LangChain文档嵌入模型、向量数据库以及检索器(Retriever)的学习和使用,并实现一个简单的RAG对话助手
本文介绍了文本向量化模型及其在LangChain中的应用。主要内容包括: 文本嵌入模型的作用:将文本编码为向量,用于文档向量化和查询匹配。LangChain提供两种接口:embed_documents处理文档,embed_query处理句子。 向量数据库功能:内置similarity_search等召回函数,通过计算向量相似度实现检索。LangChain还提供更复杂的Retriever组件。 实践
0 概述
Text Embedding Models:文档嵌入模型,提供将文本编码为向量的能力,即文档向量化 。 文档写入和用户查询匹配前都会先执行文档嵌入编码,即向量化。
向量数据库本身已经包含了实现召回功能的函数方法如similarity_search,该函数通过计算原始查询向量与数据库中存储向量之间的相似度来实现召回。
此外LangChain还提供了更加复杂的召回策略 ,这些策略被集成在Retrievers(检索器或召回器)组件中Retriever(检索器)是一种用于从大量文档中检索与给定查询相关的文档或信息片段的工具。检索器不需要存储文档,只需要返回(或检索)文档即可。
1 使用向量模型向量化
LangChain中针对向量化模型的封装提供了两种接口,一种针对文档的向量化(embed_documents) ,一 种针对句子的向量化(embed_query) 。
1.1 句子向量化
示例代码:
将text = "Nice to meet you!"这段文本转为向量,最后打印高维向量前5维以及总维数
import os
import dotenv
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
os.environ["OPENAI_BASE_URL"] = os.getenv("QWEN_BASE_URL")
os.environ["OPENAI_API_KEY"] = os.getenv("QWEN_API_KEY")
# 获取向量模型
embeddings_model = OpenAIEmbeddings(
model="text-embedding-v2",
check_embedding_ctx_length=False
)
# 待嵌入的文本句子
text = "Nice to meet you!"
# 文本句子向量化
embedded_text = embeddings_model.embed_query(text)
print(embedded_text[:5])
print(len(embedded_text))
输出效果:
输出高维向量前五维以及总向量维度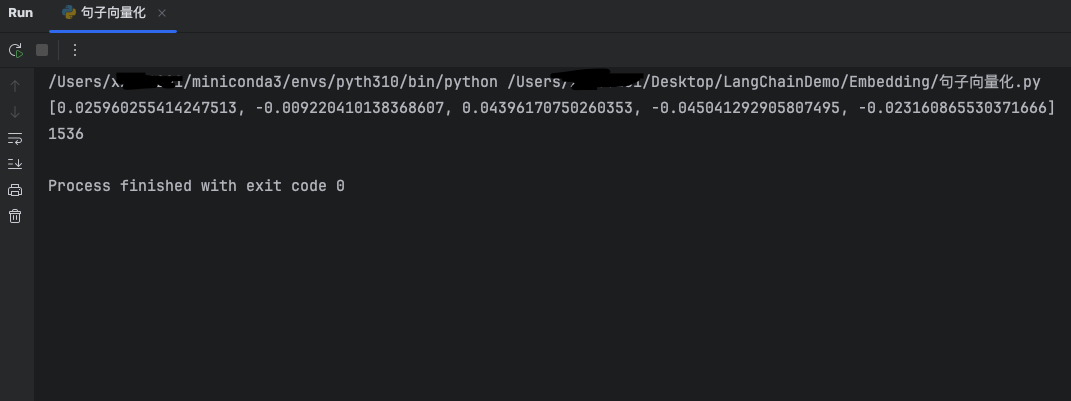
1.2 文档向量化
示例代码:
将本地的pdf文档进行向量化
import os
import dotenv
from langchain_community.document_loaders import PyPDFLoader
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
os.environ["OPENAI_BASE_URL"] = os.getenv("QWEN_BASE_URL")
os.environ["OPENAI_API_KEY"] = os.getenv("QWEN_API_KEY")
# 获取向量模型
embeddings_model = OpenAIEmbeddings(
model="text-embedding-v2",
check_embedding_ctx_length=False
)
# 加载文档并切割
pdf_loader = PyPDFLoader(file_path="脸上爆痘:从成因解析到科学护理的全指南.pdf")
# 底层调用RecursiveCharacterTextSplitter进行切分得到document列表
pdf_document_list = pdf_loader.load_and_split()
# 遍历向量化每一个document对象的page_content
embedded_pdf_document_list = embeddings_model.embed_documents([document.page_content for document in pdf_document_list])
print(f"切割的块数:{len(embedded_pdf_document_list)}")
print(f"向量的维度:{len(embedded_pdf_document_list[0])}")
print(f"地第一块向量前五维度:{embedded_pdf_document_list[0][:5]}")
输出效果:
切割成8块,向量维度为1536维,并输出第一个向量化后的chunk的前五维的数值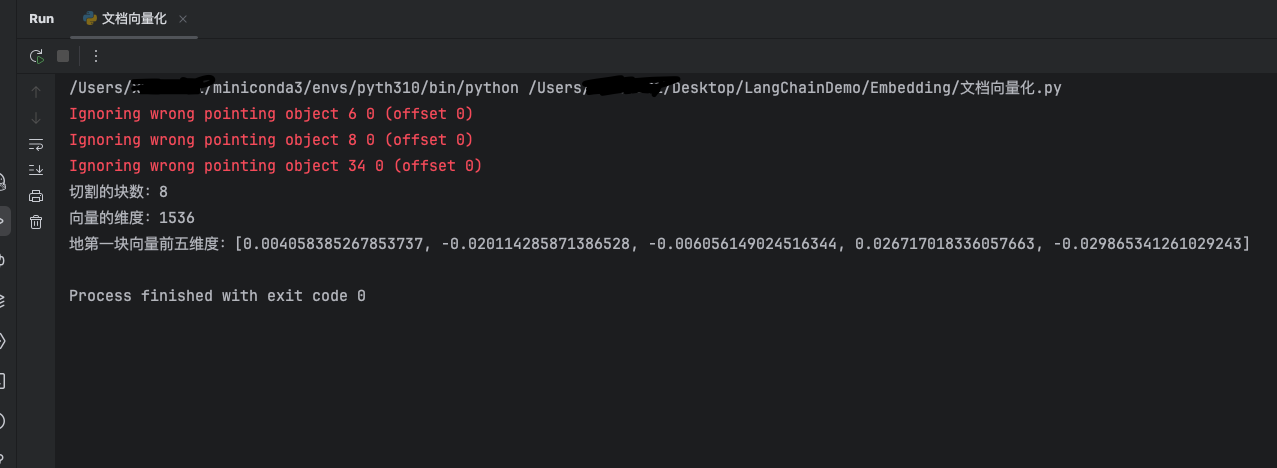
2 向量化
LangChain提供了超过50种不同向量存储(Vector Stores)的集成,从开源的本地向量存储到云托管的私有向量存储,允许你选择最适合需求的向量存储。
常用的向量数据库如下:
| 向量数据库 | 描述 |
|---|---|
| Chroma | 开源、免费的嵌入式数据库 |
| FAISS | Meta出品,开源、免费,Facebook AI相似性搜索服务。(Facebook AI Similarity Search,Facebook AI 相似性搜索库) /fæs/ |
| Milvus | 用于存储、索引和管理由深度神经网络和其他ML模型产生的大量嵌入向量的数据库 |
2.1 示例代码
以下示例通过加载本地一篇pdf文档,然后切割为document列表,最后将document列表存入向量数据库中,最后通过数据库自带的similarity_search方法来进行召回,该策略主要通过语义相似性进行匹配搜索
import os
import dotenv
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
os.environ["OPENAI_BASE_URL"] = os.getenv("QWEN_BASE_URL")
os.environ["OPENAI_API_KEY"] = os.getenv("QWEN_API_KEY")
# 获取向量模型
embeddings_model = OpenAIEmbeddings(
model="text-embedding-v2",
check_embedding_ctx_length=False
)
# 加载文档并切割
pdf_loader = PyPDFLoader(file_path="脸上爆痘:从成因解析到科学护理的全指南.pdf")
# 底层调用RecursiveCharacterTextSplitter进行切分得到document列表
pdf_document_list = pdf_loader.load_and_split()
# 将文档和数据存储到向量数据库中
db = Chroma.from_documents(pdf_document_list, embeddings_model)
# 测试使用相似度查找
query = "爆痘的原因有啥"
# similarity_search
search_document_list = db.similarity_search(query)
print(f"总chunk数:{len(pdf_document_list)}")
print(f"搜索出的chunk数:{len(search_document_list)}")
print(f"搜索结果第一条内容:{search_document_list[0].page_content}")
2.2 输出效果
数据库中共有8个chunk,最后召回4块,显示第一块内容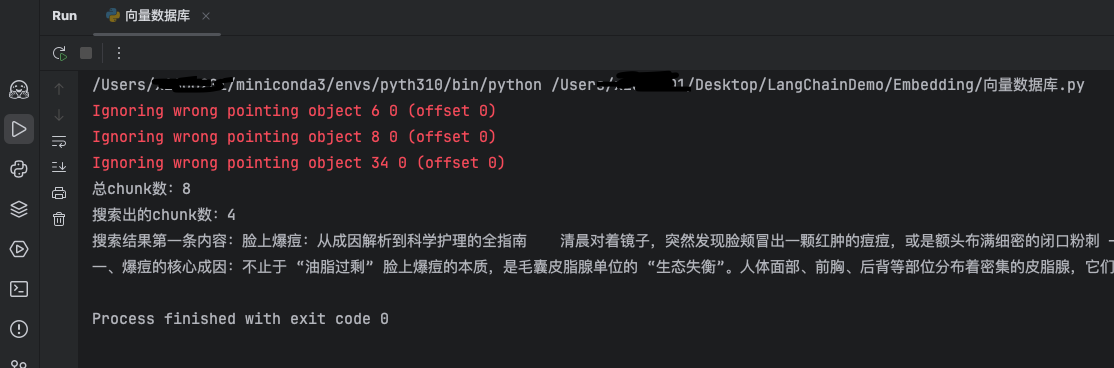
2.3 数据库其他召回功能函数
除了similarity_search,向量数据库还有其他召回功能函数
| 召回函数 | 描述 |
|---|---|
| 相似性检索(similarity_search) | 字面意思,就是根据搜索语句在数据库中进行相似性匹配 |
| 支持直接对问题向量查询(similarity_search_by_vector) | 字面意思,就是根据搜索语句在数据库中进行相似性匹配 |
| 通过L2距离分数进行搜索(similarity_search_with_score) | L2距离就是欧式距离, 分数值越小,检索到的文档越和问题相似。分值取值范围:[0,正无穷] |
| 通过余弦相似度分数进行搜索(_similarity_search_with_relevance_scores) | 分数值越接近1(上限),检索到的文档越和问题相似 |
similarity_search_by_vector核心代码:
将问题向量化后放入similarity_search_by_vector函数中
# similarity_search_by_vector
embedded_query = embeddings_model.embed_query(query)
search_document_list = db.similarity_search_by_vector(embedded_query)
print(f"总chunk数:{len(pdf_document_list)}")
print(f"搜索出的chunk数:{len(search_document_list)}")
print(f"搜索结果第一条内容:{search_document_list[0].page_content}")
输出效果:
和similarity_search示例一致
similarity_search_with_score核心代码:
# similarity_search_with_score
search_document_list = db.similarity_search_with_score(query)
for doc, score in search_document_list:
print(f"✏️得分:{score},内容: {doc.page_content}")
输出效果:
输出召回的各个chunk的得分,越小表示越近,相似性越大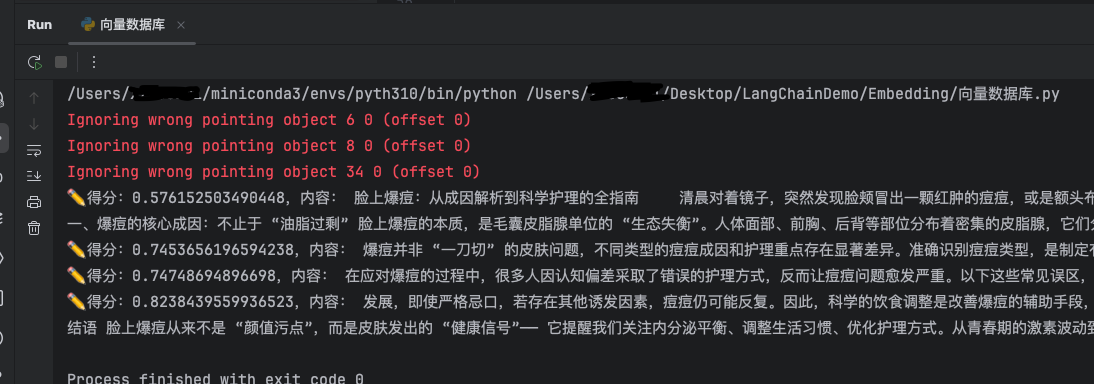
_similarity_search_with_relevance_scores核心代码:
# _similarity_search_with_relevance_scores
search_document_list = db._similarity_search_with_relevance_scores(query)
for doc, score in search_document_list:
print(f"✏️得分:{score},内容: {doc.page_content}")
输出效果:
余弦值越接近1表示越相似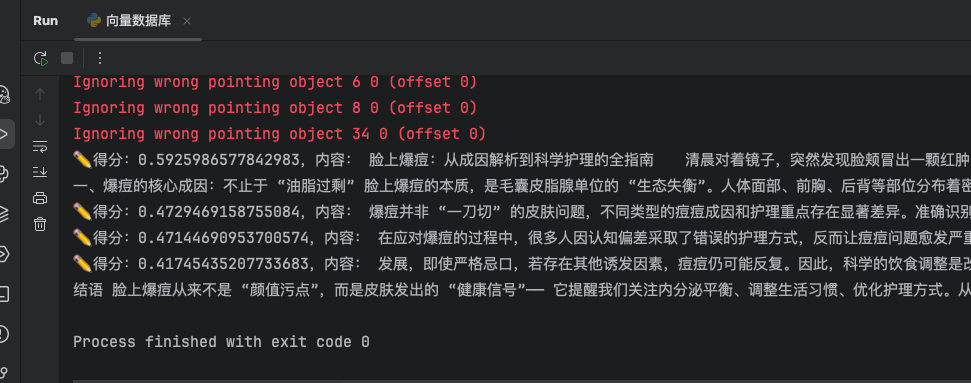
3 检索器(Retriever)
Retrievers(检索器)是一种用于从大量文档中检索与给定查询相关的文档或信息片段的工具。检索器不需要存储文档 ,只需要返回(或检索)文档即可。
即检索器和向量数据库是分离的一个独立的模块,使用Retriever可以降低耦合度并且具备更多数据库本身不具备的更强大的检索策略。以下将论述默认检索器以及分数阈值检索器的使用
3.1 检索策略
默认使用相似性搜索:
关键代码:
# 获取检索器
retriever = db.as_retriever(search_kwargs={"k": 2})
search_document_list = retriever.invoke(query)
print(f"总chunk数:{len(pdf_document_list)}")
print(f"搜索出的chunk数:{len(search_document_list)}")
print(f"搜索结果第一条内容:{search_document_list[0].page_content}")
输出效果:
因为前面参数指定search_kwargs={"k": 2}所以相比前面只检索出最相近的两条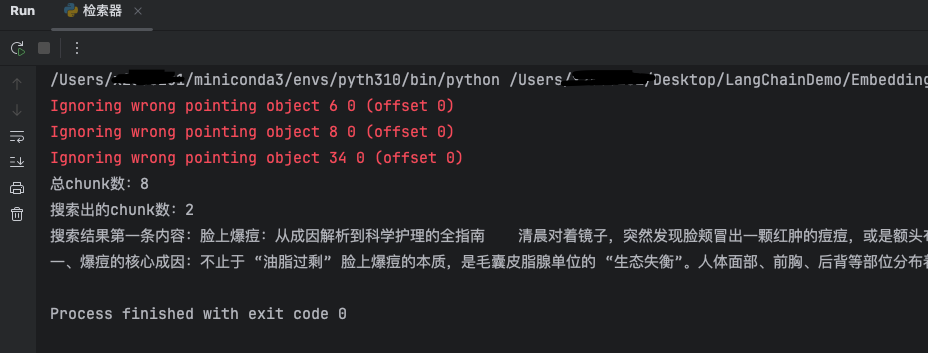
分数阈值查询:
关键代码:
尝试不同的阈值来进行检索
print(f"总chunk数:{len(pdf_document_list)}")
score_threshold = [0.4, 0.5, 0.6]
search_document_list = []
for item in score_threshold:
# 获取检索器(分数阈值查询)
retriever = db.as_retriever(search_type="similarity_score_threshold", search_kwargs={"score_threshold": item})
search_document_list = retriever.invoke(query)
print(f"阈值为{item}时搜索出的chunk数:{len(search_document_list)}")
输出效果:
如图,不同的阈值检索出来的chunk数不同,检索相似度高于0.6的chunk数为0,并提示No relevant docs were retrieved using the relevance score threshold 0.6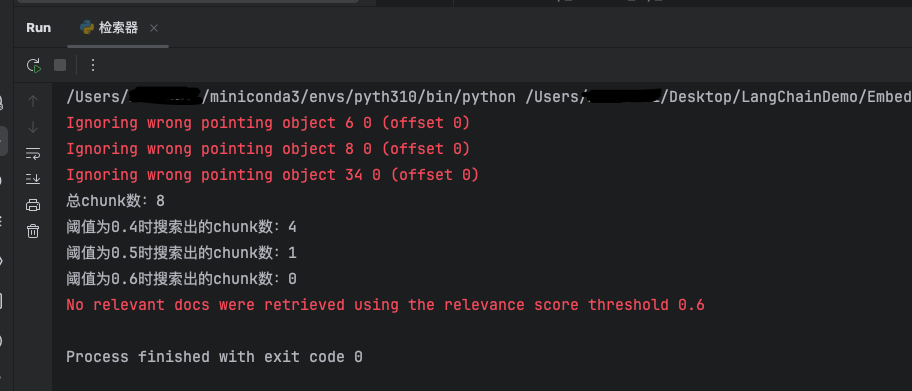
4 结合大模型使用检索器(RAG)
4.1 完整示例代码
以下代码实现了向大模型提问,大模型会自己根据提问意图调用我们封装好的检索向量数据库的工具,最后将检索到的chunk结合问题进行回复
import os
import dotenv
from langchain import hub
from langchain.agents import create_openai_tools_agent, AgentExecutor
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import Chroma
from langchain_core.tools import create_retriever_tool
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
dotenv.load_dotenv()
os.environ["OPENAI_BASE_URL"] = os.getenv("QWEN_BASE_URL")
os.environ["OPENAI_API_KEY"] = os.getenv("QWEN_API_KEY")
# 获取对话模型
chat_model = ChatOpenAI(
model="qwen-plus",
temperature=0
)
# 获取向量模型
embeddings_model = OpenAIEmbeddings(
model="text-embedding-v2",
check_embedding_ctx_length=False
)
# 获取文档切割器
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100
)
# 加载文档并切割
pdf_loader = PyPDFLoader(file_path="脸上爆痘:从成因解析到科学护理的全指南.pdf")
# 若不传切割器则底层调用RecursiveCharacterTextSplitter进行切分得到document列表
pdf_document_list = pdf_loader.load_and_split(splitter)
# 将文档和数据存储到向量数据库中
db = Chroma.from_documents(pdf_document_list, embeddings_model)
# 获取检索器(默认检索)
retriever = db.as_retriever(search_kwargs={"k": 2})
# 创建检索工具
retriever_tool = create_retriever_tool(
retriever,
"知识库检索",
"用于搜索本地向量数据库中关于爆痘的信息"
)
tools = [retriever_tool]
# 提示词模板
prompt = hub.pull("hwchase17/openai-functions-agent")
# 创建Agent 对象
agent = create_openai_tools_agent(chat_model, tools, prompt)
# 创建 AgentExecutor
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
)
print(agent_executor.invoke({"input": "爆痘怎么办?"}))
4.2 输出效果
Invoking: 知识库检索 with {'query': '爆痘怎么办'} 表示大模型自主调用了检索工具。靛蓝色部分是大模型检索向量数据得到的内容,后面是大模型结合检索内容增强生成得到的结果。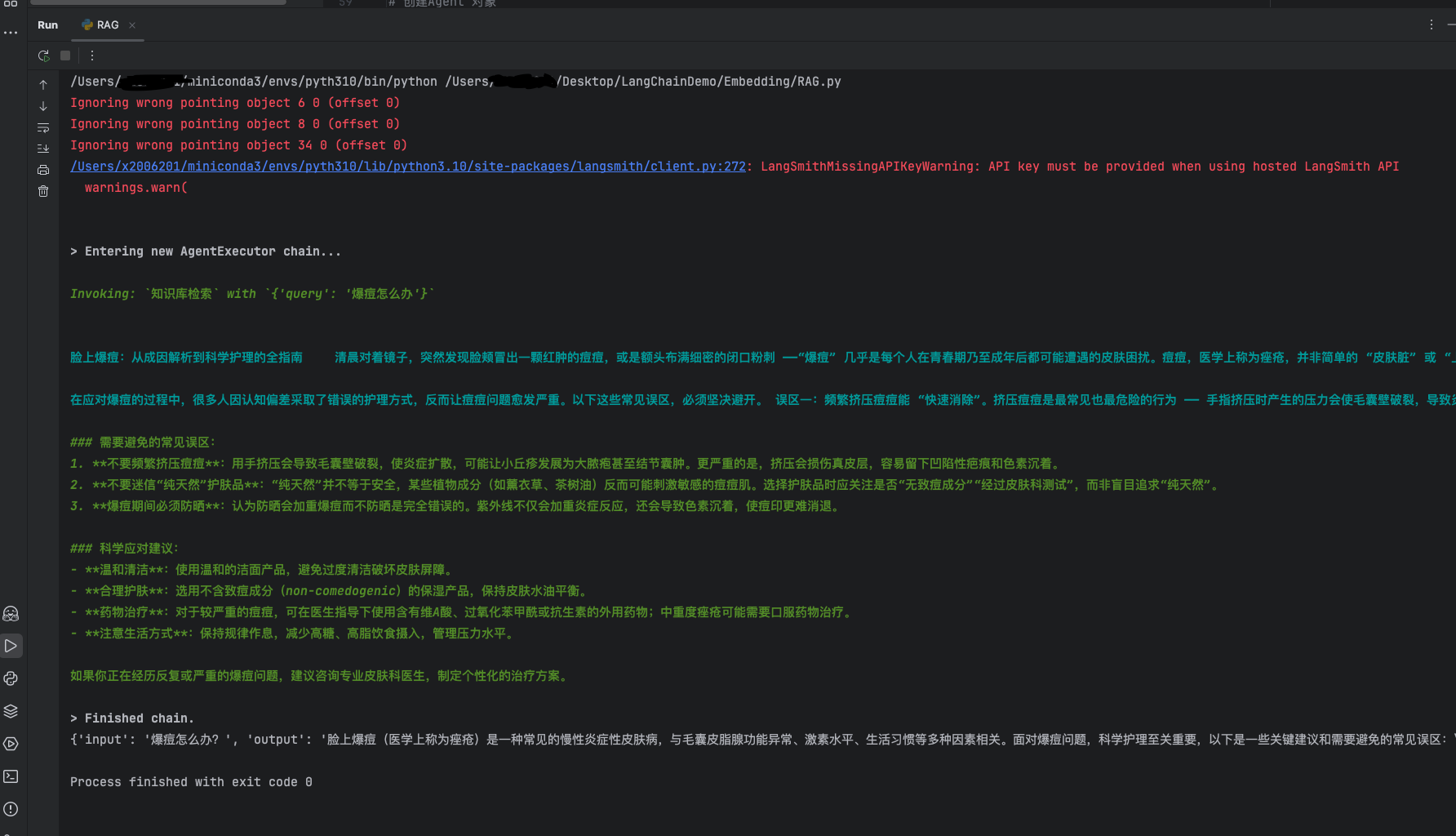
4.3 步骤分解
使用LangChain实现RAG并不复杂,只需要将各种模块像搭积木一样组合在一起即可
4.3.1 获取对话模型和文档嵌入模型
首先需要加载环境变量并新建对话模型实例和文档嵌入模型
dotenv.load_dotenv()
os.environ["OPENAI_BASE_URL"] = os.getenv("QWEN_BASE_URL")
os.environ["OPENAI_API_KEY"] = os.getenv("QWEN_API_KEY")
# 获取对话模型
chat_model = ChatOpenAI(
model="qwen-plus",
temperature=0
)
# 获取向量模型
embeddings_model = OpenAIEmbeddings(
model="text-embedding-v2",
check_embedding_ctx_length=False
)
4.3.2 将文档存入向量数据库
将文档存入向量数据库需要使用文档对应的Loader加载并使用切割器个性化切割文档,切割得到document 列表对象使用向量数据库的from_documents方法存入向量数据库中
# 获取文档切割器
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100
)
# 加载文档并切割
pdf_loader = PyPDFLoader(file_path="脸上爆痘:从成因解析到科学护理的全指南.pdf")
# 若不传切割器则底层调用RecursiveCharacterTextSplitter进行切分得到document列表
pdf_document_list = pdf_loader.load_and_split(splitter)
# 将文档和数据存储到向量数据库中
db = Chroma.from_documents(pdf_document_list, embeddings_model)
4.3.3 创建检索工具
创建检索器retriever后作为参数传入create_retriever_tool方法中得到检索工具
# 获取检索器(默认检索)
retriever = db.as_retriever(search_kwargs={"k": 2})
# 创建检索工具
retriever_tool = create_retriever_tool(
retriever,
"知识库检索",
"用于搜索本地向量数据库中关于爆痘的信息"
)
tools = [retriever_tool]
4.3.4 获取提示词模板
通过网络获取的方式得到提示词模板
# 提示词模板
prompt = hub.pull("hwchase17/openai-functions-agent")
4.3.5 创建Agent和AgentExecutor
将上述创建得到的对话模型、工具以及提示词模板作为参数使用create_openai_tools_agent方法得到agent,然后创建得到agent_executor
# 创建Agent 对象
agent = create_openai_tools_agent(chat_model, tools, prompt)
# 创建 AgentExecutor
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
)
4.3.6 AgentExecutor invoke 调用
print(agent_executor.invoke({"input": "爆痘怎么办?"}))

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)