【每天一个AI小知识】:什么是生成对抗网络?
摘要:生成对抗网络(GAN)是一种由生成器和判别器组成的深度学习模型,通过对抗训练实现数据生成。文章以画家与鉴赏家的故事为引,生动解释了GAN的工作原理:生成器不断优化仿作质量,判别器持续提升鉴别能力,最终达到平衡。详细介绍了GAN的数学模型、经典变体(DCGAN、CycleGAN、StyleGAN等)及其在图像生成、风格转换等领域的应用。通过MNIST手写数字生成的代码示例,展示了GAN的实现过
目录
一、开篇:从画家与鉴赏家的故事说起
在巴黎的一条艺术街上,有两位才华横溢的年轻人:一位是画家小G,另一位是鉴赏家小D。他们决定进行一场特殊的比赛,挑战艺术的极限。
比赛规则很简单:小G需要创作一幅足以以假乱真的蒙娜丽莎仿作,而小D则需要鉴别出哪一幅是真品,哪一幅是仿作。
第一轮比赛,小G画出了一幅粗糙的仿作,小D一眼就看出了破绽:"你画的蒙娜丽莎笑容不够神秘,背景的山水也太模糊了!"
小G并没有气馁,他仔细研究了蒙娜丽莎的每一个细节,包括颜料的质感、光影的变化和构图的比例。
第二轮比赛,小G的仿作有了很大进步,但小D还是发现了问题:"人物的眼神缺乏神韵,手部的线条不够流畅!"
就这样,他们不断地进行着比赛:小G努力提高自己的绘画技巧,创作出越来越逼真的仿作;小D则不断锻炼自己的鉴别能力,努力找出每一个细微的破绽。
经过数百轮的较量,奇迹发生了:小G创作的蒙娜丽莎仿作竟然与真品难分真假,连小D都无法准确鉴别!
这个故事,正是生成对抗网络(Generative Adversarial Network,GAN)的工作原理——两个神经网络相互对抗、共同进步,最终创造出令人惊叹的成果。
二、什么是生成对抗网络?
生成对抗网络是一种由生成器(Generator)和判别器(Discriminator)组成的深度学习模型,它通过两个网络的相互对抗来学习数据的分布,从而生成新的、与原始数据相似的样本。
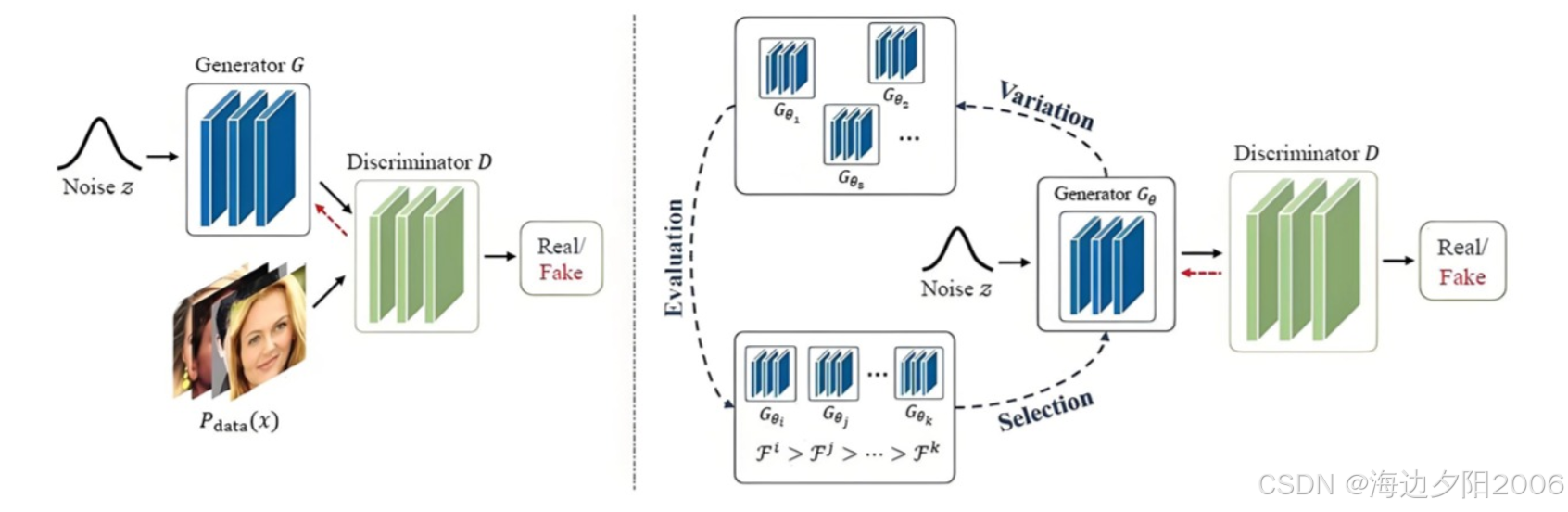
核心思想:
- 生成器(Generator):学习数据的分布,生成与原始数据相似的假样本
- 判别器(Discriminator):学习区分真实样本和生成的假样本
- 对抗过程:生成器和判别器在对抗中不断提高自己的能力,最终达到一种平衡状态
与传统生成模型的区别:
- 传统生成模型(如VAE)通过最大化数据的似然概率来学习数据分布
- GAN通过对抗过程直接学习数据的分布,生成的样本质量通常更高
三、GAN的结构:生成器与判别器的双人舞
3.1 GAN的基本结构
生成对抗网络主要由两部分组成:生成器(Generator)和判别器(Discriminator)。

1. 生成器(Generator):
- 输入:随机噪声向量(Latent Vector)
- 输出:与原始数据相似的假样本
- 功能:学习数据的分布,生成逼真的假样本
- 结构:通常由反卷积层(或全连接层)组成,用于将低维噪声向量映射到高维数据空间
2. 判别器(Discriminator):
- 输入:真实样本或生成器生成的假样本
- 输出:样本为真实数据的概率(0-1之间)
- 功能:区分真实样本和假样本
- 结构:通常由卷积层(或全连接层)组成,用于将高维数据映射到一维概率输出
3.2 GAN的工作原理
GAN的工作过程就像画家与鉴赏家的比赛,分为以下几个步骤:
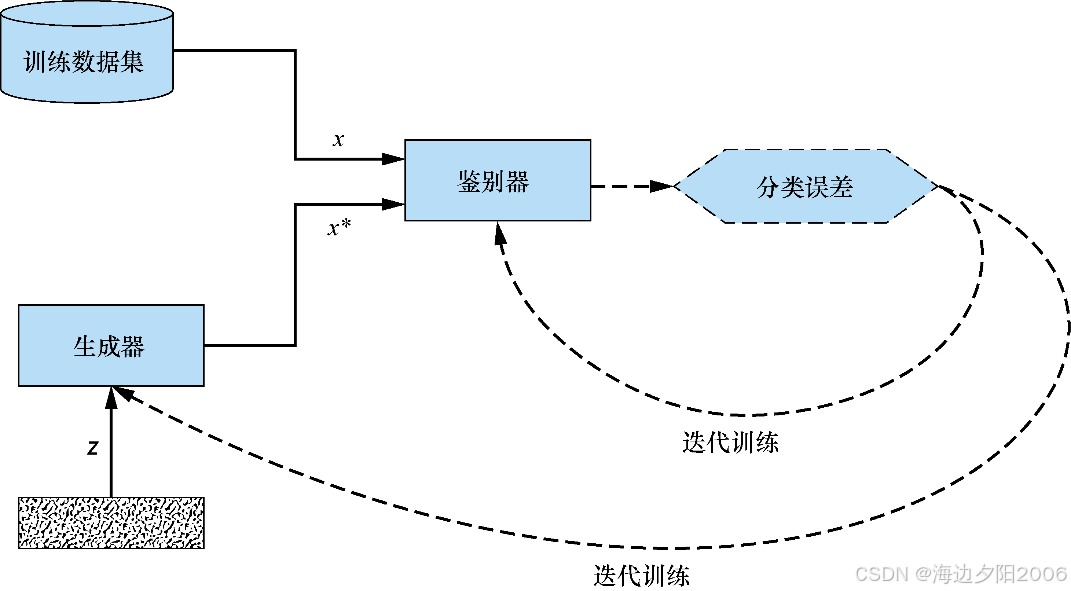
1. 初始化:随机初始化生成器和判别器的参数
2. 生成假样本:生成器接收随机噪声向量,生成假样本
3. 训练判别器:
- 判别器接收真实样本,输出概率接近1
- 判别器接收生成器生成的假样本,输出概率接近0
- 通过反向传播更新判别器的参数,提高其鉴别能力
4. 训练生成器:
- 生成器生成新的假样本
- 判别器尝试鉴别这些假样本
- 通过反向传播更新生成器的参数,提高其生成逼真样本的能力
5. 迭代训练:重复步骤2-4,直到生成器生成的样本足以以假乱真,判别器的准确率接近50%
3.3 GAN的数学模型
GAN的训练过程可以用以下数学公式表示:
目标函数:
其中:
- (
) 是真实数据的分布
- (
) 是噪声的分布
- ( G(z) ) 是生成器生成的假样本
- ( D(x) ) 是判别器判断样本为真实数据的概率
训练过程:
1. 固定生成器G,训练判别器D:
- 最大化目标函数V(D, G)
- 使判别器能够准确区分真实样本和假样本
2. 固定判别器D,训练生成器G:
- 最小化目标函数V(D, G)
- 使生成器生成的假样本能够骗过判别器
3.4 GAN的平衡点
GAN的训练过程是一个纳什均衡问题,当达到平衡时:
- 生成器G生成的样本分布与真实数据分布完全相同
- 判别器D无法区分真实样本和假样本,输出概率始终为0.5
此时,目标函数达到最小值:
四、GAN的经典变体:从基础到前沿
随着研究的深入,科学家们提出了许多GAN的变体,以解决基本GAN存在的问题(如训练不稳定、模式崩溃等),并扩展其应用领域。
4.1 DCGAN:深度卷积生成对抗网络
DCGAN(Deep Convolutional GAN)是GAN的第一个重要变体,它使用卷积神经网络来构建生成器和判别器。
核心改进:
- 使用反卷积层(Transposed Convolution)代替全连接层构建生成器
- 使用卷积层代替全连接层构建判别器
- 移除池化层,使用步幅卷积和反卷积来控制特征图大小
- 使用Batch Normalization稳定训练过程
- 使用ReLU激活函数(生成器输出层使用Tanh)
应用场景:
- 图像生成
- 风格迁移
- 超分辨率重建
4.2 CycleGAN:循环一致对抗网络
CycleGAN是一种无监督图像到图像翻译的GAN变体,它能够将一种风格的图像转换为另一种风格,而不需要成对的训练数据。
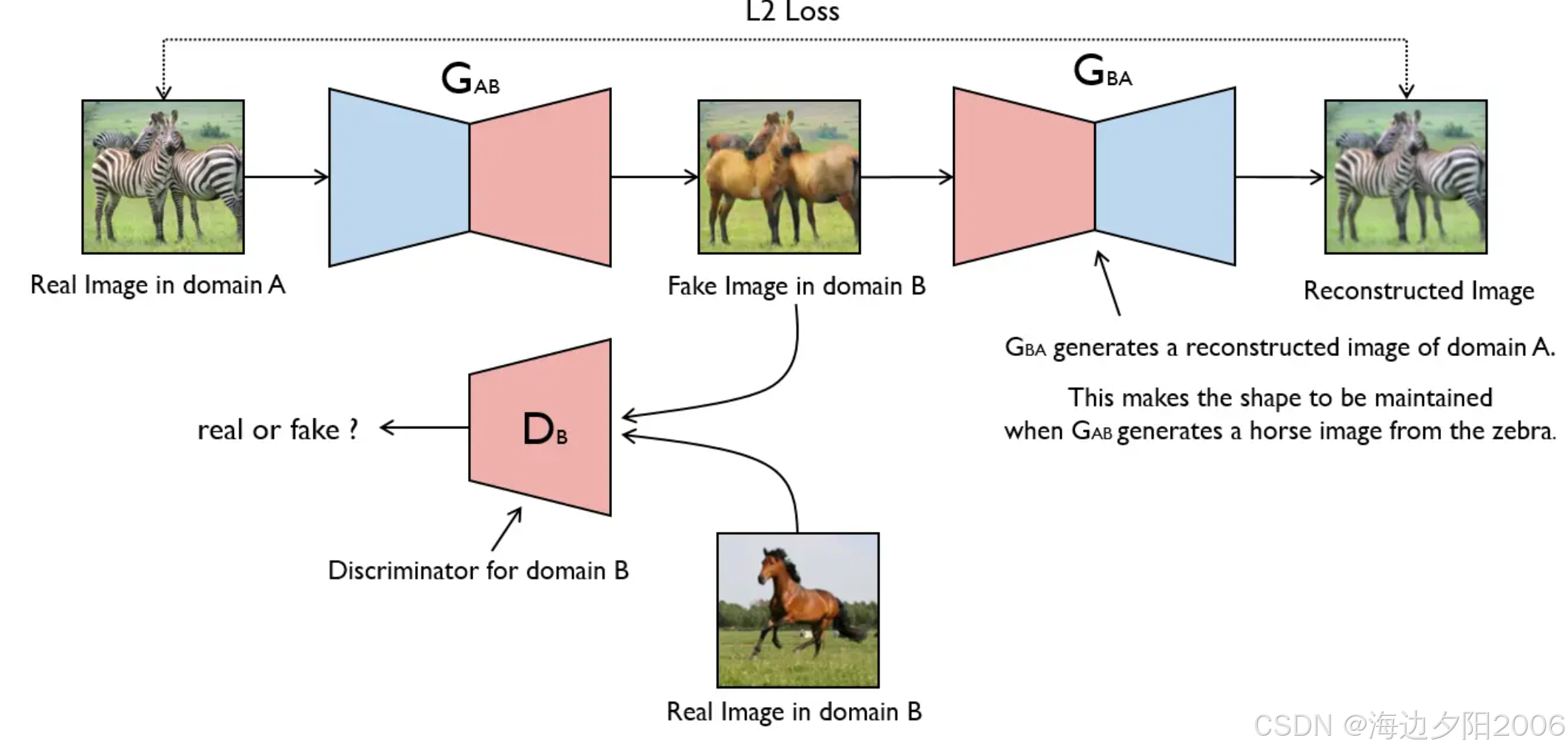
核心思想:
- 使用两个生成器:G(A→B)和F(B→A)
- 使用两个判别器:DA(判别A域图像)和DB(判别B域图像)
- 引入循环一致性损失,确保A→B→A和B→A→B的转换能够恢复原始图像
应用场景:
- 图像风格转换(如梵高风格、莫奈风格)
- 季节转换(如冬季→夏季)
- 物体转换(如马→斑马)
4.3 StyleGAN:风格生成对抗网络
StyleGAN是一种能够生成高质量、高度可控图像的GAN变体,它能够分离图像的内容和风格。
核心改进:
- 引入风格向量(Style Vector)控制图像的风格
- 使用自适应实例归一化(AdaIN)将风格注入到生成过程中
- 采用渐进式生长策略,从低分辨率到高分辨率逐步训练
- 引入噪声输入增强图像的细节变化
应用场景:
- 高质量人脸生成
- 图像编辑和风格控制
- 艺术创作
4.4 Pix2Pix:条件生成对抗网络
Pix2Pix是一种有监督图像到图像翻译的GAN变体,它需要成对的训练数据。
核心思想:
- 使用条件生成器,将输入图像和噪声一起作为输入
- 使用U-Net结构作为生成器,保留空间信息
- 使用PatchGAN作为判别器,关注局部区域的真实性
应用场景:
- 图像着色
- 边缘检测到图像
- 卫星图像到地图
4.5 GAN的其他重要变体
- WGAN(Wasserstein GAN):使用Wasserstein距离代替JS散度,解决训练不稳定问题
- ProGAN(Progressive GAN):采用渐进式生长策略,生成高分辨率图像
- StarGAN:统一的多域图像到图像翻译框架
- BigGAN:大规模GAN,生成超高质量图像
五、GAN的工作流程:一个详细的例子
为了更好地理解GAN的工作原理,让我们通过一个具体的例子来演示它的完整工作流程。
5.1 MNIST手写数字生成
假设我们有一个MNIST手写数字数据集,包含60,000张28×28像素的手写数字图像。我们将使用GAN来生成新的手写数字图像。
步骤1:数据预处理
- 将图像转换为28×28×1的张量
- 归一化像素值到[-1, 1]之间
步骤2:构建生成器
- 输入:100维的随机噪声向量
- 结构:4层反卷积网络
- 输出:28×28×1的生成图像
- 激活函数:ReLU(中间层)和Tanh(输出层)
步骤3:构建判别器
- 输入:28×28×1的图像
- 结构:4层卷积网络
- 输出:图像为真实数据的概率(0-1)
- 激活函数:LeakyReLU(中间层)和Sigmoid(输出层)
步骤4:训练GAN
1. 训练判别器:
- 从真实数据集中采样一批图像(如128张)
- 生成一批噪声向量,通过生成器生成假图像
- 计算判别器对真实图像和假图像的输出
- 计算判别器的损失函数(二元交叉熵)
- 使用反向传播更新判别器的参数
2. 训练生成器:
- 生成一批新的噪声向量
- 通过生成器生成假图像
- 计算判别器对假图像的输出
- 计算生成器的损失函数(二元交叉熵)
- 使用反向传播更新生成器的参数
3. 迭代训练:
- 重复上述过程,训练100个epoch
- 每训练一定轮次,保存生成器的权重,并生成一些图像观察效果
步骤5:生成新的手写数字
- 生成一个100维的随机噪声向量
- 通过训练好的生成器生成新的手写数字图像
- 可以调整噪声向量来生成不同风格的手写数字
六、GAN的实现代码示例
为了让大家更直观地了解GAN的实现,我们将使用Python和TensorFlow/Keras库来实现一个基本的GAN,用于生成MNIST手写数字图像。
6.1 导入库和数据
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Reshape, Flatten, Dropout
from tensorflow.keras.layers import BatchNormalization, LeakyReLU, Conv2D, Conv2DTranspose
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.optimizers import Adam
6.2 准备数据
# 加载MNIST数据集
(X_train, _), (_, _) = mnist.load_data()
# 数据预处理
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32')
X_train = (X_train - 127.5) / 127.5 # 将像素值归一化到[-1, 1]
# 设置参数
img_rows, img_cols, channels = 28, 28, 1
img_shape = (img_rows, img_cols, channels)
z_dim = 100 # 噪声向量的维度
batch_size = 128
6.3 构建生成器
def build_generator():
model = Sequential()
# 输入层:100维噪声向量
model.add(Dense(256, input_dim=z_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
# 输出层:28×28×1的图像
model.add(Dense(np.prod(img_shape), activation='tanh'))
model.add(Reshape(img_shape))
model.summary()
z = Input(shape=(z_dim,))
img = model(z)
return Model(z, img)
6.4 构建判别器
def build_discriminator():
model = Sequential()
# 输入层:28×28×1的图像
model.add(Flatten(input_shape=img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
# 输出层:图像为真实数据的概率
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=img_shape)
validity = model(img)
return Model(img, validity)
6.5 构建和训练GAN
# 构建判别器
discriminator = build_discriminator()
discriminator.compile(loss='binary_crossentropy', optimizer=Adam(0.0002, 0.5), metrics=['accuracy'])
# 构建生成器
generator = build_generator()
# 构建GAN
z = Input(shape=(z_dim,))
img = generator(z)
discriminator.trainable = False # 在训练生成器时,固定判别器的参数
validity = discriminator(img)
# 编译GAN模型
gan = Model(z, validity)
gan.compile(loss='binary_crossentropy', optimizer=Adam(0.0002, 0.5))
# 训练GAN
def train(epochs, save_interval=50):
# 创建标签
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
# --------------------- 训练判别器 --------------------- #
# 从真实数据集中采样一批图像
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
# 生成一批噪声向量
noise = np.random.normal(0, 1, (batch_size, z_dim))
# 生成一批假图像
gen_imgs = generator.predict(noise)
# 训练判别器
d_loss_real = discriminator.train_on_batch(imgs, valid)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# --------------------- 训练生成器 --------------------- #
# 生成一批新的噪声向量
noise = np.random.normal(0, 1, (batch_size, z_dim))
# 训练生成器
g_loss = gan.train_on_batch(noise, valid)
# --------------------- 打印进度 --------------------- #
print(f"Epoch {epoch+1}/{epochs} [D loss: {d_loss[0]:.4f}, acc.: {100*d_loss[1]:.2f}%] [G loss: {g_loss:.4f}]")
# 保存生成的图像
if (epoch + 1) % save_interval == 0:
save_imgs(epoch + 1)
# 保存生成的图像
def save_imgs(epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, z_dim))
gen_imgs = generator.predict(noise)
# 将像素值转换回[0, 1]
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig(f"gan_mnist_epoch_{epoch}.png")
plt.close()
# 训练GAN
train(epochs=10000, save_interval=1000)
6.6 生成新的手写数字
# 生成新的手写数字
r, c = 10, 10
noise = np.random.normal(0, 1, (r * c, z_dim))
gen_imgs = generator.predict(noise)
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c, figsize=(10, 10))
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("gan_mnist_generated.png")
plt.show()
七、GAN的应用场景:从艺术创作到科学研究
生成对抗网络凭借其强大的生成能力,在许多领域都有广泛的应用。
7.1 图像生成
GAN能够生成高质量、多样化的图像,是图像生成领域的重要技术。
应用案例:
- 人脸生成(StyleGAN)
- 风景图像生成
- 艺术作品生成
7.2 图像到图像翻译
GAN能够将一种风格的图像转换为另一种风格,实现图像到图像的翻译。
应用案例:
- 图像着色(黑白→彩色)
- 风格迁移(如梵高风格、莫奈风格)
- 物体转换(如马→斑马、猫→狗)
7.3 图像超分辨率
GAN能够将低分辨率图像转换为高分辨率图像,提高图像的质量和细节。
应用案例:
- 老照片修复
- 视频超分辨率
- 医疗图像增强
7.4 文本到图像生成
GAN能够将文本描述转换为相应的图像,实现文本到图像的生成。
应用案例:
- 根据文本描述生成图像
- 插画生成
- 概念设计
7.5 音频生成
GAN不仅可以生成图像,还可以生成音频数据。
应用案例:
- 音乐生成
- 语音合成
- 音效生成
7.6 视频生成
GAN能够生成连续的视频序列,实现视频生成。
应用案例:
- 视频预测
- 动作生成
- 视频插帧
7.7 其他应用场景
- 数据增强:生成新的训练数据,提高模型的泛化能力
- 异常检测:学习正常数据的分布,检测异常数据
- 药物发现:生成新的分子结构,用于药物研发
- 游戏开发:生成游戏场景、角色和纹理
八、GAN的挑战与解决方案:生成对抗网络的困境与突破
尽管GAN在许多领域都取得了显著的成果,但它仍然面临着一些挑战。
8.1 训练不稳定
问题:GAN的训练过程是一个动态的博弈过程,容易出现不稳定的情况,如梯度消失、梯度爆炸等。
解决方案:
- 使用WGAN的Wasserstein距离代替JS散度
- 使用Batch Normalization稳定训练过程
- 使用较小的学习率和合适的优化器(如Adam)
8.2 模式崩溃
问题:生成器只生成有限种类的样本,无法覆盖整个真实数据的分布。
解决方案:
- 使用多个判别器
- 引入多样性损失
- 使用WGAN-GP等改进模型
8.3 评估困难
问题:缺乏客观的指标来评估生成样本的质量和多样性。
解决方案:
- 使用Inception Score(IS)评估生成样本的质量和多样性
- 使用Fréchet Inception Distance(FID)评估生成样本与真实样本的分布差异
- 使用人工评估辅助判断
8.4 计算资源需求大
问题:训练高质量的GAN需要大量的计算资源和时间。
解决方案:
- 使用分布式训练
- 使用模型压缩技术
- 优化网络结构
九、哲学思考:生成对抗网络的启示
生成对抗网络的发明不仅仅是技术上的突破,也引发了我们对人工智能、创造力和人类认知的思考。
9.1 创造力的本质
GAN能够生成前所未有的图像和内容,这引发了我们对创造力本质的思考:创造力是人类独有的能力吗?机器是否也能够拥有创造力?
9.2 对抗与合作
GAN的核心思想是对抗与合作的结合:生成器和判别器在对抗中共同进步。这启示我们,对抗与合作是推动进步的重要力量。
9.3 模仿与创造
GAN通过学习数据的分布来生成新的样本,这是一个从模仿到创造的过程。这启示我们,模仿是创造的基础,创造是模仿的升华。
9.4 真实与虚假
GAN能够生成以假乱真的样本,这挑战了我们对真实与虚假的认知:什么是真实?如何区分真实与虚假?
十、总结
生成对抗网络是人工智能领域的一项重大突破,它通过生成器和判别器的对抗过程,学习数据的分布,从而生成新的、与原始数据相似的样本。
从画家与鉴赏家的故事到复杂的数学模型,从基本GAN到各种变体,从图像生成到视频预测,GAN用它独特的方式,展示了人工智能的创造力和潜力。
尽管GAN仍然面临着一些挑战,但随着研究的不断深入,它将在更多领域发挥重要作用,为人类带来更多的惊喜和便利。无论是在艺术创作、内容生成还是科学研究领域,GAN都将继续展现它的魔法,帮助我们更好地理解和利用数据。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)