LangChain 四种常用文档切分器的使用
文档拆分方法比较与实现 本文介绍了四种文档拆分方法及其应用场景: 字符拆分(CharacterTextSplitter):按固定字符数切分,简单高效但可能破坏语义完整性。 递归字符拆分(RecursiveCharacterTextSplitter):最常用方法,优先在自然语言边界(如段落、句子)处分割,通过递归尝试多种分隔符实现智能分段。 Token拆分(TokenTextSplitter):按T
0 为什么要拆分文档
当拿到统一的一个Document对象后,接下来需要切分成Chunks。如果不切分,而是考虑作为一个整体的Document对象,会存在两点问题:
- 假设提问的Query的答案出现在某一个Document对象中,那么将检索到的整个Document对象 直接放入Prompt中并不是最优的选择,因为其中一定会包含非常多无关的信息,而无效信息越多,对大模型后续的推理影响越大。
- 任何一个大模型都存在最大输入的Token限制,如果一个Document非常大,比如一个几百兆的 PDF,那么大模型肯定无法容纳如此多的信息。
基于此,一个有效的解决方案就是将完整的Document对象进行分块处(Chunking) 。无论是在存储还是检索过程中,都将以这些块(chunks) 为基本单位,这样有效地避免内容不相关性问题和超出最大输入限制的问题。
LangChain 中常用的文档切分器有CharacterTextSplitter、RecursiveCharacterTextSpl、TokenTextSplitter、SemanticChunker。以下将详细说明其使用。
1 CharacterTextSplitter(字符数分块)
1.1参数情况说明
| 参数 | 说明 |
|---|---|
| chunk_size | 每个切块的最大字符数,默认值为4000(由长度函数测量) |
| chunk_overlap | 相邻两个块之间的字符重叠数,避免信息在边界处被切断而丢失。默认值为200,通常会设置为chunk_size的10% - 20% |
| length_function | 用于测量给定块字符数的函数,默认值为len函数。len函数在Python中按Unicode字符计数,所以一个汉字、一个英文字母、一个符号都算一个字符 |
| keep_seperator | 是否在块中保留分隔符,默认为False |
| add_start_index | 如果为True,则在元数据中包含块的起始索引,默认值为False |
| strip_whitespace | 如果为True,则从每个文档的开始和结束处去除空白字符,默认值为True |
1.2代码示例
from langchain_text_splitters import CharacterTextSplitter
# 示例文本
text = """
LangChain 是一个用于开发由语言模型驱动的应用程序的框架的。它提供了一套工具和抽象,使开发者
能够容易地构建复杂的应用程序"""
# 定义字符分割器
splitter = CharacterTextSplitter(
chunk_size=50, # 每块大小
chunk_overlap=5, # 块与块之间的重复字符数
separator="" #为空串表示无需分隔符
)
# 分割文本
split_text = splitter.split_text(text)
# 打印结果
for i,chunk in enumerate(split_text):
print(f"第{i + 1}块,长度:{len(chunk)}")
print(chunk)
print("-" * 50)
1.3运行结果
第一块的长度为49,小于设置的最大长度,因为separator="",不使用分隔符就会导致实际长度略小于chunk_size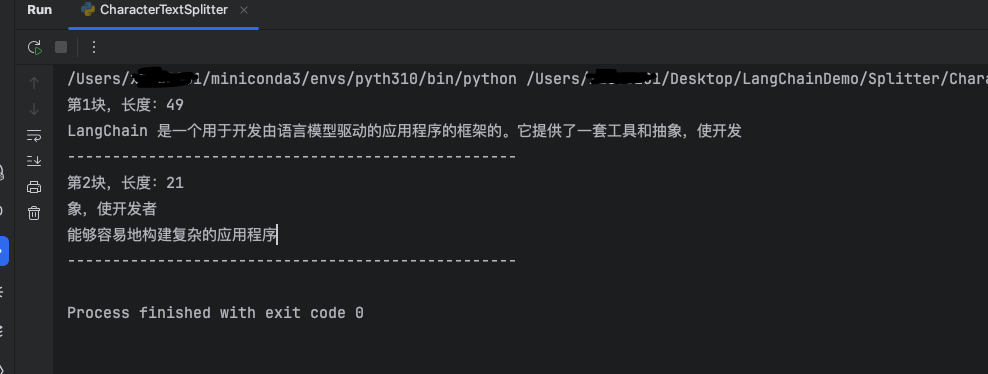
2 RecursiveCharacterTextSplitter(最常用)
文档切分器中较常用的是RecursiveCharacterTextSplitter(递归字符文本切分器),遇到特定字符时进行分割。默认情况下,它尝试进行切割的字符包括[“\n\n”, “\n”, " ", “”]。
具体为:根据第一个字符进行切块,但如果任何切块太大,则会继续移动到下一个字符继续切块,以此 类推。
此外,还可以考虑添加,。等分割字符。
2.1 特点
保留上下文:优先在自然语言边界(如段落、句子结尾)处分割,减少信息碎片化 。
智能分段:通过递归尝试多种分隔符,将文本分割为大小接近chunk_size的片段。
灵活适配:适用于多种文本类型(代码、Markdown、普通文本等),是LangChain中 最通用的文本拆分器。
2.2 示例代码
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 示例文本
text = """
LangChain是,一个用于开发由语言模型驱动\n的应用程序的框架\n\n的。它提供了一套工具和抽象,使开发者
能够容易地构建复杂的应用程序"""
# 定义字符分割器
splitter = RecursiveCharacterTextSplitter(
chunk_size=20, # 每块大小
chunk_overlap=5, # 块与块之间的重复字符数
)
# 分割文本
split_text = splitter.split_text(text)
# 打印结果
for i,chunk in enumerate(split_text):
print(f"第{i + 1}块,长度:{len(chunk)}")
print(chunk)
print("-" * 50)
2.3 运行结果
默认按照[“\n\n”, “\n”, " ", “”]中的分隔符来递归分隔,也可自主定义separators, 但是会有覆盖效果,即只根据自定义的separators中的分隔符来进行分隔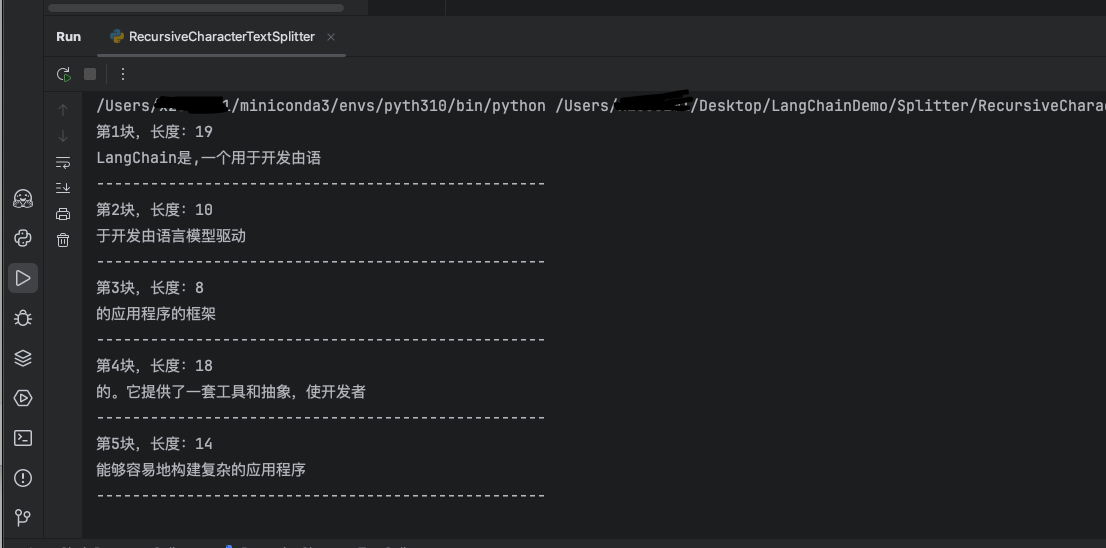
3 TokenTextSplitter(Token分块)
当我们将文本拆分为块时,除了字符以外,还可以: 按Token的数量分割 (而非字符或单词数),将长文本切分成多个小块。
特点:
- 核心依据:Token数量 + 自然边界。(TokenTextSplitter 严格按照 token 数量进行分割,但同时 会优先在自然边界(如句尾)处切断,以尽量保证语义的完整性。)
- 优点:与LLM的Token计数逻辑一致,能尽量保持语义完整 缺点:对非英语或特定领域文本,Token化效果可能不佳
- 典型场景:需要精确控制Token数输入LLM的场景
3.1 代码示例
from langchain_text_splitters import TokenTextSplitter
# 示例文本
text = """
LangChain是,一个用于开发由语言模型驱动的应用程序的框架的。它提供了一套工具和抽象,使开发者
能够容易地构建复杂的应用程序"""
# 定义字符分割器
splitter = TokenTextSplitter(
chunk_size=20, # 每块大小
chunk_overlap=0, # 块与块之间的重复字符数
encoding_name="cl100k_base"
)
# 分割文本
split_text = splitter.split_text(text)
# 打印结果
for i,chunk in enumerate(split_text):
print(f"第{i + 1}块,长度:{len(chunk)}")
print(chunk)
print("-" * 50)
3.2 运行结果
我们发现第一块的长度就超出了我们所设定的20,这是因为字符长度并不等于Token数量,我们这里设置的chunk_size为token数量,而一个Token可能是由几个字符组成的。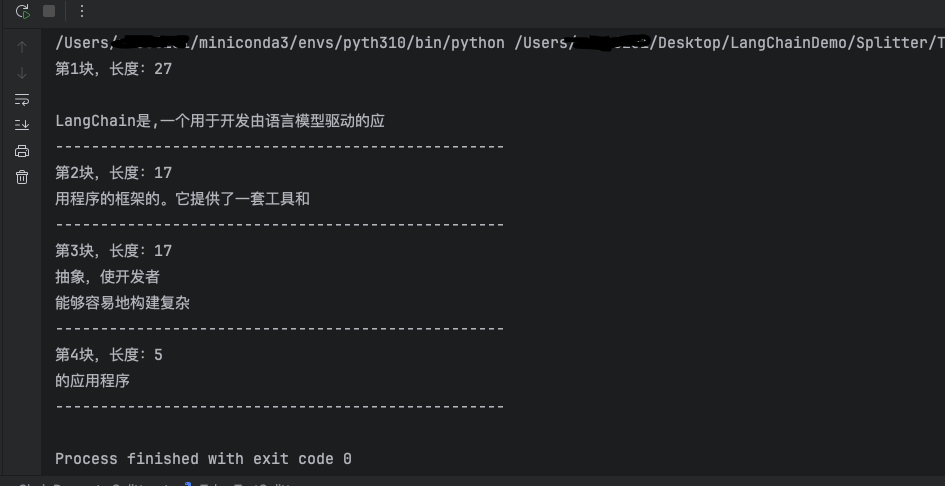
4 SemanticChunker(语义分块)
SemanticChunking(语义分块)是 LangChain 中一种更高级的文本分割方法,它超越了传统的基于字符或固定大小的分块方式,而是根据文本的语义结构进行智能分块,使每个分块保持语义完整性 ,从而提高检索增强生成(RAG)等应用的效果。
4.1 语义分割和普通分割的对比
| 特性 | 语义分割(SemanticChunker) | 传统字符分割(RecursiveCharacterTextSplitter) |
|---|---|---|
| 分割依据 | 嵌入向量相似度 | 固定字符/换行符以及最大字符数 |
| 语义完整性 | 连贯完整 | 句子逻辑可能不完整 |
| 计算成本 | 高(需要嵌入模型计算) | 低 |
| 适用场景 | 需要高语义一致性的任务 | 简单文本处理 |
语义分割是需要使用嵌入模型进行计算的,是需要消耗算力的,所以使用成本比普通的分割要高,所以适用于对语义完整性高的场景。
4.2 示例代码
尝试了很久始终无法正常切割文本,始终只能得到一整块文本,使用了Qwen系列的文本嵌入模型和本地部署的nomic-embed-text模型都不能解决,只能是放弃了,也许使用OpenAi的模型有用,但是我的账户没有余额就不尝试了
import dotenv
from langchain_experimental.text_splitter import SemanticChunker
from langchain_ollama import OllamaEmbeddings
dotenv.load_dotenv()
with open("split_text", encoding="utf-8") as f:
split_text = f.read()
embeddings_model = OllamaEmbeddings(
model="nomic-embed-text:latest",
)
text_splitter = SemanticChunker(
embeddings=embeddings_model,
breakpoint_threshold_type="percentile",
breakpoint_threshold_amount=1,
)
docs = text_splitter.create_documents(texts=[split_text])
print(f"📊 总块数: {len(docs)}\n")
for i, doc in enumerate(docs, 1):
content = doc.page_content
print(f"⚡️ Chunk {i} ({len(content)} 字符):")
print("-" * 60)
if len(content) > 250:
print(f"{content[:150]}...\n...{content[-100:]}")
else:
print(content)
print()
4.3 输出结果
大模型没有很好地按语义切割文本,可能是使用的模型问题。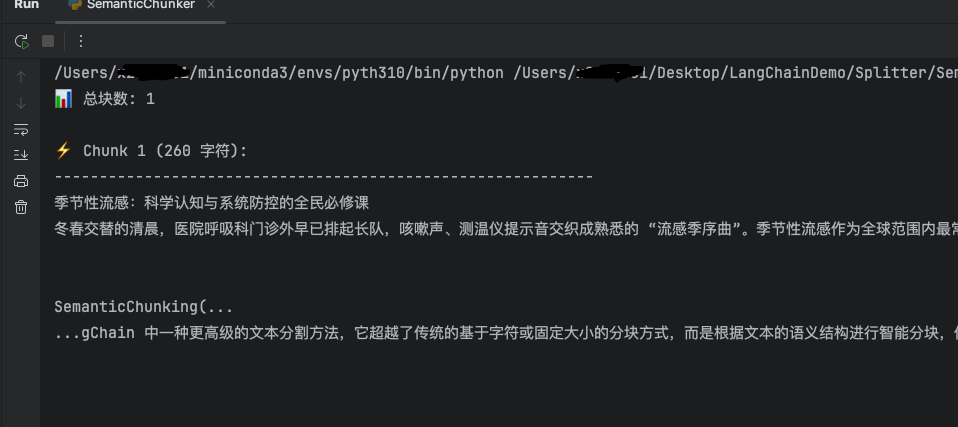
LangChain官网的对话助手询问了文本切割方法,ai只回答了上述三种常用的切割方法,并没有提到基于语义的方式,接着继续提问,回答说这个SemanticChunker目前还属于实验性方法,不太稳定,并不是很推荐使用。最推荐的还是RecursiveCharacterTextSplitter方法。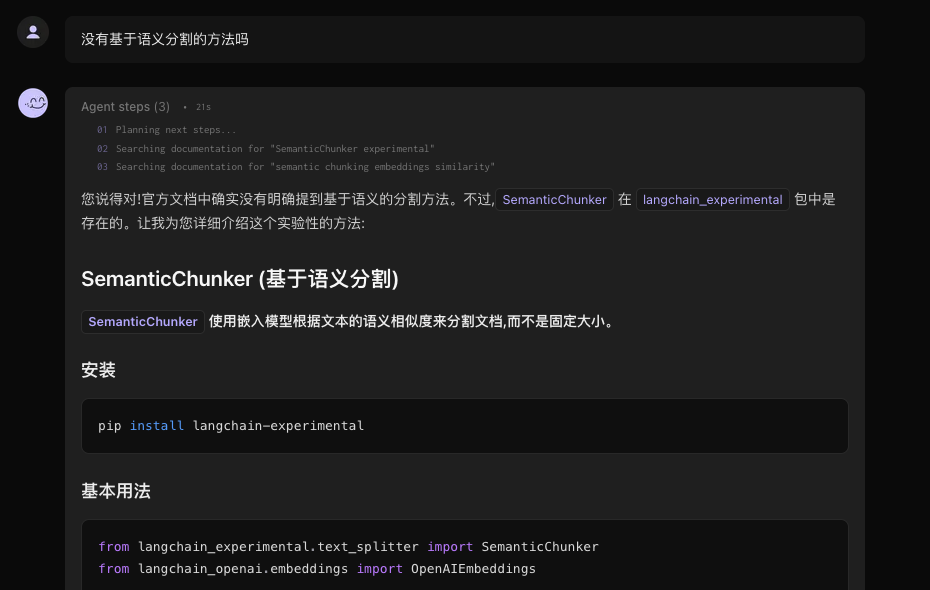
5 小结
尝试了很久SemanticChunker,一直都不能成功,总是只切割为一份,最后放弃了,有个了解就行了,重点掌握RecursiveCharacterTextSplitter的使用就好了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)