LangChain从入门到实践(七)——Tool工具调用
Function Calling 最早是 OpenAI 在其 API 中引入的一项功能,允许开发者将大语言模型(如 GPT-4)与外部函数或工具集成。
Tool 介绍
为什么需要 Tool
虽然大模型具备强大的语言理解和生成能力,但它本质上是静态的、不可交互的。比如:
- 不具备访问数据库、调用 API 的能力
- 不能执行代码或文件操作
- 无法实时访问互联网或动态数据等
通过 Tool(工具)机制,可以让模型具备“调用外部函数”的能力,使其能够与外部系统、API 或自定义函数交互,从而完成仅靠文本生成无法实现的任务。例如:
- 实时访问外部世界(如天气、股票、网页等)
- 调用计算函数(数学、单位换算)
- 查询数据库或搜索文档
- 实现“多轮决策”流程(如规划任务、搜索后总结)
Function calling 介绍
Function Calling 最早是 OpenAI 在其 API 中引入的一项功能,允许开发者将大语言模型(如 GPT-4)与外部函数或工具集成。通过 Function Calling,模型可以理解用户请求并生成调用外部函数所需的参数,从而实现更复杂、更动态的任务处理。
简单来说,Function calling让大语言模型拥有了调用外部接口的能力,使用这种能力,大模型能做一些比如实时获取天气信息、发送邮件等和现实世界交互的事情。
Function calling 原理
在发送信息给大模型的时候,携带着“工具”列表,这些工具列表代表着大模型能使用的工具。当大模型遇到用户提出的问题时,会先思考是否应该调用工具解决问题,如果需要调用工具,和普通消息不同,这种情况下会返回“function_call”类型的消息,请求方根据返回结果调用对应的工具得到工具输出,然后将之前的信息加上工具输出的信息一起发送给大模型,让大模型整合起来综合判断给出结果。
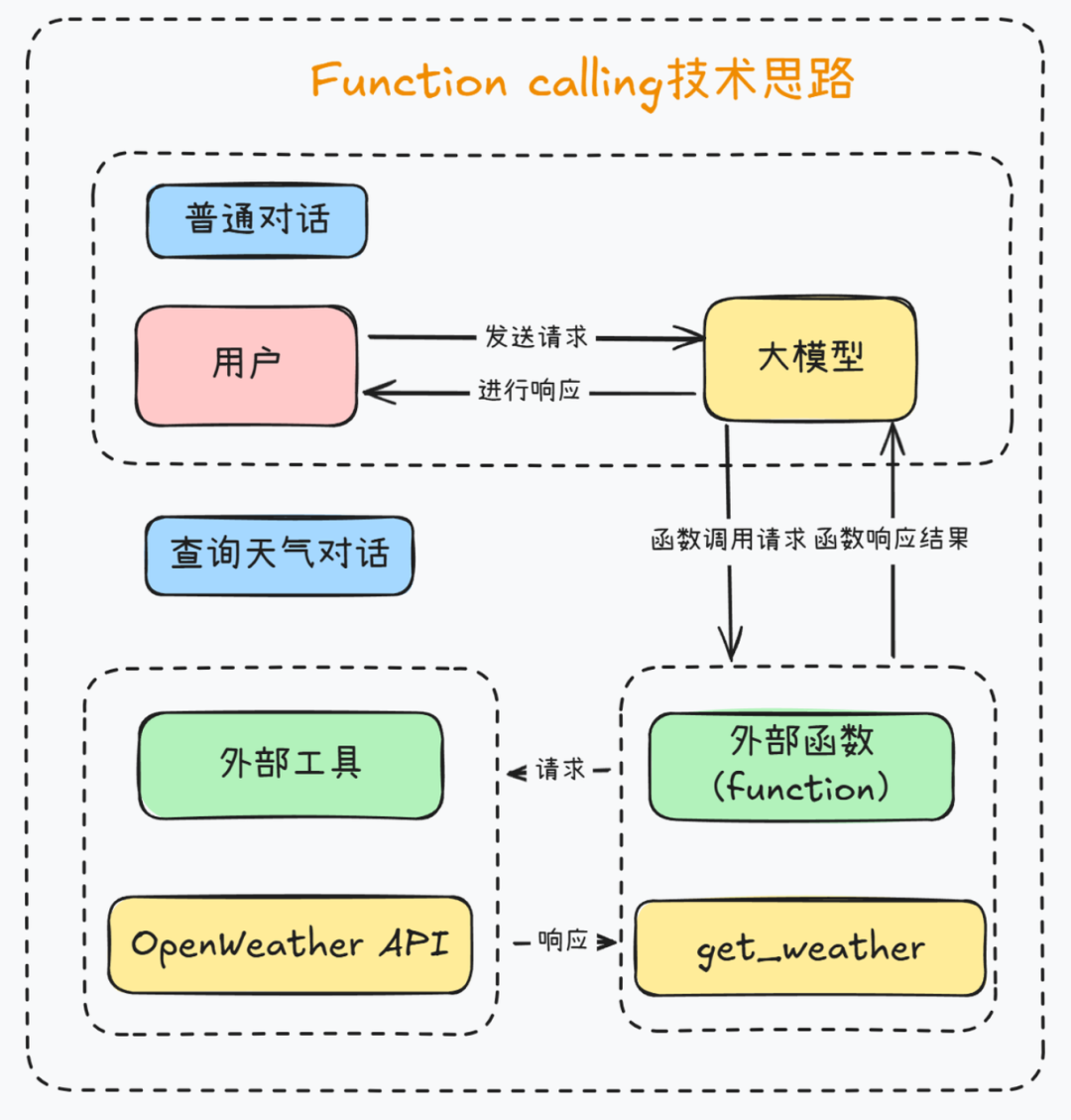
Tool 工作原理
工具的工作流程如下:
- 定义工具:指定工具的名称、描述和执行逻辑(函数或类)。
- 注册工具:将工具提供给代理或链,代理根据任务描述选择工具。
- 调用工具:代理生成工具调用的指令(包括输入参数),工具执行并返回结果。
- 处理结果:代理或链将工具输出整合到工作流中,生成最终响应。
工具的核心依赖:
- 工具描述:帮助代理理解工具的功能和适用场景。
- 输入解析:确保工具能正确处理代理提供的输入。
- 输出格式:工具返回的结果应与代理或链的期望兼容。
Tool 类继承关系
分析LangChain源码可知,在 LangChain 的类结构中,tool 的顶层基类是 Runnable,定义可执行的对象,实现了通用的执行接口。然后又通过 Serializable 提供 LangChain内部的可序列化能力,从而实现了允许工具、链、模型被保存或导出,供后续加载。最后通过 BaseTool 定义工具的统一规范 ,实现了同步 / 异步支持,参数校验等功能。
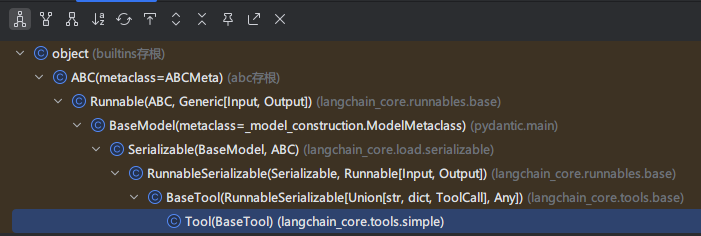
使用内置 Tool
在MCP爆火之前,LangChian生态中就已经内置集成了非常多的实用工具,开发者可以快速调用这些工具完成更加复杂工作流的开发。
LangChain内置工具列表:https://docs.langchain.com/oss/python/integrations/tools
LangChain提供了多种内置工具,大致可分为以下几类:
- 搜索工具:如Google搜索、维基百科搜索等
- 数据库工具:SQL查询、向量数据库操作等
- API工具:与外部API交互的工具
- 文件工具:读写文件、处理文档等
- 数学工具:执行数学计算的工具
- 编程工具:执行代码、Shell命令等
每种工具都专注于解决特定类型的问题,让模型能够根据需要选择最合适的工具。
下面用 LangChain官方内置 PythonREPLTool 实现基于大语言模型的代码生成和执行系统,主要功能是让模型生成Python代码并自动执行。参考文档:https://docs.langchain.com/oss/python/integrations/tools/python
代码实现如下:
from langchain_core.output_parsers import StrOutputParserfrom langchain_experimental.utilities import PythonREPLfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnableLambdafrom langchain_ollama import ChatOllamafrom loguru import loggerdef debug_print(x): """ 调试打印函数,用于在链式调用中输出中间结果 参数: x: 任意类型的输入值,将被打印并原样返回 返回值: 与输入值x相同的值 """ logger.info(f"中间结果:{x}") return x# 创建Python REPL工具实例,用于执行生成的Python代码tool = PythonREPL()# 初始化Ollama语言模型,使用qwen3:8b模型llm = ChatOllama(model="qwen3:8b", reasoning=False)# 定义聊天提示模板,包含系统指令和用户问题占位符prompt = ChatPromptTemplate.from_messages( [ ("system", "你只返回纯净的 Python 代码,不要解释。代码必须是单行或多行 print。"), ("human", "{question}") ])# 创建调试节点,用于在链式调用中插入调试信息输出debug_node = RunnableLambda(debug_print)# 创建字符串输出解析器,用于解析模型输出parser = StrOutputParser()# 构建处理链:提示模板 -> 语言模型 -> 调试输出 -> 输出解析 -> 代码执行chain = prompt | llm | debug_node | parser | RunnableLambda(lambda code: tool.run(code))# 执行链式调用,计算1到100的整数总和result = chain.invoke({"question": "计算1到100的整数总和"})logger.info(result)
执行结果如下
2025-11-21 10:18:18.141 | INFO | __main__:debug_print:19 - 中间结果:content='print(sum(range(1, 101)))' additional_kwargs={} response_metadata={'model': 'qwen3:8b', 'created_at': '2025-11-21T02:18:18.139783373Z', 'done': True, 'done_reason': 'stop', 'total_duration': 1183296308, 'load_duration': 24048613, 'prompt_eval_count': 53, 'prompt_eval_duration': 394815777, 'eval_count': 12, 'eval_duration': 761370757, 'model_name': 'qwen3:8b'} id='run--870a9cdc-3684-452b-9079-3769d5ae8ceb-0' usage_metadata={'input_tokens': 53, 'output_tokens': 12, 'total_tokens': 65}Python REPL can execute arbitrary code. Use with caution.2025-11-21 10:18:18.155 | INFO | __main__:<module>:48 - 5050
自定义Tool
Tool 工具机制的思想比较简单,他允许用户以AP接口的形式给大模型提供额外的帮助。当本地应用跟大模型聊天时,除了告诉大模型问题,同时也告诉他,本地应用能够提供哪些工具(比如查询今天的日期。这样大模型会对问题进行综合判断,当单行觉得需要使用某些工具帮助解决问题时,就会向本地应用返回一个需要调用工具的请求。然后本地应用就可以执行工具,并将工具的执行结果返回给大模型。大摸型再结合工具的执行结果,给出一个完整的答案。这样就可以让八大模型强大的知识推理能力和本地应用的私有业务能力形成良好的互动。
自定义 Tool 方式
第1种:使用@tool装饰器(自定义工具的最简单方式)
装饰器默认使用函数名称作为工具名称,但可以通过参数name_or_callable 来覆盖此设置。
同时,装饰器将使用函数的文档字符串作为工具的描述,因此函数必须提供文档字符串。
第2种:使用StructuredTool.from_function类方法
这类似于@tool 装饰器,但允许更多配置和同步/异步实现的规范。
Tool 常用属性
| 属性 | 类型 | 描述 |
|---|---|---|
| name | str | 必选,在提供给LLM或Agent的工具集中必须是唯一的。 |
| description | str | 可选但建议,描述工具的功能。LLM或Agent将使用此描述作为上下文,使用它确定工具的使用 |
| args_schema | Pydantic BaseModel | 可选但建议,可用于提供更多信息(例如,few-shot示例)或验证预期参数。 |
| return_direct | boolean | 仅对Agent相关。当为True时,在调用给定工具后,Agent将停止并将结果直接返回给用户。 |
@tool装饰器实现
定义了一个名为add_number的工具函数,用于执行两个整数相加操作。主要功能包括:
- 使用Pydantic定义参数模型FieldInfo,指定两个整数参数a和b
- 通过@tool装饰器将函数注册为LangChain工具,绑定参数schema
- 打印工具的元信息(名称、参数、描述等)
- 调用工具执行加法运算并输出结果
from langchain_core.tools import toolfrom loguru import loggerfrom pydantic import BaseModel, Fieldclass FieldInfo(BaseModel): """ 定义加法运算所需的参数信息 """ a: int = Field(description="第1个参数") b: int = Field(description="第2个参数")# 通过args_schema定义参数信息,也可以定义name、description、return_direct参数@tool(args_schema=FieldInfo)def add_number(a: int, b: int) -> int: """ 两个整数相加 """ return a + b# 打印工具的基本信息logger.info(f"name = {add_number.name}")logger.info(f"args = {add_number.args}")logger.info(f"description = {add_number.description}")logger.info(f"return_direct = {add_number.return_direct}")# 调用工具执行加法运算res = add_number.invoke({"a": 1, "b": 2})logger.info(res)
执行结果如下:
2025-11-23 21:00:48.000 | INFO | __main__:<module>:20 - name = add_number2025-11-23 21:00:48.001 | INFO | __main__:<module>:21 - args = {'a': {'description': '第1个参数', 'title': 'A', 'type': 'integer'}, 'b': {'description': '第2个参数', 'title': 'B', 'type': 'integer'}}2025-11-23 21:00:48.001 | INFO | __main__:<module>:22 - description = 两个整数相加2025-11-23 21:00:48.001 | INFO | __main__:<module>:23 - return_direct = False2025-11-23 21:00:48.010 | INFO | __main__:<module>:27 - 3
StructuredTool实现
StructuredTool.from_function 类方法提供了比@tool 装饰器更多的可配置性,而无需太多额外的代
码。
from langchain_core.tools import StructuredToolfrom loguru import loggerfrom pydantic import BaseModel, Fieldclass FieldInfo(BaseModel): """ 定义加法运算所需的参数信息 """ a: int = Field(description="第1个参数") b: int = Field(description="第2个参数")def add_number(a: int, b: int) -> int: """ 两个整数相加 """ return a + bfunc = StructuredTool.from_function( func=add_number, name="Add", description="两个整数相加", args_schema=FieldInfo)logger.info(f"name = {func.name}")logger.info(f"description = {func.description}")logger.info(f"args = {func.args}")res = func.invoke({"a": 1, "b": 2})logger.info(res)
执行结果如下
2025-11-23 21:08:43.228 | INFO | __main__:<module>:27 - name = Add2025-11-23 21:08:43.228 | INFO | __main__:<module>:28 - description = 两个整数相加2025-11-23 21:08:43.229 | INFO | __main__:<module>:29 - args = {'a': {'description': '第1个参数', 'title': 'A', 'type': 'integer'}, 'b': {'description': '第2个参数', 'title': 'B', 'type': 'integer'}}2025-11-23 21:08:43.237 | INFO | __main__:<module>:32 - 3
调用工具过程使用与分析
大模型会自动分析用户需求,判断是否需要调用指定工具。
如果模型认为需要调用工具(如 MoveFileTool ),返回的 message 会包含
- content : 通常为空(因为模型选择调用工具,而非生成自然语言回复)。
- additional_kwargs : 包含工具调用的详细信息:
如果模型认为无需调用工具(例如用户输入与工具无关),返回的 message 会是普通文本回复
from datetime import datefrom langchain_core.tools import toolfrom langchain_ollama import ChatOllamafrom loguru import logger@tooldef get_today() -> str: """ 获取当前系统日期 Returns: str: 今天的日期字符串,格式为 yyyy-MM-dd """ logger.info("执行工具:get_today") return date.today().isoformat()# 设置本地模型,不使用深度思考llm = ChatOllama(model="qwen3:14b", reasoning=False)# 将工具绑定到语言模型llm_with_tools = llm.bind_tools([get_today])# 用户提问question_list = ["你是谁?","今天是几号?"]for question in question_list: logger.info(f"用户问题:{question}") # 调用语言模型处理用户问题 ai_msg = llm_with_tools.invoke(question) logger.info(f"LLM回复:{ai_msg}") # 检查是否有工具调用 if ai_msg.tool_calls: logger.info(ai_msg.tool_calls) # 获取第一个工具调用信息 tool_call = ai_msg.tool_calls[0] # 执行对应的工具函数并获取结果 tool_result = locals()[tool_call["name"]].invoke(tool_call["args"]) logger.info(f"调用工具结果:{tool_result}") else: # 直接输出语言模型的回答 logger.info(f"LLM 直接作答:{ai_msg.content}")
项目实践:天气助手
实现了一个天气查询功能。通过调用OpenWeather API获取指定城市的实时天气数据,并将结果以自然语言形式输出。主要步骤包括构建请求、发送HTTP请求、解析JSON响应并格式化为易读的中文描述
获取 API Key
登录https://home.openweathermap.org/api_keys,免费获取API Key,并写入.env文件中,方便后续进行天气查询。
# cat .envOPENWEATHER_API_KEY="XXXX"
定义 Tool
新建 tools 文件,内容如下:
from langchain_core.tools import toolimport jsonimport osimport httpx@tooldef get_weather(loc): """ 查询即时天气函数 :param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称。 注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气, 则 loc 参数需要输入 'Beijing'。 :return: OpenWeather API 查询即时天气的结果。具体 URL 请求地址为: https://api.openweathermap.org/data/2.5/weather。 返回结果对象类型为解析之后的 JSON 格式对象,并用字符串形式进行表示, 其中包含了全部重要的天气信息。 """ # Step 1. 构建请求 URL url = "https://api.openweathermap.org/data/2.5/weather" # Step 2. 设置查询参数,包括城市名、API Key、单位和语言 params = { "q": loc, "appid": os.getenv("OPENWEATHER_API_KEY"), # 从环境变量中读取 API Key "units": "metric", # 使用摄氏度 "lang": "zh_cn"# 输出语言为简体中文 } # Step 3. 发送 GET 请求获取天气数据 response = httpx.get(url, params=params) # Step 4. 解析响应内容为 JSON 并序列化为字符串返回 data = response.json() return json.dumps(data)
大模型调用 Tool
在 main.py 中引入 tool 与天气助手 API Key,并通过大模型调用 tool。
import dotenvfrom langchain_core.output_parsers import JsonOutputKeyToolsParser, StrOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain_ollama import ChatOllamafrom loguru import loggerfrom tools import get_weather# 加载环境变量配置dotenv.load_dotenv()# 初始化大语言模型实例,使用 qwen3:14b 模型llm = ChatOllama(model="qwen3:14b", reasoning=False)# 将模型与工具绑定,使其能够调用 get_weather 工具llm_with_tools = llm.bind_tools([get_weather])# 创建解析器,用于提取工具调用结果中的 JSON 数据parser = JsonOutputKeyToolsParser(key_name=get_weather.name, first_tool_only=True)# 构建工具调用链:模型 -> 解析器 -> 调用天气工具get_weather_chain = llm_with_tools | parser | get_weather# print(get_weather_chain.invoke("你好, 请问北京的天气怎么样?"))# 定义输出提示模板,将 JSON 天气数据转换为自然语言描述output_prompt = PromptTemplate.from_template( """你将收到一段 JSON 格式的天气数据{weather_json},请用简洁自然的方式将其转述给用户。 以下是天气 JSON 数据: 请将其转换为中文天气描述,例如: “北京现在天气:多云,气温 28℃,体感有点闷热(约 32℃),湿度 75%,微风(东南风 2 米/秒),能见度很好,大约 10 公里。建议穿短袖短裤。适合做户外运动。" """)# 创建字符串输出解析器output_parser = StrOutputParser()# 构建最终输出链:提示模板 -> 模型 -> 输出解析器output_chain = output_prompt | llm | output_parser# 构建完整的处理链:天气查询链 ->将天气数据包装为字典格式 -> 输出链full_chain = get_weather_chain | (lambda x: {"weather_json": x}) | output_chain# 执行完整链路,查询上海天气并打印结果result = full_chain.invoke("请问上海今天的天气如何?")logger.info(result)
执行结果如下
2025-11-23 21:21:56.633 | INFO | __main__:<module>:44 - 上海现在天气:多云,气温 15℃,体感较舒适(约 14℃),湿度 63%,微风(西南风 2 米/秒),能见度良好,大约 8 公里。建议穿轻便衣物。适合外出活动。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献475条内容
已为社区贡献475条内容

所有评论(0)