多模型集成新答案:GMI Cloud・百模兼容
经过两周的深度实测,GMI Cloud 的综合表现十分出色,核心优势集中在“提升开发效率”与“降低使用门槛”两大维度。以往接入新 AI 模型,需经历注册平台、研读文档、编写适配代码等一系列繁琐流程,耗时费力;而在 GMI Cloud 上,只需一个账号、一套密钥,即可调用平台所有模型,基础代码一次编写即可复用,切换模型仅需修改名称参数,大幅减少重复工作量。平台聚合了 36 款文本模型与 31 款视频
目录
在线模型使用教程
生成 API 密钥(Keys)
首先完成步骤1的操作,随后在步骤2中找到并点击“API Keys”选项。
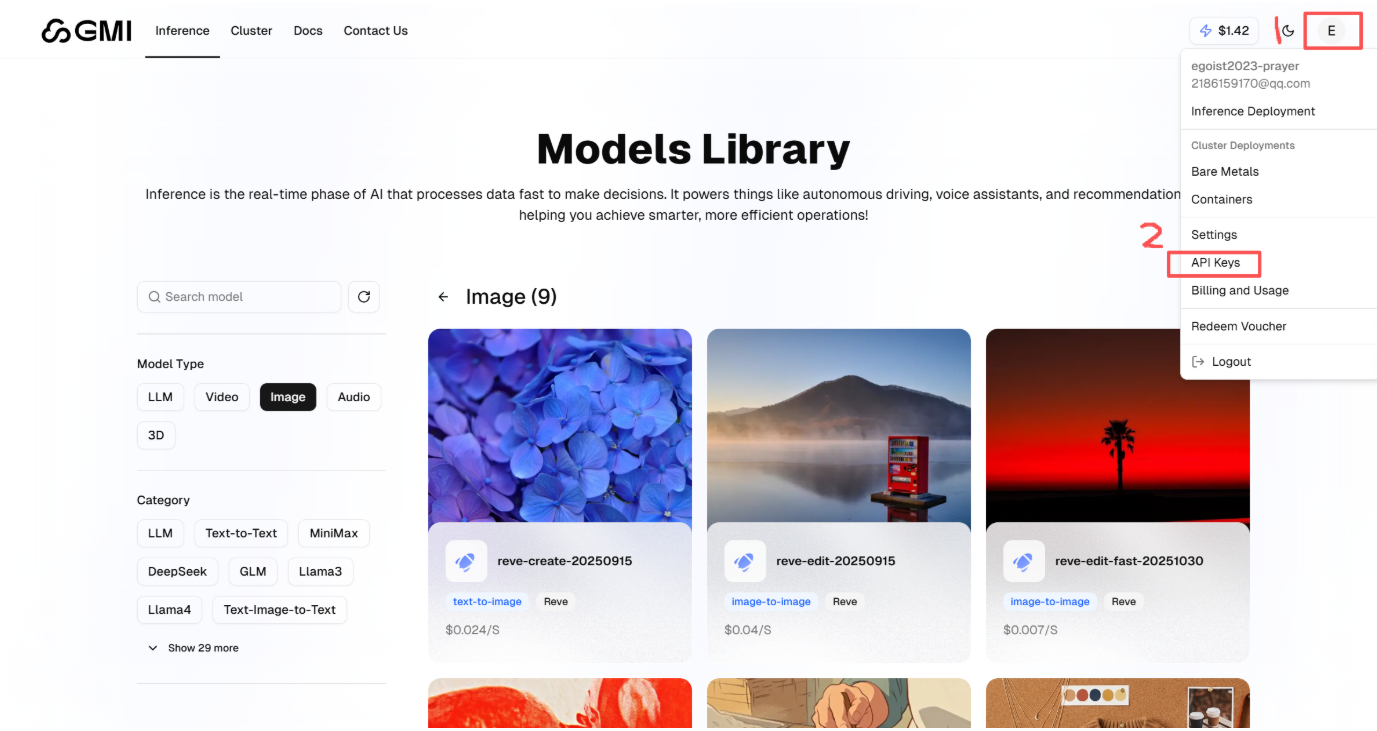
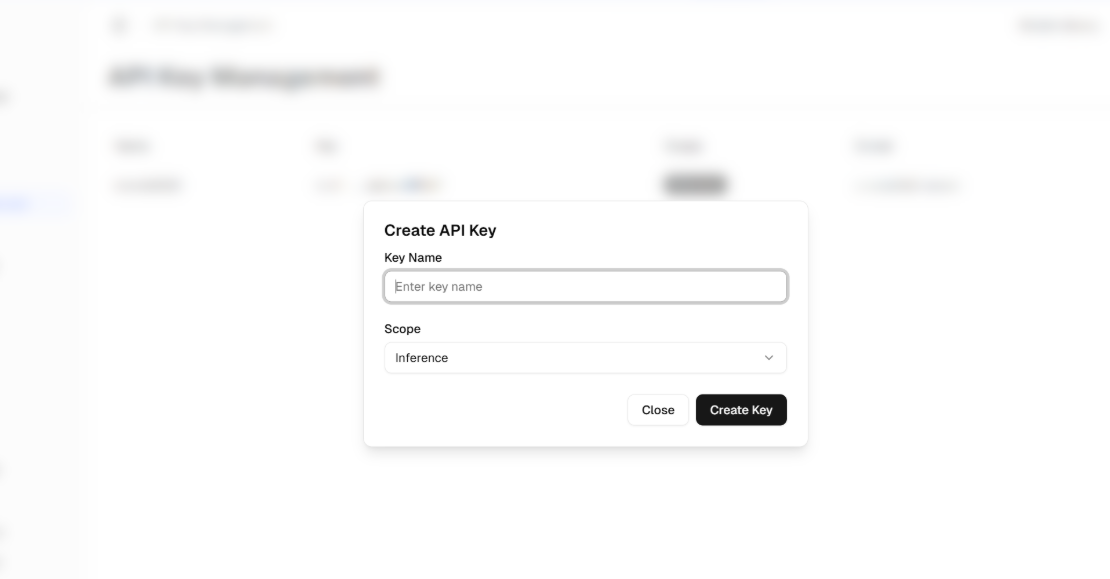
进入页面后,点击「Create New API Key」按钮创建密钥:先为密钥设置一个易识别的名称,再根据实际需求配置权限范围——例如仅开放文本模型调用权限,或设置为禁止写入的只读模式。特别提醒,该密钥仅在创建时显示一次,生成后请立即复制并妥善保存,避免后续无法找回。
大语言模型测试
平台支持多种模型测试,此处以 Kimi-K2-Thinking 为例演示操作流程:
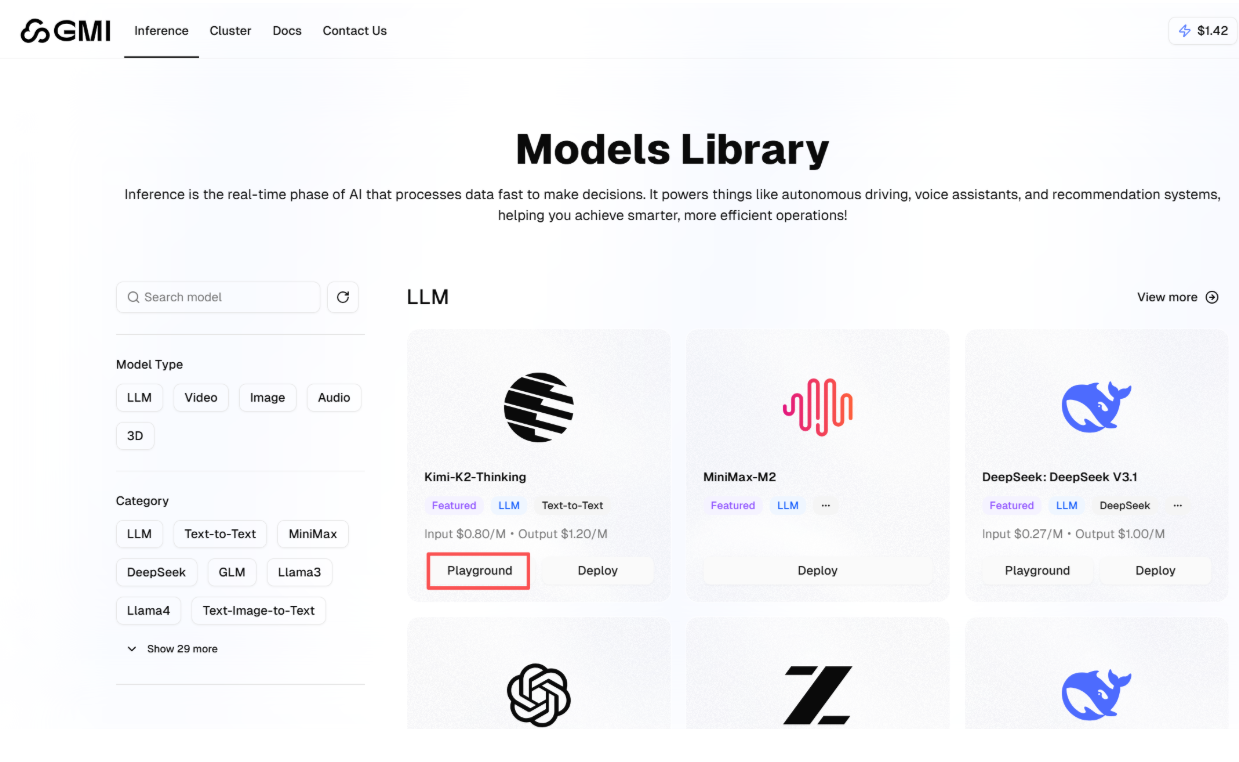
找到 Kimi-K2-Thinking 模型,点击其对应的“Playground”标签;
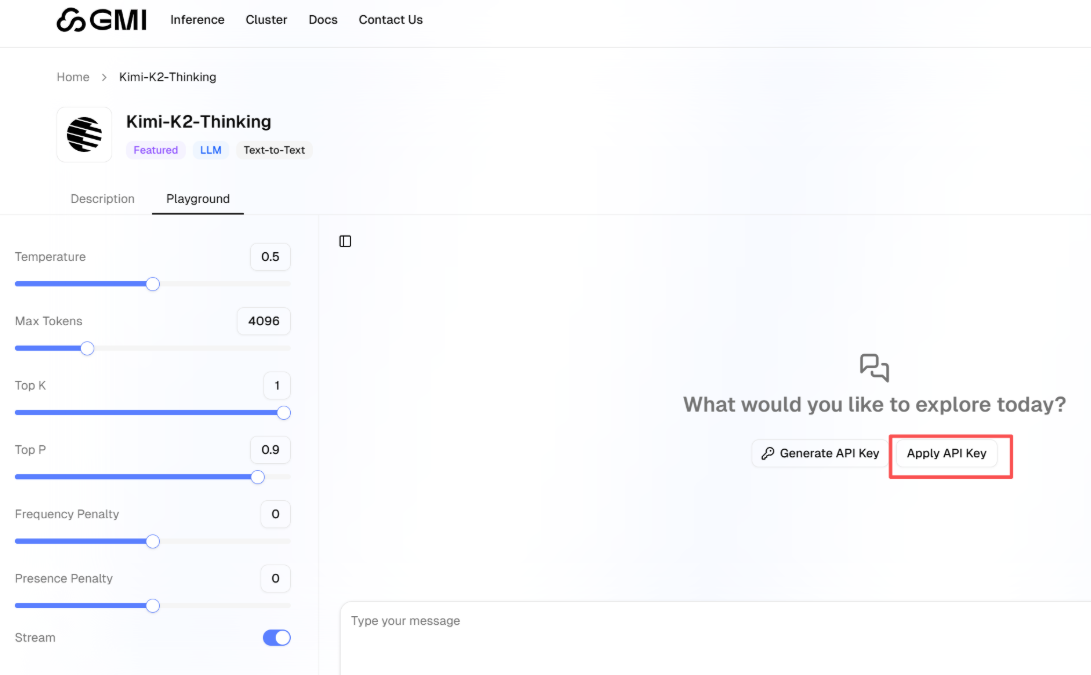
点击“Apply API Key”按钮,将之前保存的 API 密钥输入其中,完成配置后即可使用该模型。
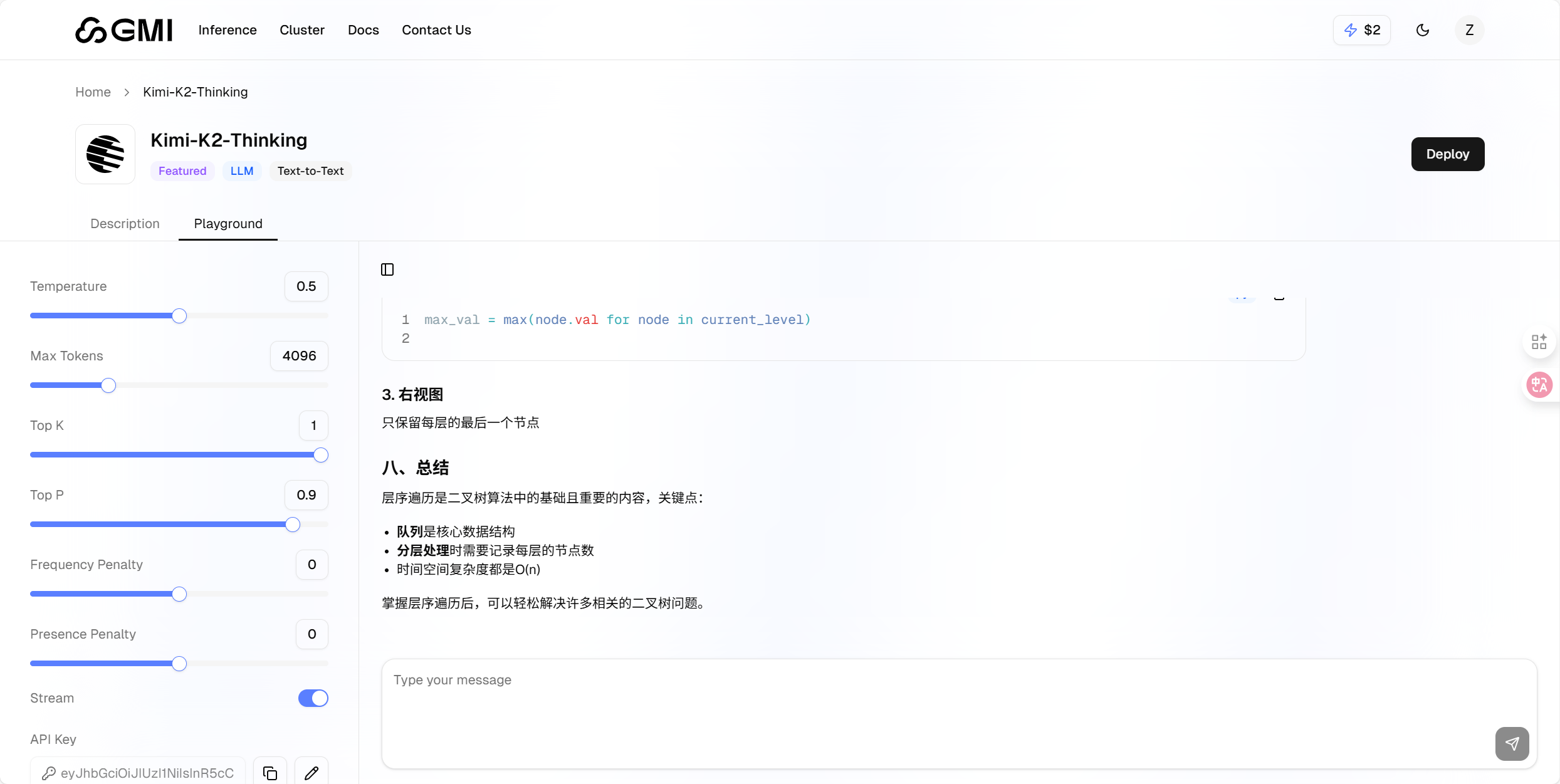
实测发现,平台返回结果的精准度较高,左侧还配备了多个实用可调参数:通过调节“温度值”可控制回复的随机性,自定义“最大令牌数”则能限制输出长度,可灵活适配不同场景的使用需求。
AI 视频生成
在平台菜单中选择“Video”分类,此处以 Minimax-Hailuo-2.3 模型为例说明生成流程:
-
点击进入该模型页面,可上传一张图片作为视频首帧或风格参考;
-
通过“Duration”和“Resolution”选项自主设置视频时长与分辨率;
-
输入视频生成提示词,示例提示词为:“让图片动起来”;
-
完成参数设置后,点击“Generate”按钮,等待视频生成即可。
原图:

生成的动态视频效果:

感兴趣的用户可自行实操体验。
API 模型一键调用与本地部署
基础调用方法(以 Python 为例)
以此前测试过的 Kimi-K2-Thinking 模型为例,调用步骤如下:启动模型后,点击「Description」选项,页面将呈现详细的调用指引。
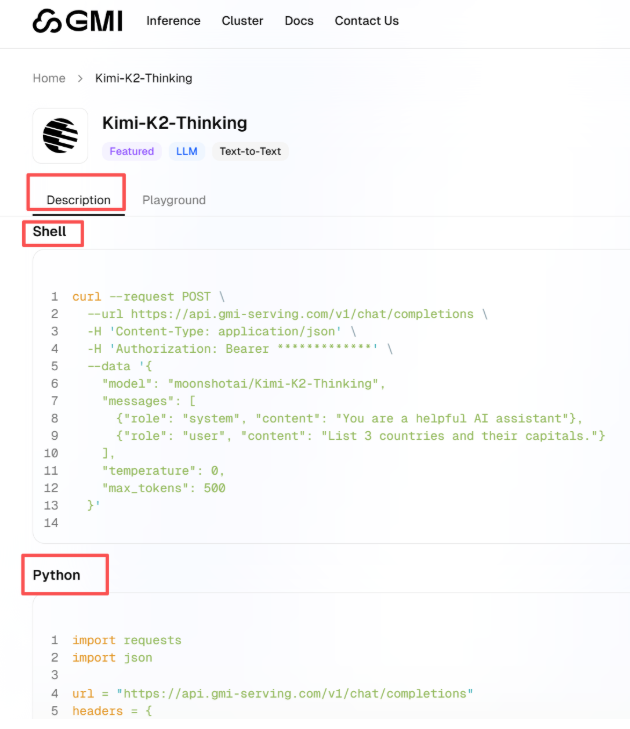
直接复制页面中的 Python 代码块
import requests
import json
url = "https://api.gmi-serving.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer *************"
}
payload = {
"model": "moonshotai/Kimi-K2-Thinking",
"messages": [
{"role": "system", "content": "You are a helpful AI assistant"},
{"role": "user", "content": "List 3 countries and their capitals."}
],
"temperature": 0,
"max_tokens": 500
}
response = requests.post(url, headers=headers, json=payload)
print(json.dumps(response.json(), indent=2))将代码中 “Bearer *************” 部分替换为自己的 API 密钥,点击运行即可完成调用。调用成功后,系统会返回结构化 JSON 输出,该格式兼容性强,可被 Python、Java、JavaScript 等多种编程语言及不同系统便捷解析。
LLM 模型本地部署优化
为提升代码的灵活性与可维护性,针对基础调用代码做了两处核心优化:一是将提问内容从 messages 中抽离,单独定义为 user_question 变量,后续更换问题仅需修改该变量,无需调整整体代码框架;二是优化输出格式,从响应数据中提取 AI 核心回复,按“问题+回答”的对应形式清晰打印,解决了原始代码输出杂乱的问题。优化后的代码如下:
import requests
import json
url = "https://api.gmi-serving.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer ........"
}
# 提问内容
user_question = "讲述二叉树的实现"
payload = {
"model": "moonshotai/Kimi-K2-Thinking",
"messages": [
{"role": "system", "content": "You are a helpful AI assistant"},
{"role": "user", "content": user_question} # 引用提问内容
],
"temperature": 0,
"max_tokens": 500
}
response = requests.post(url, headers=headers, json=payload)
response_data = response.json()
# 提取 AI 的回答
ai_answer = response_data['choices'][0]['message']['content']
# 同时打印问题和回答
print(f"你的问题:{user_question}")
print("\nAI 的回答:")
print(ai_answer)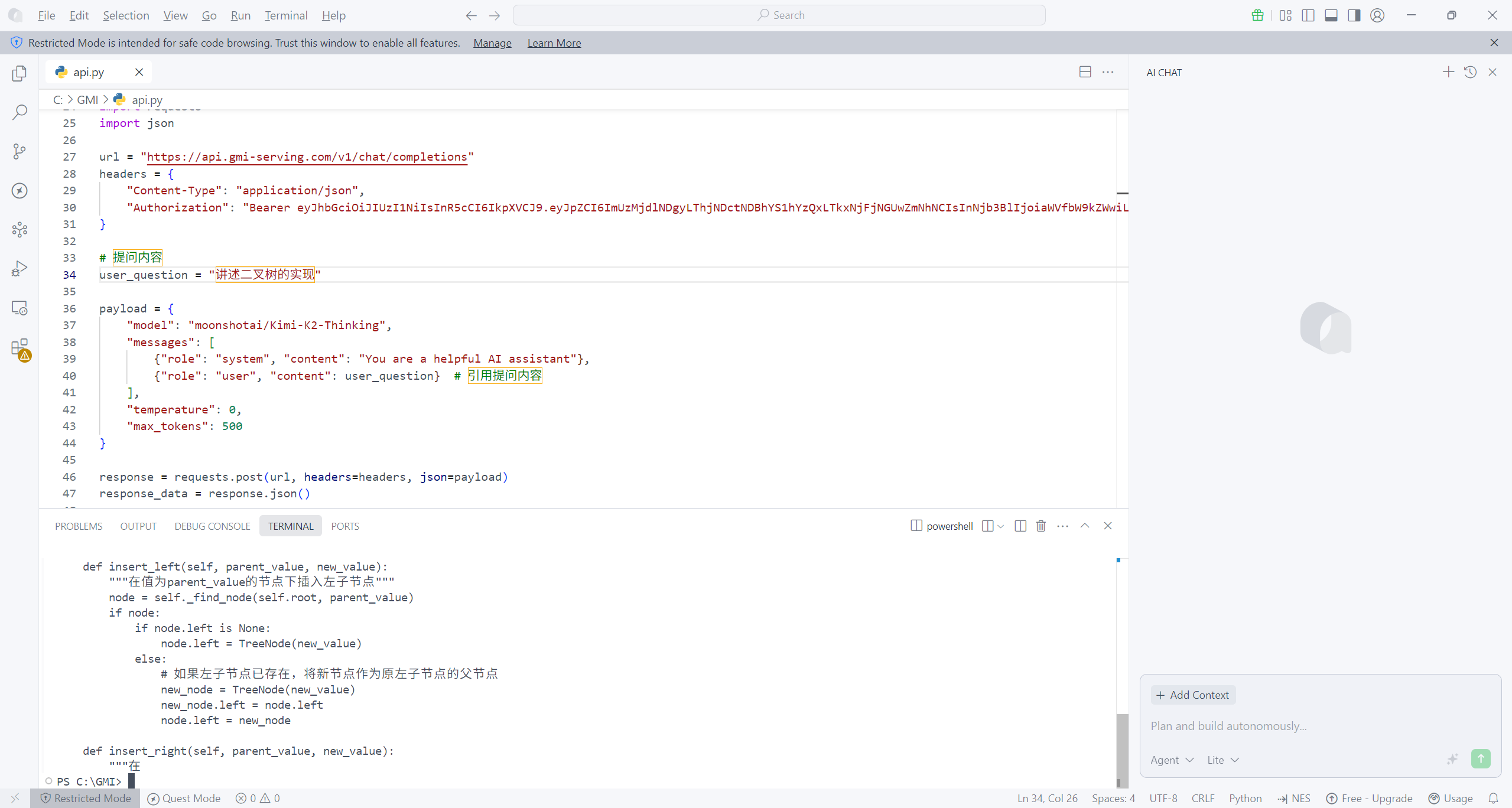
各模型的具体调用指南均可在对应模型详情页查询,大家可根据实际需求选择调用。接下来,就为大家演示视频模型的详细调用流程。
视频模型本地部署
借鉴 LLM 模型的封装思路,对视频生成 API 调用逻辑进行标准化封装,提升代码复用性与可维护性。以下以 Minimax-Hailuo-2.3-Fast 模型为例
import requests
import json
import os
API_KEY = os.getenv("GMI_API_KEY", "........") # 写下自己的 API Keys 秘钥
# 视频生成 API 的基础 URL 和 Endpoint
BASE_URL = "https://console.gmicloud.ai"
ENDPOINT = "/api/v1/ie/requestqueue/apikey/requests"
FULL_URL = f"{BASE_URL}{ENDPOINT}"
HEADERS = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
VIDEO_MODEL_NAME = "Minimax-Hailuo-2.3-Fast"
PROMPT = "A serene ocean scene with waves under a pink sunset"
DURATION = 6 # 视频时长(秒)
RESOLUTION = "768P" # 分辨率,可选值如 "768P", "1080P" 等
PROMPT_OPTIMIZER = True # 是否开启提示词优化
FAST_PRETRATMENT = False # 是否开启快速预处理
# 使用一个公共可用的图像URL作为测试
FIRST_FRAME_IMAGE = "https://picsum.photos/768/432" # 一个随机的768x432图像(符合768P分辨率)
payload = {
"model": VIDEO_MODEL_NAME,
"payload": {
"prompt": PROMPT,
"duration": DURATION,
"resolution": RESOLUTION,
"prompt_optimizer": PROMPT_OPTIMIZER,
"fast_pretreatment": FAST_PRETRATMENT,
"first_frame_image": FIRST_FRAME_IMAGE
}
}
def main():
print(f"--- 开始调用视频模型: {VIDEO_MODEL_NAME} ---")
print(f"提示词: {PROMPT}")
print(f"API Key: {API_KEY[:10]}...") # 显示API密钥的前10个字符用于验证
print(f"Headers: {HEADERS}")
print(f"Payload: {json.dumps(payload, indent=2, ensure_ascii=False)}")
try:
# 发送 POST 请求
response = requests.post(FULL_URL, headers=HEADERS, json=payload)
# 检查响应状态码
response.raise_for_status()
# 解析 JSON 响应
response_data = response.json()
print("\n请求成功!")
print("完整响应:")
print(json.dumps(response_data, indent=2, ensure_ascii=False))
if "data" in response_data and "task_id" in response_data["data"]:
task_id = response_data["data"]["task_id"]
print(f"\n任务 ID: {task_id}")
print("请保存此 Task ID,用于后续查询视频生成状态。")
except requests.exceptions.RequestException as e:
print(f"\n调用 API 时发生错误: {e}")
if hasattr(e, 'response') and e.response is not None:
print("错误响应状态码:", e.response.status_code)
print("错误响应头:", e.response.headers)
print("错误响应内容:")
print(e.response.text)
else:
print("没有收到响应,请检查网络连接或API端点是否正确。")
if __name__ == "__main__":
if API_KEY == "你的API" and not os.getenv("GMI_API_KEY"):
print("警告: 请设置 GMI_API_KEY 环境变量或在代码中替换 '你的API密钥'。")
main()提供可直接落地的结构化封装代码,示例提示词为 “A serene ocean scene with waves under a pink sunset”
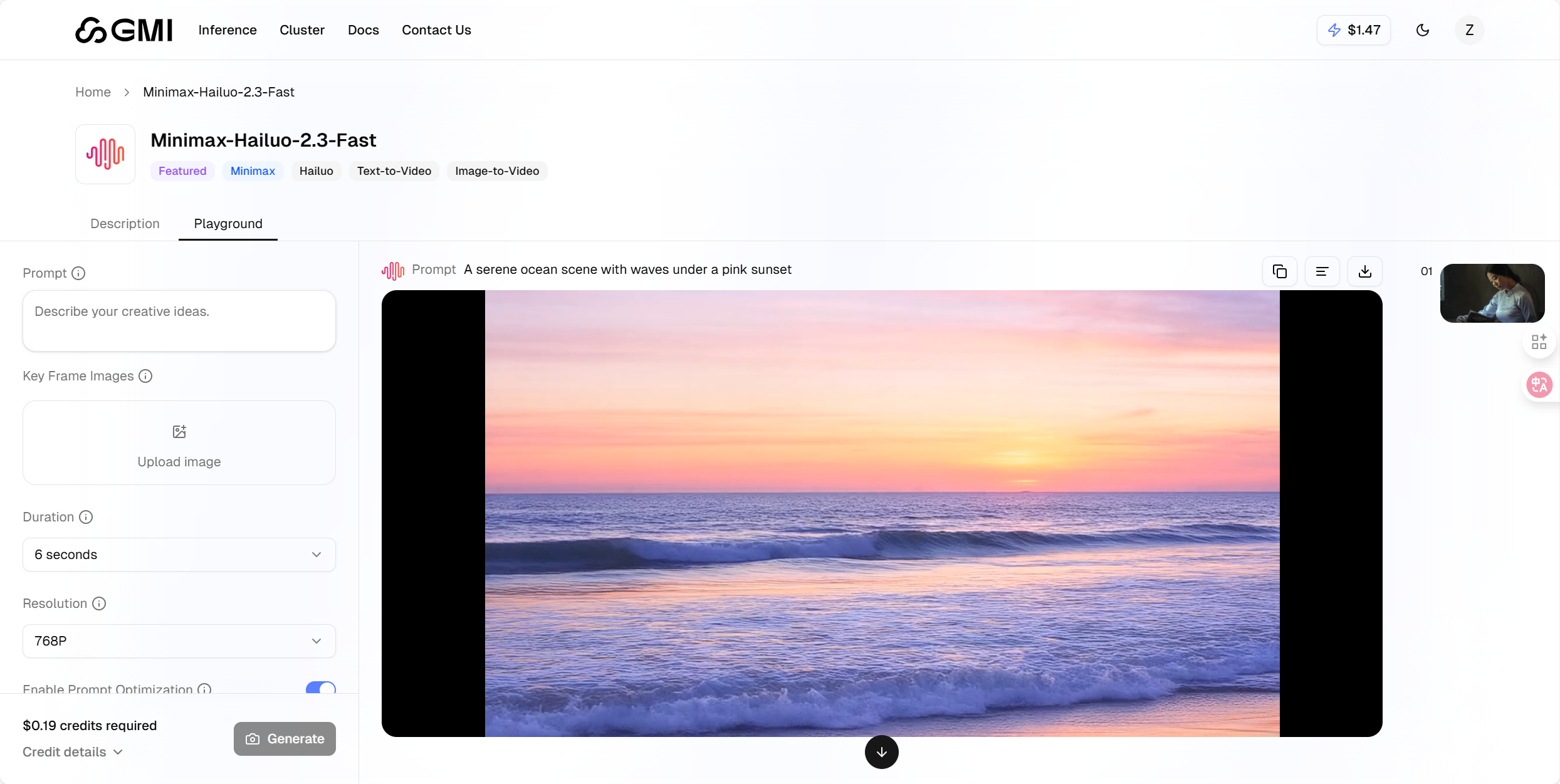
前端查看生成的视频时,可直观感受到其逼真的画面效果。
实测总结:高效便捷的 AI 模型聚合平台
经过两周的深度实测,GMI Cloud 的综合表现十分出色,核心优势集中在“提升开发效率”与“降低使用门槛”两大维度。以往接入新 AI 模型,需经历注册平台、研读文档、编写适配代码等一系列繁琐流程,耗时费力;而在 GMI Cloud 上,只需一个账号、一套密钥,即可调用平台所有模型,基础代码一次编写即可复用,切换模型仅需修改名称参数,大幅减少重复工作量。
平台聚合了 36 款文本模型与 31 款视频模型,全面覆盖各类主流使用场景;更值得称赞的是,新模型上线响应迅速,往往在官方发布后不久就能在平台上体验,助力用户紧跟 AI 技术前沿。计费方式采用按 Token 精准计费,每一次调用的消耗明细都清晰可查,虽不同模型价格有差异,但整体处于合理区间,成本可控性极强,非常推荐有相关需求的用户亲自体验。
-
统一操作体系,简化开发全流程:以“单账号+单密钥”实现全模型统一管理,彻底告别为不同模型重复注册、查阅文档、编写适配代码的麻烦。基础代码一次编写即可长期复用,模型切换仅需调整名称参数,显著降低开发与维护成本。
-
模型资源完备,前沿能力同步快:36 款文本模型与 31 款视频模型的丰富储备,可满足各类主流使用需求;新模型上线速度快,确保用户能第一时间接入前沿 AI 能力,无需为适配新模型等待漫长周期。
-
计费透明精准,成本管理高效:按 Token 精准计费,调用消耗明细一目了然,用户可清晰掌握成本支出;各模型价格虽有差异,但整体处于合理范围,便于企业与个人做好成本控制。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)