收藏!大模型训练秘籍:Tokenizer详解到小型LLM预练全流程
文章详细介绍了大语言模型的训练流程,重点讲解了Tokenizer的三种分词方法及BPE等算法实现。提供了从数据预处理、模型训练到微调,使用Seq-Monkey和BelleGroup数据集训练8000万参数中文大模型。通过PretrainDataset和SFTDataset两种数据集格式,实现了模型从语言学习到对话能力的训练过程,最后展示了模型文本生成方法。
2 训练 Tokenizer
在自然语言处理(NLP)中,计算机要想理解人类的语言,第一步就是——分词(Tokenization)。
简单来说,分词的作用就是把一整段文字拆分成一个个更小的单位,称为 token。
这些 token 可以是单词、子词、字符,甚至标点符号。
就像人类阅读时会自然地停顿和识别单词一样,计算机也需要这种“切割”过程,才能更好地理解文本的结构和含义。
根据任务的不同,分词的方式也不一样。接下来我们来看看几种常见的分词方法,以及它们各自的优缺点。
🔹 2.1 Word-based Tokenizer “按词切割”的老派方法
思路:
最直观的做法,就是按照空格和标点把句子切成单词。
比如:
输入:
"Hello, world! There is Datawhale."
输出:
["Hello", ",", "world", "!", "There", "is", "Datawhale", "."]
优点:
- 简单、直观,人类一看就懂。
- 实现成本低,速度快。
缺点:
- 对未知词(没见过的新词)无能为力,比如“Datawhale”这种词。
- 对复合词(如 “New York”)或缩写(如 “don’t”)的处理不够精准。
- 对中文、日文等没有空格的语言几乎无能为力。
👉 总的来说,Word-based Tokenizer 就像一个基础版本的“剪刀手”,能完成最简单的切割任务,但面对复杂语言结构时就力不从心了。
🔹 2.2 Character-based Tokenizer “逐字切割”的细致派
思路:
这种方法干脆不管词的边界,直接把每个字符都当作一个 token。
例如:
输入: "Hello"
输出: ["H", "e", "l", "l", "o"]
优点:
- 永远不会出现“没见过的词”这种问题。
- 对拼写错误、新词或混合语言都能灵活处理。
缺点:
- 分出来的 token 太多,句子会变得“超长”。
- 丢失词级语义,模型要靠更大的计算量去理解上下文。
👉 Character-based 方法就像一台显微镜,能看清语言的“细胞”,但要理解整句话的含义,往往要付出更高的计算代价。
🔹 2.3 Subword Tokenizer “词与字之间”的聪明平衡
Subword(子词)分词是一种折中思路。
它既不像 Word-based 那样粗糙,也不像 Character-based 那样碎片化。
它会把一个单词拆成若干“子词单元”,这些子词既能代表语义,又能组合成新词。
这让它在处理新词时既灵活,又保留了足够的上下文信息。
常见的子词分词算法包括 BPE、WordPiece 和 Unigram。下面分别介绍👇
(1)Byte Pair Encoding (BPE)
BPE 是最常用的子词分词算法之一。
它通过一种“统计合并”的方式:
- 先从字符开始。
- 每次找到出现频率最高的相邻字符对,并把它们合并成一个新的子词。
- 不断重复,直到生成预定大小的词典。
示例:
输入: "lower" → 输出: ["low", "er"]
输入: "newest" → 输出: ["new", "est"]
这样,BPE 能捕捉到“词根+词缀”的结构,比如 “new+est”,
从而在面对新词时,也能用已有的子词组合出来。
👉 BPE 就像一位“语言拼图大师”,从最常见的碎片开始拼出词汇世界。
(2)WordPiece
WordPiece 是谷歌为 BERT 模型设计的分词方法。
它的思路与 BPE 类似,但更加“智能”,它不是只看出现频率,而是选择能让语言模型整体概率最高的子词。
示例:
输入: "unhappiness"
输出: ["un", "##happiness"]
其中 “##” 表示后缀子词。
这种设计让模型知道,“##happiness”并不是一个独立单词,而是接在 “un” 后的部分。
👉 WordPiece 相当于在 BPE 的基础上加了“语义权重”,让分词更符合语言逻辑。
(3)Unigram
Unigram 使用的是概率模型。
它为每个子词分配一个概率,然后选择能让整句概率最高的分词方式。
示例:
输入: "unhappiness"
→ 输出: ["un", "happiness"]
输入: "newest" → 输出: ["new", "est"]
Unigram 的优势在于它的灵活性和多语言适应性,特别适合在多语种语料中训练。
👉 它更像是一位“语言学家”,基于统计规律,选择最自然的分词结果。
2.2 训练一个 Tokenizer
2.2.1 使用 BPE 训练一个自定义 Subword Tokenizer
在自然语言处理中,Tokenizer(分词器) 是模型理解文字的第一步。
在上一节我们提到,Subword Tokenizer 结合了“按词分”和“按字分”的优点,既能处理新词,又能保留语义信息。
这一节我们将通过一个完整的实例,带你使用 BPE (Byte Pair Encoding) 算法训练一个自己的分词器。
🪜 Step 1:安装依赖库
我们使用的是 Hugging Face 的 tokenizers 库,它专门为高性能分词任务设计。
此外,我们还会用到 datasets 和 transformers 库,用于加载数据和后续测试。
pip install tokenizers datasets transformers
然后在 Python 中导入相关模块:
from tokenizers.normalizers import NFKC
from typing import Generator
import random
import json
import os
from transformers import AutoTokenizer, PreTrainedTokenizerFast
from tokenizers import (
decoders,
models,
pre_tokenizers,
trainers,
Tokenizer,
)
📚 Step 2:加载训练数据
为了让分词器学习语言规律,我们需要提供大量的文本。
在这里,我们使用“出门问问(TuringMonkeys)”的开源语料数据集。
由于数据量较大,我们只需取其中一部分作为示例即可。
def read_texts_from_jsonl(file_path: str) -> Generator[str, None, None]:
"""读取 JSONL 文件并提取文本内容"""
with open(file_path, 'r', encoding='utf-8') as f:
for line_num, line in enumerate(f, 1):
try:
data = json.loads(line)
if 'text' not in data:
raise KeyError(f"Missing 'text' field in line {line_num}")
yield data['text']
except json.JSONDecodeError:
print(f"Error decoding JSON in line {line_num}")
except KeyError as e:
print(e)
✅ 小贴士:
如果你的机器内存不够,可提前手动抽取一小部分语料进行训练。
教学目的下几万条数据就足够了。
⚙️ Step 3:创建 Tokenizer 配置文件
一个完整的分词器除了“词典”,还需要一份配置文件告诉模型如何使用它。
我们需要两个文件:
tokenizer_config.json:分词器的参数定义。special_tokens_map.json:定义特殊标记(如句子开头、结尾、未知词等)。
def create_tokenizer_config(save_dir: str) -> None:
"""创建 tokenizer 配置文件"""
config = {
"add_bos_token": False,
"add_eos_token": False,
"add_prefix_space": False,
"bos_token": "<|im_start|>",
"eos_token": "<|im_end|>",
"pad_token": "<|im_end|>",
"unk_token": "<unk>",
"model_max_length": 1e30,
"tokenizer_class": "PreTrainedTokenizerFast",
"chat_template": (
"{% for message in messages %}"
"{% if message['role'] == 'system' %}"
"<|im_start|>system\n{{ message['content'] }}<|im_end|>\n"
"{% elif message['role'] == 'user' %}"
"<|im_start|>user\n{{ message['content'] }}<|im_end|>\n"
"{% elif message['role'] == 'assistant' %}"
"<|im_start|>assistant\n{{ message['content'] }}<|im_end|>\n"
"{% endif %}"
"{% endfor %}"
"{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
)
}
# 保存配置文件
os.makedirs(save_dir, exist_ok=True)
with open(os.path.join(save_dir, "tokenizer_config.json"), "w", encoding="utf-8") as f:
json.dump(config, f, ensure_ascii=False, indent=4)
# 特殊 token 定义
special_tokens_map = {
"bos_token": "<|im_start|>",
"eos_token": "<|im_end|>",
"unk_token": "<unk>",
"pad_token": "<|im_end|>",
"additional_special_tokens": ["<s>", "</s>"]
}
with open(os.path.join(save_dir, "special_tokens_map.json"), "w", encoding="utf-8") as f:
json.dump(special_tokens_map, f, ensure_ascii=False, indent=4)
这些特殊 token 用于标记:
- 句子开头
<|im_start|> - 句子结束
<|im_end|> - 未知词
<unk> - 模型输入填充
<pad>
这样模型在训练时能“看懂”句子的结构。
🔧 Step 4:训练 BPE Tokenizer
核心部分来了!我们开始训练分词器 👇
def train_tokenizer(data_path: str, save_dir: str, vocab_size: int = 8192) -> None:
"""训练并保存自定义 BPE Tokenizer"""
os.makedirs(save_dir, exist_ok=True)
tokenizer = Tokenizer(models.BPE(unk_token="<unk>"))
tokenizer.normalizer = NFKC()
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=False)
tokenizer.decoder = decoders.ByteLevel()
# 特殊 token
special_tokens = ["<unk>", "<s>", "</s>", "<|im_start|>", "<|im_end|>"]
trainer = trainers.BpeTrainer(
vocab_size=vocab_size,
special_tokens=special_tokens,
min_frequency=2,
show_progress=True,
initial_alphabet=pre_tokenizers.ByteLevel.alphabet()
)
print(f"Training tokenizer with data from {data_path}")
texts = read_texts_from_jsonl(data_path)
tokenizer.train_from_iterator(texts, trainer=trainer, length=os.path.getsize(data_path))
tokenizer.save(os.path.join(save_dir, "tokenizer.json"))
create_tokenizer_config(save_dir)
print(f"Tokenizer saved to {save_dir}")
💡 说明:
vocab_size=8192表示我们希望生成 8192 个子词。ByteLevel能很好地处理各种字符集(尤其是中文和表情符号)。- 训练完成后会在目标目录生成三个文件:
tokenizer.json、tokenizer_config.json、special_tokens_map.json。
🧪 Step 5:加载并测试 Tokenizer
我们可以使用训练好的 Tokenizer 来看看效果:
def eval_tokenizer(tokenizer_path: str) -> None:
"""评估 tokenizer 功能"""
tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
print("\n=== Tokenizer基本信息 ===")
print(f"Vocab size: {len(tokenizer)}")
print(f"Special tokens: {tokenizer.all_special_tokens}")
print(f"Special token IDs: {tokenizer.all_special_ids}")
messages = [
{"role": "system", "content": "你是一个AI助手。"},
{"role": "user", "content": "How are you?"},
{"role": "assistant", "content": "I'm fine, thank you. and you?"},
{"role": "user", "content": "I'm good too."},
{"role": "assistant", "content": "That's great to hear!"},
]
print("\n=== 聊天模板测试 ===")
prompt = tokenizer.apply_chat_template(messages, tokenize=False)
print("Generated prompt:\n", prompt, sep="")
print("\n=== 编码解码测试 ===")
encoded = tokenizer(prompt, truncation=True, max_length=256)
decoded = tokenizer.decode(encoded["input_ids"], skip_special_tokens=False)
print("Decoded text matches original:", decoded == prompt)
print("\n=== 特殊token处理 ===")
test_text = "<|im_start|>user\nHello<|im_end|>"
encoded = tokenizer(test_text).input_ids
decoded = tokenizer.decode(encoded)
print(f"Original: {test_text}")
print(f"Decoded: {decoded}")
print("Special tokens preserved:", decoded == test_text)
运行结果如下:
=== Tokenizer基本信息 ===
Vocab size: 6144
Special tokens: ['<|im_start|>', '<|im_end|>', '<unk>', '<s>', '</s>']
Special token IDs: [3, 4, 0, 1, 2]
=== 聊天模板测试 ===
<|im_start|>system
你是一个AI助手。<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
I'm fine, thank you. and you?<|im_end|>
...
虽然部分空格或特殊符号在解码时有轻微偏差(例如多出空格),但整体逻辑是正确的。
这是因为 ByteLevel Tokenizer 在还原空格时的行为稍有不同,可以在后续阶段通过调整
add_prefix_space
等参数来优化。
3 预训练一个小型LLM
3.1 训练一个 8,000 万参数的大语言模型
在前面的章节中,我们已经了解了大语言模型(LLM)的核心结构,以及 Tokenizer 的作用和训练方式。现在,是时候亲自动手实践了——这一节我们将带你完成一个实战:训练一个拥有约 8,000 万参数的中文大模型。
3.1.1 数据下载与处理
训练一个语言模型,首先要有大量的文本数据。这里我们选用了两个常用的中文开源数据集,它们为模型提供了丰富的语料来源。
📘 数据集 1:Seq-Monkey
这是一个综合性中文文本语料库,来源包括网页、百科、问答、博客、书籍、代码、试题等。
经过清洗和筛选后,它包含了大约 100 亿 Token 的通用中文语料,非常适合作为预训练数据集。
💬 数据集 2:BelleGroup 中文对话数据集
BelleGroup 数据集包含约 350 万条对话样本,覆盖了人机对话、人物对话等多种形式。
这类数据非常适合用于模型的 指令微调(SFT, Supervised Fine-Tuning),帮助模型学会如何与人自然交流。
🧩 下载与解压数据
我们可以直接通过命令行工具下载并解压数据:
# 下载预训练语料(出门问问序列猴子)
os.system("modelscope download --dataset ddzhu123/seq-monkey mobvoi_seq_monkey_general_open_corpus.jsonl.tar.bz2 --local_dir your_local_dir")
# 解压数据
os.system("tar -xvf your_local_dir/mobvoi_seq_monkey_general_open_corpus.jsonl.tar.bz2")
# 下载 BelleGroup 对话数据
os.system("huggingface-cli download --repo-type dataset --resume-download BelleGroup/train_3.5M_CN --local-dir BelleGroup")
🧹 数据预处理
原始语料往往篇幅较长,我们需要将文本切分成较短的片段,以便模型训练:
def split_text(text, chunk_size=512):
return [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)]
然后将所有文本转为统一格式:
with open('seq_monkey_datawhale.jsonl', 'a', encoding='utf-8') as pretrain:
with open('mobvoi_seq_monkey_general_open_corpus.jsonl', 'r', encoding='utf-8') as f:
for line in tqdm(f, desc="Processing"):
text = json.loads(line)['text']
for chunk in split_text(text):
pretrain.write(json.dumps({'text': chunk}, ensure_ascii=False) + '\n')
对话数据也需要转换为标准格式(system / user / assistant):
def convert_message(data):
message = [{"role": "system", "content": "你是一个AI助手"}]
for item in data:
role = 'user' if item['from'] == 'human' else 'assistant'
message.append({'role': role, 'content': item['value']})
return message
3.1.2 训练 Tokenizer
在模型训练前,我们需要一个 Tokenizer 来把文本转为模型能理解的数字序列。
这里我们会自己训练一个 BPE(Byte Pair Encoding) 分词器。
💡 提示:数据集较大,训练时间较长。如果你的设备性能有限,可以直接使用提供的预训练 Tokenizer。
🧠 Tokenizer 的训练思路
Tokenizer 的目标是:
把每一段文本拆分成一组「词单元」,并为每个单元分配唯一编号。
BPE 模型会从单个字符开始,逐步合并出现频率最高的字符组合,从而得到稳定、高效的子词词表。
from tokenizers import Tokenizer, models, trainers, pre_tokenizers, decoders
from tokenizers.normalizers import NFKC
import os, json
def train_tokenizer(data_path, save_dir, vocab_size=6144):
os.makedirs(save_dir, exist_ok=True)
tokenizer = Tokenizer(models.BPE(unk_token="<unk>"))
tokenizer.normalizer = NFKC()
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=False)
tokenizer.decoder = decoders.ByteLevel()
special_tokens = ["<unk>", "<s>", "</s>", "<|im_start|>", "<|im_end|>"]
trainer = trainers.BpeTrainer(
vocab_size=vocab_size,
special_tokens=special_tokens,
min_frequency=2
)
# 从数据中训练词表
with open(data_path, 'r', encoding='utf-8') as f:
texts = (json.loads(line)['text'] for line in f)
tokenizer.train_from_iterator(texts, trainer=trainer)
tokenizer.save(os.path.join(save_dir, "tokenizer.json"))
print(f"✅ Tokenizer 已保存到 {save_dir}")
🧪 Tokenizer 测试
训练完成后,我们可以测试它是否正常工作:
tokenizer = AutoTokenizer.from_pretrained("tokenizer_k")
print("=== Tokenizer 基本信息 ===")
print("词表大小:", len(tokenizer))
print("特殊符号:", tokenizer.all_special_tokens)
messages = [
{"role": "system", "content": "你是一个AI助手。"},
{"role": "user", "content": "你好呀!"},
{"role": "assistant", "content": "你好,很高兴见到你。"}
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False)
print("\n=== 生成的 Prompt ===")
print(prompt)
🧭 预期输出示例
=== Tokenizer基本信息 ===
Vocab size: 6144
Special tokens: ['<|im_start|>', '<|im_end|>', '<unk>', '<s>', '</s>']
Special token IDs: [3, 4, 0, 1, 2]
=== 聊天模板测试 ===
<|im_start|>system
你是一个AI助手。<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
I'm fine, thank you. and you?<|im_end|>
💬 说明:如果出现 Decoded text matches original: False,这是因为在解码过程中,Tokenizer 可能自动插入空格或规范化符号。这属于正常现象,不影响训练效果。
3.2 Dataset数据集格式
在模型真正开始训练之前,我们还需要做一件非常关键的事,就是把原始文本数据转化成模型能理解的数字形式(Token)。
在 PyTorch 中,这一步通常是通过自定义的 Dataset 类来实现的。
本节我们将介绍两个核心数据集类:
PretrainDataset:用于大模型的无监督预训练阶段- SFTDataset: 用于模型的指令微调(Supervised Fine-Tuning, SFT)阶段
🧩 一、PretrainDataset:教模型“读懂世界”的第一步
在预训练阶段,我们希望模型学习到语言的基础规律,比如:
哪些词经常连在一起出现?
一句话里哪些语法结构更自然?
为此,我们会用大规模语料(例如前面下载的“出门问问序列猴子”数据)去训练模型。
下面我们通过自定义的 PretrainDataset 类,把文本数据处理成模型可以直接使用的格式。
from torch.utils.data import Dataset
class PretrainDataset(Dataset):
def __init__(self, data_path, tokenizer, max_length=512):
super().__init__()
self.data_path = data_path
self.tokenizer = tokenizer
self.max_length = max_length
self.padding = 0
with open(data_path, 'r', encoding='utf-8') as f:
self.data = f.readlines()
def __len__(self):
return len(self.data)
def __getitem__(self, index: int):
sample = json.loads(self.data[index])
text = f"{self.tokenizer.bos_token}{sample['text']}"
input_id = self.tokenizer(text).data['input_ids'][:self.max_length]
text_len = len(input_id)
padding_len = self.max_length - text_len
input_id = input_id + [self.padding] * padding_len
loss_mask = [1] * text_len + [0] * padding_len
input_id = np.array(input_id)
X = np.array(input_id[:-1]).astype(np.int64)
Y = np.array(input_id[1:]).astype(np.int64)
loss_mask = np.array(loss_mask[1:]).astype(np.int64)
return torch.from_numpy(X), torch.from_numpy(Y), torch.from_numpy(loss_mask)
🧠 工作原理解析
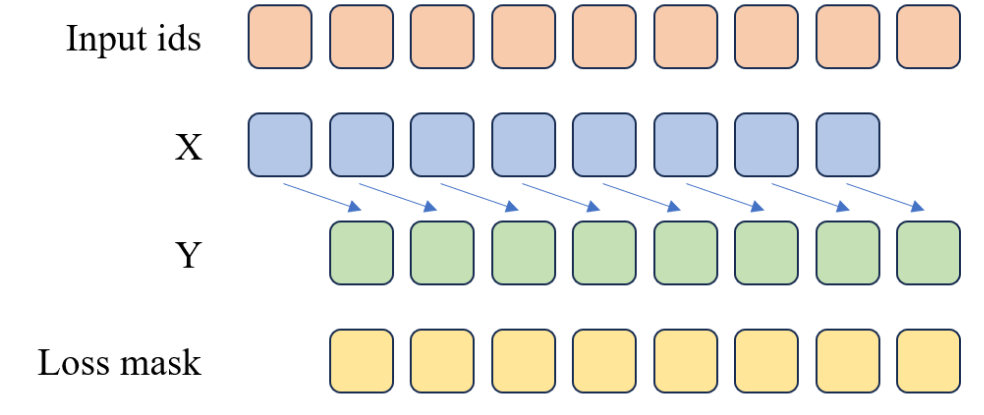
可以把 PretrainDataset 想象成一个“文字打碎机”,它会把每一条文本都切分成固定长度的数字序列(Token ID),然后再组合成模型的输入与输出。
- 输入 X:前
n-1个 Token - 目标 Y:后
n-1个 Token - loss_mask:标记哪些 Token 需要计算损失
比如,假设我们设置 max_length = 9,模型的输入序列为:
输入序列: [BOS, T1, T2, T3, T4, T5, T6, T7, EOS]
经过切分后:
| 项目 | 内容 | 说明 |
|---|---|---|
| X | [BOS, T1, T2, T3, T4, T5, T6, T7] | 模型输入(上下文) |
| Y | [T1, T2, T3, T4, T5, T6, T7, EOS] | 模型预测目标 |
| loss_mask | [0, 1, 1, 1, 1, 1, 1, 1, 1] | 仅对有效词计算损失 |
在训练时,模型会学习如何根据前文预测下一个 Token。
这正是语言模型最核心的训练逻辑。
💬 二、SFTDataset:教模型“学会聊天”
当模型通过预训练掌握了语言规律后,它还需要学会与人交流。
这一步就是所谓的 SFT(Supervised Fine-Tuning,监督式微调)。
在这个阶段,我们使用对话类数据(如 BelleGroup 数据集)来教模型如何按照人类意图进行回答。
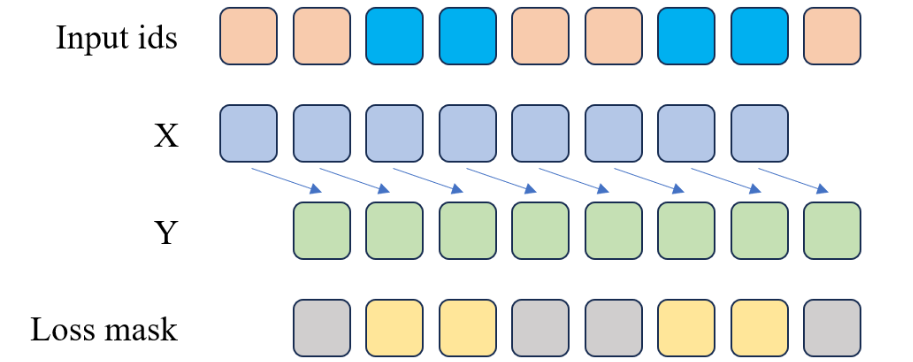
class SFTDataset(Dataset):
def __init__(self, data_path, tokenizer, max_length=512):
super().__init__()
self.data_path = data_path
self.tokenizer = tokenizer
self.max_length = max_length
self.padding = 0
with open(data_path, 'r', encoding='utf-8') as f:
self.data = f.readlines()
def __len__(self):
return len(self.data)
def generate_loss_mask(self, input_ids):
# 生成 loss mask, 1 表示计算损失, 0 表示跳过
mask = [0] * len(input_ids)
a_sequence = [3, 1074, 537, 500, 203] # 即 <|im_start|>assistant\n
a_length = len(a_sequence)
n = len(input_ids)
i = 0
while i <= n - a_length:
match = all(input_ids[i + k] == a_sequence[k] for k in range(a_length))
if match:
# 找到对应的 <|im_end|>
for j in range(i + a_length, n):
if input_ids[j] == 4: # 4 表示 <|im_end|>
for pos in range(i + a_length, j + 1):
mask[pos] = 1
break
i += a_length
else:
i += 1
return mask
def __getitem__(self, index: int):
sample = json.loads(self.data[index])
text = self.tokenizer.apply_chat_template(sample, tokenize=False, add_generation_prompt=False)
input_id = self.tokenizer(text).data['input_ids'][:self.max_length]
text_len = len(input_id)
padding_len = self.max_length - text_len
input_id = input_id + [self.padding] * padding_len
loss_mask = self.generate_loss_mask(input_id)
input_id = np.array(input_id)
X = np.array(input_id[:-1]).astype(np.int64)
Y = np.array(input_id[1:]).astype(np.int64)
loss_mask = np.array(loss_mask[1:]).astype(np.int64)
return torch.from_numpy(X), torch.from_numpy(Y), torch.from_numpy(loss_mask)
🧩 原理讲解
SFT 数据与预训练数据的结构很相似,
区别在于我们只希望模型学习 AI 助手的回答部分。
为此,我们定义了一个 generate_loss_mask() 函数。
它的逻辑是:
每当检测到
<|im_start|>assistant\n这个标志,就开始计算损失;
一直持续到<|im_end|>停止。
这样,模型只在回答内容部分(即 AI 的输出)进行学习,而不会对用户输入部分计算梯度。
可以把它想象成这样👇:
| 内容 | 是否计算损失 |
|---|---|
| 用户提问 | ❌ 不计算 |
| AI 回答 | ✅ 计算 |
在图示中,蓝色区域代表 AI 的回答部分,对应到 loss_mask 中的黄色方块(标记为 1),
而灰色部分则被标记为 0,不参与训练。
🧭 总结一下
| 模型阶段 | 数据集类 | 学习目标 | 损失计算范围 |
|---|---|---|---|
| 预训练(Pretrain) | PretrainDataset |
学习语言规律 | 全部 Token |
| 指令微调(SFT) | SFTDataset |
学习对话行为 | 仅 AI 回答部分 |
通过这两种数据集的配合,
我们就能从“教模型识字”一路走到“教模型聊天”,
让大语言模型不仅懂语言,还能像人一样对话
3.3 预训练
在完成数据预处理之后,我们终于要进入最激动人心的部分——训练语言模型。
这里使用的模型是一个与 LLaMA2 结构相同的 Decoder-only Transformer
接下来,我们将模型训练步骤分解,逐步介绍预训练有哪些步骤:
🧠 一、模型是如何“生成文字”的?
语言模型最神奇的地方在于“生成”文本。
在模型的 generate 方法中,我们能看到这种“逐词生成”的过程:
- 输入序列:给模型一段文本,比如“你好,我想了解一下”。
- 预测下一个词:模型会根据上下文计算每个可能词的概率(称为 logits)。
- 采样或选取概率最高的词:
- 如果设置温度
temperature=0,模型总是选取概率最高的词; - 如果
temperature>0,模型会随机采样,使生成的文字更具创造性。
- 将新词加入序列,继续预测:
模型将自己刚生成的词作为输入,再次预测下一个,循环往复。
最终,模型一步步“写出”整段文本,直到遇到指定的结束符(stop_id)。
这个过程就像一个人一边说话一边思考,每次只想下一句话该怎么接。
@torch.inference_mode()
def generate(self, idx, stop_id=None, max_new_tokens=256, temperature=1.0, top_k=None):
"""
给定输入序列 idx(形状为 (bz,seq_len) 的长整型张量),通过多次生成新 token 来完成序列。
在 model.eval() 模式下运行。效率较低的采样版本,没有使用键k/v cache。
"""
index = idx.shape[1]
for _ in range(max_new_tokens):
# 如果序列上下文过长,截断它到最大长度
idx_cond = idx if idx.size(1) <= self.args.max_seq_len else idx[:, -self.args.max_seq_len:]
# 前向传播获取序列中最后一个位置的 logits
logits = self(idx_cond).logits
logits = logits[:, -1, :] # 只保留最后一个时间步的输出
if temperature == 0.0:
# 选择最有可能的索引
_, idx_next = torch.topk(logits, k=1, dim=-1)
else:
# 缩放 logits 并应用 softmax
logits = logits / temperature
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = -float('Inf')
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
if idx_next == stop_id:
break
# 将采样的索引添加到序列中并继续
idx = torch.cat((idx, idx_next), dim=1)
return idx[:, index:] # 只返回生成的token
 ### ⚙️ 二、学习率调度:模型学习的“节奏控制器”
### ⚙️ 二、学习率调度:模型学习的“节奏控制器”
在训练模型时,学习率决定了模型参数更新的幅度——太快会学不稳,太慢又收敛太慢。
为了让模型学习更加平稳,代码中使用了一种常见策略:余弦退火(Cosine Annealing)调度。
这个调度大致分为三个阶段:
- 预热阶段(Warmup):一开始学习率从 0 逐渐升高,让模型慢慢进入状态。
- 退火阶段(Cosine Decay):随着训练进行,学习率沿着余弦曲线慢慢降低,防止震荡。
- 稳定阶段:当训练接近尾声时,学习率维持在一个较小的值,帮助模型精修细节。
这种方法能让模型像“先热身再冲刺最后稳步收尾”的运动员一样,学习过程更加高效稳定。
🔁 三、训练循环:模型如何一步步学会“语言”
每一次完整的训练循环(一个 epoch)可以理解为模型“读完所有数据一遍”的过程。
在每个训练步骤中,程序会经历以下环节:
- 加载一批数据(batch):取若干条样本(比如几百段文本),送入模型。
- 前向传播(Forward):模型根据输入计算预测输出。
- 计算损失(Loss):比较模型预测的词与真实词的差距。
- 反向传播(Backward):根据损失反向调整模型参数。
- 梯度累积(Gradient Accumulation):为节省显存,可以多步累积再更新一次。
- 梯度裁剪(Clip):防止梯度过大导致训练不稳定。
- 优化器更新(Optimizer Step):真正修改模型参数,让它“变聪明一点”。
在训练过程中,还会定期:
- 打印日志,记录当前损失和学习率;
- 保存模型权重文件,防止中断训练;
- 可选地将指标上传到实验平台(如 SwanLab)做可视化追踪。
整个训练就像一个长期的学习过程,模型会在每一轮迭代中逐渐减少预测错误,越来越“理解”语言结构。
💾 四、模型初始化:让一切准备就绪
在训练开始前,程序会完成以下准备工作:
- 加载分词器(Tokenizer),把文字转化为数字。
- 创建 Transformer 模型,设定层数、维度等结构参数。
- 检测可用 GPU 并开启多卡并行训练。
- 统计模型参数量(例如 215M 参数量的模型意味着约 2.15 亿个可训练权重)。
完成这些步骤后,模型就准备好“开课”了。
🚀 五、训练启动:让语言模型开始“学习”
当所有配置准备完毕后,训练正式开始:
- 从指定路径加载已处理好的数据集(如
seq_monkey_datawhale.jsonl)。 - 使用
DataLoader高效读取数据并打乱顺序。 - 初始化优化器(Adam)和混合精度训练工具。
- 循环执行
train_epoch(),逐步更新模型参数。
在训练过程中,模型会从随机初始化的状态逐渐学会模仿文本中的语言规律。经过足够多的轮次,它将能够自主生成连贯、符合语义的句子。
注:在使用下面代码进行模型训练时,需要指定 --data_path 参数为预处理好的数据集路径,例如 --data_path seq_monkey_datawhale.jsonl,也需要指定要用哪几张GPU进行训练,例如 --gpus 0,1。
def get_lr(it, all):
"""
计算当前迭代的学习率,使用余弦退火调度策略
学习率调度策略:
1. Warmup阶段:学习率从0线性增长到目标学习率
2. 余弦退火阶段:学习率按余弦函数衰减到最小学习率
3. 超出训练步数后:保持最小学习率
Args:
it (int): 当前迭代步数
all (int): 总迭代步数
Returns:
float: 当前步数对应的学习率
"""
warmup_iters = args.warmup_iters # 预热迭代次数
lr_decay_iters = all # 学习率衰减的总迭代次数
min_lr = args.learning_rate / 10 # 最小学习率,为初始学习率的1/10
# Warmup阶段:线性增长
if it < warmup_iters:
return args.learning_rate * it / warmup_iters
# 超出训练步数:保持最小学习率
if it > lr_decay_iters:
return min_lr
# 余弦退火阶段
decay_ratio = (it - warmup_iters) / (lr_decay_iters - warmup_iters)
assert 0 <= decay_ratio <= 1
coeff = 0.5 * (1.0 + math.cos(math.pi * decay_ratio)) # 余弦系数
return min_lr + coeff * (args.learning_rate - min_lr)
def train_epoch(epoch):
"""
训练一个epoch的函数
实现了完整的训练循环,包括:
1. 数据加载和设备转移
2. 动态学习率调整
3. 前向传播和损失计算
4. 梯度累积和反向传播
5. 梯度裁剪和优化器更新
6. 日志记录和模型保存
Args:
epoch (int): 当前epoch编号
"""
start_time = time.time() # 记录开始时间
# 遍历数据加载器中的每个batch
for step, (X, Y, loss_mask) in enumerate(train_loader):
# 将数据转移到指定设备(GPU/CPU)
X = X.to(args.device) # 输入序列
Y = Y.to(args.device) # 目标序列
loss_mask = loss_mask.to(args.device) # 损失掩码,用于忽略padding token
# 计算当前步骤的学习率
lr = get_lr(epoch * iter_per_epoch + step, args.epochs * iter_per_epoch)
# 更新优化器中所有参数组的学习率
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# 使用混合精度训练上下文
with ctx:
# 前向传播
out = model(X, Y)
# 计算损失并除以累积步数(用于梯度累积)
loss = out.last_loss / args.accumulation_steps
# 将loss_mask展平为一维
loss_mask = loss_mask.view(-1)
# 应用掩码计算有效损失(忽略padding位置)
loss = torch.sum(loss * loss_mask) / loss_mask.sum()
# 使用scaler进行混合精度的反向传播
scaler.scale(loss).backward()
# 每accumulation_steps步执行一次优化器更新
if (step + 1) % args.accumulation_steps == 0:
# 取消梯度缩放,准备梯度裁剪
scaler.unscale_(optimizer)
# 梯度裁剪,防止梯度爆炸
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
# 执行优化器步骤
scaler.step(optimizer)
# 更新scaler的缩放因子
scaler.update()
# 清零梯度,set_to_none=True可以节省内存
optimizer.zero_grad(set_to_none=True)
# 每log_interval步记录一次日志
if step % args.log_interval == 0:
spend_time = time.time() - start_time
# 打印训练进度信息
Logger(
'Epoch:[{}/{}]({}/{}) loss:{:.3f} lr:{:.7f} epoch_Time:{}min;'.format(
epoch + 1,
args.epochs,
step,
iter_per_epoch,
loss.item() * args.accumulation_steps, # 恢复真实的loss值
optimizer.param_groups[-1]['lr'],
spend_time / (step + 1) * iter_per_epoch // 60 - spend_time // 60))
# 如果启用SwanLab,记录训练指标
if args.use_swanlab:
swanlab.log({
"loss": loss.item() * args.accumulation_steps,
"lr": optimizer.param_groups[-1]['lr']
})
# 每save_interval步保存一次模型
if (step + 1) % args.save_interval == 0:
model.eval() # 切换到评估模式
# 构建检查点文件名
ckp = f'{args.save_dir}/pretrain_{lm_config.dim}_{lm_config.n_layers}_{lm_config.vocab_size}.pth'
# 处理多卡保存:如果是DataParallel模型,需要访问.module属性
state_dict = model.module.state_dict() if isinstance(model, torch.nn.DataParallel) else model.state_dict()
torch.save(state_dict, ckp)
model.train() # 切换回训练模式
# 每20000步保存一个带步数标记的检查点
if (step + 1) % 20000 == 0:
model.eval()
# 构建带步数的检查点文件名
ckp = f'{args.save_dir}/pretrain_{lm_config.dim}_{lm_config.n_layers}_{lm_config.vocab_size}_step{step+1}.pth'
# 保存模型状态字典
state_dict = model.module.state_dict() if isinstance(model, torch.nn.DataParallel) else model.state_dict()
torch.save(state_dict, ckp)
model.train()
def init_model():
"""
初始化模型和分词器
功能包括:
1. 加载预训练的分词器
2. 创建Transformer模型
3. 设置多GPU并行训练(如果可用)
4. 将模型移动到指定设备
5. 统计并打印模型参数量
Returns:
tuple: (model, tokenizer) 初始化后的模型和分词器
"""
def count_parameters(model):
"""
统计模型中可训练参数的数量
Args:
model: PyTorch模型
Returns:
int: 可训练参数总数
"""
return sum(p.numel() for p in model.parameters() if p.requires_grad)
# 从本地路径加载预训练的分词器
tokenizer = AutoTokenizer.from_pretrained('./tokenizer_k/')
# 根据配置创建Transformer模型
model = Transformer(lm_config)
# 多卡初始化:检查可用GPU数量并设置DataParallel
num_gpus = torch.cuda.device_count()
if num_gpus > 1:
Logger(f"Using {num_gpus} GPUs with DataParallel!")
# 使用DataParallel包装模型以支持多GPU训练
model = torch.nn.DataParallel(model)
# 将模型移动到指定设备(GPU或CPU)
model = model.to(args.device)
# 计算并打印模型参数量(以百万为单位)
Logger(f'LLM总参数量:{count_parameters(model) / 1e6:.3f} 百万')
return model, tokenizer
if __name__ == "__main__":
# ==================== 命令行参数解析 ====================
parser = argparse.ArgumentParser(description="Tiny-LLM Pretraining")
# 基础训练参数
parser.add_argument("--out_dir", type=str, default="base_model_215M", help="模型输出目录")
parser.add_argument("--epochs", type=int, default=1, help="训练轮数")
parser.add_argument("--batch_size", type=int, default=64, help="批次大小")
parser.add_argument("--learning_rate", type=float, default=2e-4, help="学习率")
parser.add_argument("--device", type=str, default="cuda:0" if torch.cuda.is_available() else "cpu", help="训练设备")
parser.add_argument("--dtype", type=str, default="bfloat16", help="数据类型")
# 实验跟踪和数据加载参数
parser.add_argument("--use_swanlab", action="store_true", help="是否使用SwanLab进行实验跟踪")
parser.add_argument("--num_workers", type=int, default=8, help="数据加载的工作进程数")
parser.add_argument("--data_path", type=str, default="./seq_monkey_datawhale.jsonl", help="训练数据路径")
# 训练优化参数
parser.add_argument("--accumulation_steps", type=int, default=8, help="梯度累积步数")
parser.add_argument("--grad_clip", type=float, default=1.0, help="梯度裁剪阈值")
parser.add_argument("--warmup_iters", type=int, default=0, help="学习率预热迭代次数")
# 日志和保存参数
parser.add_argument("--log_interval", type=int, default=100, help="日志记录间隔")
parser.add_argument("--save_interval", type=int, default=1000, help="模型保存间隔")
# 多GPU训练参数
parser.add_argument("--gpus", type=str, default='0,1,2,3,4,5,6,7', help="使用的GPU ID,用逗号分隔 (例如: '0,1,2')")
args = parser.parse_args()
# ==================== GPU环境设置 ====================
# 设置可见的GPU设备
if args.gpus is not None:
os.environ["CUDA_VISIBLE_DEVICES"] = args.gpus
# 自动设置主设备为第一个可用GPU
if torch.cuda.is_available():
args.device = "cuda:0"
else:
args.device = "cpu"
# ==================== 实验跟踪初始化 ====================
if args.use_swanlab:
# 注意:使用前需要先登录 swanlab.login(api_key='your key')
run = swanlab.init(
project="Happy-LLM", # 项目名称
experiment_name="Pretrain-215M", # 实验名称
config=args, # 保存所有超参数
)
# ==================== 模型配置 ====================
# 定义语言模型的配置参数
lm_config = ModelConfig(
dim=1024, # 模型维度
n_layers=18, # Transformer层数
)
# ==================== 训练环境设置 ====================
max_seq_len = lm_config.max_seq_len # 最大序列长度
args.save_dir = os.path.join(args.out_dir) # 模型保存目录
# 创建必要的目录
os.makedirs(args.out_dir, exist_ok=True)
# 设置随机种子以确保结果可复现
torch.manual_seed(42)
# 确定设备类型(用于选择合适的上下文管理器)
device_type = "cuda" if "cuda" in args.device else "cpu"
# 设置混合精度训练的上下文管理器
# CPU训练时使用nullcontext,GPU训练时使用autocast
ctx = nullcontext() if device_type == "cpu" else torch.cuda.amp.autocast()
# ==================== 模型和数据初始化 ====================
# 初始化模型和分词器
model, tokenizer = init_model()
# 创建训练数据集
train_ds = PretrainDataset(args.data_path, tokenizer, max_length=max_seq_len)
# 创建数据加载器
train_loader = DataLoader(
train_ds,
batch_size=args.batch_size, # 批次大小
pin_memory=True, # 将数据加载到固定内存中,加速GPU传输
drop_last=False, # 不丢弃最后一个不完整的批次
shuffle=True, # 随机打乱数据
num_workers=args.num_workers # 数据加载的并行工作进程数
)
# ==================== 优化器和训练组件初始化 ====================
# 初始化混合精度训练的梯度缩放器
# 只有在使用float16或bfloat16时才启用
scaler = torch.cuda.amp.GradScaler(enabled=(args.dtype in ['float16', 'bfloat16']))
# 初始化Adam优化器
optimizer = optim.Adam(model.parameters(), lr=args.learning_rate)
# ==================== 开始训练 ====================
# 计算每个epoch的迭代次数
iter_per_epoch = len(train_loader)
# 开始训练循环
for epoch in range(args.epochs):
train_epoch(epoch)
3.4 SFT 训练
在完成了大模型的预训练(Pretrain)后,我们通常会进入一个叫 SFT(Supervised Fine-Tuning,监督微调) 的阶段。
简单来说,这一步是让模型从“会说话”变成“说得对” —— 通过高质量的对话数据(比如人类问答、多轮对话),教它如何按照指令作答。
下面的代码演示了如何使用 PyTorch 进行 SFT 训练,结构与预训练几乎一致,唯一的不同在于我们使用了一个支持多轮对话的 SFTDataset。
"""
🌟 Tiny-LLM SFT(监督微调)训练脚本
本代码在已有预训练模型的基础上,通过多轮对话数据进行微调,
让模型更符合人类意图,能够更好地理解问答与对话上下文。
"""
import os
import platform
import argparse
import time
import warnings
import math
import torch
from torch import optim
from torch.utils.data import DataLoader
from contextlib import nullcontext
from transformers import AutoTokenizer
from k_model import ModelConfig, Transformer # 自定义的模型结构
from dataset import SFTDataset # 多轮对话数据集
import swanlab # 可选:实验追踪工具
# 忽略不必要的警告
warnings.filterwarnings('ignore')
🧾 日志函数:让训练过程“有迹可循”
def Logger(content):
"""简单的日志输出函数"""
print(content)
📉 学习率调度:控制模型“学习的节奏”
SFT 阶段通常不需要太大的学习率,这里采用
余弦退火调度(Cosine Decay)
,让学习率逐渐降低,学习更稳定。
def get_lr(it, all):
"""根据当前迭代步数计算学习率"""
warmup_iters = args.warmup_iters
lr_decay_iters = all
min_lr = args.learning_rate / 10
# (1) 预热阶段:从0线性升到目标学习率
if it < warmup_iters:
return args.learning_rate * it / warmup_iters
# (2) 衰减阶段:超过训练步数后保持最小学习率
if it > lr_decay_iters:
return min_lr
# (3) 中间阶段:使用余弦曲线平滑下降
decay_ratio = (it - warmup_iters) / (lr_decay_iters - warmup_iters)
coeff = 0.5 * (1.0 + math.cos(math.pi * decay_ratio))
return min_lr + coeff * (args.learning_rate - min_lr)
🔁 训练核心:一个 Epoch 内发生的故事
每训练一个 epoch,就相当于模型“读完整个训练集一遍”。
def train_epoch(epoch):
"""训练一个epoch"""
start_time = time.time()
for step, (X, Y, loss_mask) in enumerate(train_loader):
# 把数据移动到显卡上
X, Y, loss_mask = X.to(args.device), Y.to(args.device), loss_mask.to(args.device)
# 获取并设置当前学习率
lr = get_lr(epoch * iter_per_epoch + step, args.epochs * iter_per_epoch)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# 前向传播:模型根据输入预测输出
with ctx:
out = model(X, Y)
loss = out.last_loss / args.accumulation_steps
# 使用 loss_mask 屏蔽掉不需要计算的 token
loss_mask = loss_mask.view(-1)
loss = torch.sum(loss * loss_mask) / loss_mask.sum()
# 反向传播:计算梯度
scaler.scale(loss).backward()
# 每隔一定步数才更新权重(梯度累积)
if (step + 1) % args.accumulation_steps == 0:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad(set_to_none=True)
# 打印日志
if step % args.log_interval == 0:
spend_time = time.time() - start_time
Logger(
f"Epoch:[{epoch+1}/{args.epochs}] ({step}/{iter_per_epoch}) "
f"loss:{loss.item() * args.accumulation_steps:.3f} "
f"lr:{optimizer.param_groups[-1]['lr']:.7f} "
f"time:{spend_time/60:.2f}min"
)
# 可选:上传到 swanlab 可视化平台
if args.use_swanlab:
swanlab.log({
"loss": loss.item() * args.accumulation_steps,
"lr": optimizer.param_groups[-1]['lr']
})
# 保存模型(定期保存一次)
if (step + 1) % args.save_interval == 0:
model.eval()
ckp = f"{args.save_dir}/sft_dim{lm_config.dim}_layers{lm_config.n_layers}_vocab{lm_config.vocab_size}.pth"
state_dict = model.module.state_dict() if isinstance(model, torch.nn.DataParallel) else model.state_dict()
torch.save(state_dict, ckp)
model.train()
🧩 模型初始化:加载预训练权重 + 多卡并行
在 SFT 阶段,我们通常不从零开始训练,而是
加载预训练模型的参数
,让模型“站在巨人的肩膀上”继续学习。
def init_model():
"""初始化模型和分词器"""
def count_parameters(model):
"""计算参数总量"""
return sum(p.numel() for p in model.parameters() if p.requires_grad)
# 1️⃣ 加载分词器
tokenizer = AutoTokenizer.from_pretrained('./tokenizer_k/')
# 2️⃣ 初始化模型结构
model = Transformer(lm_config)
# 3️⃣ 加载预训练权重
ckp = './base_model_215M/pretrain_1024_18_6144.pth'
state_dict = torch.load(ckp, map_location=args.device)
unwanted_prefix = '_orig_mod.'
for k, v in list(state_dict.items()):
if k.startswith(unwanted_prefix):
state_dict[k[len(unwanted_prefix):]] = state_dict.pop(k)
model.load_state_dict(state_dict, strict=False)
# 4️⃣ 多卡训练支持
num_gpus = torch.cuda.device_count()
if num_gpus > 1:
Logger(f"Using {num_gpus} GPUs with DataParallel!")
model = torch.nn.DataParallel(model)
model = model.to(args.device)
Logger(f"LLM 总参数量:{count_parameters(model) / 1e6:.3f} 百万")
return model, tokenizer
🚀 主函数:让训练正式启动!
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Tiny-LLM SFT Training")
parser.add_argument("--out_dir", type=str, default="sft_model_215M")
parser.add_argument("--epochs", type=int, default=1)
parser.add_argument("--batch_size", type=int, default=64)
parser.add_argument("--learning_rate", type=float, default=2e-4)
parser.add_argument("--device", type=str, default="cuda:0" if torch.cuda.is_available() else "cpu")
parser.add_argument("--dtype", type=str, default="bfloat16")
parser.add_argument("--use_swanlab", action="store_true")
parser.add_argument("--num_workers", type=int, default=8)
parser.add_argument("--data_path", type=str, default="./BelleGroup_sft.jsonl")
parser.add_argument("--accumulation_steps", type=int, default=8)
parser.add_argument("--grad_clip", type=float, default=1.0)
parser.add_argument("--warmup_iters", type=int, default=0)
parser.add_argument("--log_interval", type=int, default=100)
parser.add_argument("--save_interval", type=int, default=1000)
parser.add_argument("--gpus", type=str, default='0,1,2,3,4,5,6,7')
args = parser.parse_args()
# 设置可见 GPU
if args.gpus is not None:
os.environ["CUDA_VISIBLE_DEVICES"] = args.gpus
args.device = "cuda:0" if torch.cuda.is_available() else "cpu"
# 可选:初始化 SwanLab
if args.use_swanlab:
run = swanlab.init(project="Happy-LLM", experiment_name="SFT-215M", config=args)
# 模型配置
lm_config = ModelConfig(dim=1024, n_layers=18)
args.save_dir = os.path.join(args.out_dir)
os.makedirs(args.out_dir, exist_ok=True)
torch.manual_seed(42)
# 自动混合精度上下文(显存更省)
device_type = "cuda" if "cuda" in args.device else "cpu"
ctx = nullcontext() if device_type == "cpu" else torch.cuda.amp.autocast()
# 初始化模型与分词器
model, tokenizer = init_model()
# 数据加载
train_ds = SFTDataset(args.data_path, tokenizer, max_length=lm_config.max_seq_len)
train_loader = DataLoader(train_ds, batch_size=args.batch_size, pin_memory=True,
drop_last=False, shuffle=True, num_workers=args.num_workers)
# 优化器与缩放器(AMP)
scaler = torch.cuda.amp.GradScaler(enabled=(args.dtype in ['float16', 'bfloat16']))
optimizer = optim.AdamW(model.parameters(), lr=args.learning_rate)
# 开始训练!
iter_per_epoch = len(train_loader)
for epoch in range(args.epochs):
train_epoch(epoch)
🧠 总结:SFT 的本质是什么?
| 阶段 | 目标 | 特点 |
|---|---|---|
| 预训练(Pretrain) | 让模型学习“语言知识” | 大规模语料,无监督 |
| 监督微调(SFT) | 让模型学会“听懂指令、对话合理” | 有监督,多轮问答数据 |
| RLHF / DPO 等 | 让模型“更符合人类偏好” | 奖励信号训练 |
SFT 就是让模型“从懂语言到懂人话”的关键一步。
在这个阶段,我们通过人工整理的高质量问答数据,引导模型学习
该怎么回答才合适、该怎么对话才自然
。
3.5 使用模型生成文本
在模型训练完成后,我们会在
output
目录下看到生成的模型文件——这就是我们亲手训练出的语言模型。接下来,只需运行以下命令,就可以让它“开口说话”了:
python model_sample.py
🧠 模型生成脚本:model_sample.py
这个脚本主要定义了一个名为 TextGenerator 的类,用于加载模型、调用分词器,并生成文本。
下面我们来拆解它的核心逻辑。
🚀 一、模型初始化
generator = TextGenerator(checkpoint='./base_model_215M/pretrain_1024_18_6144.pth')
在初始化阶段,模型会完成以下工作:
- 自动检测设备:优先使用 GPU(CUDA),没有则用 CPU。
- 设置随机种子:确保每次生成的结果可重复。
- 加载模型权重:从
.pth文件中恢复训练好的参数。 - 统计参数量:显示模型规模,比如
215M parameters表示拥有 2.15 亿个可训练参数。 - 加载分词器:让模型能理解文字与 token 的映射关系。
💬 二、对话模板
def chat_template(self, prompt):
message = [
{"role": "system", "content": "你是一个AI助手,你的名字叫梯度更新专家。"},
{"role": "user", "content": prompt}
]
return self.tokenizer.apply_chat_template(message, tokenize=False, add_generation_prompt=True)
梯度更新专家
✍️ 三、文本生成核心逻辑
TextGenerator 中有两个主要的生成方法:
pretrain_sample():基于预训练模型生成自由文本(适合开放式续写)。sft_sample():基于指令微调(SFT)模型生成问答风格的输出。
每次生成时,模型会根据提示词(prompt)预测接下来的若干 token。
参数中:
temperature控制输出的随机性;top_k限制采样范围;max_new_tokens决定输出长度;num_samples表示生成多少条结果。
⚙️ 模型训练配置建议
如果你想复现作者的实验,这里有一些实测经验:
- batch size 可调小一点以节省显存;
- batch=4 时仅需约 7GB 显存;
- 预训练阶段:单卡预计 533 小时;
- 作者实测(8×4090 GPU):
- 预训练耗时约 46 小时;
- SFT 阶段使用 BelleGroup 350 万条中文指令数据,耗时 24 小时。
普通人如何抓住AI大模型的风口?
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
AI大模型开发工程师对AI大模型需要了解到什么程度呢?我们先看一下招聘需求:

知道人家要什么能力,一切就好办了!我整理了AI大模型开发工程师需要掌握的知识如下:
大模型基础知识
你得知道市面上的大模型产品生态和产品线;还要了解Llama、Qwen等开源大模型与OpenAI等闭源模型的能力差异;以及了解开源模型的二次开发优势,以及闭源模型的商业化限制,等等。

了解这些技术的目的在于建立与算法工程师的共通语言,确保能够沟通项目需求,同时具备管理AI项目进展、合理分配项目资源、把握和控制项目成本的能力。
产品经理还需要有业务sense,这其实就又回到了产品人的看家本领上。我们知道先阶段AI的局限性还非常大,模型生成的内容不理想甚至错误的情况屡见不鲜。因此AI产品经理看技术,更多的是从技术边界、成本等角度出发,选择合适的技术方案来实现需求,甚至用业务来补足技术的短板。
AI Agent
现阶段,AI Agent的发展可谓是百花齐放,甚至有人说,Agent就是未来应用该有的样子,所以这个LLM的重要分支,必须要掌握。
Agent,中文名为“智能体”,由控制端(Brain)、感知端(Perception)和行动端(Action)组成,是一种能够在特定环境中自主行动、感知环境、做出决策并与其他Agent或人类进行交互的计算机程序或实体。简单来说就是给大模型这个大脑装上“记忆”、装上“手”和“脚”,让它自动完成工作。
Agent的核心特性
自主性: 能够独立做出决策,不依赖人类的直接控制。
适应性: 能够根据环境的变化调整其行为。
交互性: 能够与人类或其他系统进行有效沟通和交互。

对于大模型开发工程师来说,学习Agent更多的是理解它的设计理念和工作方式。零代码的大模型应用开发平台也有很多,比如dify、coze,拿来做一个小项目,你就会发现,其实并不难。
AI 应用项目开发流程
如果产品形态和开发模式都和过去不一样了,那还画啥原型?怎么排项目周期?这将深刻影响产品经理这个岗位本身的价值构成,所以每个AI产品经理都必须要了解它。

看着都是新词,其实接触起来,也不难。
从0到1的大模型系统学习籽料
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师(吴文俊奖得主)
给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。
- 基础篇,包括了大模型的基本情况,核心原理,带你认识了解大模型提示词,Transformer架构,预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门AI大模型
- 进阶篇,你将掌握RAG,Langchain、Agent的核心原理和应用,学习如何微调大模型,让大模型更适合自己的行业需求,私有化部署大模型,让自己的数据更加安全
- 项目实战篇,会手把手一步步带着大家练习企业级落地项目,比如电商行业的智能客服、智能销售项目,教育行业的智慧校园、智能辅导项目等等

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

AI时代,企业最需要的是既懂技术、又有实战经验的复合型人才,**当前人工智能岗位需求多,薪资高,前景好。**在职场里,选对赛道就能赢在起跑线。抓住AI这个风口,相信下一个人生赢家就是你!机会,永远留给有准备的人。
如何获取?
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献297条内容
已为社区贡献297条内容

所有评论(0)