GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
传统的机器人学习太依赖昂贵的机器人数据,难以扩展。GR-2借力打力,利用互联网上无穷无尽的人类视频,通过“预测未来画面”的预训练任务,让模型先学会物理世界的运作规律。在这个强大的“常识底座”上,只需喂给它少量的机器人数据,它就能迅速学会各种操作,并且即便换了环境、换了物体也能稳定工作。这为通用的具身智能(Embodied AI)指出了一条极具潜力的道路——从视频生成迈向机器人控制。
|
序号 |
属性 | 值 |
|---|---|---|
| 1 | 论文名称 | GR-2 |
| 2 | 发表时间/位置 | 2024 |
| 3 | Code | gr2-manipulation.github.io |
| 4 | 创新点 |
1:生成式 VLA (Video-Language-Action) GR-2 不仅仅预测动作,还预测未来视频画面。验证了“世界模型”假设——如果模型能生成准确的未来画面(理解物理规律、因果关系),它就能更准确地预测出导致该结果的动作。视频生成与动作预测是相辅相成的。 2:数据策略:互联网规模预训练 (Web-Scale Pre-training) 解决了机器人数据匮乏的痛点,实现了从“人类视频”到“机器人策略”的知识迁移。通过“看”海量人类视频学会物理常识,再通过少量机器人数据学会具体操作。 3:无损迁移的 GPT 风格架构 设计了两阶段训练(预训练 -> 微调)且保证知识无损(Lossless)迁移。 输入端:使用 VQGAN 将图像 Token 化(离散化),与文本 Token 一起输入 GPT。 输出端:自回归(Auto-regressive)预测下一帧 Token。 微调策略:冻结 VQGAN 和 Text Encoder,只训练线性层和部分参数,计算效率高(230M 参数,仅 95M 可训练)。 4:轨迹预测与 cVAE 放弃了“一步一动”的单步预测,转向长时程轨迹预测。 解决了多模态动作分布问题(同一个指令有多种合法抓法)。 生成的动作比单步预测更连贯、更平滑。 R-2 看了 3800 万条人类视频学会“脑补”未来画面(预训练),利用 VQGAN+GPT 架构结合 cVAE 生成平滑动作轨迹(微调),最后通过 WBC 算法精准控制机器人,实现了小数据量下的多任务高效泛化。 |
| 5 | 引用量 | 网络视频生成到机器人控制动作的生成。 |
一:提出问题
GR-2经历了大规模的互联网视频预训练,用于学习"Dynamics of the world"(世界动态/物理规律)。之后经历了机器人轨迹数据的多任务微调,同时进行视频生成和动作预测两个任务。GR-2 是一个通过海量互联网视频学会物理常识,再通过机器人数据学会具体操作的生成式模型,它不仅在已知任务上准确率极高,还能很好地适应陌生环境,且模型越大越强。
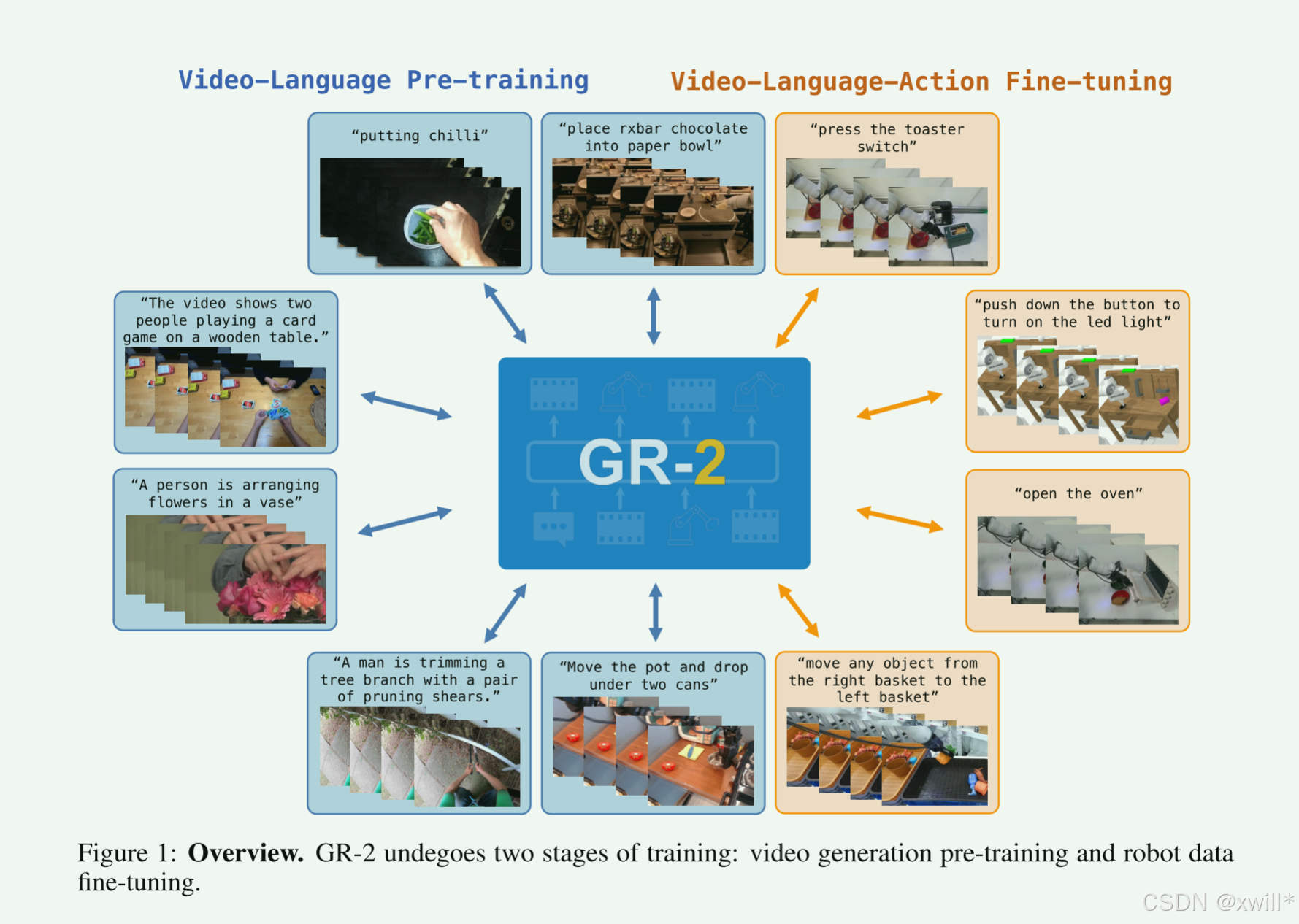
现在的 AI 在语言(GPT)、图像(Stable Diffusion)上都很强,因为有海量数据。但是机器人领域数据太少、太难收集(机器人不能像爬虫一样在网上爬数据,必须实体操作,效率低)。既然机器人数据少,那就先用人类视频数据。如果在视频上学会了“视频生成”(预测下一秒发生什么),就等于学会了“物理规律”和“因果关系”。把这个能力迁移给机器人,机器人就更容易学会怎么动。
GR-2 的核心机制视频生成即预训练。和 GPT 生成文本的逻辑一样。GPT 是根据上一个字预测下一个字;GR-2 是根据上一帧画面预测下一帧画面。例如:如果你能准确预测把杯子推倒后的画面,说明你理解了重力和碰撞。这种理解对机器人操作至关重要。经过训练后实现了:
-
每个任务只需要50次教学。
-
预训练数据规模庞大38M Videos / 50B Tokens ,属于“Web-Scale”(互联网规模),保证了模型的泛化能力。
总的来说有三个主要的贡献:
-
数据 (Data):量级大增(38M vs GR-1的小规模)。
-
架构 (Architecture):强调 "Lossless Transfer"(无损迁移)。这暗示了之前的架构可能在从“看视频”到“控制机器人”的转换中有信息丢失,新架构解决了这个问题。
-
控制 (Control):WBC(全身控制)。这说明 GR-2 不仅仅是电脑里的算法,还考虑了真机(Real Robot)落地的平稳性和实时性。
为了解决机器人数据匮乏的问题,GR-2 模仿 GPT 的思路,先看海量人类视频学会“预测未来画面”(预训练),再用少量机器人数据学会“控制动作”(微调),从而实现高效、通用的机器人操作。
二:解决方案
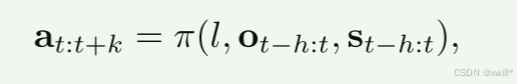
具体来说,文章要训练一个通用策略 π,它接收以下输入:语言指令 l、环境观测序列 ot−h:t、机器人状态序列 st−h:t。并且以端到端的形式输出动作轨迹at:t+k,其中h和k分别表示观测历史和动作轨迹的长度。
1.模型与训练
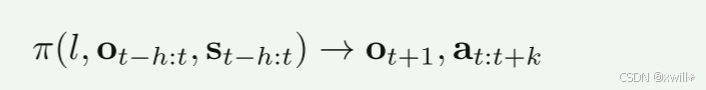
预训练阶段,在整理好的大规模视频数据集上训练 GR-2。之后,在机器人数据上对 GR-2 进行微调,使其能够串联地(in tandem)预测动作轨迹和视频。GR-2 的输入包含语言指令、视频帧序列和机器人状态序列。
-
使用冻结的文本编码器 [6] 对语言指令进行 Token 化(Tokenize)。
-
对于视频中的图像帧,使用 VQGAN [7] 将每张图像转换为离散的 Token。该 VQGAN 在大量互联网数据及领域内机器人数据上进行训练,并在 GR-2 的训练过程中保持冻结。这种方法有助于快速训练并支持高质量视频的生成。
-
机器人状态包含末端执行器(End-effector)的位置和旋转,以及夹爪的开合状态(二值)。这些状态通过线性层进行编码,该线性层在微调阶段是可训练的
主要的训练目标是赋予GR-2预测未来视频的能力,这使得模型能够建立对预测未来事件的强大先验(Prior),从而增强其做出准确动作预测的能力。该模型建立在 GPT 风格的 Transformer 之上,接收 Token 化的文本和图像序列作为输入,并输出未来图像的离散 Token。未来图像由 VQGAN 解码器从这些 Token 中解码出来。
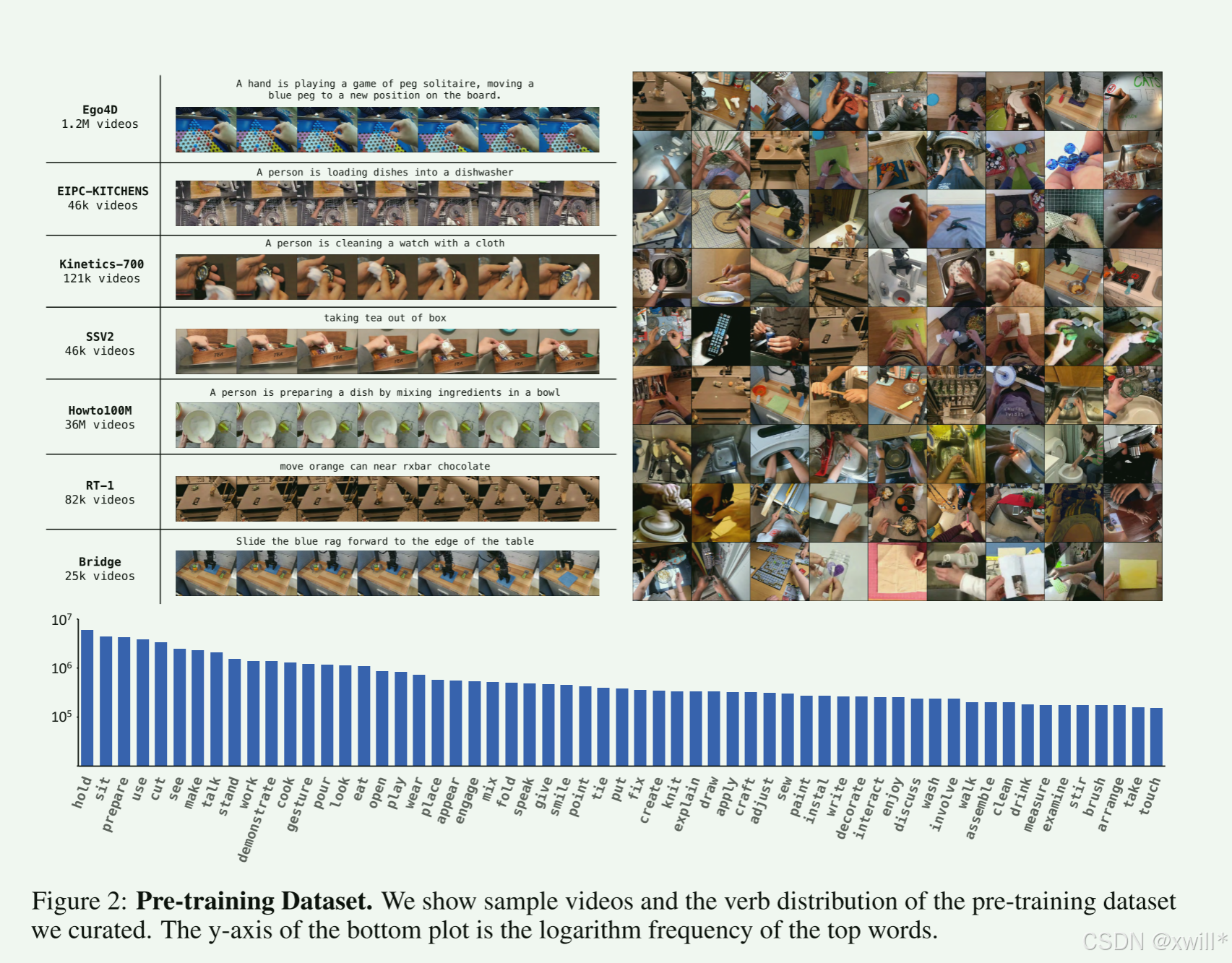
为了将预训练数据适配于机器人操纵任务,作者精心建立了一个数据处理流程,其中包括手部筛选(Hand filtering) 和重新标注(Re-captioning)。
阶段一:预训练 (Pre-training) -> 这里的关键是“预测未来”**
输入:当前画面 + 文本。
输出:下一帧画面。
逻辑:不教机器人怎么动,只教它“看视频”。如果它能画出下一秒的样子,说明它懂了物理规律(比如手推杯子,杯子会动)。
数据处理:特别提到了 Hand filtering(只保留有手的视频,因为机器人也是用“手”操作)和 Re-captioning(用大模型给视频重新写更准确的描述,提高数据质量)。
阶段二:微调 (Fine-tuning) -> 这里的关键是“动作对齐”
输入:当前画面 + 文本 + 机器人状态。
输出:下一帧画面 + 动作轨迹。
变化**:从单视角变成多视角(机器人通常有头顶和手腕两个相机)
文中提到:generating action trajectories rather than single-step actions。--也就是说生成的是一段轨迹而不是一个单步的动作。
单步:每 0.1 秒想一下下一步怎么动。容易抖动、卡顿。
轨迹:一次性规划未来 1 秒的一连串动作。
优势:动作更平滑 (Smoothness),且利于实时性 (Real-time)(算一次管好久)。
大模型生成的只是“我想去哪里”(笛卡尔空间坐标,比如 X,Y,Z),但机械臂有 7 个关节,具体每个关节转多少度?这就需要 WBC (Whole-Body Control)。
-
GR-2 (大脑):每秒运行几次,决定手大概往哪走。
-
WBC (小脑/脊髓--作者开发的算法):每秒运行 200 次 (200Hz),负责把大脑的指令瞬间翻译成 7 个电机的电流,同时保证不撞车(Collision constraints)。
GR-2 利用 VQGAN 将视频转化为 Token,通过 GPT 架构在海量人类视频上学会预测未来画面,再通过 cVAE 在机器人数据上学会生成平滑的动作轨迹,最后通过 WBC 算法将轨迹转化为高频的电机指令控制真机。
三:实验

作者设计了三种不同类型的实验,分别为了证明三个不同的论点:
-
一:多任务学习 (Multi-task Learning)
-
看点:GR-2 能否同时掌握 100 多种不同的家务技能(如倒水、擦桌子、叠衣服),而不是学会一个忘了另一个。
-
关键测试:OOD(Out-of-Distribution,分布外)。这指的是测试时故意把背景换了、物体颜色换了、或者摆放位置变了。如果模型还能成功,说明它是真懂,不是死记硬背。
-
-
二:料箱抓取 (Bin Picking)
-
看点:这是工业流水线最常见的需求。在一堆乱七八糟的东西(Cluster)里,准确抓起用户想要的那个。这考察的是视觉识别的精度和动作的细腻度。
-
-
三:CALVIN 基准测试
-
背景:真机实验每家实验室环境都不一样,很难公平对比。CALVIN 是一个开源的、标准化的仿真环境基准测试。
-
逻辑:在这个大家都公认的考场上跑个分,如果分数高,同行才会心服口服。
-
2. 模型参数的玄机 (230M vs 95M)
-
230M 参数:在 GPT-4 这种万亿参数模型面前,2.3 亿参数非常小(Lightweight)。这意味着 GR-2 的推理速度可能很快,适合部署在机器人这种算力有限的终端设备上。
-
95M 可训练 (Trainable):这说明 GR-2 采用了部分冻结 (Frozen) 的策略。
四:总结
传统的机器人学习太依赖昂贵的机器人数据,难以扩展。GR-2 借力打力,利用互联网上无穷无尽的人类视频,通过“预测未来画面”的预训练任务,让模型先学会物理世界的运作规律。在这个强大的“常识底座”上,只需喂给它少量的机器人数据,它就能迅速学会各种操作,并且即便换了环境、换了物体也能稳定工作。这为通用的具身智能(Embodied AI)指出了一条极具潜力的道路——从视频生成迈向机器人控制。
"Strong correlation between the generated video and the action predicted alongside"(生成的视频与预测的动作之间存在很强相关性)。----“脑补”能力(视频生成)有助于“动手”能力(动作预测)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)