【AI+医疗】AI医生养成记:让大模型掌握临床诊断的动态推理过程!
上海交通大学等团队提出"环境-智能体"训练框架,创建DiagGym虚拟临床环境和DiagAgent诊断智能体,通过端到端强化学习让AI掌握动态诊断能力。团队还构建了DiagBench评测基准(750个病例,973条评估准则)。实验显示,该框架训练的智能体在多轮诊断流程管理能力上显著优于DeepSeek、Claude-4等先进模型,实现了从静态问答到动态决策的AI诊断范式转变。
临床诊断并非一次性的「快照」,而是一场动态交互、不断「探案」的推理过程。然而,当下的大模型大多基于静态数据训练,难以掌握真实诊疗中充满不确定性的多轮决策轨迹。如何让AI学会「追问」、选择检查,并一步步抽丝剥茧,迈向正确诊断?
来自上海交通大学人工智能学院、上海人工智能实验室、蚂蚁集团与北京大学的联合团队提出了全新的「环境—智能体」训练框架。他们构建了面向医学诊断的世界模型 DiagGym,并在其中训练可自主演进的诊断智能体 DiagAgent。在该框架中,诊断智能体可以在安全可控的虚拟世界中反复探索,通过与虚拟病人的交互反馈持续优化自身的动态决策策略。
研究团队还设计了聚焦诊断推理过程的评测基准 DiagBench。该基准共包含 750 个病例,提供了经医生验证的中间检查推荐和最终诊断结果;其中有 99 个病例,另外由医生手工撰写了 973 条关于诊断过程的详细评估准则。在 DiagBench 上的实验结果显示,该框架下训练得到的诊断智能体在 DiagAgent 多轮诊断流程管理能力方面,显著优于 DeepSeek、Claude-4 等先进模型。
代码、模型、测试数据均已全部开源。

-
论文标题:Evolving Diagnostic Agents in a Virtual Clinical Environment
-
论文链接:https://arxiv.org/abs/2510.24654
-
代码仓库:https://github.com/MAGIC-AI4Med/DiagGym
问题背景:
从静态问答到动态决策,AI 诊断需要主动问询
真实的临床诊断是一个复杂的多轮决策过程:医生需要根据不完整的初步信息,提出一系列可能的鉴别诊断,然后主动选取、推荐一系列的检验检查「轨迹」来逐步排除或确认,最终在信息充足时做出诊断。
然而,当前多数医疗 LLM 的训练范式更像是在做「开卷考试」——它们基于静态、完整的病历数据进行指令微调。这种模式忽略了诊断过程中的交互性和长期策略性,导致模型难以处理真实诊疗中的三大核心挑战:
- 主动探索:如何主动选择下一步检查?
- 动态调整:如何根据新的检查结果更新诊断假设?
- 适时收敛:何时应该停止检查并给出最终诊断?
为了攻克这一难题,研究团队提出了一种创新的端到端智能体训练范式:让诊断智能体(DiagAgent)在一个面向医学诊断的世界模型(DiagGym)构成的虚拟临床环境中,自主交互,通过接受环境反馈和最终的强化学习奖励,「摸爬滚打」,学会一套高效、准确的多轮诊断交互策略。
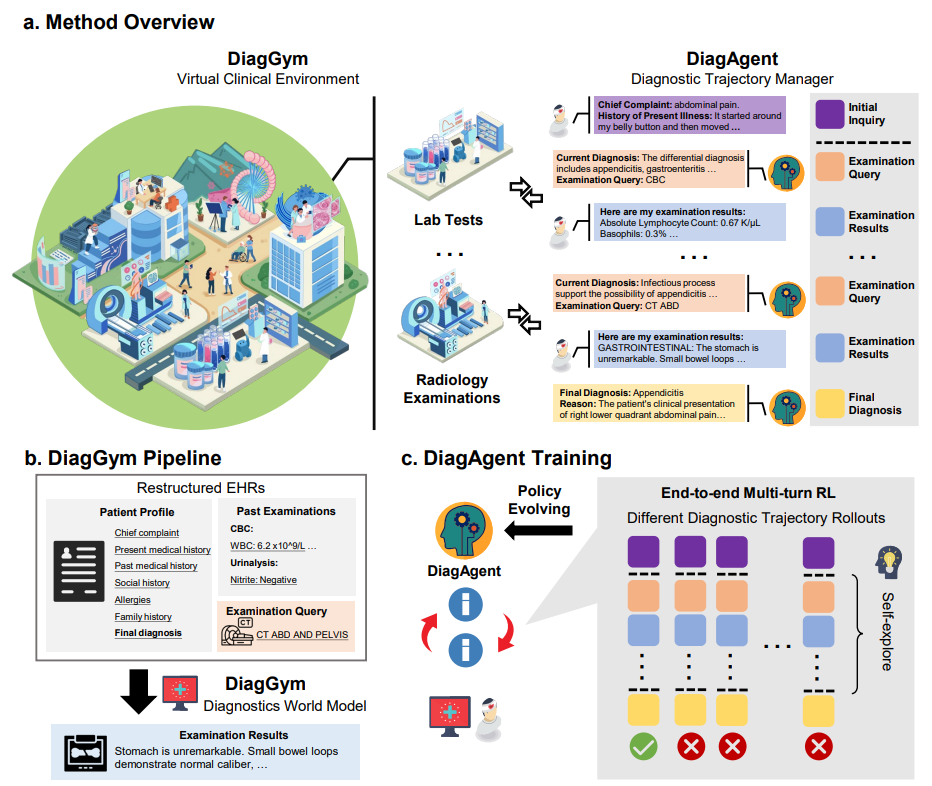
图1. 端到端的诊断智能体训练范式
核心贡献:
虚拟临床环境、诊断智能体
与基于 Rubric 的评测基准
这项工作的核心贡献可以概括为三个环环相扣的部分:
虚拟临床环境:构建医学诊断的世界模型 DiagGym
研究团队基于海量真实电子病历(EHR)训练了一个条件生成模型。这个模型可以根据患者的初始情况和已有的检查记录,实时生成「下一项检查的结果」。它构建了一个低成本、安全、可复现的闭环虚拟临床环境,为智能体的交互式训练提供了完美沙盒。更重要的是,这个环境兼具高保真度与高多样性,能模拟从典型到罕见的各种诊疗路径。
主动问询能力:端到端诊断智能体自主演进DiagAgent
在上述的虚拟环境中,DiagAgent 通过端到端强化学习进行训练。智能体需要学习在每个决策点做出最优选择——是继续建议检查,还是给出最终诊断,不断同诊断学世界模型进行交互,获得当前病人信息。其目标是学会通过动态决策,主动进行检查推荐,并在信息足够时做出诊断,从而实现高效动态问诊。
诊断过程化评测基准:人工检验诊断轨迹规范性 DiagBench
为了全面评估诊断智能体的能力,团队构建了 DiagBench。它不仅包含 750 个经人工检查的带有参考诊断路径的案例,更创新性地引入了由医生撰写的 973 条诊断过程评估准则(rubrics)。这些准则带有权重,可以细粒度地评估诊断交互过程的合规性与质量,强调「如何达成诊断」的过程,而不仅仅是「诊断结果是否正确」。
实验结果显示,无论是在单步决策场景,还是在端到端****多步诊断决策场景,经过强化学习训练的 DiagAgent 均显著优于包括 GPT4o、DeepSeekv3 在内的 10 个代表性大模型,以及两种主流智能体框架。这一结果表明,在交互式环境中进行策略学习,能够赋予模型更强的动态决策与长期诊断管理能力。
技术框架:
训练诊断学世界模型与端到端
交互式诊断智能体强化学习自主演进
第一步:DiagGym,构建可交互的诊断世界模型,打造虚拟临床环境
首先,团队需要一个能模拟真实临床反馈的「沙盒」。他们收集了超过 11 万份患者的真实诊疗数据,覆盖近 5000 种疾病。这些数据包含了患者基本信息以及按时间排序的检查序列(如化验、影像等)。
利用这些数据,团队训练了一个自回归语言模型。这个模型的核心能力是条件性文本生成:给定患者基本信息和历史检查记录,它能精准预测下一项检查可能出现的结果。这个模型就是 DiagGym,一个能够实时模拟检查反馈的诊断学世界模型。
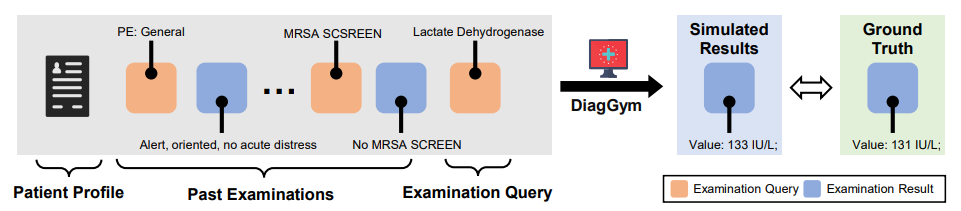
图2:基于临床序列数据的 DiagGym 自回归语言模型训练范式
第二步:DiagAgent,端到端强化学习驱动,让诊断智能体自主演进
有了「虚拟临床环境」,就可以开始训练「诊断智能体」了。DiagAgent 的训练分为两个阶段:
-
冷启动(Supervised Fine-Tuning):首先,使用 1000 条从真实病历中抽取的诊断互动轨迹进行监督微调,让模型学会基本的交互格式和临床语言。
-
强化学习(Reinforcement Learning):接着,将智能体放入 DiagGym 中进行多轮实战演练。智能体在环境中自主决策,获得环境反馈,并根据最终的奖励进行策略优化。
奖励函数的设计是关键,它由三部分构成:
-
诊断正确性:最终诊断是否准确?
-
检查推荐质量:推荐的检查是否关键、有效?(通过 F1 分数衡量)
-
交互轮数惩罚:是否用最少的步骤完成诊断?(鼓励高效)
通过 GRPO 强化学习算法,DiagAgent 逐渐学会了如何在不确定性下进行「主动搜证-评估-收敛」,将诊断从「单轮问答」升级为「轨迹级决策与策略学习」。
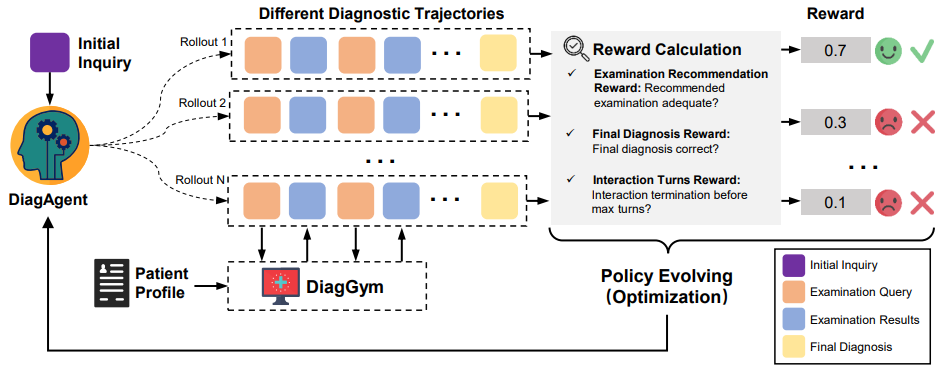
图3:采用强化学习驱动的DiagAgent策略演进的训练架构
第三步:DiagBench,手工打造规则驱动新评测基准,评估AI诊断交互能力
在评估诊断性能方面,不仅需要模型能给出正确答案,更要能展示出严谨的诊断思路。但如何衡量这个「思路」呢?传统的自动化指标显然不够。
为此,研究团队打造了一套全新的手工打造规则驱动的评测基准——DiagBench,旨在深入评估AI在多轮诊断交互中的过程质量。具体步骤如下:
-
医生验证的高质量案例库:基准包含了 750 个经过医生团队逐一验证的真实诊断案例,每个案例都附有标准的参考诊断路径和最终结果。
-
手工打造的核心评估准则(Rubrics):研究团队还引入了一套由资深医生手工打造的、基于规则的评估体系。研究团队邀请多位医生,对 99 个复杂病例进行深度复盘,将诊断过程中的关键决策点、推理逻辑、以及必须遵守的临床准则,提炼成 973 条具体的评估细则(Rubrics)。
-
带权重的精细化打分:在此基础上,医生还为每一条准则都附上权重,以区分其临床重要性。
通过这套体系,DiagBench 对诊断全过程进行细粒度过程审查,全面评估其在信息收集、假设检验、风险控制等维度的综合能力。
实验结果:
虚拟环境与智能体的双重验证
DiagGym:虚拟环境有多真实?
一个可靠的虚拟环境是成功训练智能体的前提。实验证明,DiagGym在多个维度上都表现出色:
-
高保真度:DiagGym 在逐步生成检查结果时展现出卓越性能。如表 1 所示,在逐步生成检查结果时,其步骤相似度(3.57/5分)和整链一致性(96.9%)均远超 Qwen2.5-72B 等强基线模型。更关键的是,根据医生评测结果(表2),DiagGym 同样大幅领先,其生成的报告获得了 4.49 分的平均相似度和 95.00% 的多数投票一致性,这证明 DiagGym 的结果更连贯,更少出现与病情矛盾的「过度阳性」结果,临床可信度高。
-
高多样性:生成的检查结果分布与真实数据高度对齐。如表1所示,数值型 1-Wasserstein 距离仅 0.128,同时保持了接近真实数据的多样性,有效避免了模型模式崩溃。
-
高效率:DiagGym 的部署和推理成本极低。表 1 数据显示,它仅需单卡 A100即可部署,单次生成仅耗时约 0.52 GPU·s,而同类任务若使用 DeepSeek-v3-671B 则需要至少 16 张GPU和超过 62 GPU·s 的算力。这为大规模、高频次的智能体交互训练提供了可能。
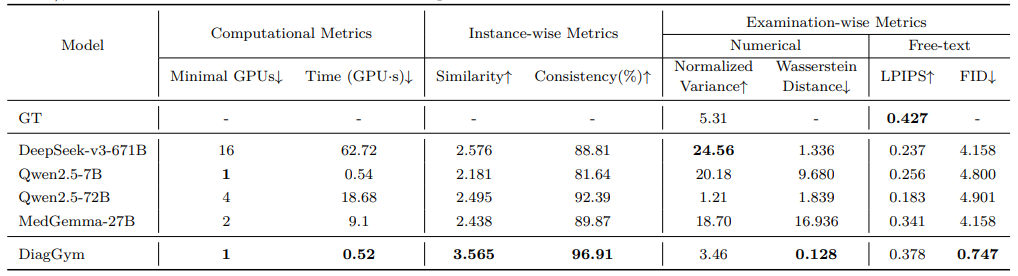
表1:DiagGym 与基线模型的定量评测结果。

表2:DiagGym 与基线模型生成结果的临床专家主观评测结果。
DiagAgent:诊断智能体的**「医术」**如何?
1、单轮能力评测:决策精准度大幅提升
在单轮能力评测中,如图 4a 所示,我们评估了智能体在给定部分病历、仅需做出下一步决策的能力。结果证明,DiagAgent 在这种单轮决策场景下展现了压倒性优势(结果见图 4c)
-
检查推荐命中率提升 44.03%,最终诊断准确率提升 9.34%(相较于次优模型)。
-
DiagAgent-7B 的检查推荐命中率高达 72.56%,而 MedGemma 和 DeepSeek-v3 等强模型仅为 20%-28%。

图4:DiagAgent在单轮决策场景下的评估框架与性能对比。
2、端到端全程诊断评测:过程与结果双优
在模拟真实诊疗、从头到尾完成诊断的全流程测试中,如图5a 所示,模型需要根据患者信息进行多轮问诊,最终给出诊断。DiagAgent 在这一复杂任务中再次表现最佳:
-
核心诊断指标全面领先。如图 5b 所示,DiagAgent-14B 平均交互 6.66 轮,检查推荐F1分数达到 46.59%,最终诊断准确率 61.27%,均远超其他模型。相比之下,许多大模型基线(如 DeepSeek-v3)倾向于在 2-4 轮内草草结束,导致检查不充分(Recall 较低),诊断准确性也大打折扣。
-
过程质量获临床准则认可。我们进一步引入医生制定的**流程化准则(rubrics)**进行评估(如图5c 所示)。在图5d的加权得分对比中,DiagAgent-14B的得分比强基线(如Claude-sonnet-4)高出7-8个百分点。这说明它不仅「诊断对」,而且「过程好」,更好地遵循了关键检查优先、基于证据收敛等临床金标准。
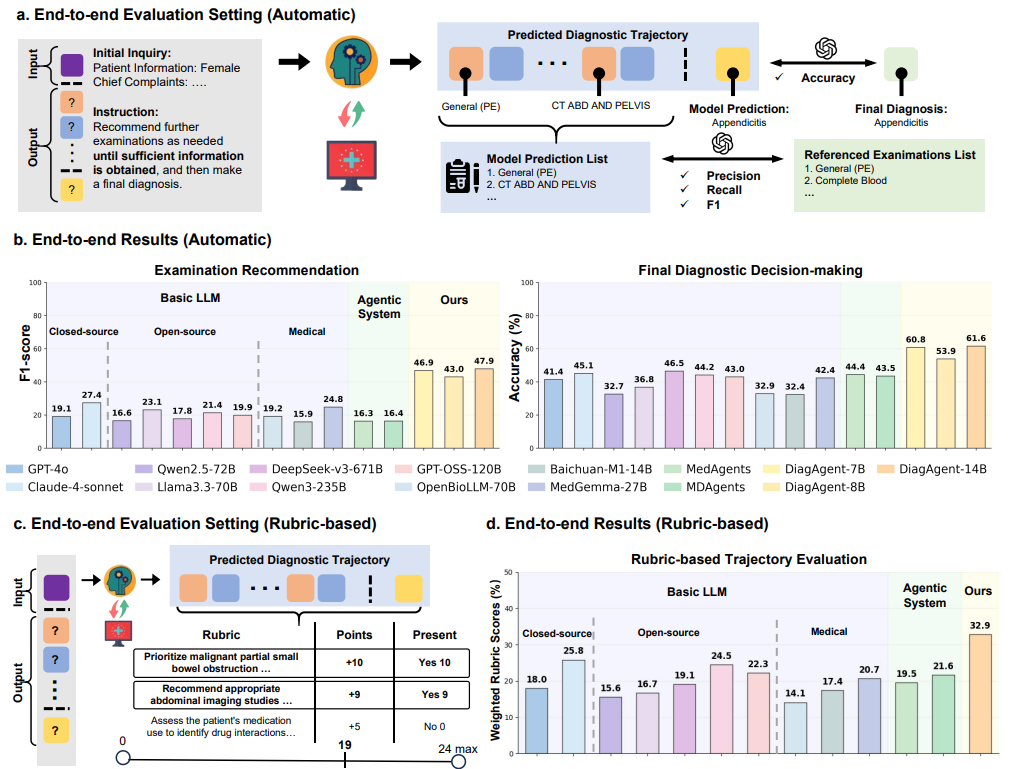
图5:DiagAgent端到端全程诊断评测框架与结果。
消融实验:
训练虚拟环境支撑强化学习
比简单利用现有样本进行SFT更加高效
框架的成功并非偶然。通过一系列消融实验,我们深入探究了DiagAgent 成功的关键因素。我们的消融实验结果如表3所示:
-
强化学习(**RL)显著优于监督微调(SFT):**在同等模型规模下,由DiagGym 虚拟环境支撑的强化学习策略,普遍为模型带来 10 至 15 个百分点以上的诊断准确率增益。
-
奖励设计是策略优化的核心:同时优化「诊断准确性」和「检查推荐质量」的双重奖励,能让模型在提升最终准确率的同时,大幅改善诊断路径的合理性。
-
强基座模型潜力更大:虽然所有模型都能从RL中获益,但更强的基座模型(如Qwen2.5-14B)能达到更高的性能上限。
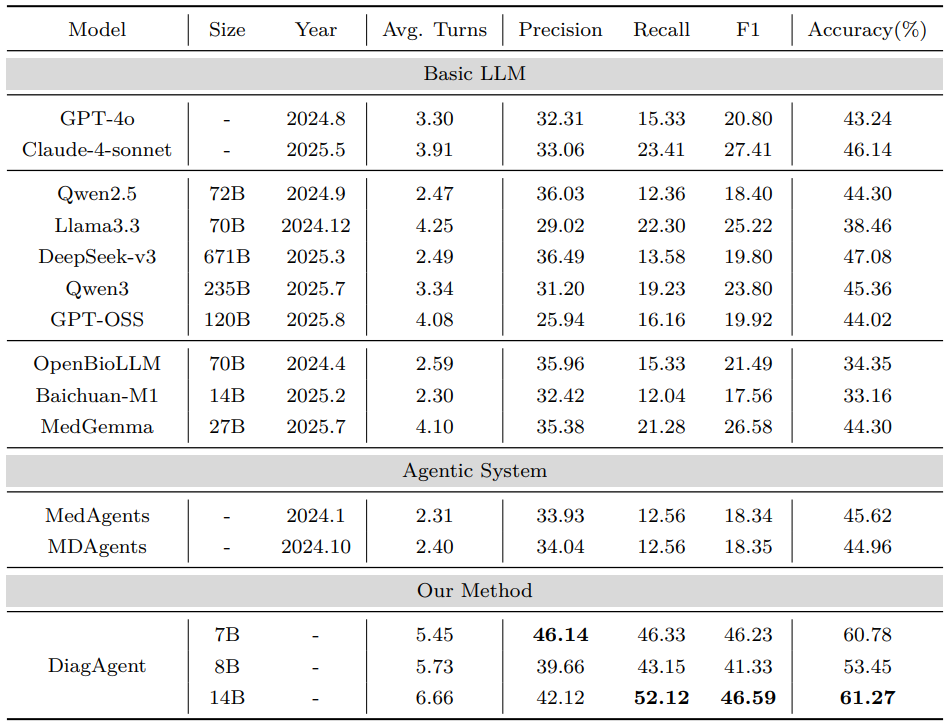
表3:消融实验结果
研究价值与未来展望
研究价值
对齐真实临床工作流:它将AI诊断从静态问答升级为动态策略学习,让智能体学会在不确定性下「主动搜证-评估-收敛」,更贴近真实世界。
开创**「环境-智能体」**闭环训练范式:DiagGym作为一个诊断学世界模型,提供了一个安全、可扩展的诊断智能体「训练场」,让智能体系统能自主探索海量诊疗路径,包括各种非典型的诊断交互轨迹,摆脱了旧有监督学习范式对收集有限、保守的诊断过程数据的依赖。
推动过程化评估:DiagBench首次在诊断交互轨迹上引入了带权重的rubrics来衡量「诊断过程」的质量,推动诊断AI的开发从「唯结果论」转向关注中间决策的合理性。
局限与展望
模型规模:当前实验主要基于7B-14B模型,未来扩展到千亿级模型有望进一步提升策略的深度和推理的上限。
任务范围:目前聚焦于「诊断」,未来可将「治疗方案、预后评估」等环节纳入虚拟环境和奖励函数,构建「诊疗一体化」的超级智能体。
环境扩展:DiagGym未来可以加入更多维度的模拟,如治疗反馈、费用/安全约束等,构建一个更全面的虚拟临床系统。
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献427条内容
已为社区贡献427条内容

所有评论(0)