架构师的登山之路|第九站:MLOps——当 AI 不再只是模型,而是平台能力
MLOps = 把 DevOps 的理念引入机器学习,让模型从开发到上线、再到运维迭代,形成一条可重复、可观测、可演进的生产流水线。数据采集、清洗、特征工程;模型训练、调参、评估、对比;模型打包、部署、灰度发布、回滚;线上监控、数据/分布漂移检测;反馈与重训练闭环。如果说传统 AI 开发像做一次科研实验,那 MLOps 的目标,就是把科研成果变成一条稳定运转的工厂产线。
架构师的登山之路|第九站:MLOps——当 AI 不再只是模型,而是平台能力
走过数据治理与数据中台这两座“规则与平台”的山头后,我们正式进入智能化架构的领域。这一站,我们聊聊一个正在逐渐取代传统 AI 项目开发方式的概念:MLOps。
如果你以为搞 AI 只是“训练一个模型”,那就太落后了。真正能落地的 AI,必须像生产线一样高效、可控、可维护,而这正是 MLOps 要解决的核心问题。
一、从「模型开发」到「AI 生产线」
很多团队做 AI 项目的典型路径是这样的:
- 算法同学拉一份数据,在 Notebook 里训练出一个效果“还不错”的模型;
- 把模型文件(
.pkl/.pt/.onnx等)扔给后端同学,后端想办法“帮忙上线”; - 上线之后,半年没人管,数据分布早就变了,效果悄悄变差;
- 某天业务同学说“感觉不准了”,大家才开始翻 log、翻代码、翻历史数据。
本质上,这是一次性「项目模式」:更像做实验,而不是做产品。
而当 AI 真正成为业务的底座能力(例如推荐、搜索、定价、风控),它的要求就变成:
- 不只是“能跑起来”,还要:
- 可以稳定地部署;
- 可以可控地迭代;
- 可以持续地监控与回溯;
- 可以跨团队协同复用。
这就需要把「做模型」升级为「建生产线」,而这个生产线的名字就是 —— MLOps。
二、什么是 MLOps?
一句话概括:
MLOps = 把 DevOps 的理念引入机器学习,让模型从开发到上线、再到运维迭代,形成一条可重复、可观测、可演进的生产流水线。
它不只是一个工具,也不只是“模型部署”这一环,而是覆盖:
- 数据采集、清洗、特征工程;
- 模型训练、调参、评估、对比;
- 模型打包、部署、灰度发布、回滚;
- 线上监控、数据/分布漂移检测;
- 反馈与重训练闭环。
如果说传统 AI 开发像做一次科研实验,那 MLOps 的目标,就是把科研成果变成一条稳定运转的工厂产线。
三、为什么 AI 项目离不开 MLOps?
很多企业都踩过类似的坑:
-
结果不可复现
同一份 Notebook,在另一个环境跑不出同样的结果;
一年后没人说得清“这个模型当年到底是用哪一批数据、哪套特征训出来的”。 -
部署过程混乱
模型文件手工拷贝;
线上服务依赖和训练环境完全不同,经常“本地 OK,线上翻车”。 -
上线后没人管
没有监控:预测分布、关键指标没有 Dashboard;
数据分布悄悄漂移,模型效果慢慢衰减,直到业务强烈抱怨。 -
无法高频迭代
每一次改模型,都像重新打一场仗:
数据再拉一遍、环境再配一遍、上线再走一遍“手工流程”,成本巨大。
MLOps 想解决的就是这些问题——让模型像应用一样:
- 有版本、有环境;
- 有自动化流水线;
- 有监控与告警;
- 有回滚和迭代机制。
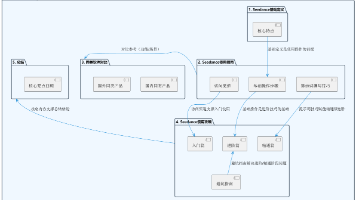
四、MLOps 全流程:模型从「想法」到「价值」的一条链路
从架构师视角看,一条完整的 MLOps 流水线大致可以拆成五个阶段:
4.1 需求 & 假设阶段
- 明确业务目标:是提升转化率、降低流失,还是识别风险?
- 转化为可衡量的指标:AUC、F1、CTR、GMV 提升等;
- 初步确定需要哪些数据、怎样的特征。
这个阶段最重要的是:定义清楚「什么叫成功」,否则后面全是拍脑袋。
4.2 数据 & 特征阶段
- 数据采集:埋点、日志、数据库、第三方数据等;
- 数据清洗与对齐:缺失值、异常值处理,时间对齐、多源对齐;
- 特征工程:特征构造、特征选择、特征归一化等;
- 数据与特征版本管理:
- 这次训练用的是「哪天之前的数据」?
- 用的是「哪些特征版本」?
这一层,如果没有管理好,后面所有“复现”和“回溯”都会变成空谈。
4.3 训练 & 评估阶段
- 选择模型结构:XGBoost / GBDT / 深度学习 / 图模型等;
- 训练任务编排:
- 手动训练 → 脚本化 → 自动调参(AutoML);
- 评估与对比:
- 不同模型版本、不同特征组合的效果对比;
- 同时关注离线指标和线上业务指标的预估。
理想状态下:
每一次训练,都会产生一条清晰的「实验记录」:
数据版本 + 特征版本 + 代码版本 + 超参配置 + 评估指标 + 模型文件。
4.4 上线 & 发布阶段
- 模型打包:容器化 / 模型格式标准化(ONNX 等);
- 部署模式:
- 在线推理服务(实时接口);
- 离线批处理(定时任务写入特征库 / 结果表);
- 发布策略:
- A/B Test;
- 灰度发布(如 5% 流量 → 20% → 50% → 全量);
- 蓝绿部署与回滚。
这一层需要和现有的 CI/CD 体系对接,也是架构师需要重点设计的部分。
4.5 监控 & 反馈 & 重训练阶段
- 监控指标:
- 系统层:QPS、延迟、错误率;
- 业务层:核心业务指标(转化、点击、收入等);
- 模型层:输入特征分布、输出分布、数据漂移、概念漂移等。
- 反馈机制:
- 触发告警:效果明显下滑、输入分布异常;
- 触发重训练:定义“何时需要重训”的规则;
- 把线上新数据纳入下一轮训练数据。
这一步,把模型从「一次上线」升级为「持续运营」,
才是真正的 MLOps 价值所在。
五、MLOps 的关键能力模块
从落地角度拆解,MLOps 通常包含几个关键能力模块:
5.1 数据与特征管理(含 Feature Store)
- 数据版本:记录训练集、验证集的时间范围与抽样规则;
- 特征版本:同一个「用户画像特征」的不同版本要可区分;
- Feature Store(特征仓库):
- 统一存储特征计算逻辑和结果;
- 既支持离线批量读取,也支持在线实时查询;
- 避免「训练时一套特征逻辑,线上推理又一套」的问题。
5.2 训练管道与任务编排
- 把「拉数 → 特征工程 → 训练 → 评估 → 产出模型」
从一堆 Notebook 变成一条可重复的流水线; - 支持定时/触发式训练:
- 比如“每周重训一次”、“数据漂移超阈值自动重训”。
常见做法是使用工作流引擎(如 Airflow、Argo、Prefect 等)来编排。
5.3 模型注册与版本管理(Model Registry)
- 每一个「通过评审的模型」都注册成一个版本;
- 记录:
- 模型文件存储位置;
- 训练元数据(数据、特征、代码、超参);
- 评估结果和上线状态(灰度、全量、已下线);
- 支持:
- 一键回滚到历史稳定版本;
- 多环境(dev / staging / prod)模型关联。
5.4 模型部署与服务化
- 支持多种部署形态:
- 在线服务:REST/gRPC 接口;
- 批处理:定时导出结果;
- 流式推理:嵌入到 Flink / Spark Streaming 作业中。
- 与基础设施对接:
- 容器化(Docker);
- 编排系统(Kubernetes);
- 配额与弹性伸缩策略。
5.5 监控、告警与审计
- 监控维度:
- 使用率(调用量、覆盖率);
- 性能(延迟、错误率、资源消耗);
- 效果(核心业务指标、模型质量指标);
- 数据漂移(输入特征分布变化、标签分布变化)。
- 告警渠道:IM、邮件、告警平台等;
- 审计能力:谁在改模型、谁把哪个版本发布到了哪里、何时修改了配置。
5.6 安全与合规
- 隐私数据处理:脱敏、匿名化、访问控制;
- 合规要求:例如某些数据不能出境、不能用于特定目的;
- 模型行为审计:对异常决策可追溯(例如风控拒绝原因)。
六、典型 MLOps 工具栈示例(按团队体量)
这里不强调具体厂牌,而是给出组合思路,你可以按自己团队情况替换同类组件。
6.1 轻量级方案:适合中小团队 / 单产品线
- 训练与实验:
- Python + 常用 ML/DL 框架(scikit-learn / XGBoost / PyTorch / TensorFlow);
- MLflow 做实验追踪与模型注册。
- 部署:
- 模型打包成 Docker 镜像;
- 用 FastAPI / Flask 暴露推理服务;
- 用现有的 CI/CD(如 GitLab CI / Jenkins)完成构建与发布。
- 监控:
- 接入 Prometheus + Grafana;
- 关键业务指标可以通过埋点接入现有监控体系。
优点:搭建成本低、学习曲线较缓;
缺点:跨团队、多项目规模化时需要重构。
6.2 成长型方案:多团队协作 / 多模型并行
- 训练编排:
- 使用 Airflow / Argo / Kubeflow Pipelines 等编排训练流程;
- 特征与数据:
- 引入 Feature Store(自建或开源);
- 模型注册与服务:
- Model Registry(MLflow / 内部平台);
- 基于 Kubernetes + KServe / Seldon 等做统一的模型服务层;
- 监控:
- 统一接入 APM + 业务监控 + 模型质量监控。
优点:更加平台化,便于多团队共享与复用;
缺点:需要专门的平台团队来建设与运维。
6.3 全托管 / 云原生方案
- 使用云厂商的 AI 平台(如各家云上的 ML 平台):
- 内置数据管理、训练、部署、监控一体化;
- 适合不想自建底层基础设施的团队。
优点:省去大量基础设施建设成本;
缺点:对云平台绑定较深,部分场景下灵活性受限。
七、架构师在 MLOps 中扮演什么角色?
MLOps 不是“算法团队的私事”,它牵涉到:
- 数据团队:数据采集、加工、治理;
- 算法团队:建模、调参、评估;
- 平台团队:基础设施、统一平台;
- 业务团队:需求定义与效果反馈。
而架构师的角色,是把这几方“接在一起”,主要包括:
-
设计整体技术架构
- 模型开发环境与生产环境如何隔离又打通;
- 数据平台、特征平台、训练平台、服务平台之间如何对接。
-
定义边界与接口
- 明确“到什么程度叫可上线”:指标要求、稳定性要求;
- 定义「从 Notebook 到可部署组件」的标准形态。
-
推动规范与最佳实践
- 模型、特征、数据的命名与版本化规范;
- 实验记录、评审流程、回滚策略。
-
关注 TCO(总成本)与可演进性
- 不盲目堆工具;
- 从轻量化方案起步,随着团队与业务发展渐进式演进。
八、给成长型架构师的一条 MLOps 学习路线
如果你现在刚开始接触 MLOps,可以按这条路线来走:
阶段 1:概念入门
- 理解:MLOps 与 DevOps 的区别与联系;
- 画出你们当前 AI 项目的真实流程图:
- 从数据 → 训练 → 上线 → 使用 → 反馈,哪里是“人工卡点”。
阶段 2:做出第一条「端到端」流水线
- 选一个简单的业务场景(如二分类 / 排序);
- 用脚本/工作流串起来:
- 数据准备 → 训练 → 评估 → 导出模型 → 部署一个简单服务;
- 把这条流水线文档化,让团队其他人也能复用。
阶段 3:引入版本管理与监控
- 为数据集和模型加上版本记录;
- 引入实验追踪工具(如 MLflow);
- 给线上模型服务加上基础监控与日志。
阶段 4:平台化与规范化
- 把验证有效的做法抽象成平台能力:
- 统一的训练模板;
- 统一的部署流程;
- 统一的监控与告警策略。
- 用少量、明确的规范把“人和平台”绑定起来。
九、常见误区:别让 MLOps 变成「重工程、轻价值」
9.1 只要“保存了模型文件”,就叫 MLOps?
保存模型文件只是最底层的存档。
没有数据与特征版本、没有训练元数据、没有部署记录,这离 MLOps 还差十万八千里。
9.2 一上来就堆一大堆“重型平台”
- 还没搞清楚团队一年能落地几个模型,就先上了一整套「全家桶平台」;
- 结果日常主要工作变成了“维护平台”,而不是“产生业务价值”。
更合理的做法是:
从一个小场景、一条流水线开始,先跑通,再逐步平台化。
9.3 只关心上线,不关心监控与迭代
- 模型上线那天是大新闻,上线之后就被遗忘;
- 没有任何“触发重训”的规则和机制。
没有「持续监控」,MLOps 就只是换了个名字的“上线流程”。
十、小结:让 AI 变成可靠的基础设施
这一站,我们从架构师视角,把 MLOps 拆成了几个关键问题:
- 它是什么:
- 把模型开发、部署、运维、迭代串联起来的一整套方法论与平台能力;
- 它解决什么:
- 结果不可复现、部署混乱、无人监控、难以迭代;
- 它包含什么:
- 数据与特征管理、训练流水线、模型注册与部署、监控与反馈;
- 架构师要做什么:
- 设计整体架构、定义接口与规范、平衡价值与成本、推动平台化演进。
简单一句话:MLOps 的价值,不在于“用了多少高大上的工具”,而在于:
能不能让 AI 在你的体系里,变成一种「稳定、可靠、可演进的基础设施」。
下一站预告
AI 平台能力搭建完成后,我们即将返回系统架构的地基——微服务架构的拆分与设计。
下一篇,我们将聊聊:
- 微服务要不要拆、拆到什么程度;
- 如何通过“领域边界、团队边界、演进节奏”三把标尺来做拆分决策;
- 在真实业务环境下,如何避免“过度微服务化”的陷阱。
敬请期待「架构师的登山之路|第十站」。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)