解决Agent多步任务卡壳:从「上下文断裂」到「状态自愈」实战指南
本文解析AI Agent多步任务卡壳的"上下文断裂"问题,提出通过结构化任务状态管理、智能上下文检索、执行监控检查点及状态自愈机制解决。强调将任务状态显性化、结构化并辅以智能上下文管理,可有效避免上下文断裂陷阱,提升Agent的一致性与可恢复性,是Agent工程化的核心竞争力。
本文解析AI Agent多步任务卡壳的"上下文断裂"问题,提出通过结构化任务状态管理、智能上下文检索、执行监控检查点及状态自愈机制解决。强调将任务状态显性化、结构化并辅以智能上下文管理,可有效避免上下文断裂陷阱,提升Agent的一致性与可恢复性,是Agent工程化的核心竞争力。
前排提示,文末有大模型AGI-CSDN独家资料包哦!

Agent多步任务总卡壳?从「上下文断裂」到「状态自愈」,一致性与可恢复性实战手册!
生产环境中,AI Agent跑多步任务,最让人抓狂的莫过于:它卡壳了。不是一次两次,是常常。你眼睁睁看着它在一个简单的循环里打转,或者在前一步已经明确给出的结果上反复纠结,白白烧掉大量Token,最终任务失败,还抱怨用户“信息不足”。这不是Agent不够智能,而是我们没有给它搭建一套足够健壮的“骨架”。
上下文断裂:Agent卡壳的元凶
大模型本身是无状态的,它每次接收的Prompt都是一次全新的开始。Agent要执行多步任务,就必须模拟出“状态”,把历史信息、中间结果、决策路径等等“塞”进下一次Prompt。起初,这很简单,直接把前面的对话历史和工具调用结果一股脑地扔进去。但很快,你就会遇到瓶颈:
-
- Context Window限制:上下文窗口是有限的,几轮对话、几次工具调用下来,Prompt就爆炸了。为了节省Token,我们不得不裁剪上下文,最直接的后果就是Agent“失忆”——忘掉了前面已经做过的事情,或者关键的约束条件。这就是典型的“上下文断裂”。
-
- 信息过载与噪声:即使上下文窗口足够大,信息量过载也会导致Agent难以聚焦。无关紧要的细节混淆了核心任务,大模型在海量文本中提取关键信息的能力并非无限。
-
- 非结构化记忆的脆弱性:简单地将历史对话文本作为记忆,是一种非常脆弱的记忆模式。它缺乏结构,难以查询,也难以更新。Agent无法区分哪些是“事实”,哪些是“任务状态”,哪些是“执行日志”。
当Agent无法获取完整且准确的上下文时,它就会陷入决策困境:要么重复已有的工作,要么执行错误的操作,要么直接宣布“无法完成”。传统上,我们可能会尝试简单的重试机制,但这只是治标不治本。如果上下文本身就是断裂的,重试一万次也只是徒劳。
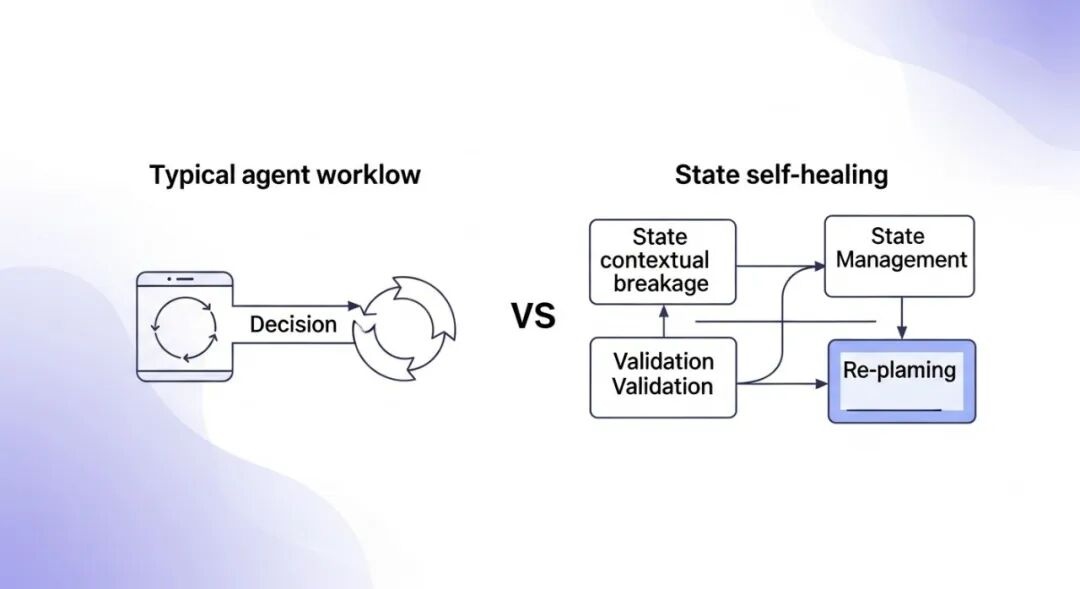
A diagram comparing a typical agent workflow with a “contextual breakage” point versus a “state self-healing” workflow. The breakage point shows a decision loop leading to failure, while the self-healing path shows state management, validation, and re-planning.
.
从「上下文断裂」到「状态自愈」:一致性与可恢复性实战
要解决Agent多步任务卡壳的问题,核心在于建立一套健壮的“状态管理”与“自愈”机制,确保上下文的一致性和任务的可恢复性。
1. 结构化任务状态管理
仅仅将历史对话作为上下文是不够的。我们需要为Agent建立一个明确的、可读写的“任务状态”对象,并将其外部化存储。
-
• 任务状态Schema设计:使用Pydantic或其他Schema定义工具,明确任务的关键信息。例如:
-
•
task_id:任务唯一标识。 -
•
current_step:当前正在执行的步骤。 -
•
status:任务状态(PENDING,RUNNING,PAUSED,FAILED,COMPLETED)。 -
•
sub_tasks:子任务列表,每个子任务包含其状态、输入、输出。 -
•
context_variables:任务执行过程中产生的关键变量,例如“用户提供的产品名称”、“查询到的库存数量”等。 -
•
error_log:错误记录,包含错误类型、发生时间、错误信息。
-
-
• 外部化状态存储:将这个结构化状态对象存储在外部持久层,如Redis(用于快速读写)或关系型数据库(用于持久化和查询)。这样即使Agent进程崩溃,任务状态也能被恢复。
-
• 状态的原子性更新:确保每次状态更新都是原子性的。例如,一个步骤完成后,同时更新
current_step和status。
2. 智能上下文检索与注入
当上下文窗口不够用时,我们需要更智能地管理送入LLM的Prompt。
-
• 分层上下文管理:
-
• 短期上下文:最近几轮对话和当前步骤的详细日志。
-
• 中期上下文:当前任务的结构化状态(Schema),以及与当前步骤最相关的历史信息(通过向量检索)。
-
• 长期上下文:Agent的通用知识、用户偏好、系统配置等(通过RAG检索)。
-
-
• 语义检索增强:当LLM需要某个特定信息时,不盲目地塞入所有历史,而是根据当前Agent的“意图”或“问题”,从结构化状态、历史日志、甚至外部知识库中进行语义检索,只注入最相关的信息。例如,如果Agent需要确认“产品A的颜色”,就去检索状态中与“产品A”和“颜色”相关的信息。
3. 执行监控与检查点
Agent的每一步执行都应该被监控,并在关键节点设置“检查点”。
- • 工具调用的幂等性:设计Agent调用的外部工具时,尽量保证幂等性。即使重复调用,也不会产生副作用。这为重试和回滚提供了基础。
- • 步骤级别的结果校验:Agent执行完一个步骤(特别是调用外部工具后),不应盲目地进入下一步。它应该主动校验该步骤的输出是否符合预期。例如,如果调用了API查询库存,Agent应校验返回结果是否包含
stock_count字段,且值是否为有效数字。如果校验失败,立即进入错误处理流程。 - • 状态快照与回滚:在执行高风险或多步事务性操作前,保存当前任务状态的快照。如果后续步骤失败,可以回滚到最近的成功快照。
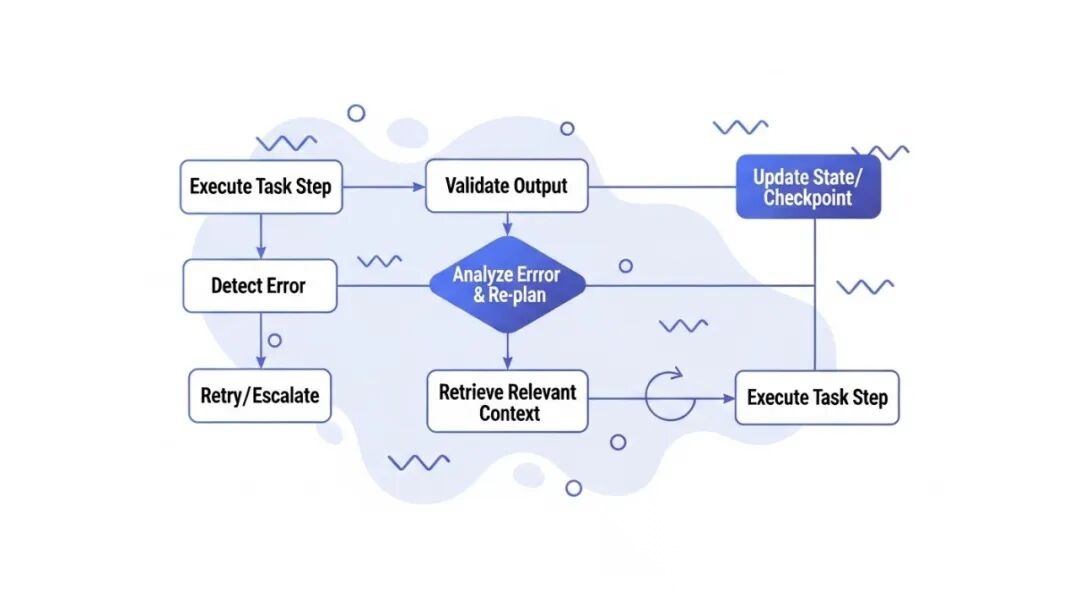
A flowchart illustrating the “state self-healing” process within an AI Agent. It shows steps like “Execute Task Step”, “Validate Output”, “Update State/Checkpoint”, “Detect Error”, “Analyze Error & Re-plan”, “Retrieve Relevant Context”, and “Retry/Escalate”.
4. 状态自愈与错误恢复策略
当Agent卡壳或遇到错误时,如何不依赖人工干预就能“自愈”是关键。
-
• 错误类型识别与分类:Agent需要能够识别不同类型的错误:
-
• 逻辑错误:Agent自身理解或决策错误,导致生成了无效指令或错误推理。
-
• 工具错误:外部工具调用失败,如API超时、返回错误码。
-
• 上下文缺失:关键信息未在Prompt中提供。
-
• 校验失败:步骤输出不符合预期。
-
-
• 动态Prompt重构与再推理:
-
• 当发生错误时,将错误信息、当前任务状态、以及错误发生前的Prompt和输出,一同注入到LLM中,要求它分析错误原因并给出新的执行计划或修正当前步骤。
-
• 例如,如果工具调用失败,Prompt可以这样设计:“工具
search_product调用失败,错误信息是API timeout。根据当前任务状态,请重新思考如何完成‘搜索产品’这一目标。”
-
-
• 自适应重试机制:不是简单的重试,而是基于错误类型和历史尝试次数的智能重试。例如,网络错误可以立即重试;逻辑错误则需要先进行再推理。
-
• 人机协作与升级:当Agent尝试多次自愈仍无法解决问题时,应能够优雅地将任务挂起,并通知人类操作员介入,提供必要的诊断信息和上下文。
总结
AI Agent要真正从玩具走向生产,仅仅依靠大模型的强大推理能力是不够的。我们必须为其构建一个坚实、可靠的工程基石。将任务执行过程中的“状态”显性化、结构化、可管理化,并辅以智能的上下文检索、执行监控和自愈机制,才能有效避免“上下文断裂”的陷阱,让Agent在复杂的多步任务中表现出真正的一致性与可恢复性。这不仅仅是技术细节,更是Agent工程化的核心竞争力。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献113条内容
已为社区贡献113条内容

所有评论(0)