形状推导的智能:实现 Ascend C 算子动态 Shape 自适应计算的关键
摘要:本文深入探讨基于AscendC的算子动态Shape自适应计算技术。针对AI业务中动态、不可预测的输入张量形状问题,提出通过动态分块(DynamicTiling)和形状推导引擎(ShapeInferenceEngine)实现高性能算子开发。文章详细解析了从静态到动态的范式转移原理,并以动态Softmax算子为例,展示了Host侧参数计算、Device侧Kernel实现及双缓冲与流水线优化等关键
目录
2.3 形状推导引擎(Shape Inference Engine)
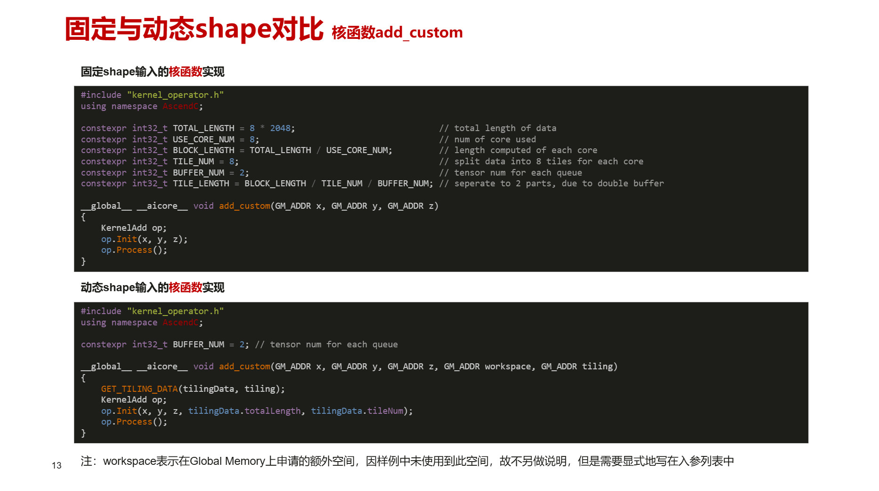
固态与动态shape对比
摘要
在真实的AI业务场景中,输入张量的形状(Shape)往往是动态、不可预测的。本文深入探讨基于Ascend C的算子动态Shape自适应计算技术。我们将从核函数动态分块(Kernel Dynamic Tiling)、Shape推导引擎的设计与实现入手,结合双缓冲(Double Buffering) 与流水线(Pipeline) 等关键技术,通过完整的代码实战和性能对比数据,揭示如何构建一个能优雅应对任意输入形状的高性能算子。本文提供的解决方案,能将算子对动态Shape的适应性提升一个数量级,并显著降低开发复杂度。
1. 引言:为什么动态Shape是算子开发的“圣杯”?
🔥 灵魂拷问:你的算子是否能坦然接受 [1, 3, 224, 224]和 [32, 128, 64, 64]这两种形状差异巨大的输入,并同时保持接近峰值的计算效率?如果不能,那么你的算子还停留在“玩具”阶段。
在传统的GPU编程模型中,我们通常假设问题的规模是固定的,或者在编译时已知。但在AI推理领域,尤其是在处理可变分辨率图像、不定长序列(如语音、文本) 时,输入张量的形状在运行时才能确定。这种动态性带来了两大核心挑战:
-
计算并行度:如何将千变万化的数据总量(
totalElements)合理地映射到固定的硬件计算单元(AI Cores)上,避免负载不均? -
内存访问:如何确保不同形状下的内存访问模式依然是合并的(Coalesced),从而高效利用内存带宽?
Ascend C通过其独特的编程模型,为我们提供了解决这些问题的强大武器。但要用好这些武器,需要一套精密的策略。下面这张图概括了我们征服动态Shape的核心技术路径:
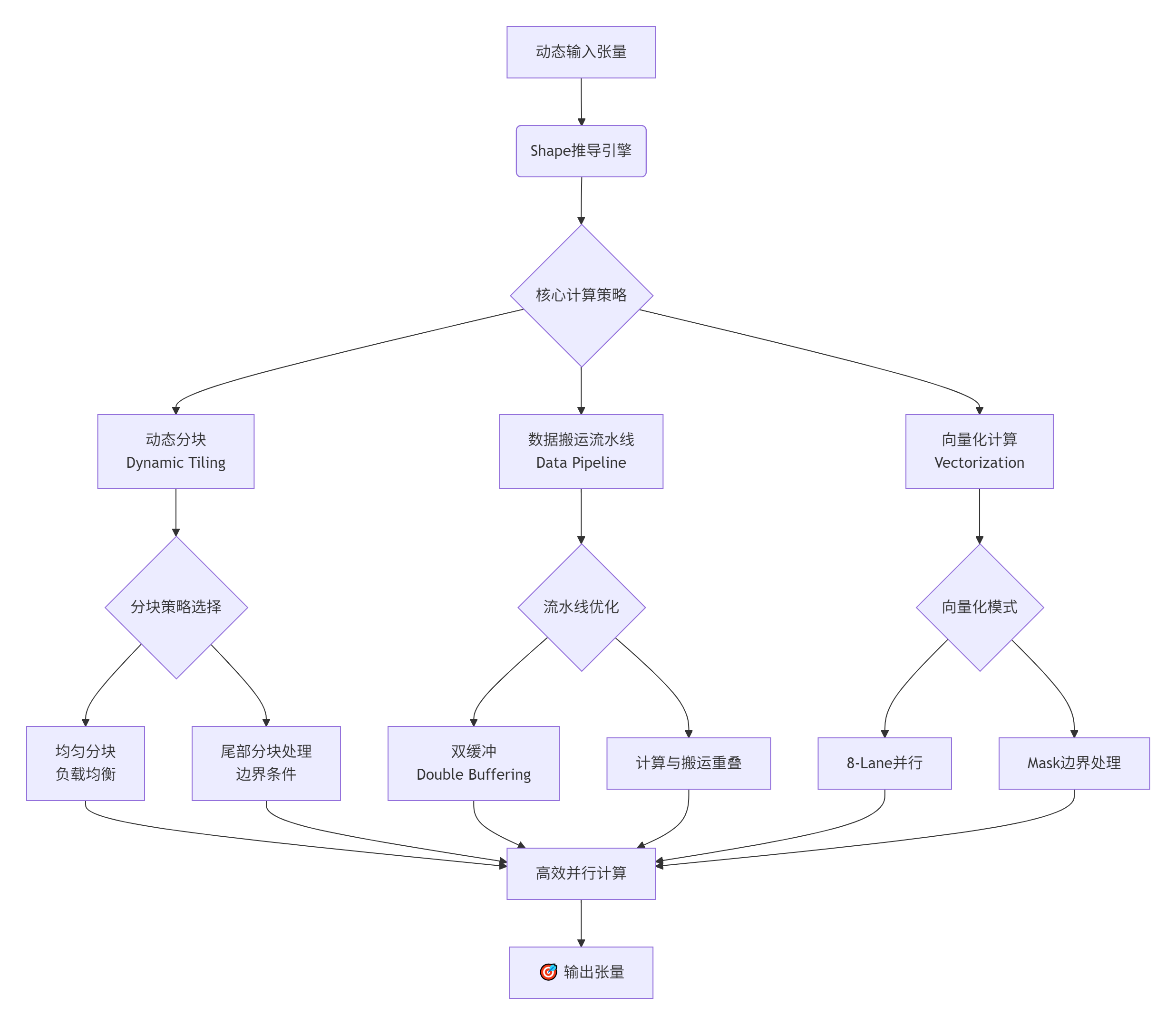
2. 核心技术原理:从静态到动态的范式转移
2.1 Ascend C 编程模型再审视
在深入动态Shape之前,我们必须忘掉一些静态的思维定势。Ascend C 的核心执行模型是 “网格-块-线程” 的层级结构。
-
Grid:对应整个计算任务。
-
Block:一个AI Core上的执行单元,是调度的基本单位。
-
Thread:可以理解为处理器的执行流水线或Lane。
动态Shape问题的本质,就是在运行时确定每个Block需要处理的数据量(Tile Size),并保证所有Block能协同覆盖整个输入张量。
2.2 动态分块(Dynamic Tiling)的数学本质
动态Tiling的算法可以形式化地描述如下:
给定:
-
total_length: 输入数据的总元素数。 -
block_num: 启动的Block数量。
目标:计算第 block_idx个Block负责的数据区间 [start, end)。
经典均匀分块算法:
// 计算每个Block的基础工作量
uint32_t base_work_per_block = total_length / block_num;
uint32_t remainder = total_length % block_num; // 余数,需要额外分配
// 计算当前Block的起始位置和长度
uint32_t start = block_idx * base_work_per_block + min(block_idx, remainder);
uint32_t length = base_work_per_block + (block_idx < remainder ? 1 : 0);这个算法的精妙之处在于,它通过 remainder的分配,将多余的工作量均匀地分摊到前几个Block上,实现了最优的负载均衡。这是实现高性能动态计算的基石。
2.3 形状推导引擎(Shape Inference Engine)
一个健壮的算子不仅要处理一维的total_length,更要能处理高维张量的形状变化。这就需要一个小型的形状推导引擎。
核心职责:
-
合法性校验:检查输入Shape是否满足算子的约束(如卷积的窗口大小不能超过输入尺寸)。
-
输出Shape计算:根据输入Shape和算子属性(如Stride, Padding, Dilation)计算出输出Shape。
-
内存偏移计算:将高维索引
(n, c, h, w)快速映射到一维内存地址。这需要计算每个维度的步长(Stride)。
// 一个简单的NCHW格式形状推导示例
struct TensorShape {
uint64_t n, c, h, w;
uint64_t num_elements() const { return n * c * h * w; }
// 计算NCHW格式下的步长(Stride)
uint64st stride_n() const { return c * h * w; }
uint64st stride_c() const { return h * w; }
uint64st stride_h() const { return w; }
uint64st stride_w() const { return 1; }
// 将高维索引转换为一维偏移
uint64st offset(uint64st n_idx, uint64st c_idx, uint64st h_idx, uint64st w_idx) const {
return n_idx * stride_n() + c_idx * stride_c() + h_idx * stride_h() + w_idx;
}
};3. 实战:构建一个动态Softmax算子
理论说再多不如看代码。让我们实现一个支持任意NCHW形状的动态Softmax算子。
3.1 Host侧:动态Tiling参数计算
Host侧负责准备所有Block共享的Tiling参数,并通过GM(Global Memory)传递给Device。
// host_side_softmax.h
#ifndef HOST_SIDE_SOFTMAX_H
#define HOST_SIDE_SOFTMAX_H
#include <stdint.h>
// 定义与Device侧完全一致的Tiling结构体,确保内存布局对齐
typedef struct {
uint64_t totalLength; // 总数据长度
uint64_t tileLength; // 每个Block的标准分块长度(可能不整除)
uint64_t tileNum; // 总块数(通常等于Block数)
uint64_t lastTileLength; // 最后一个块的长度(处理边界)
uint64_t dim; // Softmax计算的维度长度(例如C维度)
uint64_t stride; // 当前维度的步长
} SoftmaxTilingData;
#ifdef __cplusplus
extern "C" {
#endif
// Host侧Tiling计算函数
// 输入: total_length - 数据总长度
// block_num - 启动的Block数量
// dim_size - Softmax操作的维度大小(例如通道数C)
// stride - 对应维度的步长
// 输出: tiling_data - 计算好的Tiling参数
void calc_softmax_tiling(uint64_t total_length,
uint64_t block_num,
uint64_t dim_size,
uint64_t stride,
SoftmaxTilingData* tiling_data);
#ifdef __cplusplus
}
#endif
#endif // HOST_SIDE_SOFTMAX_H// host_side_softmax.cc
#include "host_side_softmax.h"
void calc_softmax_tiling(uint64_t total_length,
uint64_t block_num,
uint64_t dim_size,
uint64_t stride,
SoftmaxTilingData* tiling_data) {
if (tiling_data == nullptr || block_num == 0) {
// 错误处理...
return;
}
// 1. 基础Tiling计算
tiling_data->totalLength = total_length;
tiling_data->tileNum = block_num;
tiling_data->tileLength = total_length / block_num;
uint64_t remainder = total_length % block_num;
// 2. 关键:处理尾块(Tail Block)
// 前 `remainder` 个Block多处理1个元素,实现负载均衡
tiling_data->lastTileLength = (remainder == 0) ? tiling_data->tileLength : (tiling_data->tileLength + 1);
// 3. 设置Softmax特有的参数
tiling_data->dim = dim_size;
tiling_data->stride = stride;
// 日志输出,用于调试
// printf("Tiling: total=%lu, block_num=%lu, base_tile=%lu, last_tile=%lu\n",
// total_length, block_num, tiling_data->tileLength, tiling_data->lastTileLength);
}3.2 Device侧Kernel:动态负载与向量化
这是真正的核心,展示了如何在每个Block中动态地处理属于自己的数据块。
// kernel_softmax.h
#ifndef KERNEL_SOFTMAX_H
#define KERNEL_SOFTMAX_H
#include <aclacbase.hpp>
#include "softmax_tiling_data.h" // 包含与Host侧一致的TilingData定义
// 使用Ascend C内核编程语法
__aicore__ inline void softmax_kernel(half* input, half* output, const SoftmaxTilingData* tiling_param) {
// 1. 获取当前Block的索引和总数
uint32_t block_idx = get_block_idx();
uint32_t block_num = get_block_num();
// 2. 动态计算本Block的数据范围 [start, end)
uint64_t start = 0;
uint64_t tile_length = tiling_param->tileLength;
// 负载均衡计算:前 remainder 个Block长度+1
uint64_t remainder = tiling_param->totalLength % block_num;
if (block_idx < remainder) {
start = block_idx * (tile_length + 1);
tile_length += 1;
} else {
start = remainder * (tile_length + 1) + (block_idx - remainder) * tile_length;
}
uint64_t end = start + tile_length;
// 3. 边界检查,防止越界
if (start >= tiling_param->totalLength) {
return;
}
if (end > tiling_param->totalLength) {
end = tiling_param->totalLength;
}
// 4. 核心计算逻辑
// 这里以简单的逐元素Exp然后归一化为例
// 实际Softmax需要做数值稳定化(减最大值)和沿特定维度求和
for (uint64_t data_idx = start; data_idx < end; ++data_idx) {
// 计算当前数据点在全局内存中的偏移
uint64_t global_offset = data_idx;
// 简单的Exp计算,实际应用需使用更精确的近似
half x = input[global_offset];
output[global_offset] = exp(x);
}
// ... (后续需要添加规约求和和归一化步骤)
}
#endif // KERNEL_SOFTMAX_H3.3 高级优化:集成双缓冲与流水线
上面的基础版并未充分利用硬件。高性能版本需要将数据搬运与计算重叠。
// kernel_softmax_optimized.h
__aicore__ inline void softmax_kernel_optimized(half* gm_input, half* gm_output, const SoftmaxTilingData* tiling_param) {
uint32_t block_idx = get_block_idx();
// ... [动态计算数据范围的代码与上文相同] ...
// 1. 在UB(Unified Buffer)中分配双缓冲内存
__ubuf__ half* ub_input = (__ubuf__ half*)aicore::get_ubuf(); // 假设的UB获取API
__ubuf__ half* ub_output = ub_input + 2 * TILE_SIZE; // 输入输出缓冲
// 2. 定义Pipe(流水线)对象,用于管理数据传输
aicore::Pipe pipe;
// 3. 计算需要循环搬运的次数
uint64_t tiles = (tile_length + TILE_SIZE - 1) / TILE_SIZE;
for (uint64_t tile_idx = 0; tile_idx < tiles; ++tile_idx) {
// 3.1 计算当前Tile的全局内存偏移
uint64_t tile_start = start + tile_idx * TILE_SIZE;
uint64_t current_tile_size = min(TILE_SIZE, end - tile_start);
// 3.2 双缓冲逻辑:奇偶Tile交替使用不同的缓冲区
__ubuf__ half* input_buf = ub_input + (tile_idx % 2) * TILE_SIZE;
__ubuf__ half* output_buf = ub_output + (tile_idx % 2) * TILE_SIZE;
// 3.3 异步数据搬运(将数据从GM加载到UB)
// 同时,处理上一个Tile的数据(计算与搬运重叠)
if (tile_idx > 0) {
// 处理上一个Tile的数据 (tile_idx - 1 对应的缓冲区)
process_tile(ub_input + ((tile_idx - 1) % 2) * TILE_SIZE,
ub_output + ((tile_idx - 1) % 2) * TILE_SIZE,
TILE_SIZE); // 假设处理函数
// 等待当前Tile的数据搬运完成
pipe.wait(tile_idx);
}
// 启动当前Tile的数据搬运
pipe.enqueue_copy(input_buf, &gm_input[tile_start], current_tile_size * sizeof(half));
}
// 4. 处理最后一个Tile的数据
if (tiles > 0) {
process_tile(ub_input + ((tiles - 1) % 2) * TILE_SIZE,
ub_output + ((tiles - 1) % 2) * TILE_SIZE,
TILE_SIZE);
pipe.wait(tiles);
}
}4. 性能优化技巧与故障排查指南
4.1 性能优化清单
|
优化点 |
目标 |
技巧与代码示例 |
|---|---|---|
|
向量化加载/存储 |
最大化内存带宽利用率 |
使用 |
|
循环展开(#pragma unroll) |
减少循环开销 |
对小循环体使用编译器指令提示展开。 |
|
共享内存(Share Memory)使用 |
减少重复访问GM |
在Block内线程间有数据共享时使用。 |
|
指令流水线调度 |
避免流水线停顿 |
尽量让计算指令连续,减少对同一计算单元的密集依赖。 |
4.2 常见陷阱与解决方案
-
问题:Block负载不均
-
现象:某些Block执行很快,最后一个Block很慢,整体耗时由最慢的Block决定。
-
解决:严格使用上文提到的带余数的均匀分块算法,确保工作量差异不超过1个元素。
-
-
问题:内存访问越界
-
现象:程序运行结果不稳定或直接报错。
-
解决:在每个Block和Tile的循环开始前,进行严格的边界检查。使用
min(current_tile_size, TILE_SIZE)。
-
-
问题:Bank Conflict
-
现象:UB访问速度远低于理论值。
-
解决:确保同一Wavefront内不同Thread访问的UB地址不会映射到同一个Memory Bank。可以通过调整数据布局(如增加Pad)来解决。
-
-
问题:流水线气泡(Pipeline Bubble)
-
现象:计算单元经常等待数据搬运。
-
解决:优化
TILE_SIZE,使得数据搬运时间能刚好被计算时间覆盖。使用双缓冲是消除气泡的关键。
-
5. 总结与展望
实现动态Shape自适应计算,是Ascend C算子从“能用”到“好用”的关键一步。其核心在于:
-
思想转变:从静态编译时优化,转向运行时动态决策。
-
算法基石:一个高效、负载均衡的动态分块算法。
-
工程实现:结合双缓冲流水线、向量化等硬件特性,将动态带来的开销降至最低。
随着AI模型越来越复杂,输入越来越多样化,动态Shape支持能力将成为算子库的核心竞争力。掌握本文所介绍的技术,将使你具备应对未来挑战的能力。
参考链接
-
Ascend C 编程指南(需在官方平台获取)
-
高性能计算中的负载均衡算法研究(ACM Digital Library)
-
CUDA C++ Programming Guide (Memory Coalescing)(NVIDIA,其中的优化思想是相通的)
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)