AI与深度学习:开创智能时代的革命—— 从神经元数学原理到现代网络架构的演进
本文系统回顾了人工智能60年发展历程,重点剖析了深度学习的崛起与核心原理。文章首先梳理了AI从符号主义到深度学习的范式转变,指出大数据、算力和算法的突破是深度学习爆发的关键。随后深入探讨了神经网络的基础数学原理,包括感知机局限、激活函数作用和反向传播机制。通过对比不同激活函数特性,阐述了非线性变换对模型性能的影响。文章还详细解析了损失函数和优化器的演进,并以PyTorch代码示例展示了反向传播的实
摘要
本文作为关于人工智能与深度学习的深度综述,旨在系统性地解构这一正在重塑人类社会的颠覆性技术。在上部中,我们将首先回溯人工智能六十余年的波澜壮阔,探究深度学习如何从“寒冬”中复苏并确立统治地位。随后,我们将深入数学底层,剖析神经网络的构建原理,从感知机的局限到反向传播算法的推导,揭示机器“学习”的数学本质。在架构层面,本文将详细论述卷积神经网络(CNN)在计算机视觉中的进化逻辑,以及循环神经网络(RNN)与LSTM在序列建模中的机制创新。通过理论推导、Mermaid架构可视化及PyTorch代码实战,为读者构建坚实的深度学习知识大厦。
第一章 引言:智能时代的黎明与技术范式的转移
1.1 人工智能的定义与历史周期律
人工智能(Artificial Intelligence, AI)不仅是一门技术,更是一个关于“什么是智能”的哲学命题。1950年,艾伦·图灵(Alan Turing)在《计算机器与智能》中提出的“图灵测试”,为机器智能设立了早期的行为主义标准。然而,AI 的发展并非线性上升,而是经历了著名的“三起三落”。
-
第一次浪潮(1956-1974):符号主义的黄金时代
1956年达特茅斯会议上,麦卡锡、明斯基等先驱确立了AI领域。这一时期的核心思想是符号主义(Symbolism),即认为智能等同于符号处理。人们相信通过形式逻辑和推导规则(如逻辑理论家程序 Logic Theorist)可以解决所有问题。然而,随着问题复杂度的增加,符号系统遭遇了“组合爆炸”难题,难以处理常识推理和模糊性,导致了第一次AI寒冬。 -
第二次浪潮(1980-1987):专家系统的兴衰
随着**专家系统(Expert Systems)**的商用,AI迎来复苏。像XCON这样的系统通过硬编码人类专家的知识规则来解决特定领域问题。但这种方法依然依赖人工构建知识库(Knowledge Base),面临严重的“知识获取瓶颈”,且缺乏泛化能力。Lisp机器市场的崩盘标志着第二次寒冬的到来。 -
第三次浪潮(2006-至今):联结主义与深度学习的爆发
联结主义(Connectionism)模仿人脑神经元连接的仿生学路径最初并不被看好。直到2006年,Geoffrey Hinton在《Science》发表论文提出深度置信网络(DBN),利用逐层预训练(Layer-wise Pre-training)解决了深层网络的训练难题。此后,随着大数据(ImageNet等数据集的出现)、算力(NVIDIA GPU并行计算的普及)以及算法(ReLU, Dropout, ResNet)的三驾马车齐驱,深度学习终于迎来了寒武纪大爆发。
1.2 深度学习的核心地位:Feature Engineering的终结
传统机器学习(如SVM、随机森林)极其依赖人工特征工程(Hand-crafted Feature Engineering)。例如,在传统人脸识别中,工程师需要手工设计算法来提取边缘、纹理、SIFT或HOG特征。这不仅耗时耗力,且特征的表现力受限于人类的先验知识。
深度学习的革命性在于实现了表征学习(Representation Learning)。通过多层非线性变换,模型能够从原始数据(如像素、声波)中自动学习出从低级(边缘)到高级(眼睛、鼻子、人脸)的层次化特征。这种“端到端”(End-to-End)的学习方式,彻底粉碎了特定领域的知识壁垒,使得同一套神经网络架构可以同时横跨CV(计算机视觉)、NLP(自然语言处理)等多个领域。
第二章 深度学习基础:构建智能的数学基石
深度学习的黑盒之下,是严密的线性代数与微积分的交响乐。我们将从最基本的神经元开始,逐步构建整个网络。
2.1 感知机与异或问题的悲剧
1957年,Frank Rosenblatt 提出了感知机(Perceptron),这是最简单的神经网络。
数学上,它是一个线性分类器:
f(x)={1if w⋅x+b>00otherwisef(x) = \begin{cases} 1 & \text{if } w \cdot x + b > 0 \\ 0 & \text{otherwise} \end{cases}f(x)={10if w⋅x+b>0otherwise
虽然它能解决简单的线性可分问题(如AND/OR逻辑),但1969年 Minsky 和 Papert 在《Perceptrons》一书中证明了单层感知机无法解决 异或(XOR) 问题(因为XOR是线性不可分的)。这一数学判决书直接导致了神经网络研究停滞了近20年。
解决之道在于:堆叠层数并引入非线性激活函数。
2.2 激活函数:灵魂的非线性变换
如果只堆叠线性层,无论多深,最终网络仍然等价于单层线性变换(因为线性变换的组合仍是线性的)。激活函数(Activation Function)的引入打破了线性约束,赋予了网络逼近任意复杂函数的能力(万能逼近定理)。
2.2.1 常见激活函数对比
| 激活函数 | 公式 | 优点 | 缺点 | ||
|---|---|---|---|---|---|
| Sigmoid | σ(z)=11+e−z\sigma(z) = \frac{1}{1+e^{-z}}σ(z)=1+e−z1 | 输出在(0,1)之间,适合概率输出 | 梯度消失:当zzz很大时,导数趋近0,导致深层网络无法训练;输出不是零中心的。 | ||
| Tanh | tanh(z)=ez−e−zez+e−z\tanh(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}}tanh(z)=ez+e−zez−e−z | 输出在(-1,1)之间,零中心化 | 依然存在梯度消失问题。 | ||
| ReLU | f(z)=max(0,z)f(z) = \max(0, z)f(z)=max(0,z) | 计算极快;正区间导数为1,无梯度消失;稀疏激活性 | Dead ReLU:负区间导数为0,若神经元陷入负值区将永远无法激活。 | ||
| Leaky ReLU | f(z)=max(αz,z)f(z) = \max(\alpha z, z)f(z)=max(αz,z) | 解决了Dead ReLU问题 | 引入了超参数 $\alpha$。 |
2.3 训练的本质:损失函数与优化器
深度学习的训练过程,本质上是在高维参数空间中寻找损失函数极小值点的优化过程。
-
损失函数(Loss Function):衡量预测值 y^\hat{y}y^ 与真实值 yyy 的差距。
- 均方误差(MSE):L=1N∑(y^i−yi)2L = \frac{1}{N}\sum (\hat{y}_i - y_i)^2L=N1∑(y^i−yi)2,常用于回归任务。
- 交叉熵(Cross-Entropy):L=−∑yilog(y^i)L = -\sum y_i \log(\hat{y}_i)L=−∑yilog(y^i),常用于分类任务,它衡量两个概率分布的距离。
-
梯度下降(Gradient Descent):
为了最小化 L(θ)L(\theta)L(θ),我们需要沿着梯度的反方向更新参数:
θt+1=θt−η⋅∇θL(θt)\theta_{t+1} = \theta_t - \eta \cdot \nabla_\theta L(\theta_t)θt+1=θt−η⋅∇θL(θt)
其中 η\etaη 是学习率(Learning Rate)。如果 η\etaη 太小,收敛太慢;如果 η\etaη 太大,可能导致震荡甚至发散。 -
优化器的演进:
- SGD:随机梯度下降,每次只用一个样本更新,速度快但震荡大。
- Momentum:引入动量概念,模拟物理惯性,加速收敛并抑制震荡。
- Adam (Adaptive Moment Estimation):结合了Momentum和RMSprop,为每个参数自适应调整学习率,是目前最常用的优化器。
2.4 反向传播算法(Backpropagation):核心引擎
反向传播是深度学习的“上帝算法”。它利用微积分中的链式法则(Chain Rule),高效地计算损失函数对网络中数百万个参数的梯度。
假设有一个简单的路径:x→h→y→Lx \to h \to y \to Lx→h→y→L
其中 h=w1xh = w_1 xh=w1x, y=w2hy = w_2 hy=w2h, L=(y−t)2L = (y - t)^2L=(y−t)2。
我们想更新 w1w_1w1,需要求 ∂L∂w1\frac{\partial L}{\partial w_1}∂w1∂L:
∂L∂w1=∂L∂y⏟输出层误差⋅∂y∂h⏟层间权重⋅∂h∂w1⏟输入激活\frac{\partial L}{\partial w_1} = \underbrace{\frac{\partial L}{\partial y}}_{\text{输出层误差}} \cdot \underbrace{\frac{\partial y}{\partial h}}_{\text{层间权重}} \cdot \underbrace{\frac{\partial h}{\partial w_1}}_{\text{输入激活}}∂w1∂L=输出层误差
∂y∂L⋅层间权重
∂h∂y⋅输入激活
∂w1∂h
这种从后向前传递误差信号的机制,使得多层网络的训练成为可能。
代码实战:从零实现反向传播(PyTorch)
为了演示这一核心机制,我们不使用现成模型,而是构建一个简单的全连接层训练过程。
代码示例如下:
import torch
import torch.nn as nn
# 1. 设定随机种子以保证结果可复现
torch.manual_seed(42)
# 2. 模拟数据:输入维度10,输出分类3,Batch size 5
X = torch.randn(5, 10)
Y_target = torch.tensor([0, 1, 2, 0, 1]) # 真实标签
# 3. 定义模型权重 (手动定义,不使用 nn.Linear 以展示原理)
# 隐藏层权重: 10 -> 20
W1 = torch.randn(10, 20, requires_grad=True)
b1 = torch.zeros(20, requires_grad=True)
# 输出层权重: 20 -> 3
W2 = torch.randn(20, 3, requires_grad=True)
b2 = torch.zeros(3, requires_grad=True)
learning_rate = 0.01
# 4. 训练循环
for epoch in range(50):
# --- 前向传播 (Forward Pass) ---
# 线性变换 1
z1 = X @ W1 + b1
# 激活函数 ReLU (利用 clamp 实现 max(0, x))
a1 = torch.clamp(z1, min=0)
# 线性变换 2
z2 = a1 @ W2 + b2
# Softmax 计算概率 (为了数值稳定通常结合 CrossEntropyLoss,这里简化)
# 咱们直接使用 PyTorch 的 CrossEntropyLoss,它包含 LogSoftmax
loss_fn = nn.CrossEntropyLoss()
loss = loss_fn(z2, Y_target)
# --- 反向传播 (Backward Pass) ---
# PyTorch 自动计算计算图中的梯度
loss.backward()
# --- 参数更新 (Gradient Descent) ---
with torch.no_grad(): # 更新参数时不需要计算梯度
W1 -= learning_rate * W1.grad
b1 -= learning_rate * b1.grad
W2 -= learning_rate * W2.grad
b2 -= learning_rate * b2.grad
# 清空梯度,防止累积
W1.grad.zero_()
b1.grad.zero_()
W2.grad.zero_()
b2.grad.zero_()
if epoch % 10 == 0:
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")
print("训练完成。我们手动实现了神经网络的内核机制。")
第三章 深度学习架构与发展:视觉与时序的征服
3.1 卷积神经网络(CNN):计算机视觉的破局者
全连接网络(MLP)在处理图像时面临参数量爆炸的问题。一张 1000×10001000 \times 10001000×1000 的彩色图片,输入维度高达300万。如果第一层有1000个神经元,参数量就是30亿!这不仅难以训练,也极易过拟合。
卷积神经网络(Convolutional Neural Network) 引入了两个核心归纳偏置(Inductive Bias):
- 局部连接(Local Connectivity):神经元只关注图像的一小块区域(感受野)。
- 权值共享(Weight Sharing):用同一个卷积核扫描整张图片(因为猫在图片的左上角和右下角特征是相似的)。
3.1.1 核心组件详解
-
卷积层 (Conv):执行互相关运算。
- Padding (填充):在图像边缘补零,保持输出尺寸不变。
- Stride (步幅):卷积核滑动的步长,步幅越大,输出尺寸越小。
-
池化层 (Pooling):下采样操作。
- Max Pooling:取区域最大值,保留最显著特征,提供平移不变性。
-
Flatten & FC:将三维特征图拉平成向量,进行最终分类。
3.1.2 经典 CNN 架构进化史
-
LeNet-5 (1998):Yann LeCun提出,用于银行支票手写数字识别。现代CNN的鼻祖。
-
AlexNet (2012):ImageNet冠军,引入ReLU、Dropout,使用GPU训练,开启深度学习时代。
-
VGGNet (2014):证明了使用更小(3x3)但更深(16/19层)的卷积核效果更好。
-
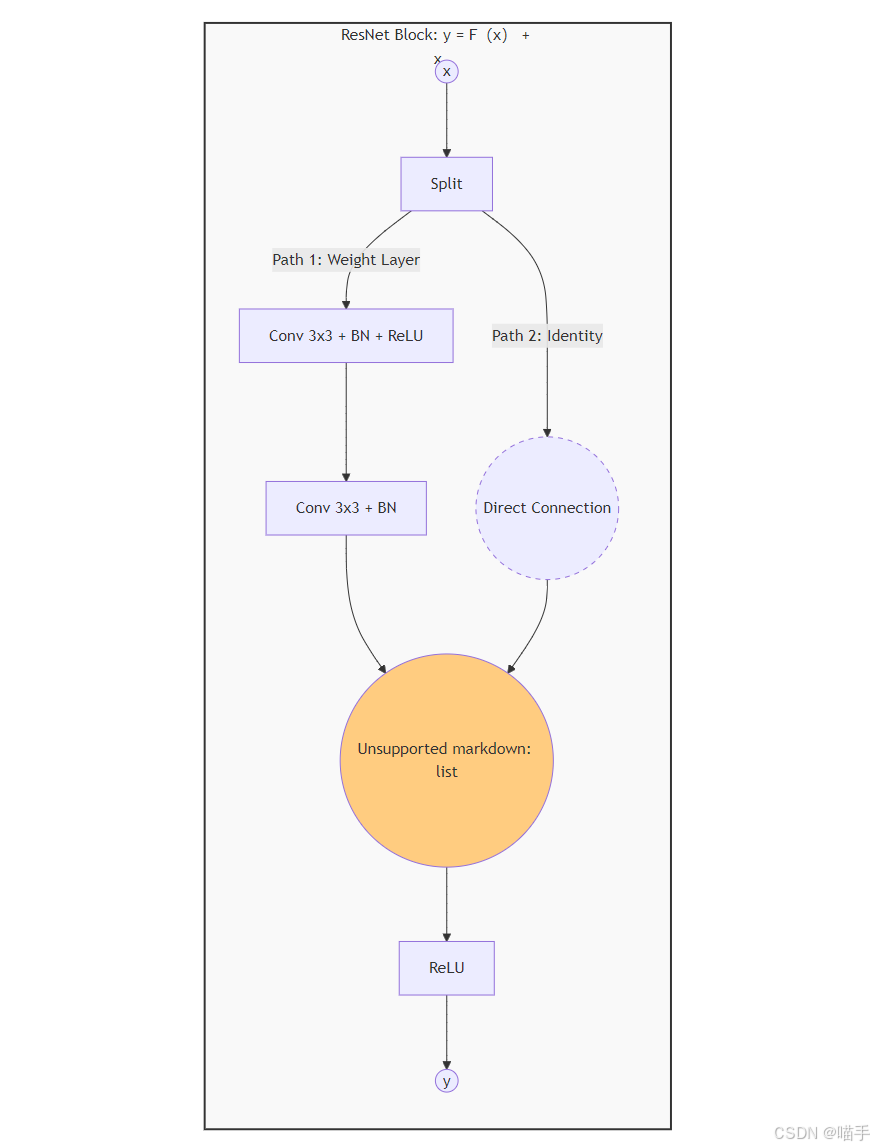
ResNet (2015):何恺明提出。
- 问题:随着网络加深,出现退化现象(Degradation),准确率反而下降。
- 方案:引入残差连接(Residual Connection),即 y=F(x)+xy = F(x) + xy=F(x)+x。这使得梯度可以通过“高速公路”直接传导到浅层,解决了梯度消失问题,使得网络可以训练到上千层。
ResNet 核心模块 Mermaid 图示:
3.2 循环神经网络(RNN)与序列建模
CNN擅长处理网格数据(如图像),而对于具有前后依赖关系的序列数据(文本、语音、股价),我们需要循环神经网络(Recurrent Neural Network)。
3.2.1 RNN 的原理与缺陷
RNN 的核心在于隐藏状态(Hidden State)。当前时刻的输出不仅取决于当前输入,还取决于上一时刻的隐藏状态。
ht=tanh(Whhht−1+Wxhxt+b)h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b)ht=tanh(Whhht−1+Wxhxt+b)
缺陷:在长序列反向传播时(BPTT),梯度会连乘。如果权重矩阵特征值小于1,梯度指数级衰减(消失);如果大于1,梯度指数级爆炸。这导致普通RNN只有“短时记忆”。
3.2.2 LSTM:长短期记忆网络
LSTM (Long Short-Term Memory) 引入了复杂的“门控机制”来精准控制信息流。
它包含三个门和一个细胞状态(Cell State, CtC_tCt):
- 遗忘门(Forget Gate):决定丢弃上一时刻的多少信息。ft=σ(Wf⋅[ht−1,xt]+bf)f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)ft=σ(Wf⋅[ht−1,xt]+bf)
- 输入门(Input Gate):决定将多少新信息存入细胞状态。
- 输出门(Output Gate):决定基于当前细胞状态输出什么值。
这种设计使得LSTM能够长时间保持重要的梯度信息,从而学会长距离依赖(例如在长文章中联系上下文)。
3.2.3 代码实战:使用 LSTM 进行文本情感分类
以下展示如何用 PyTorch 构建一个处理文本序列的模型。
import torch
import torch.nn as nn
class SentimentLSTM(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, output_dim, n_layers, dropout):
super().__init__()
# 1. 嵌入层:将单词索引转换为稠密向量
# 例如:Word ID 5 -> [0.1, -0.5, ...]
self.embedding = nn.Embedding(vocab_size, embed_dim)
# 2. LSTM 层
# batch_first=True 表示输入维度为 (batch, seq_len, features)
self.lstm = nn.LSTM(embed_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=True, # 双向LSTM效果通常更好
dropout=dropout,
batch_first=True)
# 3. 全连接层
# 因为是双向,所以输入维度是 hidden_dim * 2
self.fc = nn.Linear(hidden_dim * 2, output_dim)
# 4. Dropout 层
self.dropout = nn.Dropout(dropout)
def forward(self, text):
# text shape: [batch size, sent len]
embedded = self.dropout(self.embedding(text))
# embedded shape: [batch size, sent len, embed dim]
# LSTM 返回 output 和 (hidden, cell)
# 我们只需要最后时刻的 hidden state
output, (hidden, cell) = self.lstm(embedded)
# hidden shape: [n layers * n directions, batch size, hidden dim]
# 我们取最后两层(双向的最后状态)拼接
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1))
return self.fc(hidden)
print("LSTM 模型架构定义完毕,可用于 NLP 任务。")
第四章 总结与展望:智能时代的未来之路
4.1 深度学习的革命性影响
深度学习不仅仅是计算机科学领域的一个突破,它已深刻影响了几乎所有的行业。从医疗、金融到交通和娱乐,深度学习的应用场景在不断扩展,带来了颠覆性的改变。例如,在医学影像分析中,卷积神经网络(CNN)已成功应用于自动诊断,能够从X光片、CT图像中识别出病变区域,极大提升了诊断效率和准确率。在金融领域,深度学习被用于信用卡欺诈检测、股市预测和算法交易等方面。
然而,这场革命的背后并非一帆风顺。尽管深度学习的应用日益广泛,但在数据隐私、模型解释性和伦理问题等方面仍然面临着巨大的挑战。深度学习模型,尤其是大规模的神经网络,通常被视为“黑箱”,缺乏足够的透明度,难以解释其决策过程。对于应用场景如医疗、金融等行业,能够提供可信和可解释的AI系统已成为一项重要需求。
4.2 当前的挑战与未来的方向
尽管深度学习取得了巨大的进展,但仍有很多技术瓶颈亟待解决。以下是一些当前深度学习领域面临的主要挑战和未来发展方向:
4.2.1 模型的可解释性与透明性
深度学习模型,尤其是深度神经网络,其复杂性和非线性使得模型的推理过程难以理解和追溯。未来,如何提升AI系统的可解释性,开发出能够提供清晰决策逻辑的模型,将是一个重要的研究方向。当前,已经有一些方法如可解释AI(Explainable AI,XAI)被提出,通过可视化方法和模型简化等技术,尝试帮助人们理解模型的决策过程。
4.2.2 数据依赖与迁移学习
深度学习模型通常需要大量的标注数据才能进行有效的训练,但许多领域的标注数据非常稀缺,尤其是医学、法律等专业领域。如何在数据稀缺的情况下训练出高效的深度学习模型,成为一个亟待解决的问题。迁移学习(Transfer Learning)已经取得了一些进展,它通过将一个任务中学到的知识迁移到另一个任务中,降低了对大量标注数据的需求。未来,如何进一步提升迁移学习的性能,拓展其应用场景,将是深度学习发展的一个重要方向。
4.2.3 自监督学习与生成模型
自监督学习(Self-supervised Learning)和生成对抗网络(GANs)是近年来深度学习领域的两个重要方向。自监督学习通过利用大量未标注数据来预训练模型,使其能够在特定任务中获得优越的表现。生成对抗网络则通过生成器和判别器之间的博弈,能够生成高度逼真的图像、音频等数据。未来,这些方法可能为我们带来更强大的模型训练方式,尤其是在数据稀缺的领域,具有重要的应用前景。
4.2.4 强化学习与自主智能体
强化学习(Reinforcement Learning)已经在许多领域取得了显著的进展,如游戏、机器人控制等。未来,强化学习将可能是AI系统实现自主决策和智能行为的重要途径。自主智能体(Autonomous Agents)通过与环境的交互,能够自主地学习并执行任务,在自动驾驶、无人机等领域具有巨大的应用潜力。
4.3 对人工智能的哲学思考
随着人工智能技术的飞速发展,关于“机器能否拥有意识?”、“AI能否具有情感?”等哲学问题也愈发引起广泛关注。当前的AI系统虽然能够在某些特定任务上超越人类,但它们仍然缺乏自我意识、情感和道德判断。未来,如何平衡技术进步与伦理道德,如何为AI系统设置合理的行为约束,成为人类社会面临的重要课题。
4.4 结语:走向智能新时代
深度学习的崛起无疑是人类科技史上的一座里程碑。它不仅让机器在视觉、语言等感知任务中接近甚至超越人类,还开辟了更加广阔的智能应用领域。然而,随着技术的不断发展,如何解决当前面临的挑战,推动AI朝着更加理性、可控和智能的方向发展,将是我们未来的共同使命。
人工智能的进步,让我们看到了人类社会的无限可能,既充满机遇,也伴随着责任。作为科学工作者、工程师和社会成员,我们都应该以理性、伦理和谨慎的态度,拥抱这个智能化时代,推动科技进步造福全人类。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)