「让提词跟着我说话走」:结合语音识别做“自动跟读滚动”的 Rokid 提词器
本文分享了Rokid AR眼镜提词器功能的开发实践。通过解析Glasses SDK提供的提词器场景接口(包括打开场景、发送文本、配置参数和同步ASR结果),作者实现了"自动跟读滚动"功能,解决了传统提词器节奏不匹配的问题。文章详细介绍了从基础功能封装到AI实时滚动的实现过程,并提出了多种创新应用场景,如演讲练习助手、远程导演模式等。最后总结了开发中的常见问题,为开发者提供了实用

不知道大家关注没有 Rokid 的眼镜啊,最近可是非常的火,我也是第一时间去看了新品发布会,里面有很多的功能还是很震撼的。

人非常多,也遇见了好多的老熟人,当然也有自己比较关注的 up 主 tim。
当然说回来,我们也来聊一个 Rokid 眼镜上的一些应用开发,毕竟它能给我们带来哪些创新性体验,才是我们更关注的。
在官方的 SDK 中有个提词器场景,其实官方 SDK 其实已经把提词器能力封装得比较完整了,当然我们在这个基础上,在增加点“小玩意”,比如“自动跟读滚动”~!
一、为什么我开始折腾“自动跟读滚动”
做内容的人应该都有过类似的崩溃体验:
-
要么是提词器滚得太快,被迫狂读;
-
要么就是滚得太慢,自己说完一句还要在那里干等着字幕挪下去。
在 Rokid 的 AR 眼镜上,这个问题更明显——屏幕就在眼前,一旦节奏不对,很容易被打乱思路。
Rokid 的 GlassesSDK 里,其实已经把提词器能力封装得比较完整了:既包括基础的“打开场景 + 下发文案”,也包括基于 ASR 结果的 AI 实时滚动能力。
这篇文章就按照我自己的实战过程,从 0 到 1 带你把提词器场景跑起来,然后结合 GlassesSDK 文档里给出的接口,做一个“让提词跟着我说话走”的自动跟读 Demo,顺便聊聊还能玩出哪些新花样。

二、先对照 GlassesSDK 文档,把提词器能力说清楚
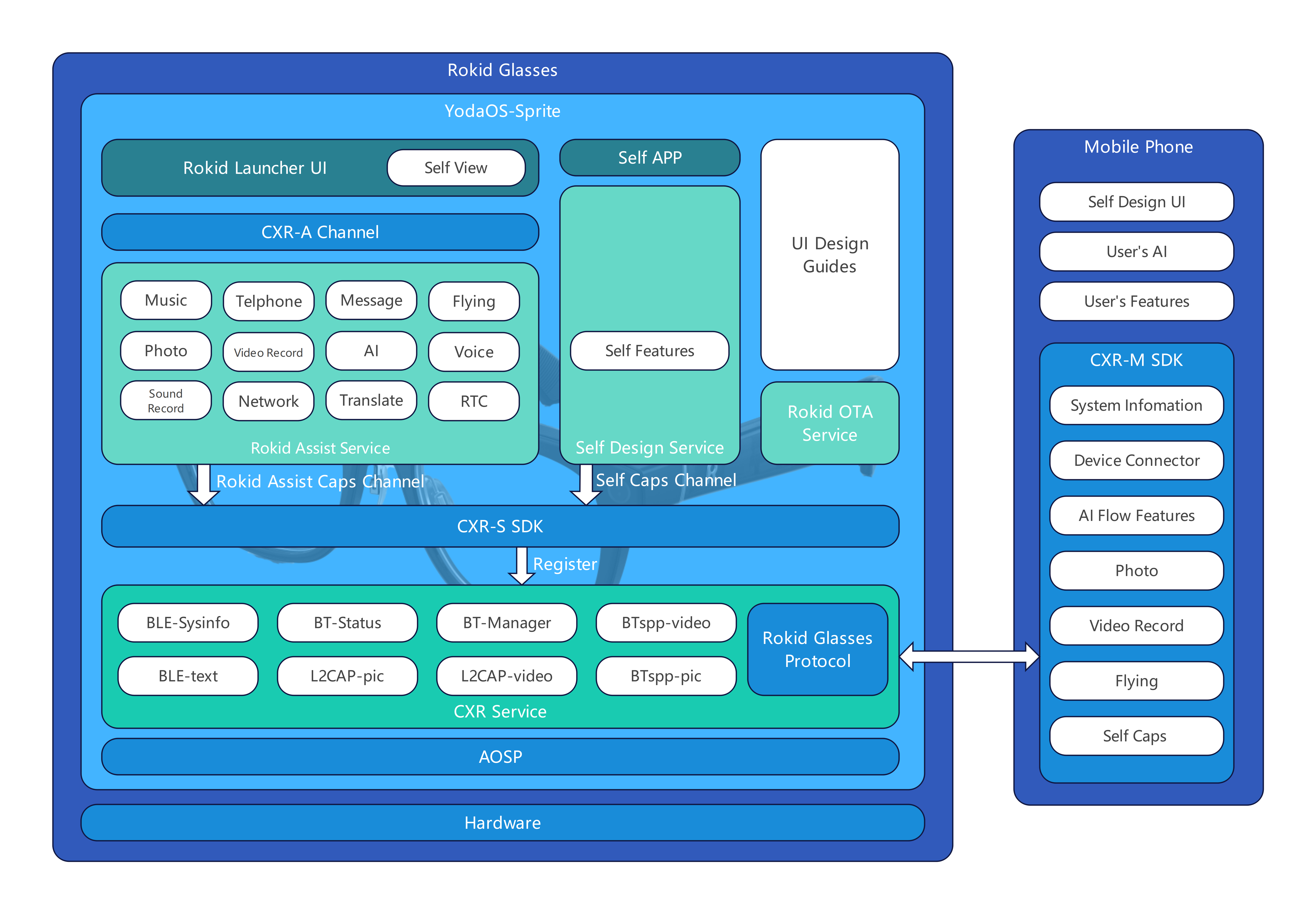
在 GlassesSDK 文档里,提词器是一个独立的 CXR 场景(scene),核心接口正是你给到的这几组:
1)打开 / 关闭提词器场景
fun openOrCloseWordTips(toOpen: Boolean): ValueUtil.CxrStatus? {
return CxrApi.getInstance()
.controlScene(ValueUtil.CxrSceneType.WORD_TIPS, toOpen, null)
}
-
对应文档里的
controlScene(ValueUtil.CxrSceneType.WORD_TIPS, openOrClose, null)。 -
返回值是
ValueUtil.CxrStatus,常见取值:REQUEST_SUCCEED/REQUEST_WAITING/REQUEST_FAILED。
2)发送提词器内容(脚本文本)
private val sendCallback = object : SendStatusCallback {
override fun onSendSucceed() {
/* 文案下发成功 */
}
override fun onSendFailed(p0: ValueUtil.CxrSendErrorCode?) {
/* 记录错误码 */
}
}
fun setWordTipsText(text: String, fileName: String): ValueUtil.CxrStatus? {
return CxrApi.getInstance().sendStream(
ValueUtil.CxrStreamType.WORD_TIPS,
text.toByteArray(),
fileName,
sendCallback
)
}
3)配置提词器场景参数
fun configWordTipsText(
textSize: Float,
lineSpace: Float,
mode: String,
startPointX: Int,
startPointY: Int,
width: Int,
height: Int
): ValueUtil.CxrStatus? {
return CxrApi.getInstance().configWordTipsText(
textSize, lineSpace, mode,
startPointX, startPointY,
width, height
)
}
-
mode支持"normal"和"ai",后者就是文档里提到的“AI 模式,ASR 触发自动滚动”。
4)发送提词器 ASR 结果(AI 实时滚动的关键)
fun sendWordTipsAsrContent(content: String): ValueUtil.CxrStatus? {
return CxrApi.getInstance().sendAsrContent(content)
}
-
文档里的描述是:当模式为
"ai"时,如果 ASR 结果触达当前画面尾部的几个字符,提词器会自动上滑。 -
所以这个接口不是“控制滚动速度”的,而是把“已经说出来的话”同步过去,让 SDK 自己做对齐和滚动判断。
理解完这四块之后,你再回头看 GlassesSDK 文档,就会发现:官方给出的其实是一套比较完整的“场景 + 数据流 + 模式配置 + ASR 同步”能力,我们要做的,只是基于这些接口配出一个顺畅的业务链路。
三、从 0 到 1:一个最小可用的 Rokid 提词器 Demo
下面这段 Kotlin 代码是我自己在 Demo 工程里的写法,基本就是对上面几个接口做了一层业务封装:
class TeleprompterManager {
private val sendCallback = object : SendStatusCallback {
override fun onSendSucceed() {
/* 这里可以做一些 UI 提示 */
}
override fun onSendFailed(error: ValueUtil.CxrSendErrorCode?) {
/* 打日志排查 */
}
}
fun open() {
val status = openOrCloseWordTips(true)
// 建议对 status 做判断,避免在 REQUEST_WAITING 状态下频繁请求
}
fun close() {
openOrCloseWordTips(false)
}
fun updateScript(text: String, fileName: String = "speech.txt") {
setWordTipsText(text, fileName)
}
fun configNormalMode(
textSize: Float = 26f,
lineSpace: Float = 1.4f,
startPointX: Int,
startPointY: Int,
width: Int,
height: Int
) {
configWordTipsText(
textSize,
lineSpace,
"normal",
startPointX,
startPointY,
width,
height
)
}
}
在 AR 眼镜上调试的时候,建议一开始先把文字区域画得小一点、靠下边缘一些,避免完全挡住视线。
等用户习惯了之后,再通过配置给他一个“沉浸式”的全屏提词体验。
四、关键一跳:把 GlassesSDK 里的 AI 实时滚动用起来
根据文档,configWordTipsText 的 mode 参数是整个“自动跟读滚动”的开关:
-
"normal":普通模式,不关联 ASR,主要依赖定速或手动滚动; -
"ai":AI 模式,结合sendWordTipsAsrContent的内容,当识别文本触达当前画面尾部时自动上滑。
所以要让提词器“跟着我说话走”,必备的两步就是:
-
先把模式配置成
"ai"; -
在语音识别有新结果时,调用
sendWordTipsAsrContent把文本同步过去。
示例代码:
fun configAiMode(
textSize: Float = 26f,
lineSpace: Float = 1.4f,
startPointX: Int,
startPointY: Int,
width: Int,
height: Int
): ValueUtil.CxrStatus? {
return configWordTipsText(
textSize,
lineSpace,
"ai", // 开启 AI 模式
startPointX,
startPointY,
width,
height
)
}
fun onAsrResultChanged(asrText: String) {
// 这里的 asrText 一般是“当前已说出的全部内容”或者到当前句子的累积文本
sendWordTipsAsrContent(asrText.trim())
}
这里有几个和文档强相关的细节:
-
建议按“累积文本”发送,而不是只发最后几个词,这样更容易和脚本做对齐;
-
不要在
REQUEST_WAITING状态下频繁调用,避免把 SDK 拍“懵”; -
ASR 文本在发送前做一点清洗(去掉多余空格、重复标点),可以减少误判滚动。
五、接上语音识别:完整的“自动跟读滚动”链路
从 GlassesSDK 的角度看,它只关心一件事:你能不能持续地把“已经识别出的文本”通过 sendWordTipsAsrContent 传过来,至于这个文本是来自 Rokid 自己的语音服务,还是来自第三方云 ASR,SDK 并不做限制。
下面是一个简化版的伪代码结构,重点在“如何把 ASR 结果整理之后喂给提词器”:
class AutoScrollTeleprompter(
private val teleprompterManager: TeleprompterManager,
private val asrClient: AsrClient // 你自己的语音识别封装
) {
private val sb = StringBuilder()
fun start(script: String) {
teleprompterManager.open()
teleprompterManager.updateScript(script)
teleprompterManager.configAiMode(
textSize = 28f,
lineSpace = 1.5f,
startPointX = 100,
startPointY = 200,
width = 800,
height = 600
)
asrClient.start(object : AsrListener {
override fun onPartialResult(text: String) {
sb.clear()
sb.append(text.trim())
sendWordTipsAsrContent(sb.toString())
}
override fun onFinalResult(text: String) {
// 最终结果可以用来做“对读评分”等分析
}
override fun onError(code: Int, msg: String?) {
// 错误处理
}
})
}
fun stop() {
asrClient.stop()
teleprompterManager.close()
}
}

六、实战玩法:做一个“演讲练习助手”后面的实战与扩展
光是自动滚动其实还不够“好玩”,结合 ASR,我们可以顺手把“练稿子”这件事做得更智能一点。
我在自己的 Demo 里做了一个简单的“演讲练习助手”:
-
提词器负责展示完整稿子,并跟着你读自动滚动;
-
ASR 负责记录你实际说了什么;
-
结束后做一次对比,给你一些“很接地气”的反馈,比如:
-
哪几句话跳读了;
-
哪些词你经常读错或卡顿;
-
当前语速是偏快还是偏慢。
-
一个很粗暴但好用的实现方式是按句子对齐:
-
按照标点把原稿切成句子列表
scriptSentences; -
把 ASR 的
finalResult也做一次简单切分; -
用一个很轻量的“相似度”算法(比如基于分词的重合度)去匹配。
伪代码大概是这样:
data class SentenceCheckResult(
val original: String,
val spoken: String?,
val similarity: Float
)
fun analyse(script: String, spokenText: String): List<SentenceCheckResult> {
val scriptSentences = splitToSentences(script)
val spokenSentences = splitToSentences(spokenText)
val results = mutableListOf<SentenceCheckResult>()
var j = 0
for (i in scriptSentences.indices) {
val s = scriptSentences[i]
var bestIdx = -1
var bestSim = 0f
for (k in j until spokenSentences.size) {
val sim = similarity(s, spokenSentences[k])
if (sim > bestSim) {
bestSim = sim
bestIdx = k
}
}
val spoken = if (bestIdx >= 0) spokenSentences[bestIdx] else null
if (bestIdx >= 0) j = bestIdx + 1
results.add(SentenceCheckResult(s, spoken, bestSim))
}
return results
}
后面你可以在眼镜上或者配套 App 里,把这些结果可视化出来,比如:
-
相似度
< 0.6的句子用红色标记,提示“建议再练两遍”; -
全文平均语速、总时长、停顿分布,用一个简单的图表展示。
对于经常要录公开课、直播或企业宣传片的同学来说,这种“自助练稿 + 自动跟读”的体验,真的比拿着稿子对着镜头硬背舒服太多。
七、基于当前 SDK 能做的几种创新玩法
前面说的演讲助手,只是“自动跟读滚动”的一个典型用法。
结合现在提词器相关的几个接口,其实还可以挖出不少玩法:
1. 远程导演模式
-
提词器场景依然跑在眼镜上;
-
导演在另一端用平板 / PC 改稿;
-
通过网络把最新文案同步到服务端,再由服务端调用
sendStream下发到 Rokid; -
实拍过程中,导演可以临时插一句提示、加一个备注,下一秒就出现在演员眼前。
2. 多语言对照提词
-
用一份脚本生成中英文两份文本;
-
通过排版控制,让英文小号字体显示在下方或侧边;
-
结合 ASR 只对中文做自动滚动,英文只是跟随展示作为对照。
3. 会议 / 培训中的“现场提醒条”
-
不是传统意义上的全文提词,而是在眼镜的一小块区域滚动关键信息;
-
比如:下一页 PPT 的重点、即将要问的问题、时间提醒;
-
通过
configWordTipsText把提词区域收得比较小,就可以变成一个“隐形便签条”。
4. 拍摄安全提示 / 法务提示场景
-
在录制对外视频时,让拍摄者在开头自动读一段合规提示;
-
系统用 ASR 校验是否确实读完了关键条目,才允许开始正式录制;
-
这里同样可以用
sendWordTipsAsrContent的文本对齐结果做一个简单的检查。
这些玩法本质上都没有超出当前 SDK 提供的能力,只是把“提词内容 + 布局 + ASR 结果”这三块重新拼了一下。
从工程实现角度来说,你完全可以先封装一层自己的 TeleprompterService,把 CxrApi 的细节藏在里面,对业务层暴露的是更高层的概念:
-
TeleprompterSceneConfig(布局、字体、模式); -
ScriptSegment(脚本片段,多语言、类别标签); -
AsrSyncStrategy(如何把 ASR 文本映射到脚本)。
八、开发中踩到的一些坑
最后简单记几条我在调试过程中踩过的坑,给后面折腾的同学省点时间:
-
不要无脑高频调用
controlScene-
SDK 里已经明确提到有
REQUEST_WAITING这个状态; -
如果频繁 open / close,很容易在状态切换时卡住场景;
-
建议在业务层自己维护一个状态机,只有判断确实是“场景已关闭”时才去调用 open。
-
-
sendStream的编码问题-
最好明确指定 UTF-8,避免在某些环境下出现乱码;
-
另外,
fileName可以当作一个轻量级的脚本 ID,用来区分不同的文案版本。
-
-
configWordTipsText的坐标和尺寸-
不同设备分辨率、FOV 略有差异,最好做一层适配;
-
可以先根据设备的物理分辨率算一个“逻辑安全区域”,把提词器放在其中;
-
不要一上来就全屏,尤其是在需要看清现实环境的场景。
-
-
ASR 的延迟和闪烁
-
如果 ASR 是云端识别,网络波动时很容易出现先静止一会儿,然后一次性滚很大一段的情况;
-
可以在业务层做一个“节流 + 缓冲”:收到长段结果时分段发送给
sendAsrContent,让滚动看起来更自然。
-
-
异常处理
-
CxrStatus里的REQUEST_FAILED一定要打详细日志,否则后期排查问题会非常难受; -
sendStream的失败回调里,可以做一次降级,比如提示用户重新加载脚本。
-
这些细节在 Demo 阶段可能感觉不明显,但一旦你把这个功能交给真正的主播、讲师、运营同学去用,就会立刻感受到“工程质量”的差距。
九、最后的小总结
GlassesSDK 给提词器做的 "ai" 模式,本质上是把“字幕滚动”这件事从一个纯 UI 动画,升级成了一个和语音识别紧密联动的能力。
按照文档,把 openOrCloseWordTips / setWordTipsText / configWordTipsText / sendWordTipsAsrContent 几个接口串起来,其实已经能比较完整地说明:“当前 GlassesSDK 里给出的提词器接口和 AI 实时滚动部分,如何在实际项目里落地”。
剩下的,就是结合自己的业务,把它变成一个真正有价值的功能:可以是演讲练习助手,可以是远程导演工具,也可以是带安全校验的合规提示提词。
如果你也做了自己的玩法,欢迎在论坛里交流,一起把提词器打造成 GlassesSDK 生态里的“标配能力”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)