能
- 希望系统5年后仍能正常运行无需更新
该框架的作者Georgi Gerganov会针对每种CPU架构(Apple Silicon、x86、ARM)进行极致优化。
2. vLLM:高性能之选
- 核心定位:GPU优化的推理服务器,专为高吞吐量设计,核心秘诀是“持续批处理(continuous batching)”——动态将多个请求批量处理,最大化GPU利用率。
- 核心优势:
- 可处理每分钟数千次请求
- 最大化GPU利用率(相同硬件下查询量提升10倍)
- 高吞吐量场景下成本极低
- 适用场景:
- 拥有GPU资源
- 高查询量(>1000次/分钟)
- 延迟并非首要约束(200-500毫秒可接受)
- 成本优化至关重要
单块A100 GPU搭配vLLM,处理的流量相当于10块GPU运行普通推理的效果。若你需要每分钟处理数千次请求,vLLM节省的基础设施成本足以覆盖其学习成本。
3. ONNX Runtime:企业级兼容之选
- 核心定位:微软推出的跨平台推理运行时,模型一次转换,即可在任意平台(Windows、Mac、Linux、ARM、x86)运行。
- 核心优势:
- 跨平台兼容性强
- 可与.NET/C++/Java等语言集成
- 适配企业级生产环境
- 稳定且文档完善
- 适用场景:
- 需要跨平台部署
- 需与现有企业基础设施集成
- 需要厂商支持和长期稳定性
模型转换过程可能偶尔遇到问题,但一旦转换完成,部署流程会非常顺畅。
决策矩阵
按回车键或点击可查看完整图片
本部分将重点介绍llama.cpp(通用性最强)和vLLM(性能最高),这两种框架可覆盖90%的生产级部署场景。
基于llama.cpp的部署
要将Mistral模型部署到生产环境,首先需将其转换为llama.cpp支持的格式。
步骤1:转换为GGUF格式
GGUF是llama.cpp的专用模型格式,优化了加载速度和推理效率。
# 克隆llama.cpp仓库
git clone <https://github.com/ggerganov/llama.cpp>
cd llama.cpp
# 编译(生成可执行文件)
make
# 将微调后的模型转换为GGUF格式
python convert-hf-to-gguf.py \\
/path/to/your/mistral-medical-lora \\ # 你的微调模型路径
--outfile mistral-lora.gguf \\ # 输出文件名
--outtype f16 # 输出精度(16位浮点数)
转换后会生成全精度(16位浮点数)的GGUF文件,Mistral-7B模型约为14GB,下一步需进行量化。
步骤2:生产级量化
量化的核心是在模型大小和性能之间找到平衡,以下是常用量化命令:
# 4位量化(大多数场景的推荐选择)
./quantize mistral-medical.gguf mistral-medical-Q4_K_M.gguf Q4_K_M
# 5位量化(更高精度,更大体积)
./quantize mistral-medical.gguf mistral-medical-Q5_K_M.gguf Q5_K_M
# 8位量化(接近原始精度)
./quantize mistral-medical.gguf mistral-medical-Q8_0.gguf Q8_0
量化级别说明:
| 量化级别 | 内存占用 | 精度损失 | 速度 | 适用场景 |
|---|---|---|---|---|
| Q4_K_M(4位) | ~4.1GB | 通常1-3% | 快,内存高效 | 默认选择,平衡性能与成本 |
| Q5_K_M(5位) | ~4.8GB | 通常<1% | 略慢于Q4 | 精度优先,可接受稍大内存占用 |
| Q8_0(8位) | ~7.2GB | 通常<0.5% | 慢于Q4/Q5 | 需接近原始精度,内存充足场景 |
“K_M”后缀代表量化方法,llama.cpp会针对不同层类型采用不同技术,“K”类方法是较新的优化方案,能在激进压缩的同时保持精度。
量化后与原模型的精度差异几乎难以察觉,但内存节省效果显著——70亿参数模型从14GB降至4GB,这意味着无需昂贵的GPU服务器,用200美元的二手工作站即可运行。
步骤3:启动推理服务器
llama.cpp内置生产级HTTP服务器,启动命令如下:
./server \\
-m mistral-medical-Q4_K_M.gguf \\ # 量化后的模型文件
-c 4096 \\ # 上下文长度(模型可处理的最大token数)
-t 8 \\ # CPU线程数(匹配核心数)
-ngl 35 \\ # GPU层数量(如有GPU)
--port 8080 \\ # 端口号
--host 0.0.0.0 # 监听所有网络接口
该服务器提供与OpenAI兼容的API,这意味着你的应用代码无需修改——无论调用OpenAI API还是本地模型,代码逻辑完全一致。
步骤4:调用API
import requests
import json
def query_model(instruction, temperature=0.7):
"""通过HTTP API查询部署的模型"""
url = "<http://localhost:8080/v1/chat/completions>"
payload = {
"messages": [
{
"role": "user",
"content": instruction
}
],
"temperature": temperature,
"max_tokens": 200,
"stream": False # 关闭流式输出
}
response = requests.post(url, json=payload)
result = response.json()
return result['choices'][0]['message']['content']
# 测试API调用
answer = query_model("2型糖尿病的症状有哪些?")
print(answer)
这与调用OpenAI API的逻辑完全一致。若你之前用GPT-4构建了原型,只需修改API地址,即可切换到本地模型,无需重写代码——这就是标准接口的力量。
步骤5:流式输出提升用户体验
用户讨厌等待,流式输出能在生成token时实时展示,让响应“感觉更快”。
def query_model_streaming(instruction):
"""流式获取模型生成的token"""
url = "<http://localhost:8080/v1/chat/completions>"
payload = {
"messages": [{"role": "user", "content": instruction}],
"temperature": 0.7,
"max_tokens": 200,
"stream": True # 启用流式输出
}
# 发起流式请求
response = requests.post(url, json=payload, stream=True)
for line in response.iter_lines():
if line:
# 解析SSE(Server-Sent Events)格式
line = line.decode('utf-8')
if line.startswith('data: '):
data = line[6:] # 移除前缀'data: '
if data == '[DONE]': # 流式结束标志
break
try:
chunk = json.loads(data)
# 提取当前token(无则返回空字符串)
token = chunk['choices'][0]['delta'].get('content', '')
if token:
print(token, end='', flush=True) # 实时打印token
except json.JSONDecodeError:
continue
print() # 结束后换行
# 测试流式输出
query_model_streaming("解释胰岛素抵抗的发展过程。")
你会看到token逐个生成,与ChatGPT的体验一致。虽然完整响应的总耗时不变,但“感知延迟”会大幅降低——用户可在模型生成的同时开始阅读。
基于vLLM的部署(高吞吐量GPU服务)
若你拥有GPU且需处理每分钟数百至数千次请求,vLLM是最佳选择。
其核心技术是“分页注意力(PagedAttention)”——像操作系统管理内存一样管理注意力缓存(KV cache)。传统推理会为最大序列长度预分配内存,造成大量浪费;而vLLM仅动态分配所需内存,并在请求间共享内存。
最终效果:相同硬件下,吞吐量提升10-20倍。
步骤1:安装vLLM
pip install vllm # 注意:原命令可能存在笔误,正确包名为vllm
步骤2:启动服务器
from vllm import LLM, SamplingParams
# 初始化模型
llm = LLM(
model="/path/to/your/mistral-medical-lora", # 微调后的模型路径
tensor_parallel_size=1, # GPU数量(单GPU设为1)
max_model_len=4096, # 最大上下文长度
gpu_memory_utilization=0.9, # GPU内存利用率(使用90%)
quantization="awq" # 可选:启用AWQ量化提升速度
)
# 或通过命令行启动HTTP服务器
# python -m vllm.entrypoints.openai.api_server \\
# --model /path/to/your/mistral-medical-lora \\
# --port 8000
步骤3:批量处理
vLLM在批量请求场景下优势显著:
from vllm import SamplingParams
# 定义采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=200
)
# 批量输入提示
prompts = [
"2型糖尿病的病因是什么?",
"解释胰岛素抵抗。",
"糖尿病的风险因素有哪些?",
# ... 可添加数百个更多请求
]
# vLLM自动批量处理以最大化GPU利用率
outputs = llm.generate(prompts, sampling_params)
# 输出结果
for output in outputs:
print(f"提示: {output.prompt}")
print(f"响应: {output.outputs[0].text}")
print("---")
单块A100 GPU运行vLLM时,70亿参数模型可处理每秒50-100次请求,相当于每天400-800万次请求。若用普通推理方式,需10-20块GPU才能达到同等吞吐量。
量化深度解析
你已见识了量化的效果,现在来理解其背后的原理。
神经网络权重通常以32位或16位浮点数存储,量化则将其转换为8位、4位甚至2位整数——本质是丢弃部分精度。关键问题是:在模型性能崩溃前,能丢弃多少精度?
无效方案:简单量化
直接将权重四舍五入为整数会彻底破坏模型。例如,0.0001这样的权重对某些计算至关重要,若直接舍为0,会导致模型功能失效。
有效方案:智能量化
核心思路是按层分析权重分布:不同层对精度的敏感度不同,针对不同层类型采用不同量化策略。
llama.cpp的“K”类量化方法正是如此:对注意力层(Q、K、V投影层)采用更高精度的量化,而对前馈层采用更激进的压缩,因为前馈层对精度损失的容忍度更高。
不同量化级别的精度变化
以原始模型(FP16)为100%基准精度,不同量化级别的表现如下:
- Q8_0:99.5%精度,差异几乎无法察觉
- Q5_K_M:98-99%精度,仅在边缘案例中存在轻微性能下降
- Q4_K_M:96-98%精度,复杂推理场景下差异明显,但满足大多数任务需求
- Q3_K_M:92-95%精度,性能开始不稳定,仅在内存极度紧张时使用
- Q2_K:85-90%精度,输出仍连贯但错误频繁
对于生产环境,Q4_K_M是“黄金平衡点”——内存占用减少75%,精度损失仅2-4%,大多数用户无法察觉差异。
量化效果的评估方法
不要凭感觉判断,需通过数据量化评估:
def evaluate_quantization(test_cases, model_original, model_quantized):
"""对比量化模型与原始模型的表现"""
results = {
'exact_match': 0, # 完全匹配
'similar': 0, # 相似
'different': 0 # 差异显著
}
for test in test_cases:
# 获取两个模型的响应
response_orig = model_original.generate(test['prompt'])
response_quant = model_quantized.generate(test['prompt'])
# 结果判断(生产环境需使用更严谨的评估指标)
if response_orig == response_quant:
results['exact_match'] += 1
elif similar_enough(response_orig, response_quant): # 自定义相似性阈值
results['similar'] += 1
else:
results['different'] += 1
# 打印差异案例,便于分析
print(f"差异案例: {test['prompt']}")
print(f"原始模型: {response_orig}")
print(f"量化模型: {response_quant}\\n")
# 输出评估结果
print(f"完全匹配率: {results['exact_match'] / len(test_cases):.1%}")
print(f"相似响应率: {results['similar'] / len(test_cases):.1%}")
print(f"差异响应率: {results['different'] / len(test_cases):.1%}")
部署量化模型前,需用100-200个测试案例运行评估。若“差异响应率”超过10%,说明量化级别过于激进,需选择更高精度的量化方案。
生产环境中的隐藏问题
让我们聊聊生产环境中实际会遇到的问题。
问题1:长上下文导致内存激增
模型处理多数查询正常,但遇到长对话时突然崩溃。
根源:KV缓存(注意力缓存)随上下文长度增长而扩大。
对于4位量化的70亿参数模型,每个token约占用0.5MB缓存,2000token的对话仅缓存就需1GB内存。
解决方案1:上下文裁剪
def smart_context_pruning(conversation_history, model, max_tokens=2000):
"""将上下文控制在限制内,同时保留关键信息"""
# 拼接完整对话并计算token数
full_context = "\\n".join(conversation_history)
token_count = len(model.tokenize(full_context))
# 若未超限制,直接返回
if token_count <= max_tokens:
return full_context
# 策略1:保留系统提示 + 最近对话
system_prompt = conversation_history[0]
recent_messages = conversation_history[-5:] # 保留最后5轮对话
pruned_context = system_prompt + "\\n" + "\\n".join(recent_messages)
# 策略2:若仍超限制,截断最近对话
if len(model.tokenize(pruned_context)) > max_tokens:
tokens = model.tokenize(pruned_context)
pruned_tokens = tokens[-max_tokens:] # 保留最后max_tokens个token
pruned_context = model.detokenize(pruned_tokens)
return pruned_context
更优方案:定期总结历史上下文
def maintain_context_with_summary(conversation, model, summary_threshold=1500):
"""当上下文过长时,总结历史对话"""
# 计算当前对话的token总数
token_count = len(model.tokenize("\\n".join(conversation)))
if token_count > summary_threshold:
# 拆分历史对话与近期对话
old_messages = conversation[:-3] # 需总结的历史对话
recent_messages = conversation[-3:] # 保留的近期对话
# 生成历史对话总结
summary_prompt = f"用2-3句话总结以下对话:\\n{old_messages}"
summary = model.generate(summary_prompt)
# 重构对话:总结 + 近期对话
conversation = [f"历史对话总结:{summary}"] + recent_messages
return conversation
问题2:非确定性输出导致测试失败
你为模型编写了测试,本地运行通过,但在持续集成(CI)环境中失败——模型对相同输入输出不同结果。
根源:采样机制。当temperature>0时,模型会从概率分布中随机选择token,导致相同输入可能产生不同输出。
测试环境解决方案:确定性生成
def deterministic_generate(model, prompt):
"""生成可复现的输出"""
return model.generate(
prompt,
temperature=0.0, # 关闭随机性
do_sample=False, # 禁用采样,使用贪心解码
top_k=1, # 始终选择概率最高的token
seed=42 # 固定随机种子(需框架支持)
)
生产环境建议:
- 需一致性的任务(分类、信息提取):设置temperature=0
- 创意类任务(写作、头脑风暴):设置temperature=0.7-1.0
问题3:偶尔出现无意义输出
模型99%的时间表现正常,但偶尔会输出“aaaaaaaaa”这类无意义内容,或重复同一短语数十次。
根源:模型陷入重复循环,或遇到异常概率峰值。
解决方案:添加重复惩罚与停止条件
def generate_with_safety_guards(model, prompt):
"""生成时添加防护机制,避免常见故障"""
output = model.generate(
prompt,
max_tokens=200,
temperature=0.7,
repetition_penalty=1.2, # 重复token惩罚(>1.0有效)
no_repeat_ngram_size=3, # 禁止重复3个token的序列
early_stopping=True, # 自然结束时停止生成
bad_words_ids=None, # 可配置禁止生成的特定token
eos_token_id=model.config.eos_token_id
)
# 后处理:若输出过度重复,重新生成
if is_repetitive(output):
output = model.generate(prompt, temperature=0.9) # 提高随机性重试
return output
def is_repetitive(text, threshold=0.3):
"""检测文本是否存在过度重复"""
words = text.split()
if len(words) < 10: # 短文本无需检测
return False
# 计算词的唯一率(越低重复度越高)
unique_ratio = len(set(words)) / len(words)
return unique_ratio < threshold # 低于阈值判定为过度重复
问题4:延迟不稳定
多数查询300毫秒内完成,部分却需2秒,用户能明显感知差异。
根源:序列长度可变。输出越长,生成耗时越久,且token生成是串行过程。
解决方案:设置固定token限制并启用流式输出
async def query_with_timeout(model, prompt, timeout_seconds=2.0):
"""确保响应在超时时间内完成"""
import asyncio
async def generate():
# 限制最大token数,确保延迟可控
return model.generate(prompt, max_tokens=100, stream=True)
try:
# 超时控制
return await asyncio.wait_for(generate(), timeout=timeout_seconds)
except asyncio.TimeoutError:
# 超时 fallback:返回友好提示
return "响应时间过长,请尝试更简单的问题。"
关键建议:
对于延迟要求严格的场景,需缩短max_tokens限制。70亿参数模型每秒约生成20-30个token,若需确保延迟<500毫秒,建议将max_tokens限制为10-15个。
生产环境监控
“无法衡量的东西,就无法改进”,以下是需要监控的核心指标:
import time
import logging
from collections import deque
from dataclasses import dataclass
from typing import Optional
# 推理指标数据类
@dataclass
class InferenceMetrics:
latency: float # 推理延迟(秒)
tokens_generated: int # 生成的token数
error: Optional[str] = None # 错误信息(无则为None)
class ProductionMonitor:
def __init__(self, window_size=1000):
# 滑动窗口存储指标,默认保留1000个样本
self.metrics = deque(maxlen=window_size)
self.total_requests = 0 # 总请求数
def log_inference(self, latency, tokens=0, error=None):
"""记录每次推理请求的指标"""
self.total_requests += 1
self.metrics.append(InferenceMetrics(latency, tokens, error))
def get_stats(self):
"""计算当前性能统计数据"""
if not self.metrics:
return {}
# 过滤无错误的延迟数据和有错误的请求
latencies = [m.latency for m in self.metrics if not m.error]
errors = [m for m in self.metrics if m.error]
sorted_lat = sorted(latencies) # 排序延迟数据,便于计算分位数
return {
'p50_latency_ms': sorted_lat[len(sorted_lat)//2] * 1000, # 50分位延迟(毫秒)
'p95_latency_ms': sorted_lat[int(len(sorted_lat)*0.95)] * 1000, # 95分位延迟
'p99_latency_ms': sorted_lat[int(len(sorted_lat)*0.99)] * 1000, # 99分位延迟
'error_rate': len(errors) / len(self.metrics), # 错误率
'avg_tokens': sum(m.tokens_generated for m in self.metrics) / len(self.metrics), # 平均token数
'total_requests': self.total_requests # 总请求数
}
def check_health(self):
"""检测性能是否退化,触发告警"""
stats = self.get_stats()
# P95延迟过高告警(示例阈值1000毫秒)
if stats.get('p95_latency_ms', 0) > 1000:
logging.warning(f"P95延迟过高:{stats['p95_latency_ms']:.0f}毫秒")
# 错误率过高告警(示例阈值5%)
if stats.get('error_rate', 0) > 0.05:
logging.error(f"错误率过高:{stats['error_rate']:.1%}")
# 初始化监控器
monitor = ProductionMonitor()
def monitored_inference(model, prompt):
"""包装推理函数,添加监控逻辑"""
start = time.time()
error = None
tokens = 0
try:
response = model.generate(prompt)
tokens = len(model.tokenize(response)) # 计算生成的token数
return response
except Exception as e:
error = str(e)
raise # 重新抛出异常,不影响业务逻辑
finally:
# 记录指标(无论成功失败)
monitor.log_inference(time.time() - start, tokens, error)
# 每处理100个请求,打印统计数据并检查健康状态
if monitor.total_requests % 100 == 0:
print(monitor.get_stats())
monitor.check_health()
核心监控指标
- P50/P95/P99延迟:了解延迟分布,P95/P99延迟更能反映用户遇到的极端情况
- 错误率:提前发现可靠性问题,避免大规模故障
- 每秒token数:监控生成速度,及时发现性能下降
- 内存占用:检测内存泄漏,防止服务器崩溃
- CPU/GPU利用率:优化资源分配,避免浪费或过载
告警策略
当指标超出阈值时需触发告警:
- P95延迟突然翻倍,可能存在性能瓶颈
- 错误率超过1%,需立即排查原因
第七部分:真正的机遇
大多数企业尚未意识到这一趋势的重要性。他们认为“人工智能”就是“调用OpenAI API”,为特定任务浪费资金使用通用模型,容忍3秒的延迟只因不知有替代方案,甚至因合规团队拒绝云端API而完全放弃人工智能。
而你现在掌握了更优的方案。
你知道70亿参数模型经领域数据微调后,在特定任务上能超越通用大模型;知道Q4_K_M量化能减少75%内存占用,且精度损失极小;知道llama.cpp可在CPU上实现亚秒级延迟;知道本地部署能解决云端API无法突破的合规难题。
这种认知本身就是一种优势——趁大多数人还不知道小型语言模型的存在,充分利用这一优势。
如今成功落地人工智能产品的企业,并非使用最大的模型,而是选择“尺寸合适”的模型:用自己的数据微调、在自己的基础设施上部署、为自己的特定场景优化。
这就是机遇所在:打造特定场景的解决方案,极致优化,交付给有需要的用户。
总结与后续步骤
你已学到
- Transformer的工作原理(注意力机制、多头注意力、层架构)
- 何时构建小型语言模型,何时使用API(基于合规、成本、延迟的决策框架)
- 如何用LoRA在消费级硬件上微调70亿参数模型
- 如何用llama.cpp(CPU)和vLLM(GPU)实现生产级部署
- 生产环境中的实际问题及解决方案
你的下一步实践
- 选择一个你熟悉的细分领域(工作内容、爱好、特定任务)
- 收集200个“指令-响应”对
- 使用本文提供的代码微调Mistral-7B模型
- 用llama.cpp部署模型
- 在20个测试案例上对比模型与GPT-4的表现
如果本文对你有帮助,请分享给他人,尤其是那些仍在为API每月花费1万美元,而本地模型即可满足需求的同事。
人工智能的未来已来,它运行在你已拥有的硬件上,为你实际面临的问题提供解决方案。
现在,开始动手构建吧。
参考资料与延伸阅读
研究论文
- 《Attention Is All You Need》——Transformer的原始论文
- 《LoRA: Low-Rank Adaptation》——参数高效微调技术论文
工具与框架
- llama.cpp——适用于LLM的CPU推理框架
- vLLM——高吞吐量GPU推理框架
- Hugging Face Transformers——模型库与训练框架
模型推荐
- Mistral-7B——优秀的微调基础模型
- Phi-3——微软推出的高效小模型
- Qwen2——阿里巴巴的多语言小型语言模型系列
关注“AI拉呱”,评论+转发此文即可私信获取一份教程+一份学习书单!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)