从GAN到Sora:生成式AI在图像与视频领域的技术演进全景
生成式人工智能(AIGC)正在重塑我们对“内容创作”的认知,而图像与视频生成技术的演进,堪称这场革命的核心战场。今天,我们就通过一张时间线图,带你穿越生成式AI在图像、视频领域的技术长河,从早期实验到Sora的里程碑突破,看懂每一步迭代的价值与意义。
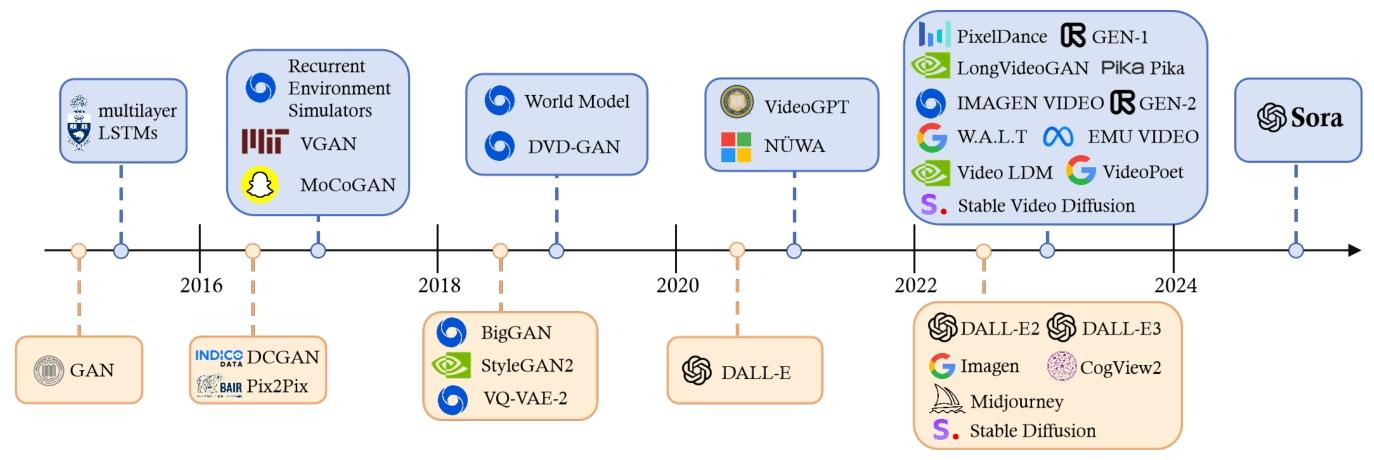
生成式人工智能(AIGC)正在重塑我们对“内容创作”的认知,而图像与视频生成技术的演进,堪称这场革命的核心战场。今天,我们就通过一张时间线图,带你穿越生成式AI在图像、视频领域的技术长河,从早期实验到Sora的里程碑突破,看懂每一步迭代的价值与意义。
一、技术黎明:生成式AI的“创世基石”(2016年前)
生成式AI的故事,要从两个关键起点讲起:
-
序列建模的萌芽:multilayer LSTMs
多层长短期记忆网络(LSTMs)是早期处理时序数据的核心工具。它能捕捉“序列依赖关系”,为后续视频这类时序性强的内容生成埋下了伏笔——毕竟视频本质是“图像的时序序列”。 -
生成对抗的革命:GAN
生成对抗网络(GAN)的诞生,是生成式AI的“破局点”。它通过“生成器(造内容)”和“判别器(辨真假)”的对抗训练,让AI能生成以假乱真的图像。从此,“生成逼真内容”有了系统性框架。
二、分野与深耕:图像与视频的技术探索(2016-2020)
从2016年开始,生成式AI开始分化出**“图像生成”和“视频生成”两条技术支线**,各自在探索中突破:
(1)图像生成:从“能不能做”到“做得精美”
-
2016年:DCGAN与Pix2Pix的“从无到有”
- DCGAN(深度卷积GAN):把卷积神经网络(CNN)引入GAN,解决了传统GAN训练不稳定、生成图像模糊的问题,让“生成清晰图像”成为可能。
- Pix2Pix:属于“条件GAN”的经典应用,实现“图像到图像”的转换(比如把建筑线稿变成写实照片),证明了GAN在“风格化创作”上的潜力。
-
2018年:BigGAN、StyleGAN2的“精益求精”
- BigGAN:主打“大规模高分辨率”,能生成亿级参数规模的高清图像,把生成质量推到新高度。
- StyleGAN2:专注“风格可控性”,可以精准控制图像细节(比如人脸的发型、妆容),成为“AI换脸”“虚拟偶像生成”的技术底座。
- VQ-VAE-2:走了“矢量量化”的路子,把图像编码成离散的“语义块”,既提升了生成效率,又能让AI学习到更结构化的图像知识。
(2)视频生成:从“动态模拟”到“时序理解”
视频生成的难点在于**“时序连贯性”和“动态合理性”**,早期模型都在攻克这两个痛点:
-
2016年:Recurrent Environment Simulators、VGAN、MoCoGAN
这些模型尝试用“循环结构”(比如类LSTM的递归网络)捕捉视频的时序信息,试图模拟“动态环境”(比如物体的运动轨迹、场景的变化逻辑)。 -
2018年:World Model、DVD-GAN
- “World Model”主打“世界建模”,让AI先学习现实世界的物理规律、场景逻辑,再生成符合常识的动态视频。
- “DVD-GAN”则聚焦“动态细节还原”,优化视频帧之间的过渡自然度,减少“画面抖动、细节丢失”的问题。
三、爆发与颠覆:从“单点生成”到“多模态宇宙”(2020-2024)
2020年后,生成式AI进入**“大模型驱动”的爆发期**,图像和视频生成都迎来了“质的飞跃”。
(1)图像生成:“文本驱动”的创意革命
-
2020年:DALL-E的“破冰者”
OpenAI的DALL-E首次实现“文本→图像”的规模化生成,用Transformer架构替代了传统GAN的框架,证明“大模型+多模态”能解锁更自由的创意空间(比如生成“会飞的热狗”这种脑洞画面)。 -
2022年至今:DALL-E 2/E3、Imagen、Midjourney、Stable Diffusion的“百家争鸣”
- DALL-E 2/E3:在“图像质量、生成速度、细节丰富度”上持续迭代,支持“图像局部编辑”“风格迁移”等精细化操作。
- Imagen(谷歌):主打“文本对齐度”,能更精准地把文字描述转化为图像(比如“一只穿着西装的猫在太空舱里喝咖啡”,细节还原度极高)。
- Midjourney:以“艺术化生成”出圈,生成的图像充满油画、赛博朋克等风格化质感,成为设计师、艺术家的创意工具。
- Stable Diffusion:凭借“开源生态”大火,开发者可以基于它训练自定义模型(比如专属的动漫风格、历史人物风格),让生成式AI的应用门槛大幅降低。
(2)视频生成:从“短片段”到“长叙事”的跨越
视频生成的技术路径在这一阶段也迎来了密集突破:
-
2020年左右:VideoGPT、NUWA(微软)
这些模型尝试把“GPT式的自回归逻辑”引入视频生成,让AI像写文字一样“逐帧生成视频”,探索“长时序视频”的建模可能。 -
2022年至今:GEN-1/GEN-2、Stable Video Diffusion、VideoPoet、Sora的“技术狂飙”
- GEN-1/GEN-2(Runway):GEN-1实现“图像→视频”的风格化生成(比如把静态画变成动态动画);GEN-2更进一步,支持“文本→视频”的直接生成,还能模仿现实镜头语言(如运镜、剪辑)。
- Stable Video Diffusion:是Stable Diffusion在视频领域的延伸,能基于文本或图像生成短时长、高连贯的视频片段。
- VideoPoet(谷歌):主打“多模态指令”,支持“文本+音乐+图像”驱动的视频生成,探索“多感官协同创作”。
- Sora(OpenAI,2024年):堪称视频生成的“里程碑”,能基于文本生成分钟级、高保真、逻辑连贯的长视频(比如“一群企鹅在纽约时代广场跳踢踏舞”),标志着AI在“动态叙事、物理一致性、场景复杂度”上的全面突破。
四、未来展望:生成式AI的“下一站”
从这张时间线图可以清晰看到,生成式AI在图像、视频领域的演进逻辑是**“从工具化到智能化,从单点生成到多模态叙事”**。未来的趋势可能集中在:
- 更自然的“多模态交互”:文本、图像、音频、视频的边界进一步模糊,AI能理解“跨模态指令”(比如“根据这段音乐生成对应的科幻短片”)。
- 更高效的“长内容生成”:像Sora这样的长视频模型会持续优化,支持“电影级叙事”“虚拟世界构建”等复杂需求。
- 更普惠的“个性化创作”:开源生态和低代码工具会让普通人也能定制专属的生成模型,实现“千人千面”的创意表达。
这场由GAN开启、由大模型推动的生成式AI革命,还在持续改写“内容创作”的定义。从静态图像到动态视频,从工具辅助到创意主导,我们正见证一个“AI赋能全民创作”的新时代加速到来。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)