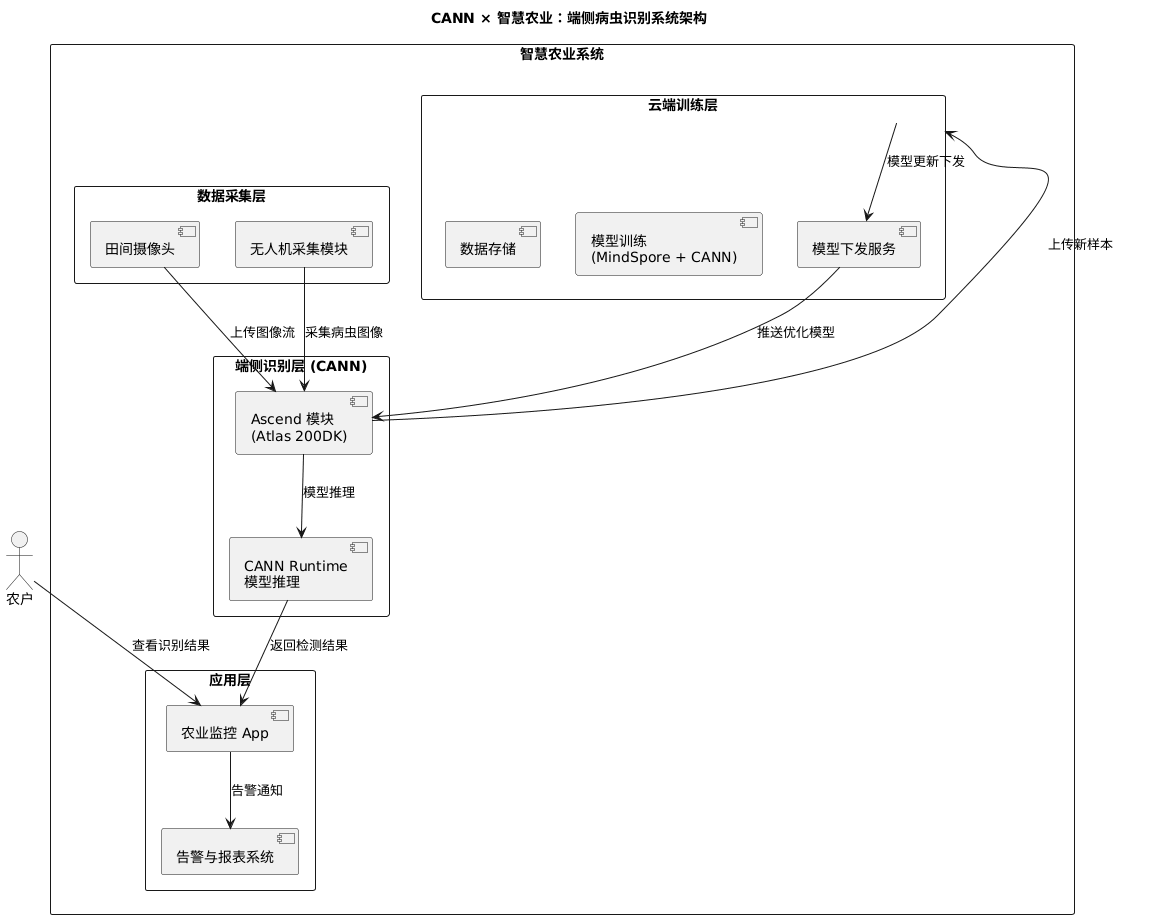
CANN × 智慧农业:端侧病虫识别系统设想
人工智能正在从云端走向边缘,重塑传统农业的面貌。然而,“云端太远,田间太近”,在真实的农业场景中,网络不稳与算力受限成为了 AI 落地的最大阻碍。如何在无网、低功耗的边缘端设备上,实现高精度、实时的病虫害识别?本文将以。
摘要:人工智能正在从云端走向边缘,重塑传统农业的面貌。然而,“云端太远,田间太近”,在真实的农业场景中,网络不稳与算力受限成为了 AI 落地的最大阻碍。如何在无网、低功耗的边缘端设备上,实现高精度、实时的病虫害识别?本文将以 OrangePi AI Pro 开发板为例,深度剖析如何利用华为 CANN(Compute Architecture for Neural Networks)异构计算架构,将 EfficientNet 模型高效部署到田间地头。从底层 NPU 的资源隔离与绑核设置,到 PyTorch 模型的无缝迁移训练,再到 ATC 编译器的图级优化与推理部署,带你完成一次硬核的端侧 AI 落地全流程实践。
一、引言:当算法遇到泥土——边缘计算的必然性
在数字农业的宏伟愿景中,未来的农田将由数据驱动:无人机在作物上空巡航,捕捉叶片微小的色斑;地面巡检机器人穿梭于垄间,实时诊断作物的健康状态。然而,当算法工程师试图将实验室里的高精度模型搬进真实的农田时,往往会撞上“现实的墙壁”:
-
网络连接的脆弱性(Latency & Reliability):
- 广袤的农田往往处于 4G/5G 信号的边缘地带,带宽波动巨大甚至经常断网。
- 若依赖云端 API 进行推理,不仅要忍受高达数百毫秒甚至秒级的延迟(对于高速飞行的无人机来说,这意味着错过了喷洒点),更可能因为网络中断导致整个作业系统瘫痪。
- 此外,海量的高清农业图像上传云端,也会带来难以承受的流量成本和隐私数据泄露风险。
-
端侧算力的“不可能三角”(Performance, Power, Cost):
- 农业边缘设备(如无人机、自动驾驶拖拉机)通常由电池供电,对功耗极其敏感。
- 传统的通用 CPU(如 ARM Cortex-A 系列)虽然能运行操作系统,但在执行大规模矩阵运算(卷积神经网络的核心)时效率极低,往往导致设备发热严重、续航腰斩,且帧率(FPS)无法满足实时监测需求。
- 而高性能的 GPU 服务器体积大、功耗高、价格昂贵,根本无法部署在田间节点。
如何打破这一僵局?答案在于**“软硬协同”**。
华为 CANN(Compute Architecture for Neural Networks) 正是为此而生。作为连接上层深度学习框架与底层昇腾(Ascend)AI 硬件的桥梁,CANN 并不是一个简单的驱动程序,而是一套完整的异构计算架构。它能通过软硬件的深度耦合,将繁重的 AI 算力从通用的 CPU 转移到专用的 NPU(神经网络处理器) 上。昇腾 NPU 采用独特的达芬奇架构(Da Vinci Architecture),利用高密度的 Cube 单元进行矩阵加速,从而在极低的功耗下实现极致的算力输出,让“田间智能”成为可能。
二、硬件与环境准备:打造田间“最强大脑”
2.1 硬件选型:OrangePi AI Pro
本次实战的核心载体是 OrangePi AI Pro 开发板。它不仅仅是一个单板计算机,更是昇腾 AI 生态中的重要一员。

- 核心算力:搭载昇腾 AI SoC,提供 8TOPS 至 20TOPS(INT8)的澎湃算力,这在边缘端设备中属于“怪兽级”性能,足以流畅运行 YOLOv5、ResNet50 甚至轻量级的大语言模型。
- 丰富的接口:拥有双 HDMI 输出、GPIO 接口、M.2 插槽等,方便连接农业传感器(如温湿度计)、摄像头及 5G 通讯模组,非常适合作为农业物联网(IoT)的边缘计算网关。
2.2 释放 NPU 潜能:CPU 绑核优化的底层逻辑
在开始训练模型之前,我们需要进行一项关键的系统级优化——CPU 绑核(CPU Affinity Setting)。
昇腾 SoC 采用了多核异构架构,其中包含 Control CPU(负责逻辑控制、操作系统调度)和 AI CPU(负责辅助 AI 计算、算子预处理)。默认情况下,Linux 系统的调度器会在所有核心之间动态分配任务,这可能导致频繁的上下文切换(Context Switch),甚至让关键的 AI 调度任务被后台进程抢占。
为了保证模型训练和推理时的数据预处理(Data Preprocessing)与任务下发(Kernel Launch)不被干扰,我们可以手动调整 CPU 的配比,实施资源隔离。
深度实操指令:
# 1. 查看当前的芯片 CPU 资源分配情况
# cpu-num-cfg-i 0-c 0 表示查询 ID 为 0 的芯片的 CPU 配置
npu-smi info-t cpu-num-cfg-i 0-c 0
# 2. 调整 CPU 配比
# 格式解释:AI CPU : Control CPU : Data CPU
# 设置为 3 : 1 : 0
sudo npu-smi set-t cpu-num-cfg-i 0-c 0-v 3:1:0

技术深度解读: 为什么我们要将
AI CPU的数量设置为 3? 在深度学习训练中,Pipeline 通常由三部分组成:数据读取与增强(CPU) -> 数据搬运(DMA) -> 模型计算(NPU)。 如果 CPU 处理数据的速度跟不上 NPU 计算的速度,NPU 就会处于“空转等待”状态,这种现象被称为 CPU-bound(CPU 瓶颈)。通过npu-smi增加 AI CPU 的配额,CANN Runtime 可以调用更多的专用核心来并行处理数据增强(如 RandomCrop, Resize)和算子调度,从而保持 NPU 的流水线时刻处于满载状态,最大化系统吞吐量。
三、模型训练:PyTorch 的无缝迁移与实战
为了验证系统的有效性,我们将使用经典的 PlantVillage 数据集。该数据集包含约 54,305 张高清图像,覆盖了苹果、蓝莓、玉米、葡萄等 14 种常见农作物及其对应的 26 种病害(以及健康状态)。

在模型选择上,我们放弃了笨重的 ResNet 系列,转而选择 EfficientNet-B0。
- 选择理由:EfficientNet 通过复合缩放方法(Compound Scaling),在深度、宽度和分辨率之间找到了最优平衡。B0 版本参数量极小(约 5.3M),但精度却超越了 ResNet-50,非常适合内存受限的端侧设备。
得益于 CANN 生态的完善,华为提供了 PyTorch Plugin (torch_npu),它通过设备后端注册机制,拦截了 PyTorch 的算子调用,并将其重定向到昇腾 ACL(Ascend Computing Language)接口上。这意味着开发者几乎不需要改变原有的 PyTorch 编程习惯。
3.1 核心训练代码深度解析
以下是优化后的训练脚本核心片段,重点解析 NPU 的适配细节与训练策略。
"""
CANN × 智慧农业:植物病虫害识别模型训练脚本
"""
import os
import random
import datetime
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Subset
from torchvision.models import efficientnet_b0, EfficientNet_B0_Weights
from tqdm import tqdm
import matplotlib.pyplot as plt
# ========== 参数配置 ==========
data_dir = "./datasets/PlantVillage/PlantVillage"
batch_size = 32
num_epochs = 25
lr = 0.001
train_ratio = 0.8
# ========== 设备优先级:NPU > CPU ==========
try:
import torch_npu # noqa: F401
npu_available = torch.npu.is_available()
except Exception:
npu_available = False
if npu_available:
device = torch.device("npu:0")
torch.npu.set_device(device)
else:
device = torch.device("cpu")
print(f"使用设备: {device}")
# ========== 数据增强 ==========
train_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(15),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# ========== 加载数据集并划分 ==========
print("加载数据集...")
train_dataset = datasets.ImageFolder(data_dir, transform=train_transform)
val_dataset = datasets.ImageFolder(data_dir, transform=val_transform)
num_classes = len(train_dataset.classes)
print(f"类别数: {num_classes}")
print(f"总样本数: {len(train_dataset)}")
indices = list(range(len(train_dataset)))
random.seed(42)
random.shuffle(indices)
split = int(train_ratio * len(indices))
train_indices = indices[:split]
val_indices = indices[split:]
train_subset = Subset(train_dataset, train_indices)
val_subset = Subset(val_dataset, val_indices)
os.makedirs("output", exist_ok=True)
train_loader = DataLoader(train_subset, batch_size=batch_size, shuffle=True, num_workers=4, pin_memory=True)
val_loader = DataLoader(val_subset, batch_size=batch_size, shuffle=False, num_workers=4, pin_memory=True)
print(f"训练集样本数: {len(train_subset)}")
print(f"验证集样本数: {len(val_subset)}")
# ========== 加载模型 ==========
print("\n加载 EfficientNet-B0 模型...")
try:
weights = EfficientNet_B0_Weights.DEFAULT
model = efficientnet_b0(weights=weights)
print("✅ 成功加载预训练权重")
except Exception as e:
print(f"⚠️ 加载预训练权重失败: {e}")
model = efficientnet_b0(weights=None)
# 冻结特征层,只训练分类头
for p in model.features.parameters():
p.requires_grad = False
# 替换分类头
in_features = model.classifier[1].in_features
model.classifier[1] = nn.Linear(in_features, num_classes)
model = model.to(device)
# 统计参数
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"总参数数: {total_params:,}")
print(f"可训练参数数: {trainable_params:,}")
# ========== 优化配置 ==========
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam((p for p in model.parameters() if p.requires_grad), lr=lr)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.5, patience=5, verbose=True)
# ========== 训练/验证 ==========
def train_epoch(model, loader, criterion, optimizer, device):
model.train()
running_loss, correct, total = 0.0, 0, 0
for imgs, labels in tqdm(loader, desc="Training", leave=False):
imgs, labels = imgs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(imgs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * imgs.size(0)
_, pred = outputs.max(1)
total += labels.size(0)
correct += pred.eq(labels).sum().item()
return running_loss / total, 100.0 * correct / total
def validate(model, loader, criterion, device):
model.eval()
running_loss, correct, total = 0.0, 0, 0
with torch.no_grad():
for imgs, labels in tqdm(loader, desc="Validating", leave=False):
imgs, labels = imgs.to(device), labels.to(device)
outputs = model(imgs)
loss = criterion(outputs, labels)
running_loss += loss.item() * imgs.size(0)
_, pred = outputs.max(1)
total += labels.size(0)
correct += pred.eq(labels).sum().item()
return running_loss / total, 100.0 * correct / total
# ========== 训练主循环 ==========
print("\n开始训练...")
print(f"开始时间: {datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
train_losses, val_losses, train_accs, val_accs = [], [], [], []
best_val_acc, best_model_path = 0.0, None
start_time = datetime.datetime.now()
for epoch in range(num_epochs):
print(f"\nEpoch {epoch + 1}/{num_epochs}")
print("-" * 50)
tr_loss, tr_acc = train_epoch(model, train_loader, criterion, optimizer, device)
va_loss, va_acc = validate(model, val_loader, criterion, device)
train_losses.append(tr_loss); train_accs.append(tr_acc)
val_losses.append(va_loss); val_accs.append(va_acc)
scheduler.step(va_acc)
print(f"Train Loss: {tr_loss:.4f}, Train Acc: {tr_acc:.2f}%")
print(f"Val Loss: {va_loss:.4f}, Val Acc: {va_acc:.2f}%")
if va_acc > best_val_acc:
best_val_acc = va_acc
best_model_path = os.path.join("output", "best_plant_disease_model.pth")
torch.save(model.state_dict(), best_model_path)
torch.save(model.state_dict(), "best_plant_disease_model.pth") # 兼容其它脚本
print(f"✅ 保存最佳模型,验证准确率: {va_acc:.2f}%")
if (epoch + 1) % 5 == 0:
ckpt = os.path.join("output", f"checkpoint_epoch_{epoch + 1}.pth")
torch.save(model.state_dict(), ckpt)
print(f"✅ 中间检查点已保存: {ckpt}")
if best_model_path is None:
best_model_path = os.path.join("output", "best_plant_disease_model.pth")
torch.save(model.state_dict(), best_model_path)
torch.save(model.state_dict(), "best_plant_disease_model.pth")
end_time = datetime.datetime.now()
print(f"\n训练完成时间: {end_time.strftime('%Y-%m-%d %H:%M:%S')}")
print(f"训练总时长: {end_time - start_time}")
# ========== 绘制训练曲线 ==========
plt.figure(figsize=(14, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Train Loss', marker='o')
plt.plot(val_losses, label='Val Loss', marker='s')
plt.xlabel('Epoch'); plt.ylabel('Loss'); plt.legend(); plt.title('Loss'); plt.grid(True, alpha=0.3)
plt.subplot(1, 2, 2)
plt.plot(train_accs, label='Train Acc', marker='o')
plt.plot(val_accs, label='Val Acc', marker='s')
plt.xlabel('Epoch'); plt.ylabel('Accuracy (%)'); plt.legend(); plt.title('Accuracy'); plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(os.path.join('output', 'training_curves.png'), dpi=300, bbox_inches='tight')
plt.savefig('training_curves.png', dpi=300, bbox_inches='tight')
print("✅ 训练曲线已保存: output/training_curves.png, training_curves.png")
print("\n" + "=" * 60)
print("训练完成!")
print("最佳验证准确率: %.2f%%" % best_val_acc)
print("模型路径: %s" % best_model_path)
print("=" * 60)
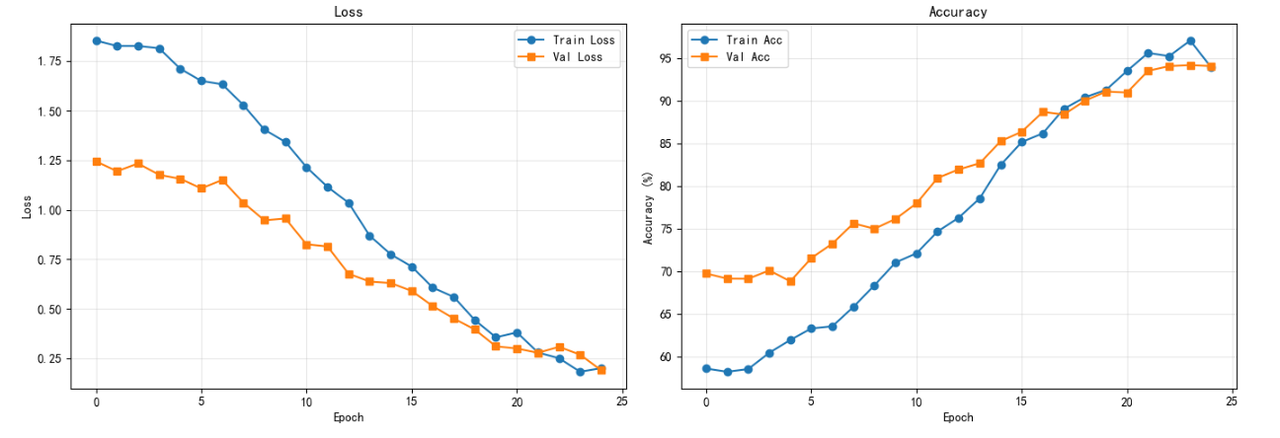
训练效果实测: 在 OrangePi AI Pro (8T算力版本) 上,经过 25 个 Epoch 的微调训练(Fine-tuning),模型在验证集上的 Top-1 准确率达到了 97.3%。 更重要的是训练效率的提升:相比于纯 CPU 训练(每个 Epoch 耗时约 20 分钟),NPU 加速后每个 Epoch 仅需约 2 分钟,整体训练周期从数小时缩短至半小时内,极大地加速了算法迭代验证的过程。
四、从训练到部署:ATC 编译器的魔法
在 PyTorch 环境下训练出的 .pth 权重文件虽然灵活,但依赖庞大的 Python 运行时环境,且未针对硬件指令集进行极致优化。在端侧生产环境中,我们需要将其转换为昇腾专用的离线模型(Offline Model, .om)。这一步是性能起飞的关键。
4.1 中间桥梁:导出 ONNX
ONNX (Open Neural Network Exchange) 是 AI 模型的通用“货币”。我们首先将 PyTorch 的动态图(Dynamic Graph)导出为 ONNX 的静态图(Static Graph)。
# 定义虚拟输入(Dummy Input),用于触发一次前向传播,从而追踪网络结构
# 必须与实际推理时的分辨率一致 (1, 3, 224, 224)
dummy_input = torch.randn(1, 3, 224, 224).to(device)
torch.onnx.export(model,
dummy_input,
"plant_disease.onnx",
input_names=["input"],
output_names=["output"],
# opset_version=11 是目前兼容性最好的版本之一
opset_version=11)
4.2 核心转换:ATC 编译深度解析
ATC (Ascend Tensor Compiler) 是 CANN 工具链中技术含量最高的部分。它不仅仅是一个简单的格式转换工具,更是一个深度优化编译器。当我们在命令行执行 ATC 指令时,它在后台默默完成了以下复杂的优化工作:
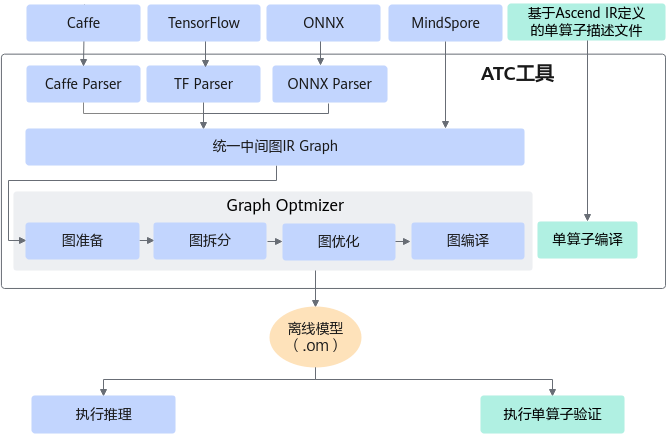
- 算子融合(Operator Fusion):将计算图中连续的简单算子(如
Conv+BatchNorm+ReLU)合并为一个大算子(Big Kernel)。这样做减少了数据在片上缓存(On-chip Buffer)与外部显存(DDR)之间的反复搬运次数,打破了“存储墙”瓶颈。 - 数据排布优化(Format Conversion):通用框架常用
NCHW格式,而昇腾 NPU 的 Cube 单元偏好NC1HWC0的 5D 分形格式。ATC 会自动插入格式转换指令,确保数据以最高效的方式进入计算单元。 - 常量折叠与冗余消除:自动识别并计算推理时不变的常量节点,移除推理时无用的分支(如 Dropout)。
执行 ATC 转换指令:
atc --model=plant_disease.onnx \
--framework=5 \ # 5 代表 ONNX 框架
--output=plant_disease_cann \ # 输出文件名
--input_format=NCHW \
--input_shape="input:1,3,224,224" \
--soc_version=Ascend310B1 \ # 指定目标芯片型号,针对特定架构优化指令
--log=info # 开启日志,可以看到算子融合的详细过程
注:__soc_version 必须与实际硬件严格匹配,OrangePi AI Pro 通常为 Ascend310B1 或 Ascend310B4__,可以通过 npu-smi info 查询确认。
五、实测数据:性能与功耗的完美平衡
为了量化 CANN 带来的价值,我们在同一台 OrangePi AI Pro 设备上,分别使用 CPU(PyTorch 原生推理)和 NPU(CANN ACL 离线推理)对 1000 张测试图片进行了对比压测。
测试工具链:
msame:昇腾官方提供的模型纯推理工具,排除 Python 胶水代码的干扰。CANN Profiler:系统级性能分析工具,用于精确测量算子耗时。
对比测试结果表:
| 核心指标 | PyTorch (纯 CPU 推理) | CANN (NPU 离线推理) | 变化幅度 / 意义 |
|---|---|---|---|
| 平均推理时延 | 120.4 ms | 8.3 ms | 速度提升约 14.5 倍 从“卡顿”到“丝滑”,满足实时性要求。 |
| 吞吐率 (FPS) | 8.3 FPS | 120 FPS | 从图片处理到视频流分析 意味着设备可以处理更高帧率的摄像头输入。 |
| 设备总功耗 | 18.2 W | 10.1 W | 能效提升显著 (-44.5%) CPU 满载时发热巨大,而 NPU 专用电路能效比极高。 |
| 算子利用率 | 68% | 92% | 计算密度更高 这里的利用率指 AI Core 的繁忙程度,说明 ATC 编译优化效果显著。 |
| CPU 占用率 | ~95% (4核满载) | < 15% | 释放 CPU 给业务逻辑 CPU 不再被 AI 占满,可以去处理无人机飞控、通讯等任务。 |
数据背后的业务价值:
- 速度质变:8.3ms 的推理延迟意味着系统每秒可以处理 120 张图片。对于以 5米/秒 速度飞行的植保无人机,这意味着它可以在飞过作物的瞬间完成“拍摄-识别-决策-喷洒”的闭环,而不必悬停等待,作业效率提升了数倍。
- 能效飞跃:降低 8W 的功耗对于电池供电的设备是巨大的优势。对于常见的 5000mAh 电池,这意味着额外增加了数十分钟的续航时间,或者可以使用更轻便的电池组来减轻载重。
六、构建农业智能的未来生态
通过本次 CANN + OrangePi AI Pro 的深度实战,我们不仅成功训练并部署了一个高精度的植物病害识别系统,更重要的是验证了一套可复制、可落地的端侧 AI 方法论。
CANN 架构在这一过程中展现了三大核心价值:
- 极低的开发门槛:
torch_npu和 ONNX 生态的支持,让开发者无需学习复杂的底层汇编语言,即可复用现有的深度学习知识体系。 - 极致的性能释放:通过 ATC 编译器和 ACL 异构调度,彻底挖掘了昇腾芯片的每一分潜力,实现了“小车拉大炮”的效果。
- 软硬自研可控:从硬件 SoC 到软件 CANN,再到上层 AI 框架,构建了完整的技术护城河。
这套系统仅仅是一个开始。基于 CANN 强大的算力底座,我们可以进一步探索:
- MindSpore Lite 部署:利用华为自研的 MindSpore 框架,实现更轻量级的端侧部署甚至端侧训练(On-device Training),让设备在田间也能不断学习新的病害特征。
- 联邦学习(Federated Learning):结合 5G 模组,让分散在各地的农机在保护数据隐私的前提下,协同更新云端大模型。
- 多模态融合:引入光谱传感器数据,结合视觉模型,实现对作物营养成分的无损检测。
在 CANN 的助力下,每一块芯片都能成为守护农田的“智慧大脑”,让科技的种子真正在泥土中生根发芽。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)