3. Context Engineering: Sessions & Memory ——【Google 5-Day AI Agents】
*核心主题:**聚焦上下文工程(),明确其两大核心组成部分为 “会话(Sessions)” 与 “记忆(Memory)”,强调该工程通过将对话历史、记忆、外部知识等必要信息动态整合到 LLM 的上下文窗口中,实现从简单对话交互到持久化、可行动智能的转化,且整个过程依赖会话与记忆两大系统的相互作用。核心角色:负责 “当下” 交互,是单轮对话的低延迟、按时间顺序排列的容器。主要挑战:需平衡性能与安全
1. 白皮书
第三天的白皮书探讨了上下文工程的相关内容,通过 Sessions(单次实时会话历史)和 Memory(长期持久化记忆)整合管理 LLM 的上下文窗口,从而实现了有状态的 Agent
- Context Engineering: 动态组合和管理 LLM 的上下文窗口内信息,实现有状态 Agent 的过程。
- Sessions: 和 Agent 完整对话的存储容器,包括对话完整链路以及过程中 Agent 产生的记忆。
- Memory: 长期保存记忆机制,跨多个会话捕获并整合信息,为 LLM Agent 提供连贯的个性化的经验
1.1. Context Engineering
LLM 自身是无状态的:除了训练数据之外,它们的推理和感知能力仅限于单次API调用的“上下文窗口”中提供的信息。
开发者需要在每个回合的对话都构造上下文(指令、Tools、知识、数据、定义等)来实现能够记忆、学习并可以个性化交互的有状态的 Agent 。
Context Engineering 是 Prompt Engineering 的演进:后者仅局限于设计最优的静态系统指令;前者则基于用户、对话历史和外部数据策略性的选择、总结、注入 LLM 高相关性低干扰性的信息。Agent 框架必须协调这些外部 context 存储系统(RAG、session stores、memory managers)获取并整合成上下文作为最终Prompt。
Context Engineering 主导复杂信息载荷(LLM工作所需的全部有效信息)的动态组装:
- 推理基础
- 系统指令:定义 Agent 角色、能力和限制
- 工具定义:Tools 说明书
- 少量示例:功能示例(输入->输出)
- 证据支撑
- 长期记忆:夸会话的持久性知识
- 外部知识:数据库、文档等外部知识
- 工具输出:Tools 返回结果
- Sub-Agent 输出:子 Agent 的结果
- 非text数据:文件、图片等
- 当前语境
- 会话历史:当前会话历史轮次消息
- 暂存状态:当前内存中的 State
- 用户提示词:用户即时指令
构建一个具备上下文感知能力的 Agent 最大的挑战之一是管理不断增长的对话历史。
随着上下文规模的扩大不但成本和延迟也会增加,还可能遭遇 context rot(上下文腐烂)现象——即随着上下文内容增多,模型对关键信息的关注能力会逐渐下降。
Context Engineering 通过采用动态调整历史记录的策略(如总结、选择性删减或压缩技术)直接应对这一问题,在控制总 token 数量的同时保留重要信息,最终实现更稳定且更具个性化的人工智能体验。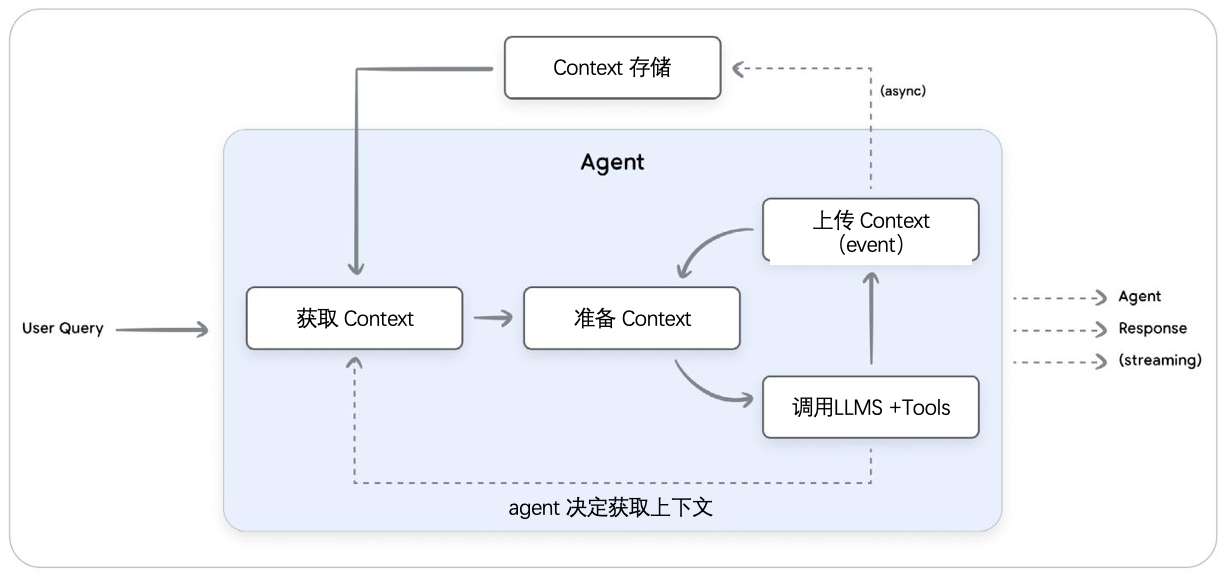
- 获取 Context:根据用户查询检索相关的上下文记忆
- 准备 Context:动态构造完整的 Prompt
- 调用LLM Tools:循环调用 LLM+Tools 并将结果加入到上下文中直到 END
- 上传 Context:将本轮工作新知识持久化到外部系统
上述流程核心组件:sessions(管理单次对话的逐轮状态) and memory(长期保存,用于捕获和整合多个会话中的关键信息)
1.2. Sessions
Sessions(会话):单次连续和 LLM 的聊天记录和工作记忆。会话使 Agent 能够在单次对话范围内保持上下文并提供连贯的响应。每个会话都是特定交互的独立、不相连的日志,包含两个关键组成部分:
- events: 按时间顺序排列的历史记录(用户输入、LLM输出、工具调用及输出) (LangGraph的Message)
- state: Agent 的工作记忆(结构化存储与当前会话相关的临时数据)
1.2.1. 框架和模型之间的差异
虽然原理相同,不同 Agent 框架以不同的方式实现sessions、events和state。Agent 框架负责为 LLM 维护对话历史和 state,利用这些上下文构建 LLM 请求,并解析和存储 LLM 的响应。
Agent 框架是代码(开发者)和LLM翻译器,并且可以将 Agent 和 LLM 厂商解耦(支持多模型)。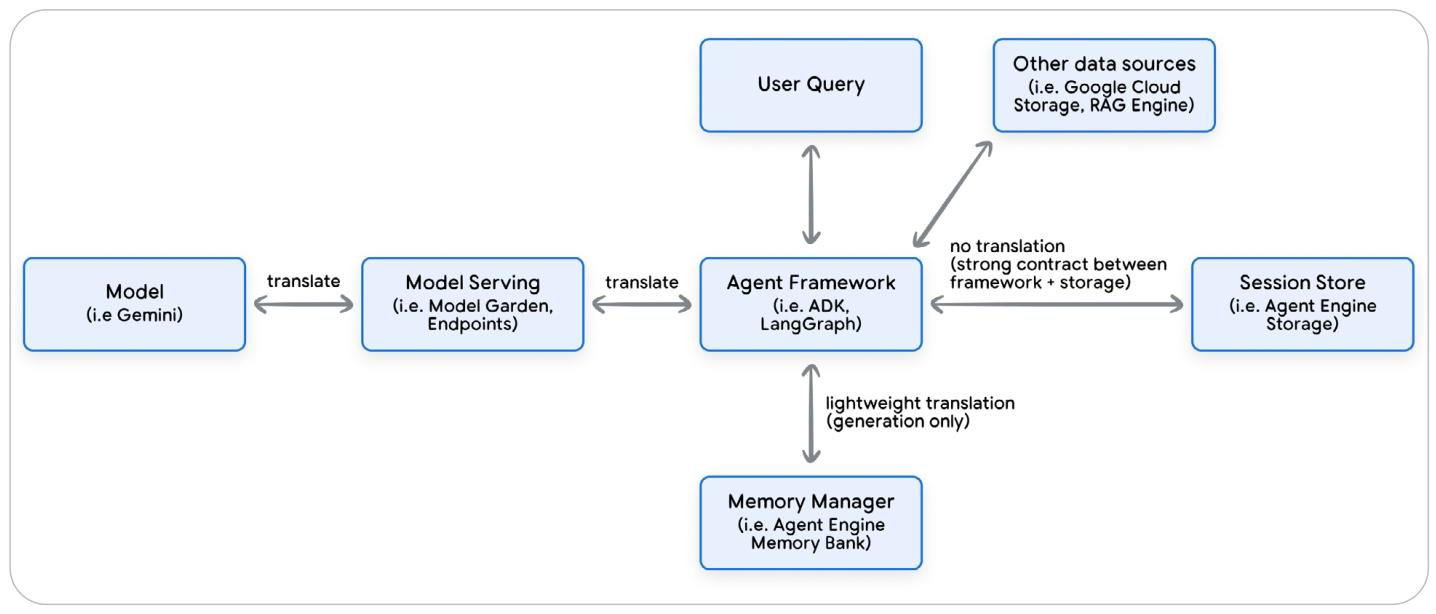
Agent 框架最终目标:生成 LLM 理解的请求(Prompt)。
ADK:Session(Event+State)
LangGraph:State(Message+Data)
1.2.2. 多智能体系统的 Sessions
多 Agents 协同工作时,每个 Agent 专注更细更专业的任务,多 Agents 间需要共享信息才能高效协作。
下图展示了几种类型的多 Agents 架构,不同架构共享信息模式有所不同,这些架构的核心组成部分就是如何处理持久化的 session 会话历史交互。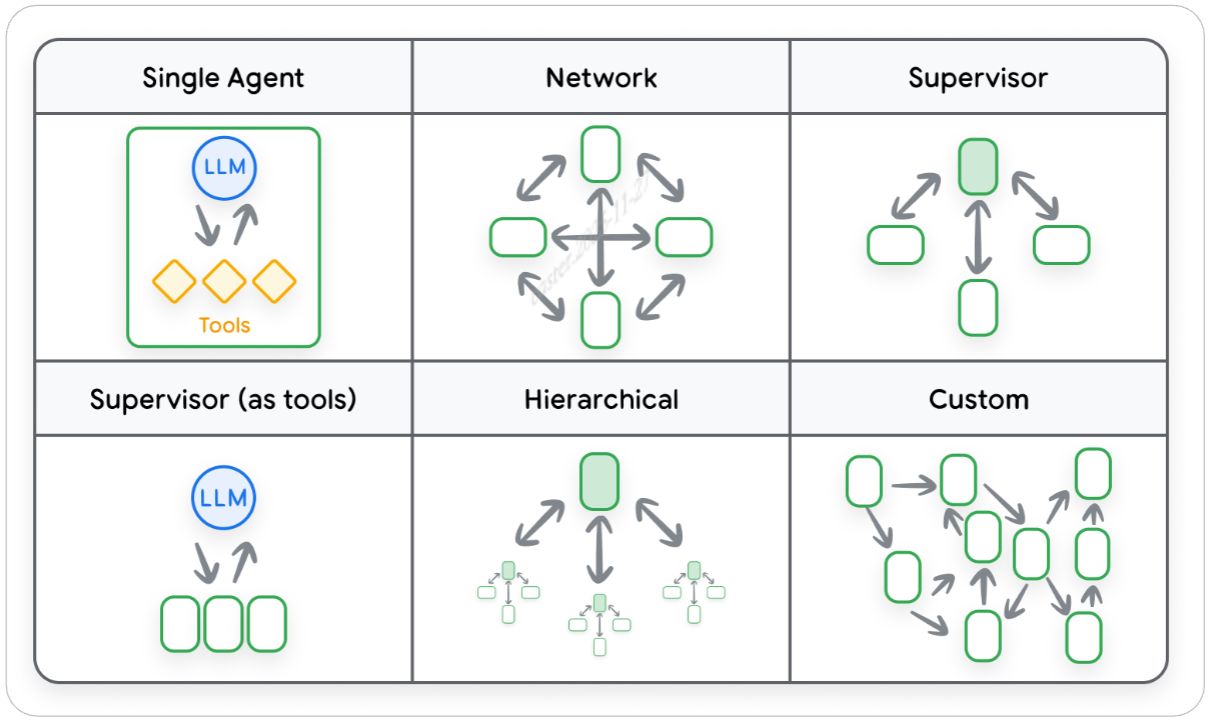
Sessions 和 Context 不同,Agent 可能仅从 Sessions 中截取片段 + 一些指导描述来构造 Context。
- Sessions:整个对话链路的完整持久性记录
- Context:每次和LLM对话构造的 Prompt
Agent 框架通过两种主要方式之一来 multi-agent 系统的 sessions:
- 多个 Agent 共享统一的会话历史(单一log)
- 每个 Agent 维护各自的会话历史,只和其他Agent分享最终输出(Agent-as-a-tool or A2A)
多个智能体框架间的交互
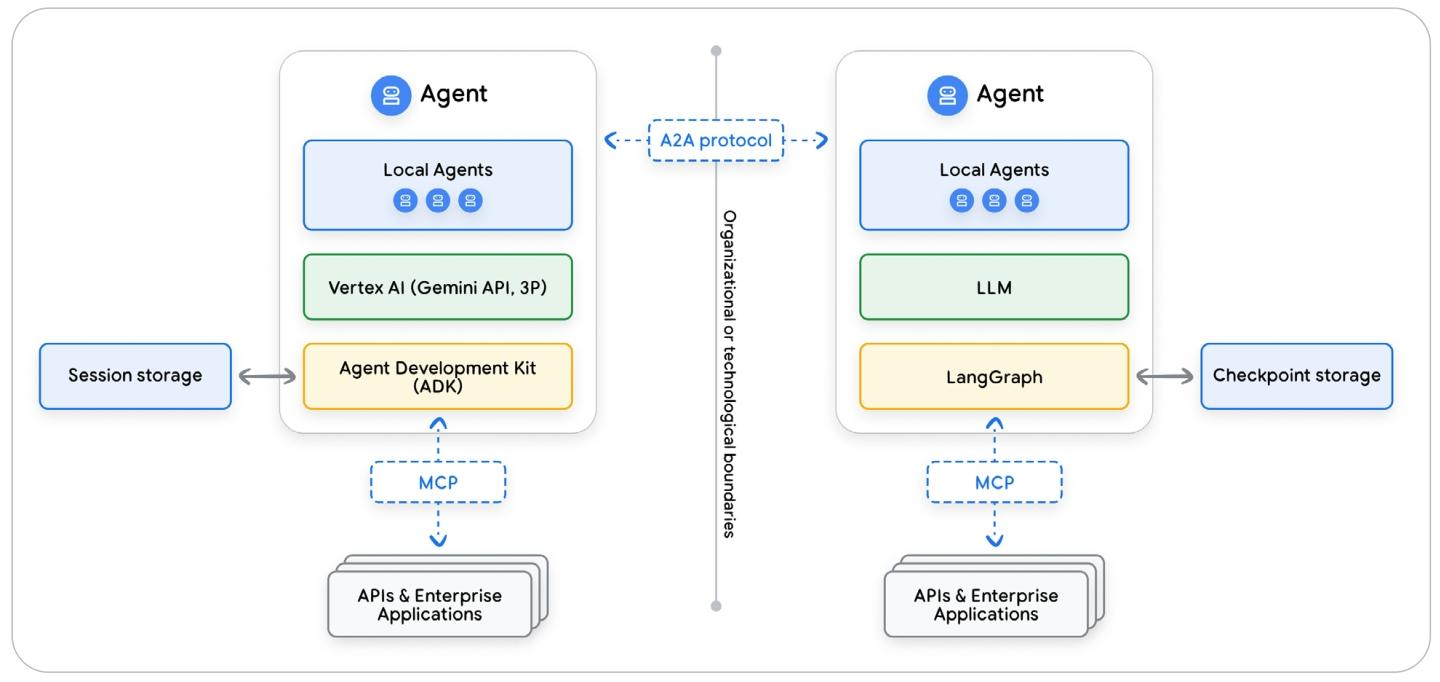
框架对 Sessions(event+state) 数据的抽象,使 Agent 与 LLM 之间解耦,也将其与其他框架的 Agent 隔离开来,且在 Sessions 持久化存储后更难互通。
Agent-to-Agent 旨在协调这些孤立的 Agent 之间的通信。但由于每个 Agent 的会话历史都编码在其框架的内部结构中,任何包含会话事件的A2A消息都需要一个转换层才能发挥作用。
另一种更稳健的互操作 Agent 性架构模式:将共享知识抽象到一个与框架无关的数据层中,例如内存中,以字符串或字典(Python结构)的形式存储,这样就实现了框架与sessions之间的解耦。
1.2.3. Sessions 生产环境
生产环境中,Sessions 管理系统需要具备:安全性与隐私性、数据完整性以及性能。
1.2.4. 长上下文管理:权衡和优化
- Context Window Limits:LLM 具备最上下文窗口限制
- API 成本 ($):LLM 按 token 计费
- 延迟 (Speed):上下文长度会影响 LLM 处理速度
- 质量:token 量增加,LLM 注意力下降
如何控制发送到 LLM 的上下文恰到好处,够用但是不冗余:
- 保留近 N 轮对话
- 根据 LLM 最大窗口进行截断
- 总结替换全量(异步后台+持久化):可以基于计数、时间或者event触发
1.3. Memory
Memory 是从 Sessions(短期记忆) 中提取的浓缩数据,会在多个 Sessions 中持续存在。
Memory Manager 负责使用原始数据结构管理 Memory,达到跨框架 Agent 使用的效果。
存储和检索 Memory 对于构建复杂且智能的 Agent 至关重要。一个强大的记忆系统应该具备以下能力:
- 个性化:记住用户偏好、事实知识和过往互动
- 上下文窗口管理:通过生成摘要或者压缩上下文减少 context
- 数据挖掘与洞察: 通过用户 sessions 总结发觉潜在消息面
- Agent 自我提升与适应:Agent 记录自己的表现(成功\失败)生成方案手册。
创建、存储和使用 Memory 是 Agent 系统的协作过程,Agent 最终用户和开发者的代码都有其价值:
- 用户:记忆中最开始的原始数据源
- Agent(开发者代码):控制何时记住什么,何时应该生成、检索记忆
- Agent 框架:提供与 Memory 交互的结构和工具
- Session 存储:存储一轮轮的会话
- Memory 管理系统:存储、检索和压缩 Memory
- Extraction:从源数据中提炼关键信息
- Consolidation:整理记忆以合并重复的实体
- Storage:将记忆持久化到永久性数据库中
- Retrieval:获取相关记忆,为新的交互提供上下文
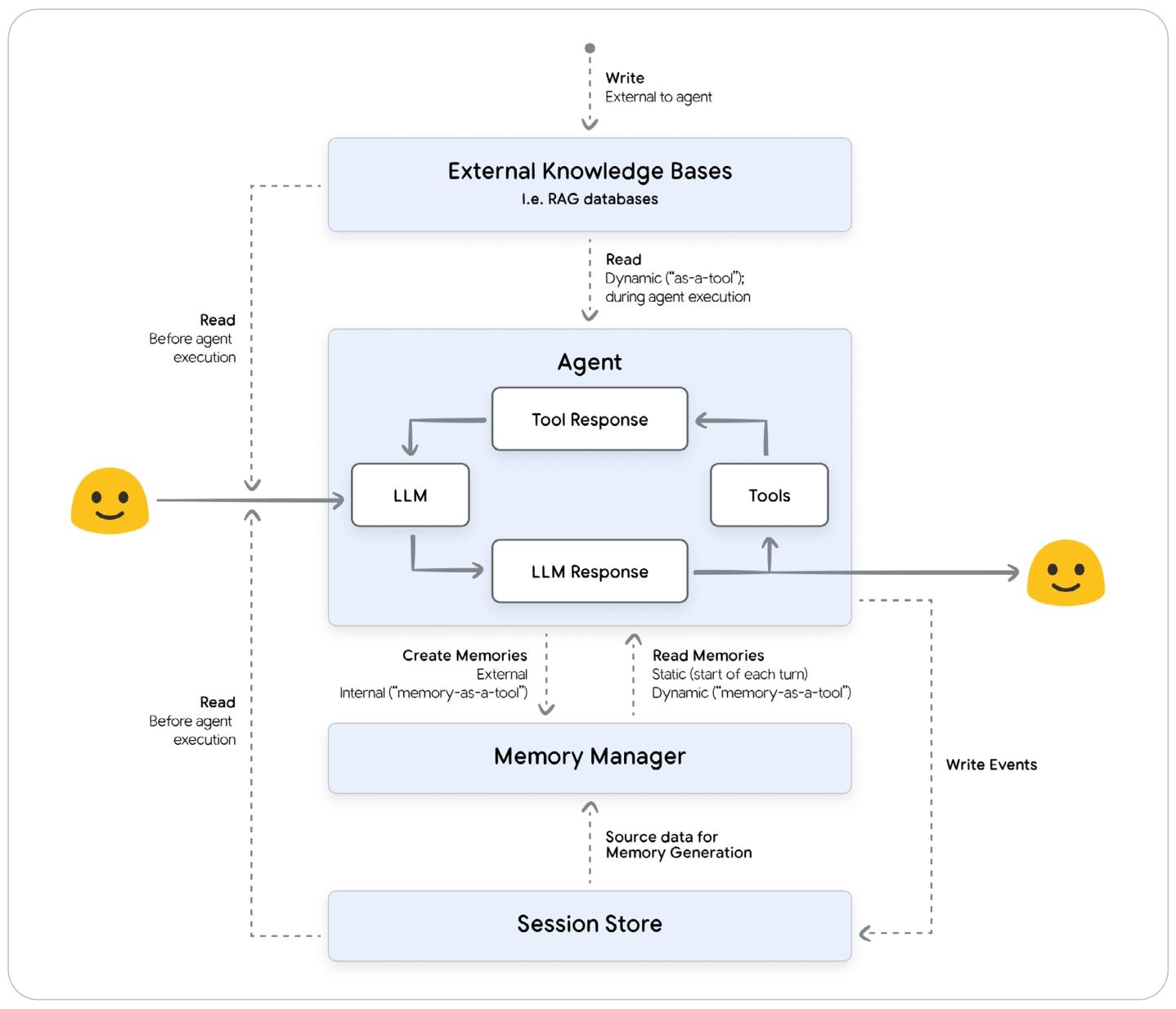
Memory Manager 和 RAG 不同
RAG:静态外部数据知识
Memory Manager:动态用户特性上下文
1.3.1. Memory 类型
Memory 是描述性的,而非预测性的,组成部分:
Content: 原始会话中提取的部分主要信息。
Metadata: 这段记忆的上下文:拥有者、来源、标签等
1.3.1.1. 信息类型
Memory 根据其代表的知识类型可以分为:
- 陈述性记忆:知道是什么:Agent 对事实、数据和事件的知识。既包括一般的世界知识(语义性知识),也包括特定的用户事实(实体/情景性知识)。
- 程序性记忆:知道怎么做:技能和工作流程的知识。如何指导 Agent 正确执行任务。
1.3.1.2. 组织模型
记忆管理器主要通过三种核心模式组织记忆,每种模式对应不同的信息关联逻辑与应用场景,具体总结如下:
- 集合模式(Collections):为单个用户将记忆整理为多个独立的自然语言片段,每个片段对应一个具体事件、摘要或观察结果,同一核心主题下可包含多个记忆;该模式适用于存储和检索与特定目标或主题相关的、结构较松散的大量信息。
- 结构化用户档案模式(Structured User Profile):将记忆以 “核心事实集合” 的形式呈现,类似不断更新的联系人卡片,聚焦用户的稳定关键信息(如姓名、偏好、账户详情);核心作用是支持对这类重要事实的快速查询,满足高效获取用户基础信息的需求。
- “滚动” 摘要模式(“Rolling” Summary):与结构化用户档案不同,它将所有信息整合为单个动态更新的记忆,该记忆是用户与智能体整体交互关系的自然语言摘要;不生成新的独立记忆,而是持续更新这一 “主文档”,常用于压缩长会话,在控制整体 Token 数量的同时保留关键信息。
1.3.1.3. 存储架构
记忆的存储架构是决定智能体记忆检索效率与能力的关键决策,核心包含 “单一架构选择” 与 “混合架构融合” 两类模式,具体总结如下:
- 向量数据库(Vector Databases):按语义相似性检索,适用于非结构化自然语言记忆。
- 知识图谱(Knowledge Graphs):以 “实体 - 关系” 网络存储,适用于结构化关系查询)。
- 混合存储:可融合二者成混合架构,给知识图谱实体加向量嵌入,实现关系与语义同步检索。
1.3.1.4. 创建机制
记忆的生成可从 “形成方式” 和 “提取逻辑位置” 两类维度分类:
按形成方式分:
- 外显记忆(用户直接命令智能体记住信息生成)
- 内隐记忆(智能体无直接命令时,从对话中推断提取信息生成)
按提取逻辑位置分:
- 内部记忆(提取逻辑内置在智能体框架,便捷但缺高级功能,可借外部存储)
- 外部记忆(依赖独立专业记忆管理服务,通过 API 交互,功能更复杂全面)
1.3.1.5. 记忆范围
记忆范围按描述对象(用户、会话、应用)划分,决定记忆聚合与检索的实体,核心分三类:
- 用户级:最常见,记忆绑定用户 ID、跨会话持久,用于长期个性化(如 “用户偏好中间座位”);
- 会话级:提取单会话关键见解,替代冗长记录、压缩长对话,记忆仅关联该会话(如 “用户某时段购特定机票偏好”);
- 应用级:所有用户可访问,提供共享 / 系统信息(如项目代号),常用作通用流程指导,需清理敏感内容防数据泄露。
1.3.1.6. 多模态记忆
多模态记忆指智能体处理图片、视频、音频等非文本信息的方式,核心分两类:
- 多模态来源记忆(主流):智能体处理多类型数据,但仅提取文本见解存储(如转写语音备忘录为 “用户不满发货延迟”,不存音频本身);
- 含多模态内容记忆(更高级):直接存储非文本媒体(如存用户上传的 logo 图片,关联用户请求)。
当前多数记忆管理器聚焦前者,因将输入转成文本更易搜索,而存储非文本需专用技术与基础设施。
1.3.2. Memory 生成:提取和整合
Memory 的生成是 LLM 驱动的 ETL 流程,能自主将原始会话数据转化为结构化的总结,其自动化的 ETL 管道是 Memory Manager区别于 RAG 引擎和传统数据库的关键(自动添加、更新、合并Memory)。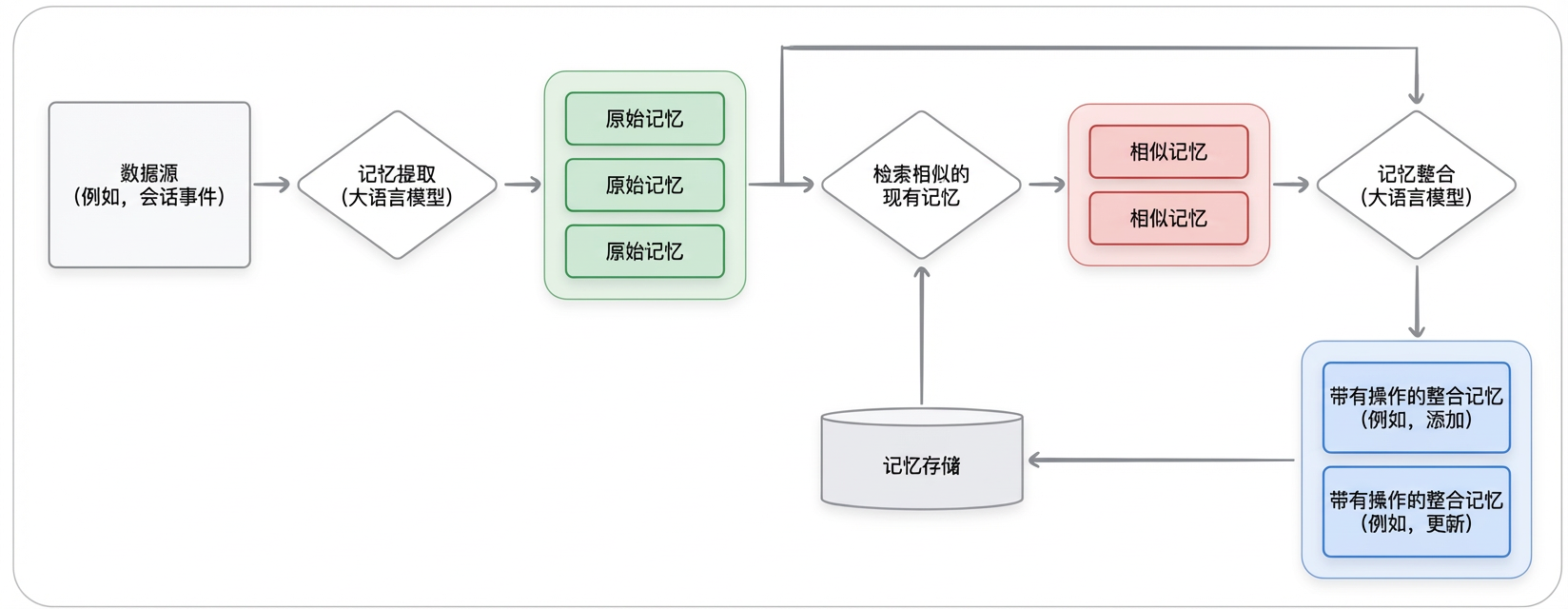
Memory 生成的高级流程通常遵循以下四个阶段:
- 摄入:client 向 Memory Manager 提供原始数据。
- 提取 & 过滤:Memory Manager 通过 LLM 从源数据中提取提取有效内容。
- 整合:Memory Manager 通过 LLM 将新提取的信息与现有记忆进行比较,然后进行:创建新记忆、与老记忆合并或者替换老记忆。
- 存储:新的或更新后的记忆会被持久化到一个耐用的存储层(例如向量数据库或知识图谱)。
Memory Manager 能异步的自动化记忆生成全流程,将对话冗余信息转为结构化知识,开发者只需简单 API 调用,无需亲自维护底层数据基础设施。
接下来深入探讨记忆生成的两个关键步骤:提取和整合
1.3.2.1. Memory 提取
Memory 提取不是简单总结,而是依据 Agent 的用途 / 场景,从对话中筛选 “有意义” 的关键信息(如事实、偏好),过滤无关内容(客套话等);“有意义” 需根据智能体类型(如客服、健康教练)定制,这是 Agent 高效的关键。
实现方式:
- 依赖 LLM + 系统提示词:通过程序化约束、主题定义(schema / 模板或自然语言描述)指导提取。
- 少样本提示:用示例让 LLM 学习提取模式,适配复杂 / 定制化主题。
- 支持开箱即用 + 自定义:默认识别通用主题(如用户偏好),也可通过主题定义、示例定制领域专属提取规则。
虽然 Memory 提取本身并非“总结”,但该算法可能会融入总结来提炼信息。为提高效率,许多 Memory Manager 会将对话的滚动总结直接纳入记忆提取过程中。
一旦从数据源中提取出信息,就必须通过整合来更新现有的记忆库,以反映这些新信息。
1.3.2.2. Memory 整合
是记忆生命周期中最复杂的阶段,由 LLM 实现 “自我梳理”,将提取的事实转化为连贯的用户认知,让记忆管理器超越简单数据库;若无整合,记忆会杂乱矛盾。
- Memory 整合解决会话数据带来的基本问题:
- 信息重复:合并用户多次提及的同一事实(如不同表述的 “去纽约”);
- 信息冲突:处理用户状态变化带来的矛盾内容;
- 信息演变:细化简单事实(如"对营销感兴趣"升级为具体"营销项目");
- 记忆衰减:主动清理过时 / 低价值记忆(通过 LLM 优先新信息或 TTL 自动删除)。
- 整合流程(LLM 驱动):
- 检索:找到与新提取记忆相似的已有记忆作为候选;
- 分析:LLM 对比新旧记忆,确定操作(更新现有记忆、创建新记忆、删除 / 作废旧记忆);
- 执行:将操作转化为事务,更新记忆存储。
1.3.2.3. Memory 来源
- LLM 场景下的 “输入 - 输出” 准则:机器学习中 “输入垃圾,输出垃圾” 的经典准则对 LLM 更关键,因其常出现 “输入垃圾,输出自信满满的垃圾” 情况。要让智能体做可靠决策、记忆管理器有效整合记忆,必须批判性评估记忆质量,而记忆的可信度直接源于其来源(Provenance)—— 即记忆起源与历史的详细记录。
- 记忆谱系追踪的必要性:记忆整合需将多来源信息合并为单一、动态演变的记忆,且单个记忆可能源自多个数据源、单个数据源也可能支撑多个记忆,这使得追踪记忆的谱系(Lineage) 成为必要。
- Agent 需追踪每个数据源的关键细节,这些细节(出处、时效性)决定数据源在记忆整合中的权重,及智能体推理时对记忆的依赖程度.
来源类型是决定可信度的最重要因素之一, 数据源主要分为三类:
- 自举数据: 从内部系统预加载的信息(可信度高)
- 用户输入: 含用户明确提供(高)和从对话中隐含提取的信息(低)
- 工具输出: 外部工具调用返回的数据(低)
Memory Manager 过程中如何应对多源记忆挑战
- 核心背景与挑战:动态多源记忆处理方式在管理时面临两大核心操作挑战 —— 冲突解决与派生数据删除,而记忆的 “出处(Provenance)”(含来源类型、时效性)是关键依据,决定来源在记忆整合中的权重及智能体推理时对记忆的依赖程度。
- 数据源分类及可信度:按可信度从高到低,数据源分三类:一是自举数据,从 CRM 等内部系统预加载,可解决智能体对新用户的 “冷启动问题”;二是用户输入,含表单等明确提供(高可信度)与对话隐含提取(低可信度)两类;三是工具输出,易失效过时,仅适合短期缓存,不建议生成长期记忆。
- 挑战解决方案:冲突解决方面,依托来源信任等级,采用优先可信源、优先最新信息、寻找多数据点佐证等策略;派生数据删除方面,避免激进删除所有关联记忆,而是用剩余有效数据源重新生成受影响记忆(虽计算成本高但更精准)。
- 记忆可信度动态管理:记忆可信度非静态,可通过多可信源佐证提升;同时需通过 “记忆修剪” 主动清理无用记忆,触发条件包括时间衰减(旧记忆相关性降低)、低可信度(无佐证的薄弱推理记忆)、不相关性(与用户当前目标无关的旧记忆)。
- 最终目标:结合 “反应式整合流程”(应对冲突与合并)与 “主动式修剪”(清理无用记忆),使智能体知识库从 “记录所有内容的增长日志”,转变为对用户 “精心筛选、准确且相关的理解”。
LLM 推理过程中如何应对多源记忆挑战
- 核心要求:除在整理记忆库内容时考虑记忆谱系外,推理阶段也需纳入记忆可信度考量,且智能体对记忆的置信度非静态,需随新信息出现与时间推移动态变化。
- 置信度变化规则:多可信来源提供一致信息时,置信度会提升;记忆随时间变陈旧、出现矛盾信息时,置信度会下降(衰减);最终系统可通过归档或删除低置信度记忆实现 “遗忘”。
- 推理阶段的应用方式:动态置信度分数在推理时至关重要,但记忆及其置信度分数不直接展示给用户,而是注入系统提示词,助力 LLM 评估信息可靠性、做出更细致可信的决策,服务于智能体内部推理流程。
1.3.2.4. 触发 Memory 生成
- 决策主体:Agent(Memory manager 仅在生成动作被触发后,自动执行记忆提取与整合,不负责触发时机决策)
- 决策意义:属于关键架构选择,需平衡数据新鲜度与计算成本、延迟两大因素。
- 触发策略:
- 会话完成:在多轮会话结束时触发生成
- 轮次节奏:每经过特定轮次后执行(如每 5 轮触发一次)
- 实时触发:每一轮会话结束后均生成记忆
- 明确指令:接收到用户直接指令时启动(如 “记住这一点”)
- 权衡因素:
- 频繁生成:记忆内容高度详尽、新鲜,可捕捉对话中所有细节;成本高。
- 非频繁生成:记忆准确性可能降低,成本效益高。
Memory as a tool
Memory as a tool 是一种让 Agent 自主决策记忆生成时机的进阶模式,其核心是将 “记忆生成” 功能封装为工具(create_memory),并通过工具定义明确 “有意义信息” 的判定标准,从而将信息筛选责任从外部记忆管理器转移至 Agent(及开发者)自身。Agent 可实时分析对话内容,在识别出值得持久化的关键信息时,自主调用该工具触发记忆生成,相比固定触发策略更具灵活性与针对性
后台操作 vs 阻塞操作
记忆生成是一项昂贵的操作,需要调用 LLM 和写入数据库。对于生产环境中的 Agent,记忆生成几乎都应作为后台进程异步处理。
1.3.3. Memory 检索
记忆检索的本质,是从 Agent 的记忆库中筛选出与当前对话最相关的信息。对 Agent 而言,检索策略的优劣直接产生两种截然不同的结果:提供无关记忆会让 LLM 困惑、拉低响应质量;而精准匹配的记忆则能让交互更具连贯性与个性化,甚至实现 “智能对话” 的突破。
其核心挑战在于 “双重约束”:既要保证记忆的 “有用性”(即与当前场景高度相关),又要满足 “低延迟”(避免用户等待)—— 毕竟生产环境中,Agent 的响应速度直接影响用户体验,检索操作必须在严格的 latency 预算内完成。
高级记忆系统通过 **“相关性、时效性、重要性” 三维评分 **,实现更精准的筛选:
- 相关性(语义相似度):记忆与当前对话的概念关联度,例如用户问 “推荐周末团建地” 时,“用户曾提过喜欢户外露营” 的记忆相关性更高;
- 时效性(时间维度):记忆的新鲜度,近期创建的记忆(如昨天提到的 “团建预算 5000 元”)通常比一年前的记忆更有参考价值;
- 重要性(全局权重):记忆本身的关键程度,这一属性在记忆生成时就已定义(如 “用户过敏史” 比 “用户某天的下午茶选择” 更重要)。
在对准确性要求极高的场景(如医疗咨询、企业级客服),可通过以下手段优化检索效果,但需注意 “成本与效率” 的平衡:
- query rewriting:让检索 “问对问题”用 LLM 将用户模糊的查询(如 “我想找之前说的那个方案”)改写为精准表述(如 “用户 3 天前提到的‘Q4 产品推广方案’”),或扩展为多维度查询(覆盖 “方案目标、预算、负责人” 等)。但该方式会增加一次 LLM 调用的 latency,需谨慎使用。
- Reranking:小范围里 “精挑细选”先通过相似度搜索获取较宽泛的候选记忆(如 Top50 结果),再用 LLM 对这一小集合重新评估排序,筛选出最精准的最终列表。这种方式兼顾了 “广度” 与 “精度”,但同样会增加少量计算成本。
- specialized retriever:为特定场景 “定制工具”通过标注数据微调检索模型,让其适配特定领域(如法律、教育)的记忆检索需求。但该方式依赖大量标注数据,且会显著提升成本,更适合高价值、专业化场景。
检索时机
在 AI 智能体的记忆管理体系中,检索时机的选择是平衡 “响应效率” 与 “上下文有效性” 的关键架构决策,主要分为主动检索与反应式检索(记忆即工具) 两种核心模式:
-
proactive retrieval
在每一轮对话开始时,系统会自动加载与当前用户相关的记忆,无需智能体额外判断或用户指令。这种方式的核心目标是 “确保上下文随时可用”,让智能体在交互初期就拥有完整的用户背景信息,避免因缺少记忆导致的响应断层。
优势:上下文覆盖全面,无需智能体额外决策,能快速支撑需要长期记忆的交互(如用户偏好关联、历史需求延续);且由于记忆在单个对话轮次中保持静态,可通过缓存机制高效复用,降低重复检索的性能损耗。
挑战:会给无需记忆的对话轮次(如简单的事实查询)带来不必要的延迟,增加无效的计算与数据传输成本。 -
Reactive Retrieval
将记忆检索封装为工具(如LoadMemoryTool或自定义工具),由智能体根据当前对话上下文自主判断是否需要检索 —— 仅在识别出 “需依赖历史记忆” 的场景(如用户提及 “之前说的旅行计划”)时,才调用工具触发检索,而非固定在每轮开始执行。
优势:效率更高,仅在必要时检索记忆,大幅减少无效成本;且能适配动态交互场景(如对话中途突然需要关联历史信息),避免资源浪费。
挑战:需额外调用一次大语言模型(用于判断是否检索及生成检索指令),会增加单次检索的延迟与成本;同时智能体可能因 “不知晓记忆库中是否存在相关信息” 而遗漏检索,需通过工具描述明确记忆类型(如在自定义工具中说明 “存储有用户偏好、历史订单等信息”),辅助智能体做出更合理的决策。
1.3.4. Memory 使用
在获取相关记忆后,将其策略性注入模型上下文窗口是关键步骤,其注入位置会显著影响 LLM 的推理过程、运营成本,最终决定回答质量。两种方式:
- 注入 system prompt:适用于稳定、全局的记忆(如用户档案),这类记忆需在交互中持续存在,能为模型提供基础且固定的用户背景信息。
- 注入对话历史:适用于临时、情景化的记忆(仅与当前对话上下文相关),可通过对话注入或 memory-as-a-tool 模式实现。
实际应用中,混合策略最为有效 —— 用 system prompt 承载需长期生效的稳定记忆,用对话注入或 memory-as-a-tool 处理即时性情景记忆,以此平衡对持久上下文的需求与即时信息检索的灵活性。
1.3.4.1. 系统指令中的记忆
将检索到的记忆附加到系统指令中,通常会搭配一段前言,明确记忆作为整个交互 “基础背景” 的定位,同时保持对话历史的整洁。例如可通过 Jinja 模板动态生成包含记忆的系统指令,模板中会先定义基础系统指令,再通过循环将用户相关记忆(如用户偏好、固定属性)以结构化形式嵌入,最终渲染为完整提示词供大语言模型调用。
优势:
- 权威性高:注入系统指令的记忆能为模型提供核心参考依据,影响模型整体推理方向,适合作为全局认知基础。
- 边界清晰:将记忆与对话内容明确分离,避免记忆混入对话历史导致的逻辑混乱,便于模型区分 “背景信息” 与 “交互内容”。
- 适配稳定记忆:尤其适合用户档案这类长期不变、需持续生效的 “全局信息”,能确保模型在整个交互过程中随时调用。
局限:
- 框架依赖强:要求智能体框架支持每次调用大语言模型前动态构建系统提示词,该功能并非所有框架都原生支持。
- 与 Memory-as-a-Tool 不兼容:系统提示词需在模型决定是否调用记忆检索工具前确定,无法适配 “模型自主判断检索时机” 的模式。
多模态支持差:多数大语言模型仅接受文本格式的系统指令,难以直接嵌入图像、音频等非文本记忆。 - 存在过度影响风险:智能体可能强行将所有话题与系统指令中的记忆关联,即使场景不匹配(如用户询问通用事实时,仍试图绑定用户过往偏好)。
1.3.4.2. 对话历史中的记忆
将检索到的记忆直接注入逐轮对话流程,可选择放在完整对话历史之前,或紧邻最新用户查询的位置。特殊场景下,可通过工具调用实现记忆注入 —— 记忆会作为工具输出的一部分,直接融入对话内容,例如调用 “加载记忆” 工具后,工具返回的用户历史需求会自动成为对话的一部分。
优势:
- 适配临时记忆:适合仅与当前对话上下文相关的情景化记忆(如用户当前话题涉及的过往细节),无需长期占用系统指令资源。
- 灵活性高:可根据对话进度动态决定记忆注入时机与位置,无需提前固定在系统指令中,适配多话题切换场景。
局限:
- 干扰强:若注入的记忆与当前对话无关,会增加对话 “噪音”,不仅提升 token 成本,还可能导致模型混淆信息。
- 存在对话注入风险:模型可能误将注入的记忆当作真实对话内容(如误认记忆中的用户偏好是用户当前表述的信息),影响推理准确性。
- 视角要求严格:需匹配对话角色视角,例如使用 “用户” 角色注入用户级记忆时,必须采用第一人称表述,否则易引发逻辑混乱。
1.3.5. 程序性 Memory
陈述性记忆(管理 “是什么”,如事实、用户数据),而程序性记忆聚焦 “如何做”,是优化智能体工作流程与推理能力的关键机制,二者核心差异在于:陈述性记忆解决 “信息检索” 问题,程序性记忆解决 “推理增强” 问题,需独立且专门的算法生命周期管理。多数商业记忆管理平台适配陈述性记忆,暂不适配程序性记忆。
- 提取: 用专用提示词从成功交互中提炼 “可复用策略 / 操作手册”,而非仅捕捉单一事实或信息。
- 巩固: 主动优化工作流程:整合新成功方法与现有 “最佳实践”、修补计划中的缺陷步骤、删减过时 / 无效程序(区别于陈述性记忆的 “合并相关事实”)。
- 检索: 目标是获取 “指导复杂任务执行的计划”,而非回答问题的数据,因此数据模式与陈述性记忆不同。
与 HumanFeedback (RLHF) 等微调手段的对比:
- 共性:均以提升智能体行为表现为目标。
- 差异:微调是 “离线、慢节奏” 过程,需修改模型权重;程序性记忆是 “在线、快适应” 方式,通过向提示词动态注入 “操作手册”,依托上下文学习指导智能体,无需微调。
1.3.6. 测试与评估
评估是 “多层次、持续性” 过程,需验证三大维度:记忆质量(记对信息)、检索能力(需时能找)、任务价值(完成目标);学术界侧重可复现基准,行业侧聚焦记忆对生产级智能体性能与可用性的实际影响。
- 记忆生成质量指标:
- 精确性:智能体生成记忆中 “准确且相关” 的占比(防无关信息污染知识库);
- 召回率:从源数据中 “应记的相关事实” 被捕捉的比例(防遗漏关键信息);
- F1 分数:精确率与召回率的调和平均数,平衡衡量质量。
- 记忆检索性能指标:
- 召回率 @K:需记忆时,正确记忆是否在检索结果前 K 项内(核心精度指标);
- 延迟:检索需在严格预算内(如 200ms 内)完成,避免影响用户体验(检索处于响应 “关键路径”)。
- 端到端任务成功指标:评估记忆是否 “实际助智能体提升工作表现”:用 LLM “评判者” 对比智能体输出与标准答案,判断准确性,衡量记忆系统对最终结果的贡献。
评估非一次性事件,而是 “建立基准→分析失败→调整系统(如优化提示词、检索算法)→重新评估” 的迭代过程,同时需兼顾 “质量” 与 “性能”(如算法延迟、负载下的扩展性)。
1.3.6. Memory 生产环境
从原型到生产,需满足可扩展性、弹性、安全性 3 大核心要求,平衡 “智能性” 与 “企业级稳健性”。
关键架构设计:解耦记忆处理与主应用逻辑,采用 “基于服务的非阻塞模式”:
- 智能体推数据:会话结束等事件后,通过非阻塞 API 向记忆管理器推送原始数据(如对话记录);
- 后台处理:记忆管理器确认请求后,将生成任务放入内部队列,异步调用 LLM 完成提取、巩固、格式化;
- 持久化存储:将最终记忆(新条目 / 更新)写入专用耐用数据库(托管记忆系统含内置存储);
- 智能体检索:新交互需上下文时,直接查询记忆存储库。
避免记忆处理的故障 / 延迟影响用户端应用,同时支持 “实时生成(保对话新鲜度)” 与 “离线批量处理(用历史数据填充系统)”。
生产级挑战与解决方案:
| 核心挑战 | 对应解决方案 |
|---|---|
| 高频事件与并发安全 | 1. 采用事务性数据库操作或乐观锁,防止多事件修改同一记忆时出现死锁或竞争条件;2. 借助强消息队列缓冲大量事件,避免记忆生成服务因负载过高而过载。 |
| 瞬时错误(如 LLM 调用失败) | 1. 启用 “指数退避重试机制” 处理临时调用失败;2. 将持续失败的任务路由至死信队列,便于后续分析故障原因。 |
| 全球应用可用性 | 1. 使用内置多区域复制功能的数据库;2. 由内存系统内部处理数据复制,确保数据事务一致性;3. 向开发者呈现单一逻辑数据存储,兼顾全球范围内的低延迟与高可用性。 |
| 简化开发负担 | 采用托管记忆系统(如 Agent Engine Memory Bank),开发者无需处理底层架构细节,可专注于核心智能体逻辑开发。 |
隐私和安全风险
记忆含用户数据,需严格管控,核心逻辑是 “专业档案管理员式防护”—— 既保知识又防风险。
| 防护维度 | 具体操作 |
|---|---|
| 数据隔离 | 1. 严格按照 “用户 / 租户” 维度隔离记忆数据,确保数据归属清晰;2. 通过访问控制列表(ACL)设置权限,仅允许智能体访问对应权限范围内的用户记忆;3. 提供用户自主控制功能,支持用户主动选择 “退出记忆生成” 或 “删除所有个人记忆”。 |
| 敏感信息处理 | 1. 在记忆数据存储前,对个人敏感信息(PII)进行 “红 act”(脱敏)处理;2. 借助 Model Armor 等专业工具,对记忆数据进行验证与净化,过滤风险信息;3. 确保处理流程符合 GDPR、CCPA 等数据合规标准,降低数据泄露风险。 |
| 防记忆污染 | 1. 建立信息真实性验证机制,对拟存入的记忆内容进行有效性校验;2. 主动丢弃伪造、误导性的内容,避免虚假信息进入记忆库;3. 防范恶意用户通过提示注入攻击,篡改智能体的持久化知识体系。 |
| 跨用户共享风险防护 | 1. 当存在多用户共享程序性记忆(如通用操作指南、标准化流程)的场景时,需先对记忆内容进行彻底匿名化处理;2. 移除记忆中包含的用户个人标识、敏感场景信息等,防止跨用户的敏感信息泄露。 |
1.4. 总结
**核心主题:**聚焦上下文工程(Context Engineering),明确其两大核心组成部分为 “会话(Sessions)” 与 “记忆(Memory)”,强调该工程通过将对话历史、记忆、外部知识等必要信息动态整合到 LLM 的上下文窗口中,实现从简单对话交互到持久化、可行动智能的转化,且整个过程依赖会话与记忆两大系统的相互作用。
- 会话(Sessions)的定位与要求:
- 核心角色:负责 “当下” 交互,是单轮对话的低延迟、按时间顺序排列的容器。
- 主要挑战:需平衡性能与安全 —— 性能上要求低延迟访问,需通过令牌截断、递归总结等提取技术压缩会话历史或请求载荷,避免上下文窗口溢出;安全上需在会话数据持久化前对个人敏感信息(PII)进行脱敏处理,确保数据隔离。
- 记忆(Memory)的定位与机制:
- 核心角色:是长期个性化的引擎,也是跨多轮会话实现持久化的核心机制,区别于检索增强生成(RAG,让智能体成为事实专家),记忆能让智能体成为 “用户专家”。
- 运行机制:属于主动的、LLM 驱动的 ETL 流程,涵盖提取(从对话历史中提炼关键信息)、整合(将新信息与现有记忆库融合,解决冲突、删除冗余以保证知识库连贯)、检索三大环节。
- 体验与安全保障:为保障用户体验,记忆生成需在智能体响应后以异步后台进程运行;同时需追踪记忆来源(溯源),并采取防护措施应对记忆污染等风险,助力开发出可信、能随用户成长的自适应智能助手。
2. 代码实验室
2.1. Agent Sessions(短期记忆)
这里列举出 Agent Sessions codelab 单元使用到的 ADK 一些功能:
- 有状态的 Agent,仅针对当前会话上下文:InMemorySessionService 非持久性
- 持久化 Session:DatabaseSessionService 通过 session ID 将会话存储到 Sqlite,新 Session 可以通过 ID 访问
- 压缩上下文:EventsCompactionConfig(compaction_interval(每N轮触发)、overlap_size(保留近N轮))
- 通过 ToolContext 控制 Session State 存储的信息作用域,达到夸 Session (通过 app or user 关联) 共享
其中 Compaction 和 ToolContext 是原生 LangGraph 不具备的能力。
2.2. Agent Memory(长期记忆)
这里列举出 Agent Memory codelab 单元使用到的 ADK 一些功能:
- 初始化 memory_service:InMemoryMemoryService(or VertexAiMemoryBankService)
- 将 Session 手动注入 memory:add_session_to_memory()
- Agent 检索 memory:load_memory(智能决策) or preload_memory(每轮检索) or search_memory(手动触发)
- Session 内容自动注入 memory:通过在回调函数中调用 add_session_to_memory()

- Memory 整合:自然语言类信息精简总结为结构化可操作数据(json等)
原生 LangGraph 支持记忆长期存储、语义检索、修剪、删除、总结等操作,并且还有 LangMem 专门用来管理长期记忆。
参考文献:
5-Day AI Agents Intensive Course with Google
Context Engineering: Sessions & Memory
Day 3a - Agent Sessions
Day 3b - Agent Memory

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)