深入解析 CANN 如何释放 Ascend 硬件潜能
在当前人工智能产业从“大模型训练”向“全场景推理”扩张的浪潮中,我们面临着一个典型的“剪刀差”:一方面是 AI 芯片(NPU)的理论峰值算力(FLOPS)不断刷新纪录,另一方面是真实业务中应用落地的实际性能往往大打折扣。阻碍算力变现的核心矛盾,往往不在于硬件本身,而在于软件栈的厚度。传统的通用计算架构(如 CPU)无法满足神经网络的大规模并行计算需求,而专用架构(DSA)虽然性能强劲,却往往因为开
摘要:在 AI 算力需求呈指数级增长的今天,硬件堆料仅是基础,软件架构才是释放性能的灵魂。CANN(Compute Architecture for Neural Networks)作为华为昇腾 AI 基础软件架构,向下屏蔽异构硬件差异,向上通过统一接口赋能全栈开发。本文将通过ACL 资源调度代码实例、PyTorch 迁移实战、自定义算子开发流程以及核心工具链解析,带你直观感受 CANN 在简化开发与性能释放上的技术魅力。
引言:打破“算力黑盒”的最后一步
在当前人工智能产业从“大模型训练”向“全场景推理”扩张的浪潮中,我们面临着一个典型的“剪刀差”:一方面是 AI 芯片(NPU)的理论峰值算力(FLOPS)不断刷新纪录,另一方面是真实业务中应用落地的实际性能往往大打折扣。
阻碍算力变现的核心矛盾,往往不在于硬件本身,而在于软件栈的厚度。传统的通用计算架构(如 CPU)无法满足神经网络的大规模并行计算需求,而专用架构(DSA)虽然性能强劲,却往往因为开发门槛高、生态封闭,变成了难以驾驭的“黑盒”。开发者常常陷入两难:要么忍受复杂的底层汇编开发,要么牺牲性能使用通用框架。
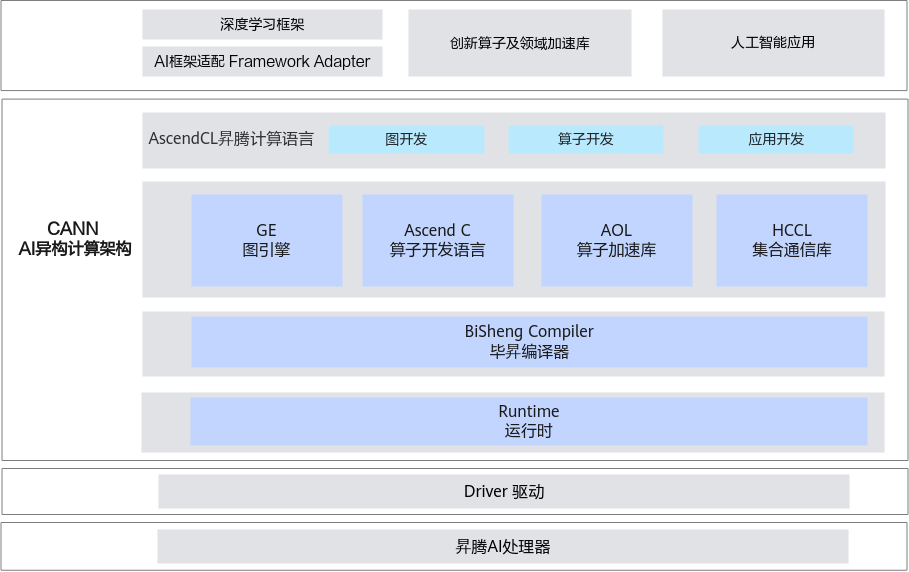
作为 Huawei 面向自研 Ascend NPU 打造的端-云一致异构计算架构,CANN(Compute Architecture for Neural Networks)的出现正是为了填平这道鸿沟。它不仅仅是一个驱动或编译器,而是一套完整的开发体系。它通过多层级的 API 设计,既为上层 AI 框架(如 PyTorch、TensorFlow、MindSpore)提供了自动化的图编译与执行能力,也为底层系统工程师开放了精细到时钟周期的硬件控制权。
本文将从应用开发、系统编程、算子构建三个实战维度,深入剖析 CANN 如何帮助开发者驾驭昇腾算力。
一、应用开发视角:一行代码背后的“无缝迁移”
对于绝大多数 AI 算法工程师而言,PyTorch 是日常工作的“母语”。如果一套新的计算架构要求开发者重写模型代码,那么它的落地阻力将是巨大的。CANN 在应用层的核心设计哲学是 “极简适配,无感加速” 。
1.1 插件化设计与动态图支持
CANN 并未试图强行改变开发者的习惯,而是通过插件化的方式(torch_npu)深度对接了 PyTorch 生态。与早期的静态图编译不同,目前的 CANN 已经支持 PyTorch 的动态图机制(Eager Mode)。这意味着开发者可以像操作原生 Tensor 一样,随时打印中间结果、调试逻辑,而底层的 NPU 设备调度对上层几乎是透明的。
案例 1:PyTorch 模型的一键迁移实战
在实际工程中,将一个在 GPU 上训练好的 ResNet 或 Transformer 模型迁移到昇腾 NPU,通常只需要修改数行代码。以下代码展示了通过 torch_npu 插件进行设备切换的完整流程。
代码对比:
import torch
import time
# 关键点:引入 CANN 的 PyTorch 适配插件
# 该插件会自动注册 NPU 后端,并重载 torch 的设备分发机制
import torch_npu
# 1. 智能设备选择:从硬编码的 'cuda' 变为动态探测 'npu'
# torch_npu.npu.is_available() 会检测当前环境是否存在昇腾处理器
device = torch.device('npu:0' if torch_npu.npu.is_available() else 'cpu')
print(f"Running on device: {device}")
# 2. 建网与数据迁移:操作与原生 PyTorch 完全一致
# 这一步触发了 Host 到 Device 的数据拷贝,CANN 底层自动处理了内存对齐
model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=True)
model = model.to(device)
model.eval()
# 创建随机输入数据
input_tensor = torch.randn(1, 3, 224, 224).to(device)
# 3. 执行推理:CANN 底层自动完成算子分发
# NPU 的计算流(Stream)会自动承载计算任务
start_time = time.time()
with torch.no_grad():
output = model(input_tensor)
# 显式同步:由于 NPU 计算是异步的,测量时间需同步流
torch.npu.synchronize()
print(f"Inference time: {time.time() - start_time:.4f}s")
print(f"Output shape: {output.shape}")
1.2 原理解析:从 Aten 到 ACLNN
当你执行 model(input_tensor) 时,CANN 在后台做了什么?
- 算子分发:PyTorch 的 Aten 算子(如
conv2d,relu)被分发机制拦截。 - 格式转换:昇腾 NPU 在处理 5D 数据(如 NC1HWC0)时有极高的效率。CANN 适配层会自动在必要时进行内存格式(Format)的转换,以匹配底层的 Cube 单元计算需求。
- 混合精度(AMP):CANN 深度支持 Automatic Mixed Precision。在 NPU 上,使用
float16进行计算不仅能减少一半的显存占用,还能利用昇腾 AI Core 针对 FP16 优化的脉动阵列,带来数倍的性能提升。
二、系统开发视角:从“黑盒”变“可控”的 ACL 接口
对于追求极致性能的推理引擎开发者(如开发 C++ 推理服务)而言,Python 层的开销是不可接受的。此时,CANN 提供了 AscendCL (Ascend Computing Language) —— 一套 C 语言风格的底层编程接口。
ACL 是打开昇腾硬件“黑盒”的钥匙。它允许开发者绕过框架的厚重包装,直接管理设备(Device)、上下文(Context)、流(Stream)和内存(Memory)。
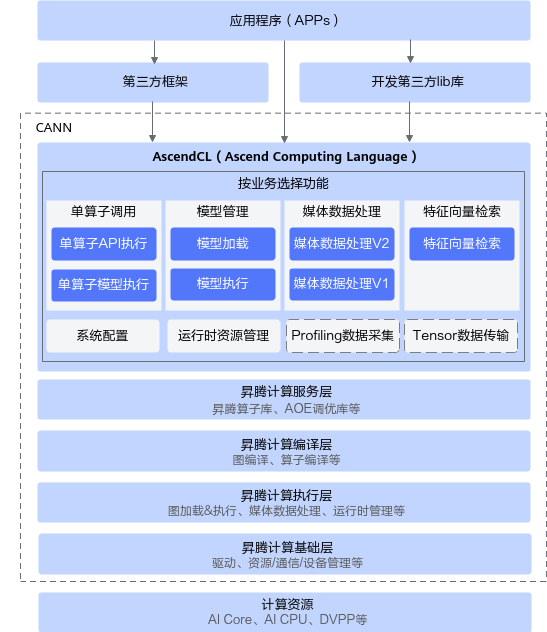
2.1 为什么需要显式管理流(Stream)?
在高性能计算中,CPU(Host)与 NPU(Device)是异构工作的。如果 CPU 发出指令后一直等待 NPU 执行完毕,那么 CPU 就会处于空闲状态,导致系统吞吐量下降。
ACL 引入了**异步流(Stream)机制。开发者可以将“数据拷贝”、“模型执行”、“后处理”等任务依次压入流中。Host 侧的 CPU 线程在压入任务后立即返回,继续处理下一批请求。这种流水线并行(Pipeline Parallelism)**技术是提升高并发服务吞吐量的核心秘诀。
案例 2:基于 ACL 的高性能异步推理 (C++ 实例)
以下代码展示了如何使用 ACL 构建一个高效的内存管理与执行流。请注意注释中关于内存池策略的解释。
实战代码解析:
#include "acl/acl.h"
#include <iostream>
void RunInferenceEngine() {
// 1. 初始化 ACL:这一步启动了 System Profiling 和 runtime 环境
const char *configPath = "./acl.json";
aclInit(configPath);
// 2. 设备申请:指定计算使用的物理 NPU ID
int32_t deviceId = 0;
aclrtSetDevice(deviceId);
// 3. 创建上下文 (Context) 与 流 (Stream)
// Context 是资源容器,Stream 是执行队列
aclrtContext context;
aclrtCreateContext(&context, deviceId);
aclrtStream stream;
aclrtCreateStream(&stream);
// 4. 极致内存管理:使用 aclrtMalloc 申请 Device 侧内存
// 关键点:ACL_MEM_MALLOC_HUGE_FIRST 策略
// 该策略优先申请大页内存(Huge Page),能显著减少 MMU 的 TLB Miss,
// 这对于频繁读写的大模型推理场景至关重要。
void *devInputPtr = nullptr;
void *devOutputPtr = nullptr;
size_t inputSize = 1024 * 1024 * 3 * 4; // 假设 float32 输入
size_t outputSize = 1000 * 4;
aclrtMalloc(&devInputPtr, inputSize, ACL_MEM_MALLOC_HUGE_FIRST);
aclrtMalloc(&devOutputPtr, outputSize, ACL_MEM_MALLOC_HUGE_FIRST);
// 5. 异步拷贝:Host -> Device
// 此时 CPU 不会阻塞,立即向下执行
aclrtMemcpyAsync(devInputPtr, inputSize, hostDataPtr, inputSize, ACL_MEMCPY_HOST_TO_DEVICE, stream);
// 6. 执行模型 (伪代码示意)
// 模型执行任务也被压入同一个 Stream,保证了执行顺序:先拷贝完,再执行
// aclmdlExecuteAsync(modelId, inputDataset, outputDataset, stream);
// 7. 异步拷贝:Device -> Host
// 将结果回传
aclrtMemcpyAsync(hostOutputPtr, outputSize, devOutputPtr, outputSize, ACL_MEMCPY_DEVICE_TO_HOST, stream);
// 8. 流同步:直到此时,CPU 才真正等待所有任务完成
// 在实际服务中,这一步通常放在回调函数中,实现全异步
aclrtSynchronizeStream(stream);
// 资源释放
aclrtFree(devInputPtr);
aclrtFree(devOutputPtr);
aclrtDestroyStream(stream);
aclrtDestroyContext(context);
aclrtResetDevice(deviceId);
aclInit(nullptr);
}
2.2 技术价值分析
上述代码实现了:
- 内存零拷贝浪费:直接在 Device 侧预申请大页内存,避免了框架层面的多次临时 Tensor 创建与销毁。
- 算力零空闲:通过多 Stream 并发,可以实现“上一帧在拷贝,当前帧在计算”的 Ping-Pong 并行模式,将 NPU 利用率从 60% 提升至 90% 以上。
三、自定义算子路径:突破标准库的限制
通用算子库(ACLNN)虽然覆盖了 95% 的场景,但在前沿算法研究(如稀疏计算、特殊的量化策略)中,开发者往往需要那剩下的 5%。CANN 提供的 TIK (Tensor Iterator Kernel) 是一种基于 Python 的动态编程语言(DSL),它允许开发者以极低的门槛编写运行在 AI Core 上的核函数。
3.1 理解昇腾 AI Core:Cube 与 Vector
要写好自定义算子,必须理解底层架构。昇腾 AI Core 主要包含两个计算单元:
- Cube Unit(矩阵运算单元):专攻矩阵乘法(MatMul),算力密度极高,适合卷积和全连接层,像一个不知疲倦的“大力士”。
- Vector Unit(向量运算单元):擅长 Element-wise 操作(如 ReLU、Add、LayerNorm),灵活性高,像一个灵巧的“工匠”。
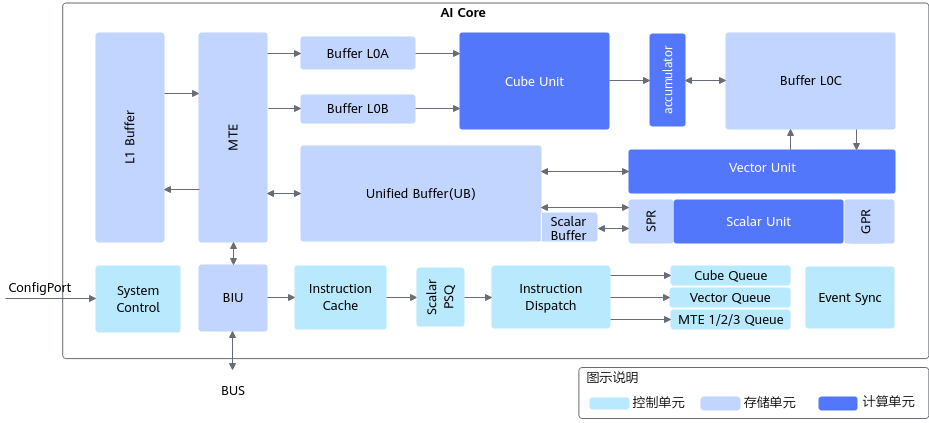
自定义算子的核心,就是精细地控制数据在 Global Memory(显存)、Unified Buffer(片内统一缓存) 以及计算单元之间的搬运与计算。
案例 3:使用 TIK 编写高性能向量加法
以下示例展示了如何通过 TIK 显式控制数据搬运流水线,实现一个在 Vector Unit 上运行的加法算子。
from tbe import tik
def custom_vector_add_tik():
# 1. 初始化 TIK 容器,构建计算图
tik_instance = tik.Tik()
# 2. 定义数据占位符
# scope_gm 代表 Global Memory,即 NPU 的高带宽内存(HBM)
data_num = 128
input_x = tik_instance.Tensor("float16", (data_num,), name="input_x", scope=tik.scope_gm)
input_y = tik_instance.Tensor("float16", (data_num,), name="input_y", scope=tik.scope_gm)
output_z = tik_instance.Tensor("float16", (data_num,), name="output_z", scope=tik.scope_gm)
# 3. 定义片内缓存 Tensor
# scope_ubuf 代表 Unified Buffer,这是 AI Core 内部的高速缓存
# 数据必须先搬运到 UB 才能被 Vector Unit 计算
input_x_ub = tik_instance.Tensor("float16", (data_num,), name="input_x_ub", scope=tik.scope_ubuf)
input_y_ub = tik_instance.Tensor("float16", (data_num,), name="input_y_ub", scope=tik.scope_ubuf)
# 4. 数据搬运:HBM -> UB
# data_move 是 DMA 搬运指令,不消耗计算资源
tik_instance.data_move(input_x_ub, input_x, 0, 1, 8, 0, 0)
tik_instance.data_move(input_y_ub, input_y, 0, 1, 8, 0, 0)
# 5. 核心计算:Vector Add
# mask=128 表示一次性处理 128 个 fp16 数据
# 这是一个 SIMD(单指令多数据)操作,效率极高
tik_instance.vec_add(128, input_x_ub, input_x_ub, input_y_ub, 1, 8, 8, 8)
# 6. 数据回写:UB -> HBM
tik_instance.data_move(output_z, input_x_ub, 0, 1, 8, 0, 0)
# 7. 编译生成 .o 二进制文件或 .json 算子描述
tik_instance.BuildCCE(kernel_name="simple_vector_add", inputs=[input_x, input_y], outputs=[output_z])
return tik_instance
这一流程看似比 PyTorch 复杂,但它赋予了开发者上帝视角。对于大语言模型中的 FlashAttention 等复杂算子,通过 TIK 手动进行切块(Tiling)和流水线优化,往往能获得比通用实现快数倍的性能。
四、关键一环:ATC 模型转换与 Profiling
除了上述开发接口,CANN 还提供了一系列“幕后英雄”工具,确保代码能高效运行。
- ATC (Ascend Tensor Compiler): 在模型从训练框架走向推理之前,ATC 扮演了“翻译官”的角色。它将开源框架的网络模型(如 ONNX, Protobuf)转换为昇腾专用的离线模型(.om)。在此过程中,ATC 会自动进行算子融合(比如将 Conv+Bn+Relu 融合为一个大算子)、死代码消除、内存复用优化。这使得最终执行的模型比原始模型更加精简高效。
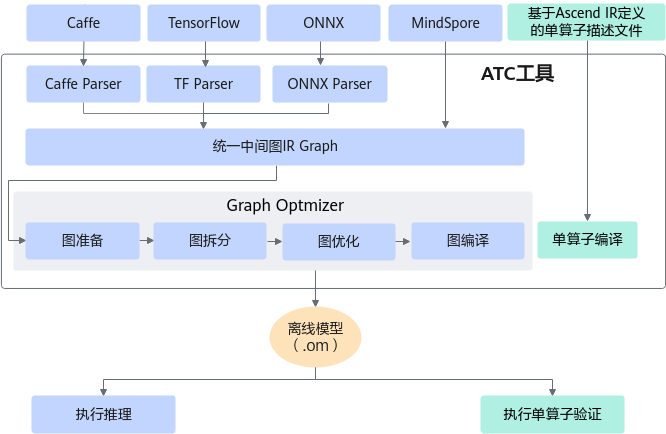
- Profiling 性能分析: “性能优化不能靠猜”。CANN 提供了系统级的 Profiling 工具(MSProf)。它能以纳秒级的精度记录每一个算子在 NPU 上的执行时间、Memory 读写带宽占用、Cube/Vector 单元的利用率。通过生成的 Timeline 热力图,开发者可以一眼看出系统瓶颈——是数据拷贝阻塞了计算,还是某个算子实现太慢,从而进行针对性优化。
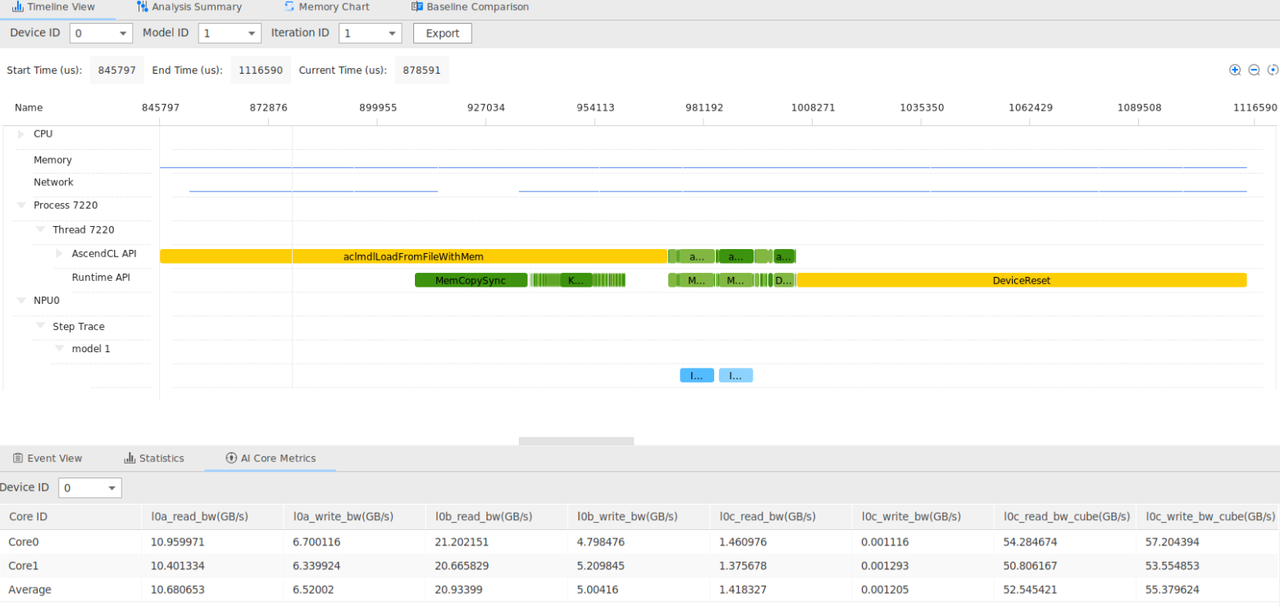
总结:CANN —— 算力的加速引擎
通过对应用迁移、系统调度、自定义算子及工具链的深入剖析,我们可以清晰地看到 CANN 的技术图谱:
- 对于应用开发者,它提供了
torch_npu这样的温床,让算力触手可及; - 对于系统工程师,它开放了
ACL这样的利刃,让硬件性能被压榨到极致; - 对于算法专家,它通过
TIK赋予了自由,让算法创新不再受限于硬件指令集。
CANN 不仅是一套工具链,更是一条从模型设计到硬件执行的工程化落地通道。在AI 基础设施日益成熟的今天,掌握 CANN 开发技术,不仅是提升个人技术栈宽度的选择,更是深度参与 AI 产业变革的关键一步。希望广大开发者亲自体验 CANN,通过代码感受 CANN 的硬核实力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)