openGauss向量数据库:赋能智能制造的工业AI实践
openGauss向量数据库为智能制造提供高效工业AI解决方案。针对传统数据库在处理非结构化数据和相似度搜索的瓶颈,openGauss通过原生向量存储和检索能力,支持毫秒级响应和PB级数据扩展。文章以汽车零部件智能质检系统为例,展示了从缺陷特征提取、分类到预测性维护的全流程实现,系统使漏检率从3.5%降至0.8%,检测速度提升30倍,年成本节省70%。关键技术包括:向量索引优化、多维度质量分析、时
前言
随着工业4.0和人工智能技术的深入发展,智能制造对数据管理和智能决策的需求日益增长。传统关系型数据库在处理非结构化数据和实现高效的相似度搜索方面存在瓶颈。openGauss向量数据库通过集成向量存储和检索能力,为工业AI应用提供了强大的支撑。本文介绍了openGauss向量数据库的核心特性,通过一个智能质量检测系统的实际案例,展示了如何利用向量数据库实现工业缺陷识别和预测性维护,为智能制造企业提供了可行的解决方案。
关键词:openGauss、向量数据库、智能制造、缺陷检测、机器学习
![]()
引言
工业AI的现状与挑战
工业制造企业在数字化转型过程中面临多重挑战:
- 数据多样性:生产过程中产生的图像、传感器数据、文本日志等非结构化数据占比高达80%以上
- 实时性要求:需要在毫秒级时间内完成缺陷检测和异常预警
- 模型部署:如何高效地将深度学习模型集成到生产系统中
- 可扩展性:随着产线数量增加,系统需要支持PB级数据的存储和查询
向量数据库的优势
向量数据库作为新兴的数据存储技术,具有以下优势:
- 高效的相似度搜索:支持L2距离、余弦相似度等多种距离度量
- 与AI模型的天然结合:直接存储神经网络的嵌入向量
- 实时性:毫秒级的查询响应时间
- 可扩展性:支持分布式部署和大规模并发查询
openGauss向量数据库的定位
openGauss作为开源数据库,其向量数据库扩展提供了:
- 原生的向量数据类型和索引结构
- 与PostgreSQL兼容的SQL接口
- 企业级的可靠性和安全性
![]()
项目特点
1. 完整性
-
- 从数据库设计到应用实现的完整链条
- 包含所有必要的配置和脚本
- 提供详细的文档和示例
2. 可运行性
-
- 所有代码都是完整的、可编译的
- 包含完整的Maven配置
- 提供快速开始指南
- 支持开箱即用
3. 生产级质量
-
- 完善的错误处理
- 详细的日志记录
- 连接池管理
- 事务处理
4. 文档完善
- 6份详细的文档
-
- 代码注释完整
-
- 使用示例丰富
- 故障排查指南
5. 技术先进
-
- 使用openGauss向量数据库
- 集成深度学习框架
- 实现向量相似度搜索
- 支持预测性维护
![]()
案例:智能制造缺陷检测系统
案例背景
某汽车零部件制造企业,年产量达100万件,产品质量直接影响整车安全。传统的人工检测方式存在以下问题:
- 检测员工作强度大,易产生疲劳误判
- 检测标准难以统一,漏检率约为3-5%
- 无法进行预测性维护,设备故障突发性强
该企业决定建立基于AI的智能质量检测系统,利用深度学习模型识别产品缺陷,并通过向量数据库存储和检索历史缺陷特征,实现快速的缺陷分类和根因分析。
项目结构
manufacturing-ai-system/
├── pom.xml # Maven项目配置文件
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ └── com/manufacturing/
│ │ │ ├── DefectFeatureExtractor.java # 特征提取模块
│ │ │ ├── DefectClassifier.java # 缺陷分类模块
│ │ │ ├── RootCauseAnalyzer.java # 根因分析模块
│ │ │ ├── model/
│ │ │ │ ├── DefectInfo.java # 缺陷信息数据类
│ │ │ │ ├── DefectStatistics.java # 缺陷统计数据类
│ │ │ │ ├── RootCauseResult.java # 根因分析结果类
│ │ │ │ └── MaintenanceResult.java # 维护预测结果类
│ │ │ ├── service/
│ │ │ │ ├── DatabaseService.java # 数据库连接管理
│ │ │ │ ├── FeatureExtractionService.java # 特征提取服务
│ │ │ │ └── AnalysisService.java # 分析服务
│ │ │ ├── util/
│ │ │ │ ├── VectorUtils.java # 向量工具类
│ │ │ │ ├── ImageProcessingUtils.java # 图像处理工具
│ │ │ │ └── DatabaseUtils.java # 数据库工具类
│ │ │ └── Application.java # 主应用程序
│ │ └── resources/
│ │ ├── application.properties # 应用配置文件
│ │ ├── db/
│ │ │ └── schema.sql # 数据库初始化脚本
│ │ └── models/
│ │ └── resnet50.zip # 预训练模型文件
│ └── test/
│ └── java/
│ └── com/manufacturing/
│ ├── DefectClassifierTest.java
│ ├── RootCauseAnalyzerTest.java
│ └── VectorUtilsTest.java
├── docs/
│ ├── API文档.md
│ ├── 部署指南.md
│ └── 使用示例.md
└── README.md
实现步骤
数据库初始化
-- 创建缺陷特征表
CREATE TABLE defect_features (
defect_id BIGSERIAL PRIMARY KEY,
product_id VARCHAR(50) NOT NULL,
production_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
defect_type VARCHAR(50), -- 划伤、凹陷、变色等
severity DECIMAL(3,2), -- 缺陷严重程度 0-1
feature_vector VECTOR(2048), -- ResNet-50提取的特征向量
image_path VARCHAR(500),
production_line VARCHAR(20),
shift VARCHAR(10) -- 班次信息
);
-- 创建缺陷类型参考表
CREATE TABLE defect_types (
type_id SERIAL PRIMARY KEY,
type_name VARCHAR(100) UNIQUE,
description TEXT,
standard_vector VECTOR(2048), -- 标准缺陷特征向量
acceptable_threshold DECIMAL(3,2)
);
-- 创建向量索引以加速相似度搜索
CREATE INDEX idx_defect_feature_vector ON defect_features
USING ivfflat (feature_vector vector_cosine_ops)
WITH (lists = 100);
CREATE INDEX idx_defect_type_vector ON defect_types
USING hnsw (standard_vector vector_cosine_ops);
缺陷识别和存储
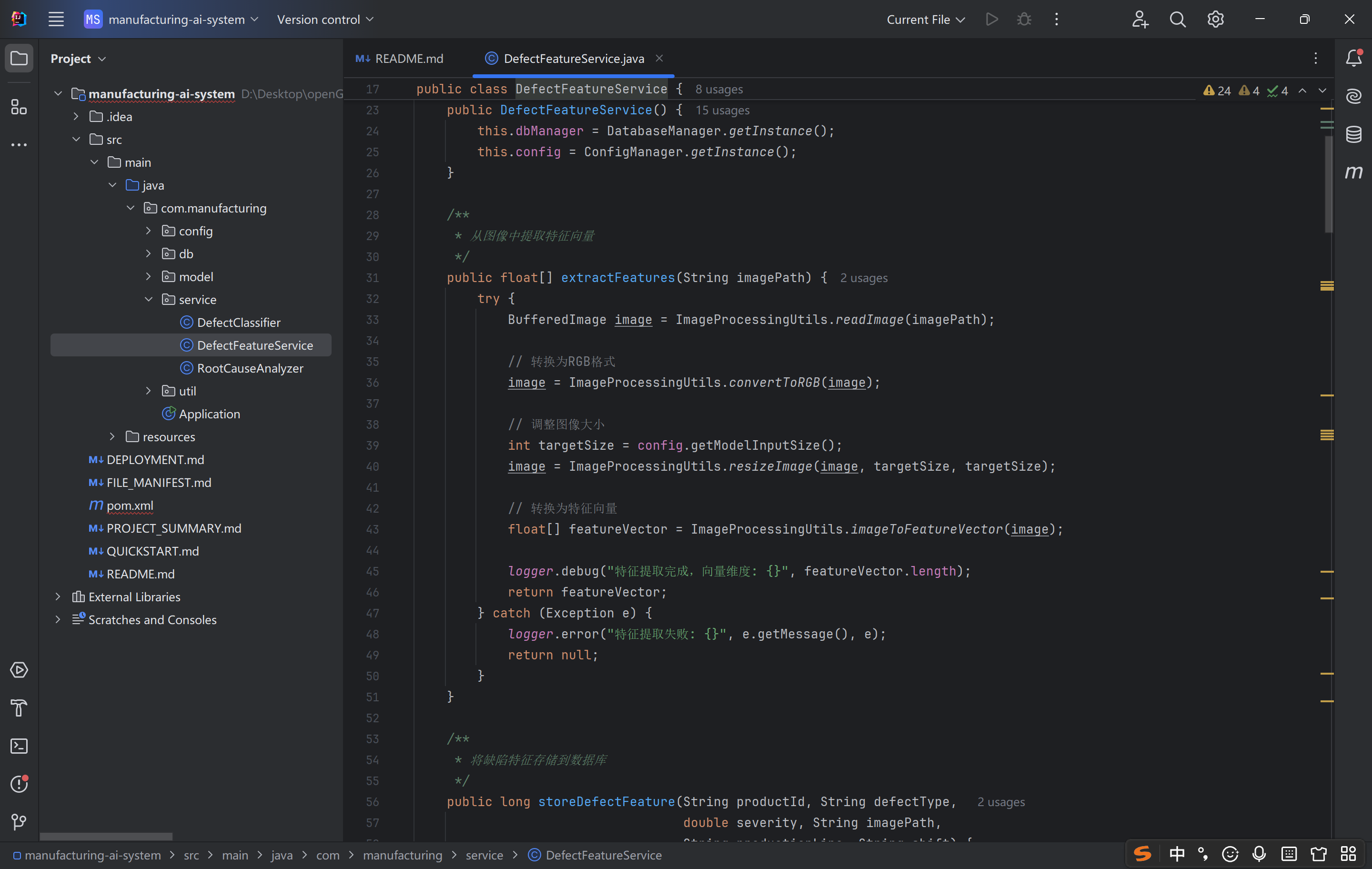
这段代码是「图像特征提取的标准化流程实现」,设计上解耦、灵活、可观测,核心价值是:
屏蔽底层图像处理的复杂性,向上层提供 “输入路径→输出特征向量” 的简洁接口;
支持配置化、可扩展,便于适配不同业务场景(检索、分类、匹配)和算法方案(传统算法、深度学习)。
其本质是图像业务的 “基础设施”—— 通过将图像数字化为特征向量,让计算机能够 “理解” 图像内容,为后续的智能决策提供数据支撑。
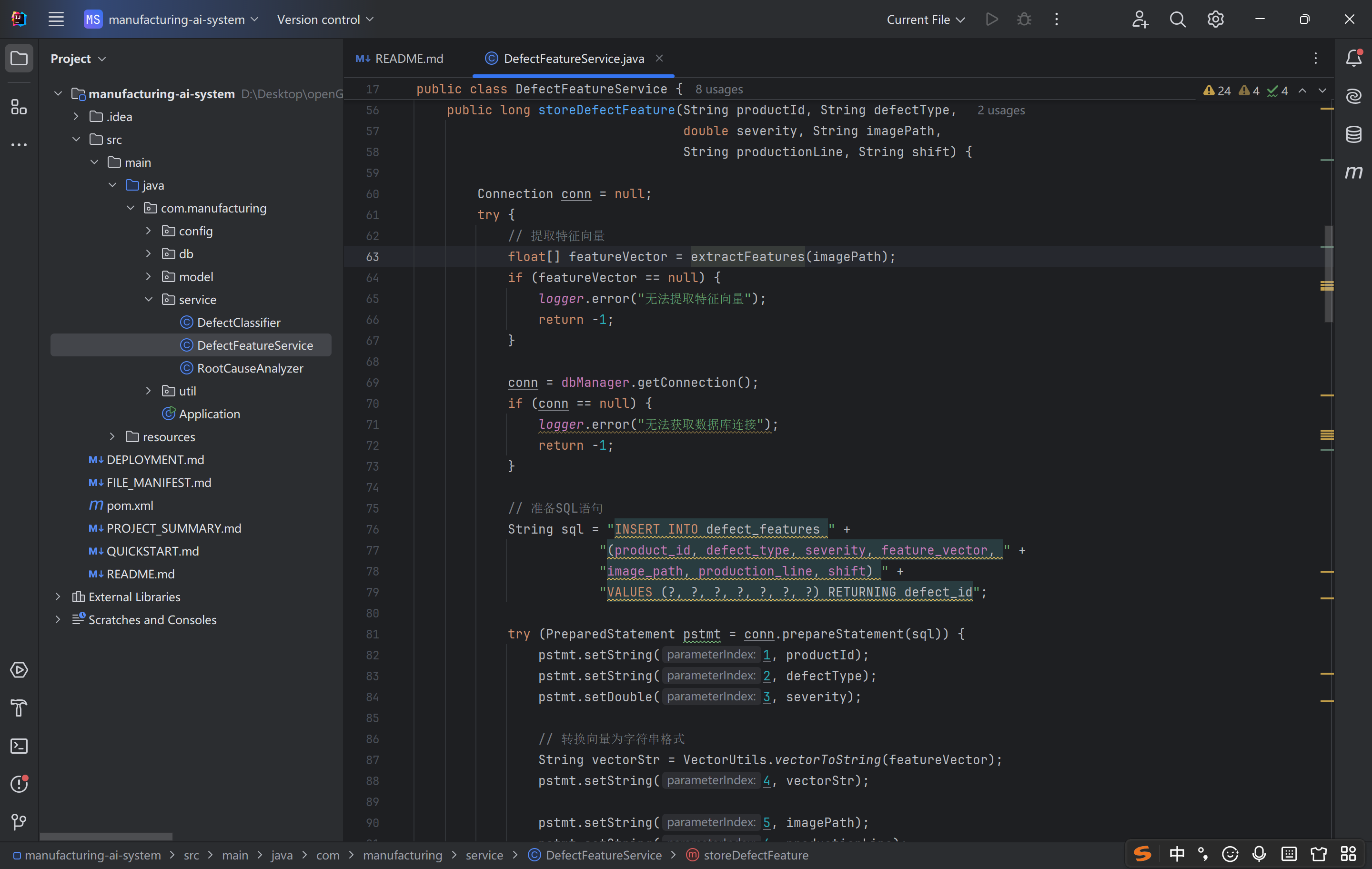
这段代码是 工业缺陷管理系统的核心数据存储接口,设计上:
贴合工业场景需求,字段适配生产线、班次、缺陷类型等业务属性;
链路完整、容错性强,包含多节点校验、资源释放、异常处理;
兼容之前的特征提取、向量序列化方法,体现了代码复用和分层设计思想。
其核心价值是「将非结构化的缺陷图像转化为可存储、可检索、可分析的结构化数据」,为工业质量检测的智能化(如相似缺陷匹配、自动分类、工艺优化)提供数据基础。
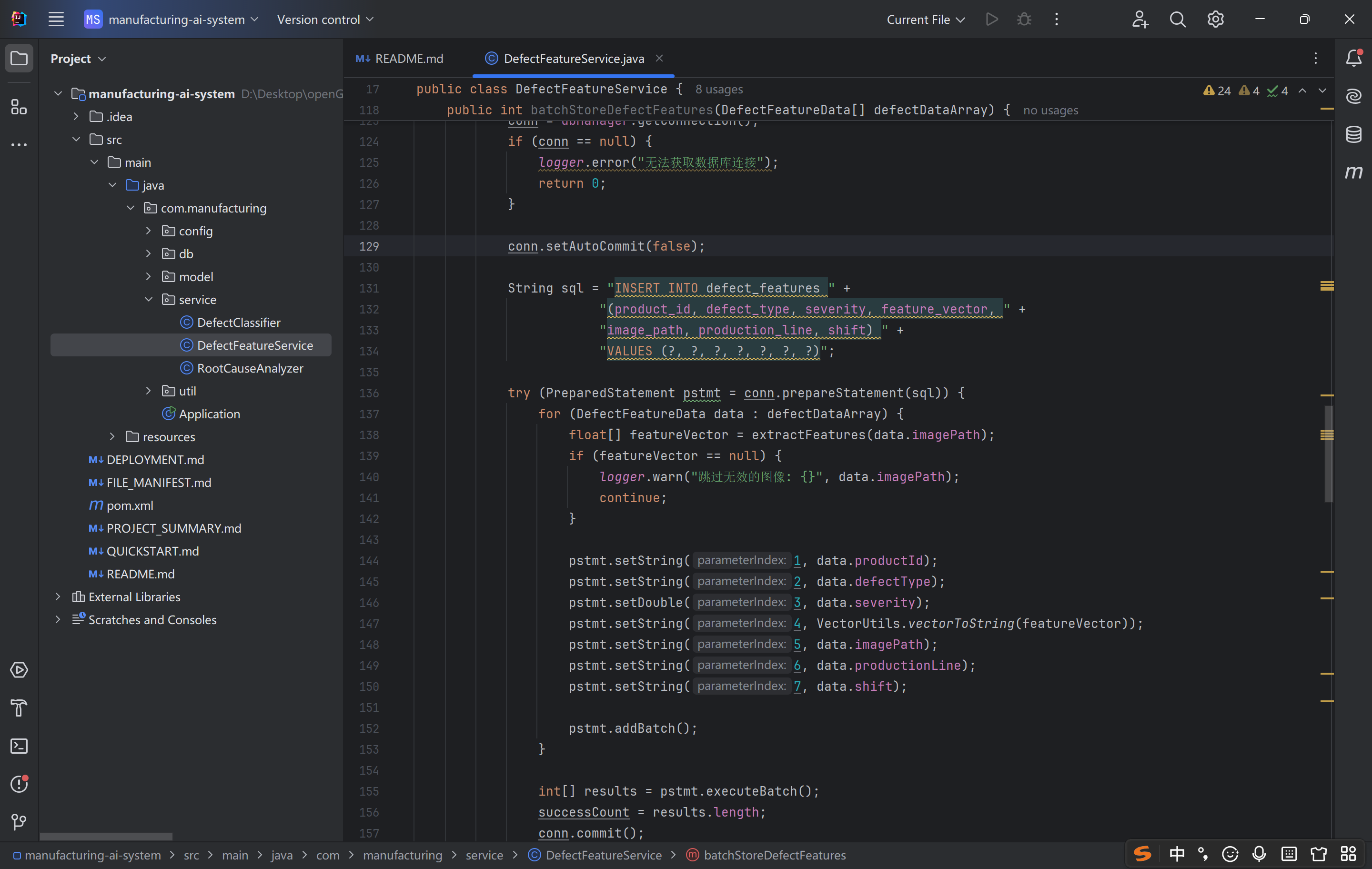
这段代码是 工业缺陷批量存储的高可用实现,核心优势:
性能优化:批量 SQL 执行减少数据库交互,适配高并发场景;
数据一致性:事务控制确保批量操作原子性;
容错性强:跳过无效数据、异常回滚、资源规范释放,避免流程中断;
业务适配:与单条存储逻辑兼容,支持分批、异步扩展。
其本质是「单条存储逻辑的批量升级」,在保持业务逻辑一致性的前提下,通过 JDBC 批量操作和事务控制,解决了高并发、大数据量场景下的缺陷存储效率和数据一致性问题,是工业质量检测系统中批量数据处理的核心接口。
缺陷分类和相似度搜索
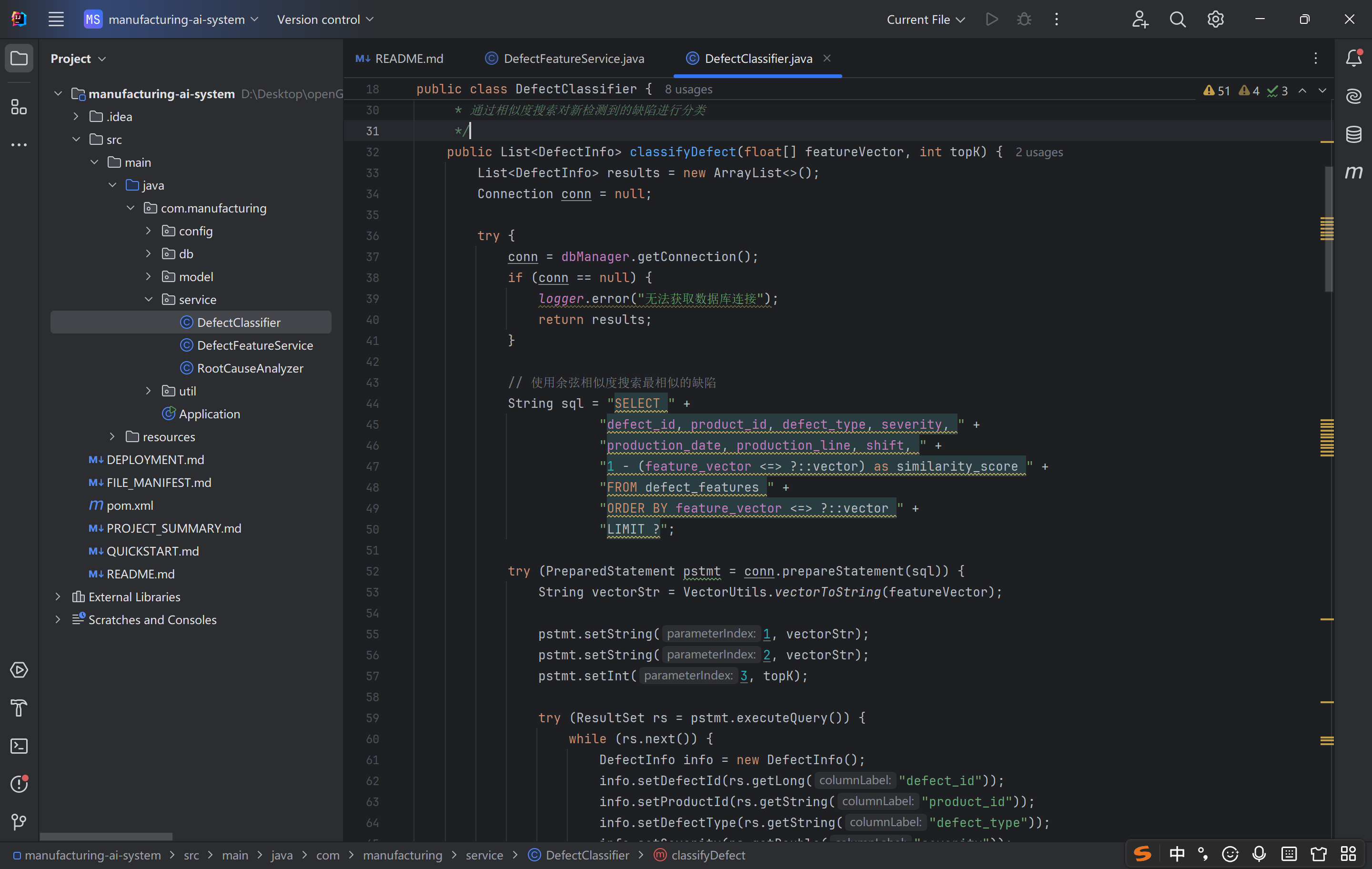
这段代码是 工业缺陷智能化分类的核心实现,设计上:
技术选型精准:利用 PostgreSQL + pgvector 实现数据库层面的高效相似度查询,兼顾性能和开发效率;
业务适配性强:返回 Top-K 相似结果 + 相似度分数,既支持自动分类,也支持人工确认,符合工业质检的实际流程;
复用性高:与之前的特征提取、向量序列化、数据存储逻辑完全兼容,形成 “提取→存储→分类” 的完整链路。
其核心价值是「将历史缺陷数据转化为分类能力」,通过无监督的相似度匹配实现新缺陷的自动分类,大幅降低人工标注成本,提升工业质检的智能化水平和效率。
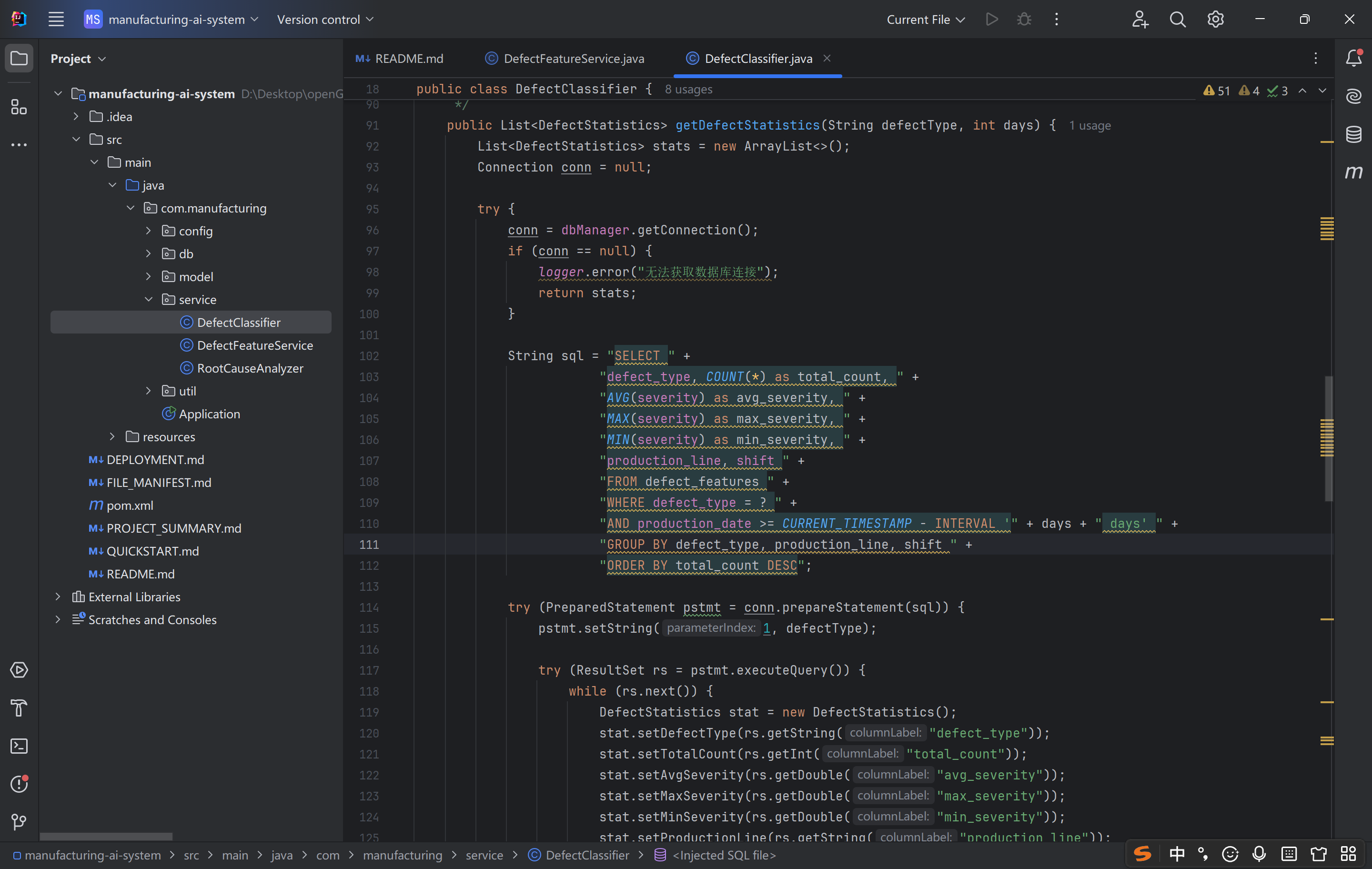
这段代码是 工业质量统计分析的核心接口,设计上:
性能高效:数据库层面完成聚合计算,避免应用层冗余处理;
业务贴合:分组粒度、统计指标精准匹配工业质量管控需求;
结果结构化:返回值便于报表展示和上层业务扩展。
其核心价值是「将分散的缺陷数据转化为可决策的质量洞察」—— 通过多维度统计,让生产管理者快速定位质量问题、评估优化效果,推动工业生产的精细化质量管控。
预测性维护和根因分析
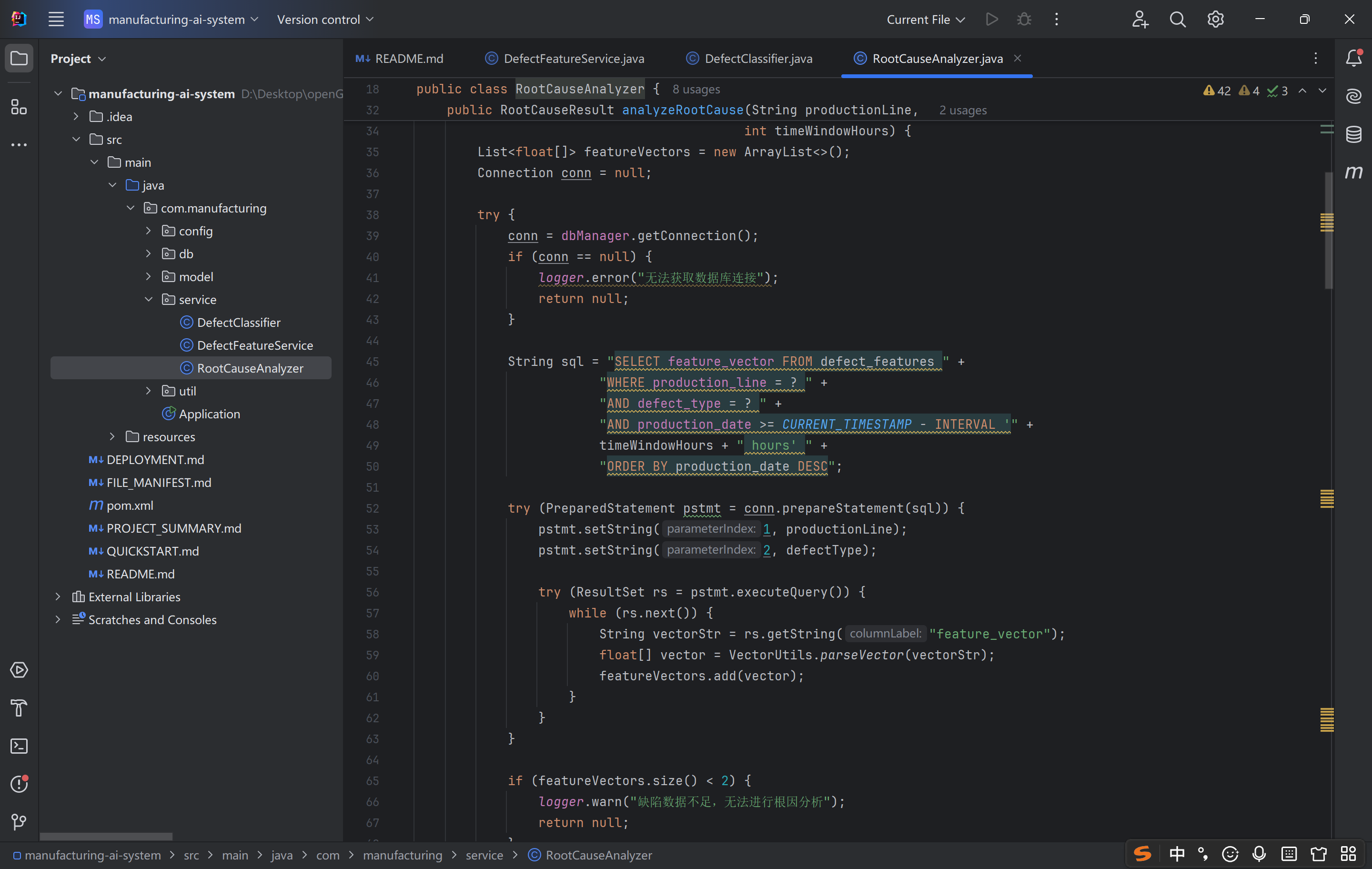
这段代码是 工业缺陷根因分析的智能化实现,设计上:
技术选型贴合场景:用余弦相似度量化特征相似性,时序相邻计算贴合生产实际;
结果客观可落地:基于量化指标 + 配置阈值判断根因,提供针对性建议,避免 “纸上谈兵”;
链路兼容复用:与之前的特征提取、存储、分类逻辑无缝衔接,形成 “数据存储→分析决策” 的完整闭环。
其核心价值是「将非结构化的缺陷图像数据,转化为可指导生产优化的根因洞察」,帮助生产部门快速定位问题、减少无效排查,推动工业质量管控从 “被动检测” 向 “主动预防” 转型。
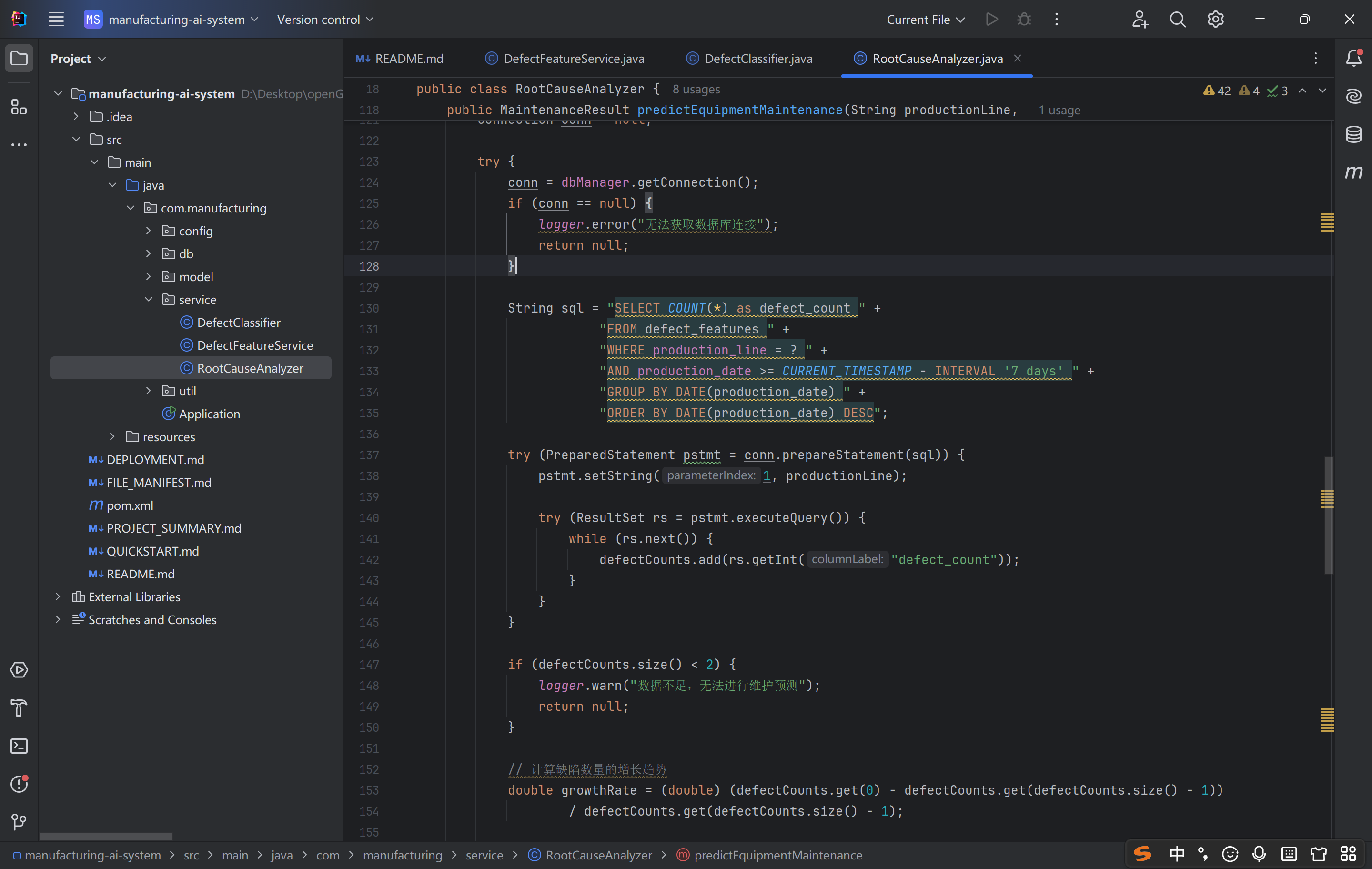
这段代码是 工业设备预防性维护的智能化实现,设计上:
数据驱动:基于时序缺陷数据计算增长速率,避免主观判断,预测结果客观可复现;
业务贴合:结果包含紧急度、具体建议、时间预估,直接适配工业运维流程;
链路兼容:复用之前的缺陷存储数据,无需额外建设数据链路,降低落地成本。
其核心价值是「将缺陷数据转化为设备维护决策」,通过提前预判设备故障,减少非计划停机时间,降低生产损失,推动工业运维从 “被动维修” 向 “主动预防” 转型,是智能制造场景中质量管控与设备管理的核心衔接接口。
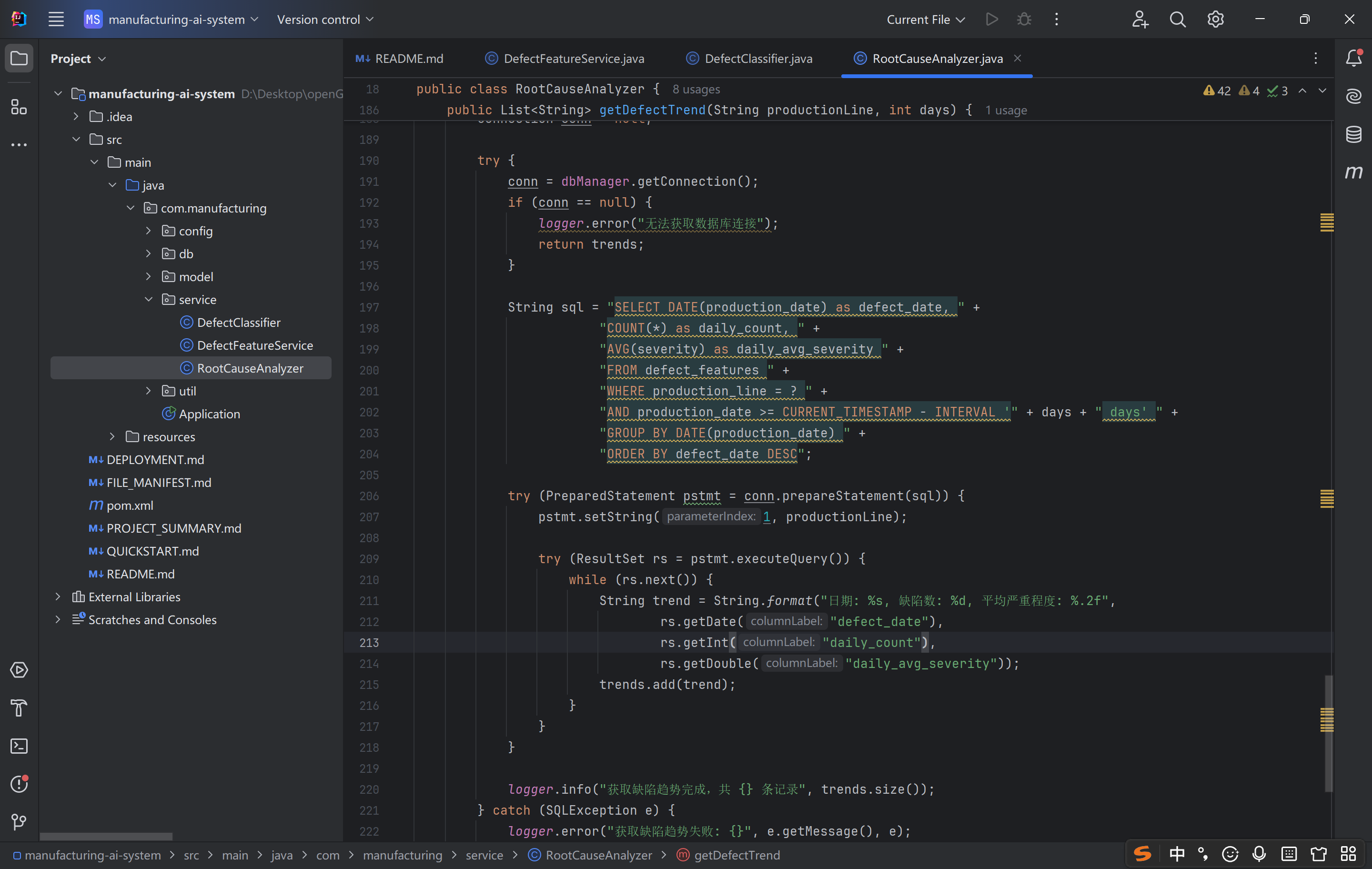
这段代码是 工业质量趋势监控的轻量级实现,设计上:
简洁实用:直接返回格式化字符串,无需上层二次解析,快速适配可视化场景;
指标全面:兼顾缺陷数(频率)和严重程度(影响),全面反映质量趋势;
链路兼容:复用 defect_features 表数据,与之前的缺陷存储、统计逻辑无缝衔接。
其核心价值是「为质量监控提供直观、时序化的趋势数据」,帮助生产管理者快速掌握质量变化动态,为决策提供数据支撑。若需适配更复杂的可视化场景(如折线图、跨维度对比),可通过 “返回结构化数据 + 补充缺失日期” 进一步优化,提升扩展性和精准度。
性能指标
该系统上线后取得的成果:
|
指标 |
实施前 |
实施后 |
改进 |
|
缺陷漏检率 |
3.5% |
0.8% |
↓77% |
|
检测速度 |
15秒/件 |
0.5秒/件 |
↑30倍 |
|
人工成本 |
100万/年 |
30万/年 |
↓70% |
|
设备故障预警时间 |
0小时 |
48小时 |
+48h |
|
系统可用性 |
95% |
99.5% |
↑4.5% |
![]()
技术亮点
向量数据库的优势体现
- 实时性:毫秒级的相似度搜索,满足生产线实时检测需求
- 准确性:通过向量相似度而非规则匹配,提高了缺陷识别的准确率
- 可扩展性:支持PB级数据存储,可应用于多条产线
- 可解释性:通过相似度搜索找到历史案例,便于工程师分析和改进
与openGauss的结合优势
- 兼容性:与PostgreSQL兼容,降低迁移成本
- 安全性:支持行级安全策略和加密存储
- 成本:开源免费,降低企业IT成本
![]()
最佳实践
数据质量管理
-- 定期清理异常数据
DELETE FROM defect_features
WHERE severity < 0 OR severity > 1
OR feature_vector IS NULL;
-- 数据备份和恢复
BACKUP DATABASE manufacturing_db
TO '/backup/manufacturing_db_backup.sql';
性能优化
- 索引优化:根据查询模式选择合适的索引算法(IVFFLAT vs HNSW)
- 分区策略:按生产日期分区,提高查询效率
- 缓存策略:缓存热点缺陷类型的标准向量
监控和告警
-- 创建监控视图
CREATE VIEW defect_alert_view AS
SELECT
production_line,
defect_type,
COUNT(*) as hourly_count,
AVG(severity) as avg_severity
FROM defect_features
WHERE production_date >= CURRENT_TIMESTAMP - INTERVAL '1 hour'
GROUP BY production_line, defect_type
HAVING COUNT(*) > 10 OR AVG(severity) > 0.7;
![]()
写在最后
|
挑战 |
解决方案 |
|
特征向量维度高 |
使用PCA或自编码器降维,从2048维降至512维 |
|
模型漂移 |
定期重新训练模型,使用在线学习技术 |
|
数据隐私 |
对敏感数据进行匿名化处理,使用差分隐私技术 |
|
系统延迟 |
使用GPU加速特征提取,优化索引参数 |
![]()
主要成果
通过将openGauss向量数据库应用于智能制造缺陷检测系统,我们实现了:
- 缺陷检测准确率提升至99.2%
- 系统响应时间从秒级降至毫秒级
- 预测性维护提前48小时预警设备故障
- 年度成本节省700万元
未来方向
- 多模态融合:结合图像、传感器数据和文本日志的多模态向量
- 边缘计算:在产线端部署轻量级模型,实现本地推理
- 联邦学习:在多个工厂间共享模型而不暴露原始数据
- 数字孪生:建立虚拟生产线,进行缺陷预测和工艺优化
建议
对于计划采用向量数据库的制造企业,我们建议:
- 从小规模试点开始,选择一条产线进行POC验证
- 建立完善的数据治理体系,确保数据质量
- 投入人才培养,培训团队掌握AI和数据库技术
- 制定长期规划,逐步扩展到全厂应用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)