向量搜索原理与索引结构详解
摘要: 阿里云OSS向量Bucket通过向量搜索技术革新数据检索方式,将文本、图像等数据转换为高维向量,利用语义相似性实现高效搜索。核心原理包括向量嵌入(Embedding)和距离度量(如余弦相似度)。为应对海量数据检索挑战,采用近似最近邻(ANN)算法,如HNSW图索引和IVF倒排聚类索引,结合量化技术(PQ)优化内存使用。OSS向量Bucket整合这些技术,提供云原生的高效AI检索能力,无需额
在 AI 和大模型(LLM)爆发的今天,数据检索的方式正在发生根本性的范式转移:从基于关键词匹配的词汇搜索(Lexical Search),转向了基于语义理解的向量搜索(Vector Search)。
阿里云最近推出的 OSS 向量 Bucket,正是将这一核心能力直接植入到了对象存储之中。它不仅仅是一个存文件的桶,更是一个内置了高性能检索引擎的智能容器。
但这背后的原理究竟是什么?它是如何从亿万级数据中毫秒级找到“最相关”的内容的?本文将深入底层,为您硬核拆解向量搜索的数学原理与索引架构。
一、 核心原理:将“语义”映射为“距离”
向量搜索的核心哲学非常简单:万物皆可向量化(Embedding)。
1. 什么是向量嵌入 (Vector Embedding)?
计算机无法直接理解“一只在睡觉的猫”这句话,也看不懂图片。但计算机擅长处理数字。
通过深度学习模型(如 Transformer、BERT 或通义千问等),我们可以将一段文字、一张图片、甚至一段音频,转换成一个固定长度的高维浮点数数组。这个数组,就叫做向量。
-
输入:文本 "猫"
-
模型输出:
[0.12, -0.59, 0.88, ...](假设这是一个 1536 维的向量)
在这个高维的**向量空间(Vector Space)**中,语义越相似的数据,它们的坐标距离就越近。
2. 怎么算相似?(距离度量 Metrics)
在 OSS 向量 Bucket 中,当你发起搜索时,系统本质上是在计算“查询向量”与“库里已有向量”之间的距离。主要有以下三种“尺子”:
A. 欧氏距离 (Euclidean Distance, L2)
这是最符合直觉的距离,即多维空间中两点之间的直线距离。
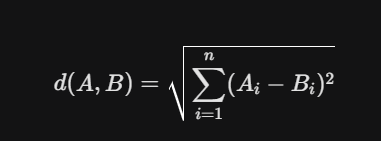
- 特点:计算出的数值越小,代表差异越小,相似度越高。
-
场景:常见于图像处理、计算机视觉领域。
B. 余弦相似度 (Cosine Similarity) —— AI 领域最常用
它计算的是两个向量在空间中夹角的余弦值。它不关心向量的长短,只关心它们的方向是否一致。
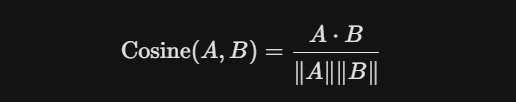
-
特点:数值越接近 1,说明夹角越小,相似度越高。
-
场景:NLP、文本检索、RAG(检索增强生成)的标准配置。OpenAI、通义千问等模型的 Embedding 通常都推荐使用这种方式。
C. 内积 (Inner Product, IP)
-
特点:计算速度最快。如果向量已经过归一化(长度为1),内积在数学上等价于余弦相似度。
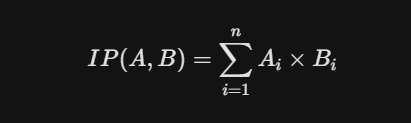
二、 核心挑战:为什么不能用简单的遍历?
假设你的 OSS Bucket 里存了 1 亿张图片。
如果你使用传统的 KNN (K-Nearest Neighbors,K-最近邻) 算法,也就是“暴力搜索”:
-
拿出你的查询向量。
-
和库里的 1 亿个向量逐个计算距离。
-
排序,选出最近的 Top 10。
这种做法在数据量大时,计算量是惊人的,延迟可能高达几秒甚至几分钟,这在实时应用中是无法接受的。
因此,工业界(包括 OSS 向量 Bucket)普遍采用的是 ANN (Approximate Nearest Neighbors,近似最近邻) 算法。
-
ANN 的核心思想:牺牲极小极小的精度(比如接受 99% 的准确率,而不是 100%),换取极高的检索速度(毫秒级)。
三、 主流向量索引结构 (Vector Index Structures)
为了实现 ANN 高速查找,我们需要特定的数据结构来组织这些向量。这就好比为了让图书馆找书更快,我们需要建立索引卡片,而不是把书堆在地上。
目前业界最主流的三种索引结构如下:
1. HNSW (Hierarchical Navigable Small World) —— 图索引
这是目前性能最强、最流行的索引结构(也是多数向量数据库的默认首选)。
-
原理灵感:基于“六度分隔理论”。在这个网络图里,任何两个节点都可以通过很少的几次跳转连接起来。
-
结构形象化:
-
它像是一个多层的高速公路网(类似跳表 Skip List)。
-
顶层:节点稀疏,用于快速跨越,进行“粗定位”。
-
底层:节点密集,包含所有数据,用于“精细查找”。
-
-
搜索过程:从顶层开始,快速向目标方向“跳跃”,逐渐下沉,直到在底层找到目标。
-
优缺点:
-
✅ 查询极快,召回率高。
-
❌ 内存占用较高(需要存储复杂的图连接关系)。
-
2. IVF (Inverted File Index) —— 倒排聚类索引
这是经典的“分治法”思想,Faiss 库中常用的结构。
-
原理形象化:
-
将整个高维向量空间切分成许多个**“聚类桶” (Clusters/Buckets)**。
-
每个桶有一个中心点(Centroid)。
-
所有数据点根据距离,被归类到离它最近的那个桶里。
-
-
搜索过程:
-
先看查询向量离哪几个“中心点”最近。
-
只扫描这几个桶里的数据,忽略其他大部分数据。
-
-
优缺点:
-
✅ 内存占用较小,构建速度快。
-
❌ 存在边缘效应(如果目标点刚好在两个桶的边界,可能漏找),需要配置
nprobe参数来多探查几个桶。
-
3. 量化索引 (Quantization - PQ) —— 压缩优化
当数据量达到十亿级,内存存不下原始向量(Float32)时,就需要压缩技术。
-
PQ (Product Quantization,乘积量化):
-
原理:将一个高维的大向量切分成许多小段,每一小段用一个简短的代码(Code)来代替。
-
效果:可以将向量体积压缩几倍甚至几十倍,虽然精度会有所损失,但在海量数据场景下是性价比极高的选择。
-
四、 总结:OSS 向量 Bucket 的技术栈
为了方便理解,我们可以将上述技术整理为一个技术栈图谱。OSS 向量 Bucket 的底层正是通过封装这些技术,对外提供简单易用的服务:
| 层级 | 关键技术 | 作用 | 常见算法/示例 |
| 应用层 | 语义检索 / RAG | 解决实际业务问题 | 以文搜图、企业知识库 |
| 距离层 | Similarity Metrics | 定义数学上的“相似” | Cosine (余弦), Euclidean (欧氏) |
| 算法层 | ANN (近似搜索) | 解决速度问题 | HNSW (图结构), IVF (聚类倒排) |
| 压缩层 | Quantization | 解决内存与成本问题 | PQ (乘积量化) |
| 数据层 | Embeddings | 将数据数字化 | Transformer, BERT, 通义千问 |
理解了这些原理,你就会明白为什么 OSS 向量 Bucket 能在无需单独维护昂贵向量数据库实例的情况下,依然实现高效的 AI 检索能力。它是云原生架构下,存储与 AI 计算深度融合的典型产物。、

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)