AI工具全景:从数据标注到智能编程的完整技术栈
本文深入探讨了现代AI开发工具链的三大核心组件:智能编码工具、数据标注平台和模型训练系统。以GitHub Copilot为例,详细解析了智能编码工具的架构原理、工作流程和Prompt工程实践,展示了如何通过上下文理解和代码模式识别提升开发效率。在数据标注方面,系统介绍了标注平台架构、流程管理以及计算机视觉和NLP领域的标注工具实现。针对模型训练,文章阐述了分布式训练平台设计、完整训练流程和超参数优
引言
人工智能正在重塑软件开发和数据分析的各个层面。从辅助程序员编写代码的智能编码工具,到为机器学习准备数据的数据标注平台,再到训练复杂模型的模型训练系统,AI工具链已经形成了一个完整的生态系统。这些工具不仅提高了开发效率,更重要的是降低了AI技术的应用门槛,使得更多开发者能够参与到AI应用的构建中来。
本文将深入探讨三大类AI工具:智能编码工具、数据标注工具和模型训练平台,通过代码示例、流程图、Prompt示例和具体案例分析,全面展示现代AI开发工具链的技术实现和应用场景。
一、智能编码工具:GitHub Copilot深度解析
1.1 GitHub Copilot架构与工作原理
GitHub Copilot是基于OpenAI Codex模型的AI编程助手,它能够根据上下文自动生成代码建议。其核心技术架构如下:
python
# Copilot工作流程模拟
class GitHubCopilot:
def __init__(self):
self.context_analyzer = ContextAnalyzer()
self.codex_model = CodexModel()
self.suggestion_filter = SuggestionFilter()
def get_suggestion(self, file_content, cursor_position, file_type):
# 分析代码上下文
context = self.context_analyzer.analyze(
file_content,
cursor_position,
file_type
)
# 生成候选建议
raw_suggestions = self.codex_model.generate(
prompt=context.prompt,
max_tokens=100,
temperature=0.7
)
# 过滤和排序建议
filtered_suggestions = self.suggestion_filter.filter(
raw_suggestions,
context=context
)
return filtered_suggestions
# 上下文分析器
class ContextAnalyzer:
def analyze(self, file_content, cursor_position, file_type):
# 提取当前行和前几行代码
lines = file_content.split('\n')
current_line_index = self._get_line_index(cursor_position, lines)
# 构建上下文窗口
context_window = self._build_context_window(
lines, current_line_index, window_size=10
)
# 识别代码模式
patterns = self._detect_patterns(context_window, file_type)
return Context(
prompt=self._build_prompt(context_window, patterns),
file_type=file_type,
patterns=patterns
)
def _build_prompt(self, context_window, patterns):
# 构建给模型的提示
prompt = "// 基于以下上下文生成代码:\n"
for line in context_window:
prompt += f"{line}\n"
if patterns.get('function_def'):
prompt += f"// 正在定义函数: {patterns['function_def']}\n"
prompt += "// 建议的代码:"
return prompt
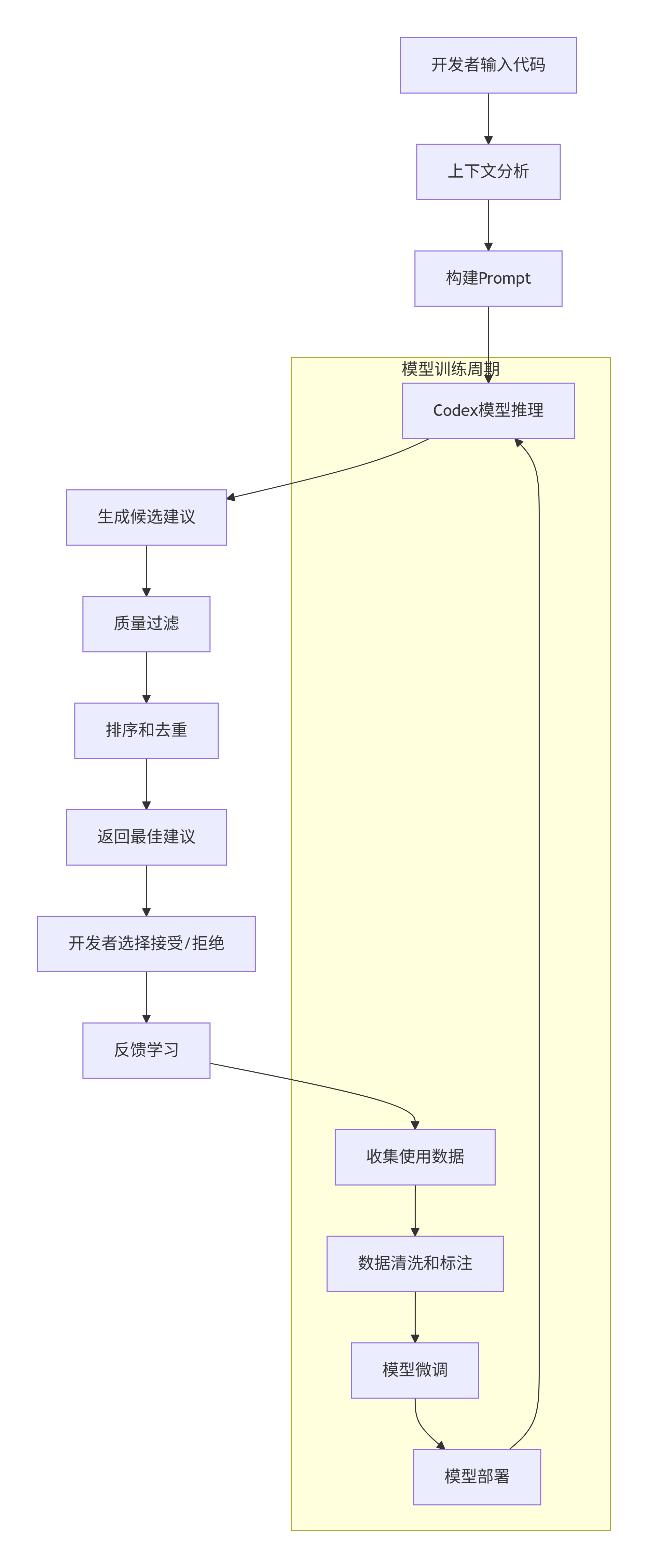
1.2 Copilot工作流程
graph TD
A[开发者输入代码] --> B[上下文分析]
B --> C[构建Prompt]
C --> D[Codex模型推理]
D --> E[生成候选建议]
E --> F[质量过滤]
F --> G[排序和去重]
G --> H[返回最佳建议]
H --> I[开发者选择接受/拒绝]
I --> J[反馈学习]
subgraph "模型训练周期"
K[收集使用数据] --> L[数据清洗和标注]
L --> M[模型微调]
M --> N[模型部署]
N --> D
end
J --> K
1.3 Copilot Prompt工程示例
Copilot的成功很大程度上依赖于精心设计的Prompt。以下是一些有效的Prompt模式:
python
# 1. 函数级Prompt示例
def test_copilot_prompts():
"""
Prompt模式1: 清晰的函数描述
"""
# 当输入这样的注释时,Copilot会生成相应的函数实现
# 计算两个向点积
def dot_product(vector1, vector2):
return sum(x * y for x, y in zip(vector1, vector2))
"""
Prompt模式2: 示例驱动
"""
# 像这样使用:
# result = process_data(input_data, threshold=0.5)
# 实现process_data函数:
def process_data(data, threshold=0.5):
return [x for x in data if x > threshold]
"""
Prompt模式3: 测试驱动开发
"""
# 先写测试,再实现函数
def test_fibonacci():
assert fibonacci(0) == 0
assert fibonacci(1) == 1
assert fibonacci(5) == 5
assert fibonacci(10) == 55
# 实现fibonacci函数
def fibonacci(n):
if n <= 1:
return n
a, b = 0, 1
for _ in range(2, n + 1):
a, b = b, a + b
return b
# 2. 类级别Prompt示例
class DataProcessor:
"""
数据处理类,用于清洗和转换数据
功能包括:
- 数据标准化
- 缺失值处理
- 特征编码
"""
def __init__(self, config):
self.config = config
self.scaler = None
self.encoders = {}
def fit(self, data):
"""训练数据处理参数"""
# Copilot会根据上下文生成完整的方法实现
self.scaler = StandardScaler()
self.scaler.fit(data['numerical_features'])
for column in data['categorical_features'].columns:
encoder = LabelEncoder()
encoder.fit(data['categorical_features'][column])
self.encoders[column] = encoder
def transform(self, data):
"""转换数据"""
transformed_data = data.copy()
# 数值特征标准化
transformed_data['numerical_features'] = self.scaler.transform(
data['numerical_features']
)
# 分类特征编码
for column, encoder in self.encoders.items():
transformed_data[column] = encoder.transform(data[column])
return transformed_data
1.4 Copilot集成开发实践
以下展示如何在真实项目中集成Copilot:
python
# web开发示例:Flask API开发
from flask import Flask, request, jsonify
from typing import Dict, List, Optional
app = Flask(__name__)
class TaskManager:
"""简单的任务管理器"""
def __init__(self):
self.tasks = []
self.next_id = 1
def create_task(self, title: str, description: str, priority: int = 1) -> Dict:
"""创建新任务"""
task = {
'id': self.next_id,
'title': title,
'description': description,
'priority': priority,
'completed': False,
'created_at': '2024-01-01T00:00:00Z' # 实际应该用datetime.now()
}
self.tasks.append(task)
self.next_id += 1
return task
def get_task(self, task_id: int) -> Optional[Dict]:
"""根据ID获取任务"""
for task in self.tasks:
if task['id'] == task_id:
return task
return None
def update_task(self, task_id: int, updates: Dict) -> Optional[Dict]:
"""更新任务"""
task = self.get_task(task_id)
if task:
task.update(updates)
return task
return None
def delete_task(self, task_id: int) -> bool:
"""删除任务"""
global tasks
initial_length = len(self.tasks)
self.tasks = [task for task in self.tasks if task['id'] != task_id]
return len(self.tasks) < initial_length
# 初始化任务管理器
task_manager = TaskManager()
# API路由
@app.route('/tasks', methods=['POST'])
def create_task():
"""创建新任务"""
data = request.get_json()
if not data or 'title' not in data:
return jsonify({'error': '缺少标题'}), 400
task = task_manager.create_task(
title=data['title'],
description=data.get('description', ''),
priority=data.get('priority', 1)
)
return jsonify(task), 201
@app.route('/tasks', methods=['GET'])
def get_tasks():
"""获取所有任务"""
# 支持过滤和排序
status_filter = request.args.get('status')
priority_filter = request.args.get('priority')
tasks = task_manager.tasks.copy()
# 应用过滤器
if status_filter == 'completed':
tasks = [task for task in tasks if task['completed']]
elif status_filter == 'active':
tasks = [task for task in tasks if not task['completed']]
if priority_filter:
tasks = [task for task in tasks if task['priority'] == int(priority_filter)]
# 排序
sort_by = request.args.get('sort_by', 'id')
if sort_by in ['id', 'priority', 'created_at']:
tasks.sort(key=lambda x: x[sort_by])
return jsonify({'tasks': tasks, 'count': len(tasks)})
@app.route('/tasks/<int:task_id>', methods=['GET'])
def get_task(task_id):
"""获取特定任务"""
task = task_manager.get_task(task_id)
if task:
return jsonify(task)
return jsonify({'error': '任务未找到'}), 404
@app.route('/tasks/<int:task_id>', methods=['PUT'])
def update_task(task_id):
"""更新任务"""
data = request.get_json()
task = task_manager.update_task(task_id, data)
if task:
return jsonify(task)
return jsonify({'error': '任务未找到'}), 404
@app.route('/tasks/<int:task_id>', methods=['DELETE'])
def delete_task(task_id):
"""删除任务"""
if task_manager.delete_task(task_id):
return jsonify({'message': '任务已删除'})
return jsonify({'error': '任务未找到'}), 404
if __name__ == '__main__':
app.run(debug=True)
二、数据标注工具:机器学习的数据基石
2.1 数据标注平台架构
数据标注工具是机器学习项目中的重要环节,以下是一个完整的数据标注系统设计:
python
# 数据标注平台核心架构
import json
from enum import Enum
from typing import List, Dict, Any, Optional
from datetime import datetime
from dataclasses import dataclass
class AnnotationType(Enum):
CLASSIFICATION = "classification"
BOUNDING_BOX = "bounding_box"
POLYGON = "polygon"
SEGMENTATION = "segmentation"
NER = "named_entity_recognition"
@dataclass
class Annotation:
id: str
data_id: str
annotator_id: str
annotation_type: AnnotationType
labels: List[str]
metadata: Dict[str, Any]
created_at: datetime
updated_at: datetime
class DataAnnotationPlatform:
"""数据标注平台核心类"""
def __init__(self, storage_backend, ml_backend=None):
self.storage = storage_backend
self.ml_backend = ml_backend
self.projects = {}
self.annotators = {}
def create_project(self, name, description, annotation_type,
classes, guidelines):
"""创建标注项目"""
project_id = f"project_{len(self.projects) + 1}"
project = {
'id': project_id,
'name': name,
'description': description,
'annotation_type': annotation_type,
'classes': classes,
'guidelines': guidelines,
'created_at': datetime.now(),
'status': 'active'
}
self.projects[project_id] = project
return project
def upload_dataset(self, project_id, dataset_files, file_type='image'):
"""上传数据集"""
project = self.projects.get(project_id)
if not project:
raise ValueError(f"项目 {project_id} 不存在")
# 处理上传的文件
data_items = []
for file_info in dataset_files:
data_id = f"data_{len(data_items) + 1}"
data_item = {
'id': data_id,
'project_id': project_id,
'file_path': file_info['path'],
'file_type': file_type,
'metadata': file_info.get('metadata', {}),
'status': 'pending',
'uploaded_at': datetime.now()
}
data_items.append(data_item)
# 存储到后端
self.storage.batch_save(data_items)
return len(data_items)
def assign_tasks(self, project_id, annotator_ids, items_per_annotator=100):
"""分配标注任务"""
# 获取未标注的数据
pending_items = self.storage.get_pending_items(project_id, limit=1000)
assignments = []
for annotator_id in annotator_ids:
# 为每个标注员分配任务
assigned_items = pending_items[:items_per_annotator]
pending_items = pending_items[items_per_annotator:]
for item in assigned_items:
assignment = {
'annotator_id': annotator_id,
'data_id': item['id'],
'project_id': project_id,
'assigned_at': datetime.now(),
'status': 'assigned'
}
assignments.append(assignment)
if not pending_items:
break
self.storage.batch_save_assignments(assignments)
return assignments
def submit_annotation(self, data_id, annotator_id, labels, metadata=None):
"""提交标注结果"""
annotation = Annotation(
id=f"annotation_{datetime.now().timestamp()}",
data_id=data_id,
annotator_id=annotator_id,
annotation_type=AnnotationType.CLASSIFICATION,
labels=labels,
metadata=metadata or {},
created_at=datetime.now(),
updated_at=datetime.now()
)
# 保存标注
self.storage.save_annotation(annotation)
# 更新数据项状态
self.storage.update_item_status(data_id, 'annotated')
return annotation
def get_annotation_quality(self, project_id):
"""计算标注质量指标"""
annotations = self.storage.get_project_annotations(project_id)
# 计算标注者一致性
consistency_metrics = self._calculate_consistency(annotations)
# 计算标注进度
progress_metrics = self._calculate_progress(project_id)
return {
'consistency': consistency_metrics,
'progress': progress_metrics,
'total_annotations': len(annotations),
'unique_annotators': len(set(a.annotator_id for a in annotations))
}
def _calculate_consistency(self, annotations):
"""计算标注一致性"""
# 实现一致性计算逻辑
pass
def _calculate_progress(self, project_id):
"""计算标注进度"""
total_items = self.storage.get_project_item_count(project_id)
annotated_items = self.storage.get_annotated_item_count(project_id)
return {
'total': total_items,
'annotated': annotated_items,
'progress_percentage': (annotated_items / total_items * 100) if total_items > 0 else 0
}
# 存储后端抽象
class StorageBackend:
def batch_save(self, items):
pass
def get_pending_items(self, project_id, limit=100):
pass
def batch_save_assignments(self, assignments):
pass
def save_annotation(self, annotation):
pass
def update_item_status(self, data_id, status):
pass
def get_project_annotations(self, project_id):
pass
def get_project_item_count(self, project_id):
pass
def get_annotated_item_count(self, project_id):
pass
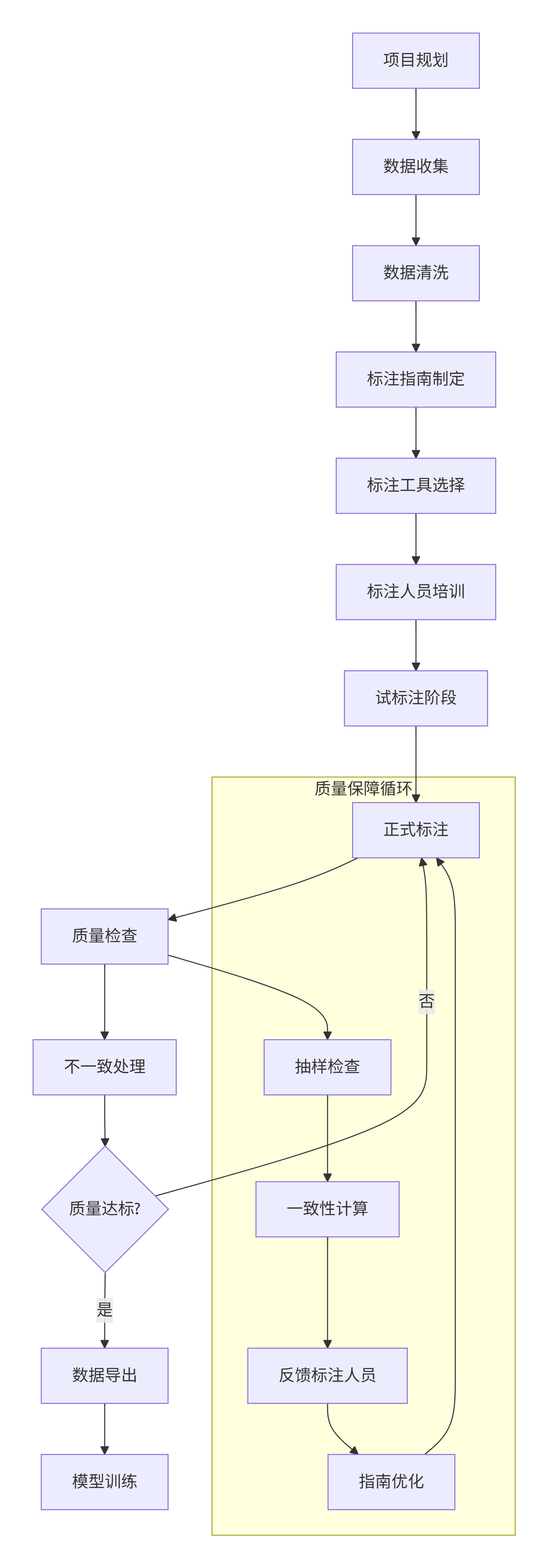
2.2 数据标注流程
graph TD
A[项目规划] --> B[数据收集]
B --> C[数据清洗]
C --> D[标注指南制定]
D --> E[标注工具选择]
E --> F[标注人员培训]
F --> G[试标注阶段]
G --> H[正式标注]
H --> I[质量检查]
I --> J[不一致处理]
J --> K{质量达标?}
K -->|否| H
K -->|是| L[数据导出]
L --> M[模型训练]
subgraph "质量保障循环"
N[抽样检查] --> O[一致性计算]
O --> P[反馈标注人员]
P --> Q[指南优化]
Q --> H
end
I --> N
2.3 计算机视觉数据标注示例
python
# 计算机视觉标注工具实现
import cv2
import numpy as np
from PIL import Image, ImageDraw
import json
class CVAnnotationTool:
"""计算机视觉标注工具"""
def __init__(self, image_width=800, image_height=600):
self.image_width = image_width
self.image_height = image_height
self.current_image = None
self.annotations = []
self.current_annotation = None
self.selected_tool = 'bbox' # bbox, polygon, etc.
def load_image(self, image_path):
"""加载图像"""
self.current_image = Image.open(image_path)
self.annotations = []
return self.current_image
def start_annotation(self, annotation_type='bbox'):
"""开始标注"""
self.current_annotation = {
'type': annotation_type,
'points': [],
'label': '',
'confidence': 1.0
}
def add_point(self, x, y):
"""添加标注点"""
if not self.current_annotation:
return
self.current_annotation['points'].append((x, y))
# 如果是边界框,需要2个点
if (self.current_annotation['type'] == 'bbox' and
len(self.current_annotation['points']) == 2):
self.finish_annotation()
def finish_annotation(self):
"""完成当前标注"""
if self.current_annotation and self.current_annotation['points']:
self.annotations.append(self.current_annotation)
self.current_annotation = None
def set_label(self, label):
"""设置标注标签"""
if self.current_annotation:
self.current_annotation['label'] = label
def draw_annotations(self):
"""绘制标注结果"""
if not self.current_image:
return None
# 创建副本进行绘制
draw_image = self.current_image.copy()
draw = ImageDraw.Draw(draw_image)
# 绘制已有标注
for annotation in self.annotations:
self._draw_single_annotation(draw, annotation)
# 绘制当前进行中的标注
if self.current_annotation:
self._draw_single_annotation(draw, self.current_annotation)
return draw_image
def _draw_single_annotation(self, draw, annotation):
"""绘制单个标注"""
points = annotation['points']
label = annotation['label']
if annotation['type'] == 'bbox' and len(points) == 2:
# 绘制边界框
x1, y1 = points[0]
x2, y2 = points[1]
draw.rectangle([x1, y1, x2, y2], outline='red', width=2)
# 绘制标签
if label:
draw.text((x1, y1 - 10), label, fill='red')
elif annotation['type'] == 'polygon':
# 绘制多边形
if len(points) > 1:
draw.line(points + [points[0]], fill='blue', width=2)
# 绘制点
for point in points:
x, y = point
draw.ellipse([x-2, y-2, x+2, y+2], fill='blue')
def export_annotations(self, format='coco'):
"""导出标注结果"""
if format == 'coco':
return self._export_coco_format()
elif format == 'voc':
return self._export_voc_format()
elif format == 'yolo':
return self._export_yolo_format()
else:
return self._export_json_format()
def _export_coco_format(self):
"""COCO格式导出"""
coco_data = {
"images": [{
"id": 1,
"width": self.current_image.width,
"height": self.current_image.height,
"file_name": "image.jpg"
}],
"annotations": [],
"categories": []
}
# 收集所有类别
categories = set()
for ann in self.annotations:
categories.add(ann['label'])
# 构建类别映射
category_map = {cat: i+1 for i, cat in enumerate(categories)}
coco_data["categories"] = [{"id": idx, "name": name}
for name, idx in category_map.items()]
# 构建标注
for i, ann in enumerate(self.annotations):
if ann['type'] == 'bbox' and len(ann['points']) == 2:
x1, y1 = ann['points'][0]
x2, y2 = ann['points'][1]
coco_ann = {
"id": i + 1,
"image_id": 1,
"category_id": category_map[ann['label']],
"bbox": [x1, y1, x2 - x1, y2 - y1],
"area": (x2 - x1) * (y2 - y1),
"iscrowd": 0
}
coco_data["annotations"].append(coco_ann)
return coco_data
# 使用示例
def demo_annotation_tool():
"""演示标注工具使用"""
tool = CVAnnotationTool()
# 模拟标注流程
tool.load_image("sample.jpg")
# 标注第一个对象
tool.start_annotation('bbox')
tool.add_point(100, 100) # 左上角
tool.add_point(200, 200) # 右下角
tool.set_label('person')
# 标注第二个对象
tool.start_annotation('bbox')
tool.add_point(300, 150)
tool.add_point(400, 250)
tool.set_label('car')
# 导出结果
coco_data = tool.export_annotations('coco')
print(json.dumps(coco_data, indent=2))
return tool
2.4 自然语言处理标注工具
python
# NLP数据标注工具
import spacy
from typing import List, Tuple
class NLPAnnotationTool:
"""自然语言处理标注工具"""
def __init__(self):
self.documents = []
self.annotations = []
self.entity_types = ['PERSON', 'ORG', 'LOC', 'DATE', 'MONEY']
def load_text(self, text: str, doc_id: str = None):
"""加载文本"""
if not doc_id:
doc_id = f"doc_{len(self.documents) + 1}"
document = {
'id': doc_id,
'text': text,
'tokens': self._tokenize(text),
'entities': []
}
self.documents.append(document)
return document
def _tokenize(self, text: str) -> List[dict]:
"""简单的分词"""
# 实际应用中可以使用spacy等专业工具
tokens = []
words = text.split()
start = 0
for word in words:
# 找到单词在原文中的位置
start = text.find(word, start)
if start == -1:
continue
end = start + len(word)
tokens.append({
'text': word,
'start': start,
'end': end,
'index': len(tokens)
})
start = end
return tokens
def add_entity(self, doc_id: str, start: int, end: int,
entity_type: str, text: str):
"""添加实体标注"""
annotation = {
'doc_id': doc_id,
'start': start,
'end': end,
'entity_type': entity_type,
'text': text,
'annotator_id': 'user_1',
'created_at': datetime.now()
}
self.annotations.append(annotation)
# 更新文档实体列表
for doc in self.documents:
if doc['id'] == doc_id:
doc['entities'].append({
'start': start,
'end': end,
'type': entity_type
})
break
return annotation
def export_conll_format(self, doc_id: str) -> List[str]:
"""导出CONLL格式"""
doc = next((d for d in self.documents if d['id'] == doc_id), None)
if not doc:
return []
# 获取该文档的实体标注
doc_annotations = [a for a in self.annotations if a['doc_id'] == doc_id]
# 为每个token分配标签
token_labels = ['O'] * len(doc['tokens'])
for ann in doc_annotations:
# 找到与实体重叠的tokens
for i, token in enumerate(doc['tokens']):
if (token['start'] >= ann['start'] and
token['end'] <= ann['end']):
# 确定BIO标签
if token['start'] == ann['start']:
token_labels[i] = f'B-{ann["entity_type"]}'
else:
token_labels[i] = f'I-{ann["entity_type"]}'
# 生成CONLL格式
conll_lines = []
for token, label in zip(doc['tokens'], token_labels):
conll_lines.append(f"{token['text']} {label}")
return conll_lines
def calculate_iaa(self, doc_id: str, annotator1: str, annotator2: str) -> float:
"""计算标注者间一致性"""
# 获取两个标注者的标注
ann1_annotations = [
a for a in self.annotations
if a['doc_id'] == doc_id and a['annotator_id'] == annotator1
]
ann2_annotations = [
a for a in self.annotations
if a['doc_id'] == doc_id and a['annotator_id'] == annotator2
]
# 计算F1分数作为一致性指标
precision = self._calculate_precision(ann1_annotations, ann2_annotations)
recall = self._calculate_recall(ann1_annotations, ann2_annotations)
if precision + recall == 0:
return 0.0
f1 = 2 * precision * recall / (precision + recall)
return f1
def _calculate_precision(self, ann1: List, ann2: List) -> float:
"""计算精确率"""
if not ann1:
return 0.0
matches = 0
for a1 in ann1:
for a2 in ann2:
if (a1['start'] == a2['start'] and
a1['end'] == a2['end'] and
a1['entity_type'] == a2['entity_type']):
matches += 1
break
return matches / len(ann1)
def _calculate_recall(self, ann1: List, ann2: List) -> float:
"""计算召回率"""
return self._calculate_precision(ann2, ann1)
# 使用示例
def demo_nlp_annotation():
"""演示NLP标注工具"""
tool = NLPAnnotationTool()
# 加载文本
text = "苹果公司于2023年9月12日在加利福尼亚发布了新款iPhone。"
doc = tool.load_text(text, "doc_1")
# 添加实体标注
tool.add_entity("doc_1", 0, 2, "ORG", "苹果公司")
tool.add_entity("doc_1", 3, 11, "DATE", "2023年9月12日")
tool.add_entity("doc_1", 12, 17, "LOC", "加利福尼亚")
tool.add_entity("doc_1", 20, 27, "PRODUCT", "新款iPhone")
# 导出CONLL格式
conll_lines = tool.export_conll_format("doc_1")
print("CONLL格式输出:")
for line in conll_lines:
print(line)
return tool
三、模型训练平台:规模化机器学习
3.1 分布式训练平台架构
python
# 分布式训练平台核心组件
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, DistributedSampler
import argparse
import os
from datetime import datetime
import json
class DistributedTrainingPlatform:
"""分布式训练平台"""
def __init__(self, config):
self.config = config
self.setup_distributed()
self.model = None
self.optimizer = None
self.scheduler = None
def setup_distributed(self):
"""初始化分布式训练环境"""
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
self.rank = int(os.environ['RANK'])
self.world_size = int(os.environ['WORLD_SIZE'])
self.local_rank = int(os.environ['LOCAL_RANK'])
else:
# 单机训练
self.rank = 0
self.world_size = 1
self.local_rank = 0
# 设置GPU
if torch.cuda.is_available():
torch.cuda.set_device(self.local_rank)
# 初始化进程组
if self.world_size > 1:
dist.init_process_group(backend='nccl')
print(f"初始化进程 {self.rank}/{self.world_size}, local_rank: {self.local_rank}")
def setup_model(self, model_class, model_config):
"""设置模型"""
self.model = model_class(**model_config)
if torch.cuda.is_available():
self.model = self.model.cuda()
# 分布式数据并行
if self.world_size > 1:
self.model = DDP(self.model, device_ids=[self.local_rank])
return self.model
def setup_optimizer(self, optimizer_class, optimizer_config):
"""设置优化器"""
self.optimizer = optimizer_class(
self.model.parameters(), **optimizer_config
)
return self.optimizer
def setup_scheduler(self, scheduler_class, scheduler_config):
"""设置学习率调度器"""
self.scheduler = scheduler_class(self.optimizer, **scheduler_config)
return self.scheduler
def setup_dataloader(self, dataset, batch_size, num_workers=4):
"""设置数据加载器"""
if self.world_size > 1:
sampler = DistributedSampler(
dataset,
num_replicas=self.world_size,
rank=self.rank,
shuffle=True
)
else:
sampler = None
dataloader = DataLoader(
dataset,
batch_size=batch_size,
sampler=sampler,
num_workers=num_workers,
pin_memory=True
)
return dataloader
def train_epoch(self, train_loader, criterion, epoch):
"""训练一个epoch"""
self.model.train()
total_loss = 0.0
total_samples = 0
for batch_idx, (data, target) in enumerate(train_loader):
# 移动数据到GPU
if torch.cuda.is_available():
data, target = data.cuda(), target.cuda()
# 前向传播
self.optimizer.zero_grad()
output = self.model(data)
loss = criterion(output, target)
# 反向传播
loss.backward()
self.optimizer.step()
# 统计信息
total_loss += loss.item() * data.size(0)
total_samples += data.size(0)
if batch_idx % self.config['log_interval'] == 0 and self.rank == 0:
print(f'Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} '
f'({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
# 计算平均损失
avg_loss = total_loss / total_samples
# 同步所有进程的损失
if self.world_size > 1:
avg_loss_tensor = torch.tensor(avg_loss).cuda()
dist.all_reduce(avg_loss_tensor)
avg_loss = avg_loss_tensor.item() / self.world_size
return avg_loss
def validate(self, val_loader, criterion):
"""验证模型"""
self.model.eval()
total_loss = 0.0
total_correct = 0
total_samples = 0
with torch.no_grad():
for data, target in val_loader:
if torch.cuda.is_available():
data, target = data.cuda(), target.cuda()
output = self.model(data)
loss = criterion(output, target)
total_loss += loss.item() * data.size(0)
pred = output.argmax(dim=1, keepdim=True)
total_correct += pred.eq(target.view_as(pred)).sum().item()
total_samples += data.size(0)
avg_loss = total_loss / total_samples
accuracy = total_correct / total_samples
# 同步所有进程的指标
if self.world_size > 1:
avg_loss_tensor = torch.tensor(avg_loss).cuda()
accuracy_tensor = torch.tensor(accuracy).cuda()
dist.all_reduce(avg_loss_tensor)
dist.all_reduce(accuracy_tensor)
avg_loss = avg_loss_tensor.item() / self.world_size
accuracy = accuracy_tensor.item() / self.world_size
return avg_loss, accuracy
def save_checkpoint(self, epoch, metrics, filepath):
"""保存检查点"""
if self.rank != 0:
return
checkpoint = {
'epoch': epoch,
'model_state_dict': self.model.state_dict(),
'optimizer_state_dict': self.optimizer.state_dict(),
'scheduler_state_dict': self.scheduler.state_dict() if self.scheduler else None,
'metrics': metrics,
'config': self.config,
'timestamp': datetime.now().isoformat()
}
torch.save(checkpoint, filepath)
print(f"检查点已保存: {filepath}")
def load_checkpoint(self, filepath):
"""加载检查点"""
checkpoint = torch.load(filepath, map_location='cpu')
self.model.load_state_dict(checkpoint['model_state_dict'])
self.optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
if self.scheduler and checkpoint['scheduler_state_dict']:
self.scheduler.load_state_dict(checkpoint['scheduler_state_dict'])
print(f"加载检查点: {filepath}, epoch: {checkpoint['epoch']}")
return checkpoint['epoch'], checkpoint['metrics']
# 训练配置管理
class TrainingConfig:
"""训练配置管理"""
def __init__(self, config_file=None):
self.default_config = {
'model': {
'type': 'resnet50',
'num_classes': 1000,
'pretrained': True
},
'training': {
'batch_size': 32,
'epochs': 100,
'learning_rate': 0.001,
'weight_decay': 1e-4,
'momentum': 0.9
},
'optimizer': {
'type': 'adam',
'lr': 0.001,
'betas': [0.9, 0.999]
},
'scheduler': {
'type': 'cosine',
'T_max': 100
},
'data': {
'train_dir': './data/train',
'val_dir': './data/val',
'num_workers': 4
},
'distributed': {
'world_size': 1,
'backend': 'nccl'
},
'logging': {
'log_interval': 10,
'checkpoint_interval': 5,
'experiment_name': 'default'
}
}
if config_file:
self.load_config(config_file)
else:
self.config = self.default_config
def load_config(self, config_file):
"""从文件加载配置"""
with open(config_file, 'r') as f:
user_config = json.load(f)
# 深度合并配置
self.config = self._deep_merge(self.default_config, user_config)
def _deep_merge(self, base, user):
"""深度合并字典"""
result = base.copy()
for key, value in user.items():
if (key in result and isinstance(result[key], dict)
and isinstance(value, dict)):
result[key] = self._deep_merge(result[key], value)
else:
result[key] = value
return result
def save_config(self, filepath):
"""保存配置到文件"""
with open(filepath, 'w') as f:
json.dump(self.config, f, indent=2)
def get(self, key, default=None):
"""获取配置值"""
keys = key.split('.')
value = self.config
for k in keys:
if isinstance(value, dict) and k in value:
value = value[k]
else:
return default
return value
# 示例训练脚本
def main_training_script():
"""主训练脚本示例"""
# 解析参数
parser = argparse.ArgumentParser()
parser.add_argument('--config', type=str, required=True,
help='配置文件路径')
parser.add_argument('--resume', type=str, default=None,
help='恢复训练的检查点路径')
args = parser.parse_args()
# 加载配置
config_manager = TrainingConfig(args.config)
config = config_manager.config
# 初始化训练平台
platform = DistributedTrainingPlatform(config)
# 设置模型
model_class = get_model_class(config['model']['type'])
model = platform.setup_model(model_class, config['model'])
# 设置优化器和调度器
optimizer = platform.setup_optimizer(
get_optimizer_class(config['optimizer']['type']),
config['optimizer']
)
if 'scheduler' in config:
scheduler = platform.setup_scheduler(
get_scheduler_class(config['scheduler']['type']),
config['scheduler']
)
# 设置数据集和数据加载器
train_dataset = create_dataset(config['data']['train_dir'], is_train=True)
val_dataset = create_dataset(config['data']['val_dir'], is_train=False)
train_loader = platform.setup_dataloader(
train_dataset,
config['training']['batch_size'],
config['data']['num_workers']
)
val_loader = platform.setup_dataloader(
val_dataset,
config['training']['batch_size'],
config['data']['num_workers']
)
# 损失函数
criterion = torch.nn.CrossEntropyLoss()
# 恢复训练
start_epoch = 0
best_accuracy = 0.0
if args.resume:
start_epoch, metrics = platform.load_checkpoint(args.resume)
best_accuracy = metrics.get('best_accuracy', 0.0)
# 训练循环
for epoch in range(start_epoch, config['training']['epochs']):
if platform.world_size > 1:
train_loader.sampler.set_epoch(epoch)
# 训练
train_loss = platform.train_epoch(train_loader, criterion, epoch)
# 验证
val_loss, accuracy = platform.validate(val_loader, criterion)
# 学习率调度
if scheduler:
scheduler.step()
# 记录指标
if platform.rank == 0:
print(f'Epoch {epoch}: Train Loss: {train_loss:.4f}, '
f'Val Loss: {val_loss:.4f}, Accuracy: {accuracy:.4f}')
# 保存最佳模型
if accuracy > best_accuracy:
best_accuracy = accuracy
platform.save_checkpoint(
epoch,
{'best_accuracy': best_accuracy},
f'best_model_epoch_{epoch}.pth'
)
# 定期保存检查点
if epoch % config['logging']['checkpoint_interval'] == 0:
platform.save_checkpoint(
epoch,
{'best_accuracy': best_accuracy},
f'checkpoint_epoch_{epoch}.pth'
)
# 清理分布式训练
if platform.world_size > 1:
dist.destroy_process_group()
def get_model_class(model_type):
"""根据类型获取模型类"""
models = {
'resnet50': torchvision.models.resnet50,
'resnet101': torchvision.models.resnet101,
'vit': torchvision.models.vit_b_16,
}
return models.get(model_type, torchvision.models.resnet50)
def get_optimizer_class(optimizer_type):
"""根据类型获取优化器类"""
optimizers = {
'adam': torch.optim.Adam,
'sgd': torch.optim.SGD,
'adamw': torch.optim.AdamW,
}
return optimizers.get(optimizer_type, torch.optim.Adam)
def get_scheduler_class(scheduler_type):
"""根据类型获取调度器类"""
schedulers = {
'cosine': torch.optim.lr_scheduler.CosineAnnealingLR,
'step': torch.optim.lr_scheduler.StepLR,
'multi_step': torch.optim.lr_scheduler.MultiStepLR,
}
return schedulers.get(scheduler_type, torch.optim.lr_scheduler.StepLR)
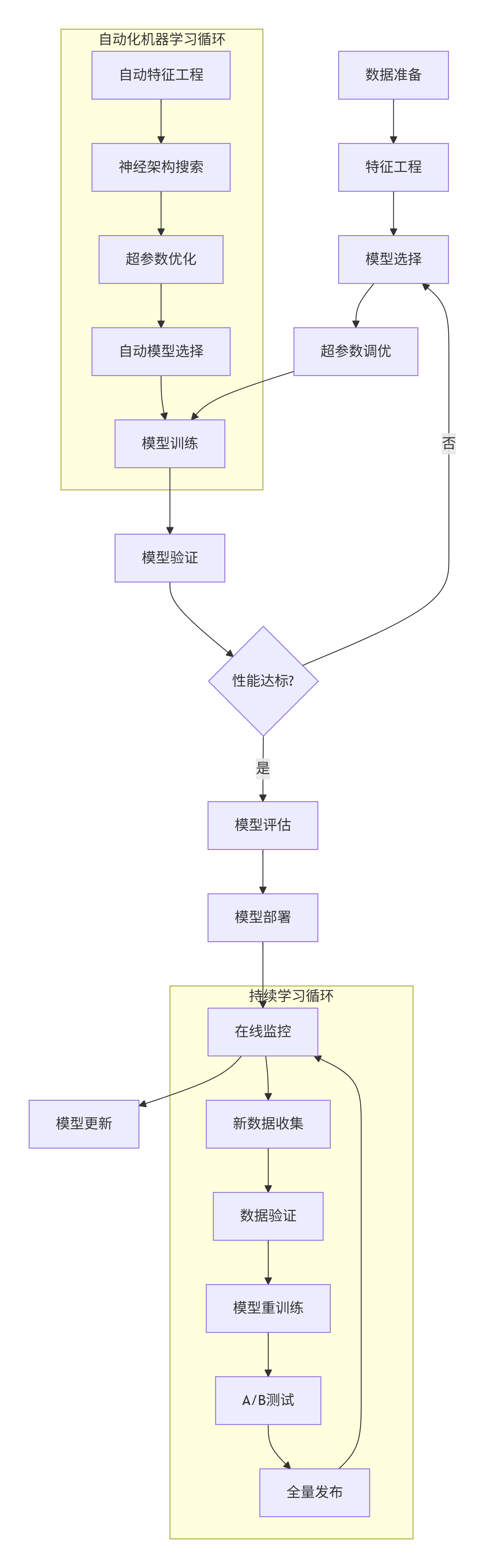
3.2 模型训练完整流程
graph TD
A[数据准备] --> B[特征工程]
B --> C[模型选择]
C --> D[超参数调优]
D --> E[模型训练]
E --> F[模型验证]
F --> G{性能达标?}
G -->|否| C
G -->|是| H[模型评估]
H --> I[模型部署]
I --> J[在线监控]
J --> K[模型更新]
subgraph "自动化机器学习循环"
L[自动特征工程] --> M[神经架构搜索]
M --> N[超参数优化]
N --> O[自动模型选择]
O --> E
end
subgraph "持续学习循环"
P[新数据收集] --> Q[数据验证]
Q --> R[模型重训练]
R --> S[A/B测试]
S --> T[全量发布]
T --> J
end
J --> P
3.3 超参数优化框架
python
# 超参数优化系统
import optuna
from optuna.trial import Trial
import numpy as np
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
import warnings
warnings.filterwarnings('ignore')
class HyperparameterOptimizer:
"""超参数优化器"""
def __init__(self, estimator, X, y, cv=5, scoring='accuracy'):
self.estimator = estimator
self.X = X
self.y = y
self.cv = cv
self.scoring = scoring
self.study = None
self.best_params = None
self.best_score = None
def objective(self, trial: Trial):
"""优化目标函数"""
# 定义超参数搜索空间
if hasattr(self.estimator, 'n_estimators'):
# 随机森林参数
n_estimators = trial.suggest_int('n_estimators', 50, 500)
max_depth = trial.suggest_int('max_depth', 3, 15)
min_samples_split = trial.suggest_int('min_samples_split', 2, 20)
min_samples_leaf = trial.suggest_int('min_samples_leaf', 1, 10)
max_features = trial.suggest_categorical('max_features',
['auto', 'sqrt', 'log2'])
model = self.estimator(
n_estimators=n_estimators,
max_depth=max_depth,
min_samples_split=min_samples_split,
min_samples_leaf=min_samples_leaf,
max_features=max_features,
random_state=42
)
elif hasattr(self.estimator, 'C'):
# SVM参数
C = trial.suggest_loguniform('C', 1e-5, 1e5)
kernel = trial.suggest_categorical('kernel',
['linear', 'rbf', 'poly'])
gamma = trial.suggest_loguniform('gamma', 1e-5, 1e5)
model = self.estimator(
C=C,
kernel=kernel,
gamma=gamma,
random_state=42
)
else:
# 通用参数
model = self.estimator()
# 交叉验证
scores = cross_val_score(model, self.X, self.y,
cv=self.cv, scoring=self.scoring)
return scores.mean()
def optimize(self, n_trials=100, direction='maximize'):
"""执行优化"""
self.study = optuna.create_study(direction=direction)
self.study.optimize(self.objective, n_trials=n_trials)
self.best_params = self.study.best_params
self.best_score = self.study.best_value
return self.best_params, self.best_score
def get_optimization_history(self):
"""获取优化历史"""
if not self.study:
return None
trials = self.study.trials
history = {
'values': [t.value for t in trials if t.value is not None],
'params': [t.params for t in trials if t.value is not None],
'timestamps': [t.datetime_start for t in trials if t.value is not None]
}
return history
def plot_optimization_history(self):
"""绘制优化历史"""
if not self.study:
return None
return optuna.visualization.plot_optimization_history(self.study)
def plot_parallel_coordinate(self):
"""绘制平行坐标图"""
if not self.study:
return None
return optuna.visualization.plot_parallel_coordinate(self.study)
def plot_param_importances(self):
"""绘制参数重要性"""
if not self.study:
return None
return optuna.visualization.plot_param_importances(self.study)
# 神经网络超参数优化
class NeuralNetworkOptimizer:
"""神经网络超参数优化"""
def __init__(self, input_dim, output_dim, X_train, y_train,
X_val, y_val, epochs=50):
self.input_dim = input_dim
self.output_dim = output_dim
self.X_train = X_train
self.y_train = y_train
self.X_val = X_val
self.y_val = y_val
self.epochs = epochs
def create_model(self, trial: Trial):
"""创建模型"""
# 网络结构参数
n_layers = trial.suggest_int('n_layers', 1, 5)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Input(shape=(self.input_dim,)))
# 添加隐藏层
for i in range(n_layers):
units = trial.suggest_int(f'units_layer_{i}', 32, 512)
dropout_rate = trial.suggest_float(f'dropout_layer_{i}', 0.0, 0.5)
model.add(tf.keras.layers.Dense(units, activation='relu'))
model.add(tf.keras.layers.Dropout(dropout_rate))
# 输出层
if self.output_dim == 1:
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
loss = 'binary_crossentropy'
else:
model.add(tf.keras.layers.Dense(self.output_dim, activation='softmax'))
loss = 'sparse_categorical_crossentropy'
# 优化器参数
optimizer_name = trial.suggest_categorical('optimizer',
['adam', 'sgd', 'rmsprop'])
learning_rate = trial.suggest_loguniform('learning_rate', 1e-5, 1e-2)
if optimizer_name == 'adam':
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
elif optimizer_name == 'sgd':
optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate)
else:
optimizer = tf.keras.optimizers.RMSprop(learning_rate=learning_rate)
model.compile(optimizer=optimizer,
loss=loss,
metrics=['accuracy'])
return model
def objective(self, trial: Trial):
"""优化目标函数"""
# 创建模型
model = self.create_model(trial)
# 训练参数
batch_size = trial.suggest_categorical('batch_size', [16, 32, 64, 128])
# 训练模型
history = model.fit(
self.X_train, self.y_train,
validation_data=(self.X_val, self.y_val),
epochs=self.epochs,
batch_size=batch_size,
verbose=0
)
# 返回验证集上的最佳准确率
best_val_accuracy = max(history.history['val_accuracy'])
return best_val_accuracy
# 使用示例
def demo_hyperparameter_optimization():
"""演示超参数优化"""
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# 加载数据
data = load_iris()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 初始化优化器
optimizer = HyperparameterOptimizer(
estimator=RandomForestClassifier,
X=X_train,
y=y_train,
cv=5,
scoring='accuracy'
)
# 执行优化
best_params, best_score = optimizer.optimize(n_trials=50)
print(f"最佳参数: {best_params}")
print(f"最佳分数: {best_score:.4f}")
# 使用最佳参数训练最终模型
best_model = RandomForestClassifier(**best_params, random_state=42)
best_model.fit(X_train, y_train)
test_score = best_model.score(X_test, y_test)
print(f"测试集分数: {test_score:.4f}")
return optimizer, best_model
四、综合案例:端到端AI项目实战
4.1 智能客服系统开发
以下是一个结合了智能编码、数据标注和模型训练的完整案例:
python
# 智能客服系统端到端实现
import pandas as pd
import numpy as np
from transformers import (AutoTokenizer, AutoModelForSequenceClassification,
Trainer, TrainingArguments, pipeline)
from sklearn.model_selection import train_test_split
import datasets
from typing import Dict, List, Any
import json
class CustomerServiceAI:
"""智能客服AI系统"""
def __init__(self, model_name="bert-base-uncased"):
self.model_name = model_name
self.tokenizer = None
self.model = None
self.classifier = None
self.label_encoder = {}
self.label_decoder = {}
def prepare_data(self, data_file: str) -> datasets.Dataset:
"""准备训练数据"""
# 加载数据
df = pd.read_csv(data_file)
# 数据清洗
df = self._clean_data(df)
# 编码标签
unique_labels = df['category'].unique()
self.label_encoder = {label: idx for idx, label in enumerate(unique_labels)}
self.label_decoder = {idx: label for label, idx in self.label_encoder.items()}
df['label'] = df['category'].map(self.label_encoder)
# 分割数据集
train_df, val_df = train_test_split(
df, test_size=0.2, random_state=42, stratify=df['label']
)
# 转换为HuggingFace数据集格式
train_dataset = datasets.Dataset.from_pandas(train_df)
val_dataset = datasets.Dataset.from_pandas(val_df)
return train_dataset, val_dataset
def _clean_data(self, df: pd.DataFrame) -> pd.DataFrame:
"""数据清洗"""
# 去除空值
df = df.dropna(subset=['text', 'category'])
# 文本清洗
df['text'] = df['text'].str.lower().str.strip()
# 过滤过短的文本
df = df[df['text'].str.len() > 5]
return df
def tokenize_function(self, examples):
"""分词函数"""
return self.tokenizer(
examples["text"],
padding="max_length",
truncation=True,
max_length=128
)
def setup_model(self, num_labels: int):
"""设置模型"""
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name)
self.model = AutoModelForSequenceClassification.from_pretrained(
self.model_name,
num_labels=num_labels
)
def train(self, train_dataset, val_dataset, output_dir="./results"):
"""训练模型"""
# 分词
tokenized_train = train_dataset.map(self.tokenize_function, batched=True)
tokenized_val = val_dataset.map(self.tokenize_function, batched=True)
# 训练参数
training_args = TrainingArguments(
output_dir=output_dir,
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
logging_steps=10,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
metric_for_best_model="accuracy",
greater_is_better=True
)
# 训练器
trainer = Trainer(
model=self.model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_val,
compute_metrics=self.compute_metrics
)
# 开始训练
trainer.train()
# 保存模型
trainer.save_model()
self.tokenizer.save_pretrained(output_dir)
# 创建分类管道
self.classifier = pipeline(
"text-classification",
model=self.model,
tokenizer=self.tokenizer,
device=0 if torch.cuda.is_available() else -1
)
return trainer
def compute_metrics(self, eval_pred):
"""计算评估指标"""
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return {
'accuracy': (predictions == labels).mean(),
'precision': self._calculate_precision(predictions, labels),
'recall': self._calculate_recall(predictions, labels),
'f1': self._calculate_f1(predictions, labels)
}
def _calculate_precision(self, predictions, labels):
"""计算精确率"""
from sklearn.metrics import precision_score
return precision_score(labels, predictions, average='weighted')
def _calculate_recall(self, predictions, labels):
"""计算召回率"""
from sklearn.metrics import recall_score
return recall_score(labels, predictions, average='weighted')
def _calculate_f1(self, predictions, labels):
"""计算F1分数"""
from sklearn.metrics import f1_score
return f1_score(labels, predictions, average='weighted')
def predict(self, text: str) -> Dict[str, Any]:
"""预测类别"""
if not self.classifier:
raise ValueError("模型未训练,请先训练模型")
result = self.classifier(text)[0]
label_idx = int(result['label'].split('_')[-1])
return {
'category': self.label_decoder[label_idx],
'confidence': result['score'],
'label_id': label_idx
}
def batch_predict(self, texts: List[str]) -> List[Dict[str, Any]]:
"""批量预测"""
return [self.predict(text) for text in texts]
def save_system(self, directory: str):
"""保存系统"""
import os
os.makedirs(directory, exist_ok=True)
# 保存模型和tokenizer
self.model.save_pretrained(directory)
self.tokenizer.save_pretrained(directory)
# 保存标签映射
with open(f"{directory}/label_mapping.json", 'w') as f:
json.dump({
'encoder': self.label_encoder,
'decoder': self.label_decoder
}, f, indent=2)
# 保存配置
config = {
'model_name': self.model_name,
'timestamp': datetime.now().isoformat()
}
with open(f"{directory}/config.json", 'w') as f:
json.dump(config, f, indent=2)
@classmethod
def load_system(cls, directory: str):
"""加载系统"""
# 加载配置
with open(f"{directory}/config.json", 'r') as f:
config = json.load(f)
# 创建实例
instance = cls(model_name=config['model_name'])
# 加载模型和tokenizer
instance.tokenizer = AutoTokenizer.from_pretrained(directory)
instance.model = AutoModelForSequenceClassification.from_pretrained(directory)
# 加载标签映射
with open(f"{directory}/label_mapping.json", 'r') as f:
label_mapping = json.load(f)
instance.label_encoder = label_mapping['encoder']
instance.label_decoder = {int(k): v for k, v in label_mapping['decoder'].items()}
# 创建分类管道
instance.classifier = pipeline(
"text-classification",
model=instance.model,
tokenizer=instance.tokenizer,
device=0 if torch.cuda.is_available() else -1
)
return instance
# 数据标注界面集成
class CustomerServiceAnnotator:
"""客服数据标注工具"""
def __init__(self, ai_system: CustomerServiceAI):
self.ai_system = ai_system
self.pending_data = []
self.annotations = []
def load_unlabeled_data(self, data_file: str):
"""加载未标注数据"""
df = pd.read_csv(data_file)
self.pending_data = df.to_dict('records')
def get_suggestion(self, text: str) -> Dict[str, Any]:
"""获取AI建议"""
return self.ai_system.predict(text)
def annotate_with_ai_assistance(self, data_index: int,
user_confirmation: bool = True) -> Dict[str, Any]:
"""AI辅助标注"""
if data_index >= len(self.pending_data):
raise IndexError("数据索引超出范围")
data = self.pending_data[data_index]
text = data['text']
# 获取AI建议
suggestion = self.get_suggestion(text)
# 如果用户确认,使用AI建议
if user_confirmation:
annotation = {
'text': text,
'category': suggestion['category'],
'confidence': suggestion['confidence'],
'ai_suggested': True,
'user_confirmed': True,
'timestamp': datetime.now().isoformat()
}
self.annotations.append(annotation)
self.pending_data.pop(data_index)
return annotation
return suggestion
def manual_annotation(self, data_index: int, category: str) -> Dict[str, Any]:
"""手动标注"""
if data_index >= len(self.pending_data):
raise IndexError("数据索引超出范围")
data = self.pending_data[data_index]
text = data['text']
annotation = {
'text': text,
'category': category,
'confidence': 1.0,
'ai_suggested': False,
'user_confirmed': True,
'timestamp': datetime.now().isoformat()
}
self.annotations.append(annotation)
self.pending_data.pop(data_index)
return annotation
def export_annotations(self, output_file: str):
"""导出标注结果"""
df = pd.DataFrame(self.annotations)
df.to_csv(output_file, index=False)
return len(self.annotations)
# 使用示例
def demo_customer_service_ai():
"""演示智能客服系统"""
# 初始化系统
cs_ai = CustomerServiceAI()
# 准备数据(假设有标注数据)
try:
train_dataset, val_dataset = cs_ai.prepare_data("customer_service_data.csv")
print(f"训练数据: {len(train_dataset)} 条")
print(f"验证数据: {len(val_dataset)} 条")
# 设置模型
num_labels = len(cs_ai.label_encoder)
cs_ai.setup_model(num_labels)
# 训练模型
trainer = cs_ai.train(train_dataset, val_dataset)
# 测试预测
test_text = "我的订单什么时候能发货?"
prediction = cs_ai.predict(test_text)
print(f"预测结果: {prediction}")
# 保存系统
cs_ai.save_system("./customer_service_model")
except FileNotFoundError:
print("未找到数据文件,跳过训练演示")
# 演示数据标注
annotator = CustomerServiceAnnotator(cs_ai)
# 加载未标注数据
try:
annotator.load_unlabeled_data("unlabeled_customer_queries.csv")
print(f"加载未标注数据: {len(annotator.pending_data)} 条")
# AI辅助标注
if annotator.pending_data:
suggestion = annotator.annotate_with_ai_assistance(0, user_confirmation=False)
print(f"AI建议: {suggestion}")
# 手动确认或修改
final_annotation = annotator.manual_annotation(0, "shipping_inquiry")
print(f"最终标注: {final_annotation}")
except FileNotFoundError:
print("未找到未标注数据文件,跳过标注演示")
return cs_ai, annotator
结论
AI工具链的成熟正在彻底改变我们开发软件和构建智能系统的方式。GitHub Copilot等智能编码工具通过理解上下文和代码模式,显著提高了开发效率;数据标注工具通过自动化和质量保障机制,解决了机器学习的数据瓶颈问题;模型训练平台通过分布式计算和自动化超参数优化,使得训练高性能模型变得更加容易。
这些工具的协同工作形成了一个完整的AI开发生态系统。开发者可以使用Copilot快速原型化数据预处理代码,利用标注工具准备高质量的训练数据,通过训练平台高效训练模型,最后再使用Copilot部署和监控模型。这种无缝的工作流程极大地加速了AI应用的开发周期。
未来,我们可以预见这些工具将进一步集成和智能化。编码助手将更加理解领域特定的需求,数据标注工具将结合主动学习减少人工标注工作量,训练平台将实现更加自动化的模型选择和优化。随着这些技术的发展,AI应用的开发将变得更加普及和高效,推动整个人工智能领域向前发展。
随着AI工具的不断进化,我们也需要关注相关的伦理和社会影响。自动化工具可能带来的偏见放大、技能需求变化、以及人机协作的新模式都需要我们认真思考和应对。只有在技术和人文之间找到平衡,我们才能充分发挥AI工具的潜力,创造更加美好的未来。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献326条内容
已为社区贡献326条内容

所有评论(0)