Elastic Observability 的 AIOps:现代 AIOps 与 Log Intelligence
摘要:Elastic最新发布的Observability 9.2(Streams)通过AI驱动的日志智能技术革新AIOps实践。Streams工具集提供自动日志分类、多维异常检测和增强根因分析能力,能快速处理PB级日志数据,将非结构化日志转化为可执行洞察。该方案特别适用于云原生环境,通过将日志与指标、追踪数据关联,显著提升故障诊断效率。研究表明,使用Streams后,原本需要数小时的手动日志分析可
作者:来自 Elastic Sophia Solomon
探索现代 AIOps 能力,包括异常检测、日志智能,以及使用 Elastic Observability 进行日志分析与分类。
AIOps 博客回顾:使用 Elastic 解锁日志中的智能
Elastic 一直在 AIOps 领域领先,特别是在最新的 Elastic Observability 9.2(Streams)更新中。随着时间推移,关于 AIOps 的讨论已经发生巨大变化。DevOps 和 SRE 团队不再问 “是否需要 AIOps”,而是在问 “如何更有效地利用 AIOps 来应对指数级增长的复杂性”。
当前 AIOps 的挑战是:现代云原生环境产生的遥测数据规模远远超过以往。但许多团队忽略了一点:日志是最丰富的运维智能来源。日志能告诉你事情发生了什么、为什么发生;指标只会告诉你 “哪里不对劲”;链路追踪只会告诉你 “问题在哪里”。问题在于:大多数组织正被日志淹没。微服务(如用户认证、库存)、无服务器函数、Kubernetes 每天都会生成数百万条日志。如果没有 AI 和机器学习,从日志中找出关键模式会耗费巨大时间和精力。
日志智能的改进:2025 年的新变化
在过去的可观测性领域,要解锁日志智能需要大量手工操作,不仅要查看日志,还要对日志进行结构化处理。Elastic Observability 完全改变了团队从日志中提取价值的方式。可观测性不再只是简单的信号分析 —— 现代工具必须能够主动、基于日志地推动调查。而在 Elastic 中,这个现代工具就是 Streams。
Streams 是 Elastic 新推出的一组 AI 驱动工具,它通过为原始解析后的日志添加有意义的字段,识别重要事件。借助 Streams,SRE 可以最大化系统、日志和数据的价值。以系统可靠性为目标,Streams 能减少管道管理开销,加速可观测性分析。而且几乎不需要任何设置时间!
以下是 Streams 如何驱动目前 Elastic Observability 的能力:
高级日志速率分析
日志速率分析不仅仅是检测峰值。Elastic 的机器学习会自动识别日志量何时偏离预期基线,然后将这些变化放入你更广泛的系统性能中进行上下文化。当你的应用突然产生更多 error 日志时,Elastic 的 AIOps 不只是警报,它还会判断这是需要立即处理的严重问题,还是只是暂时的异常。
这对你的分析很重要,因为并不是所有日志峰值都一样。DEBUG 日志增加 10 倍可能意味着在生产环境中意外开启了冗长日志。ERROR 日志增加 2 倍可能表示出现了级联故障。日志速率分析会自动区分这些场景,为你的团队提供合适的上下文以便做出正确响应。
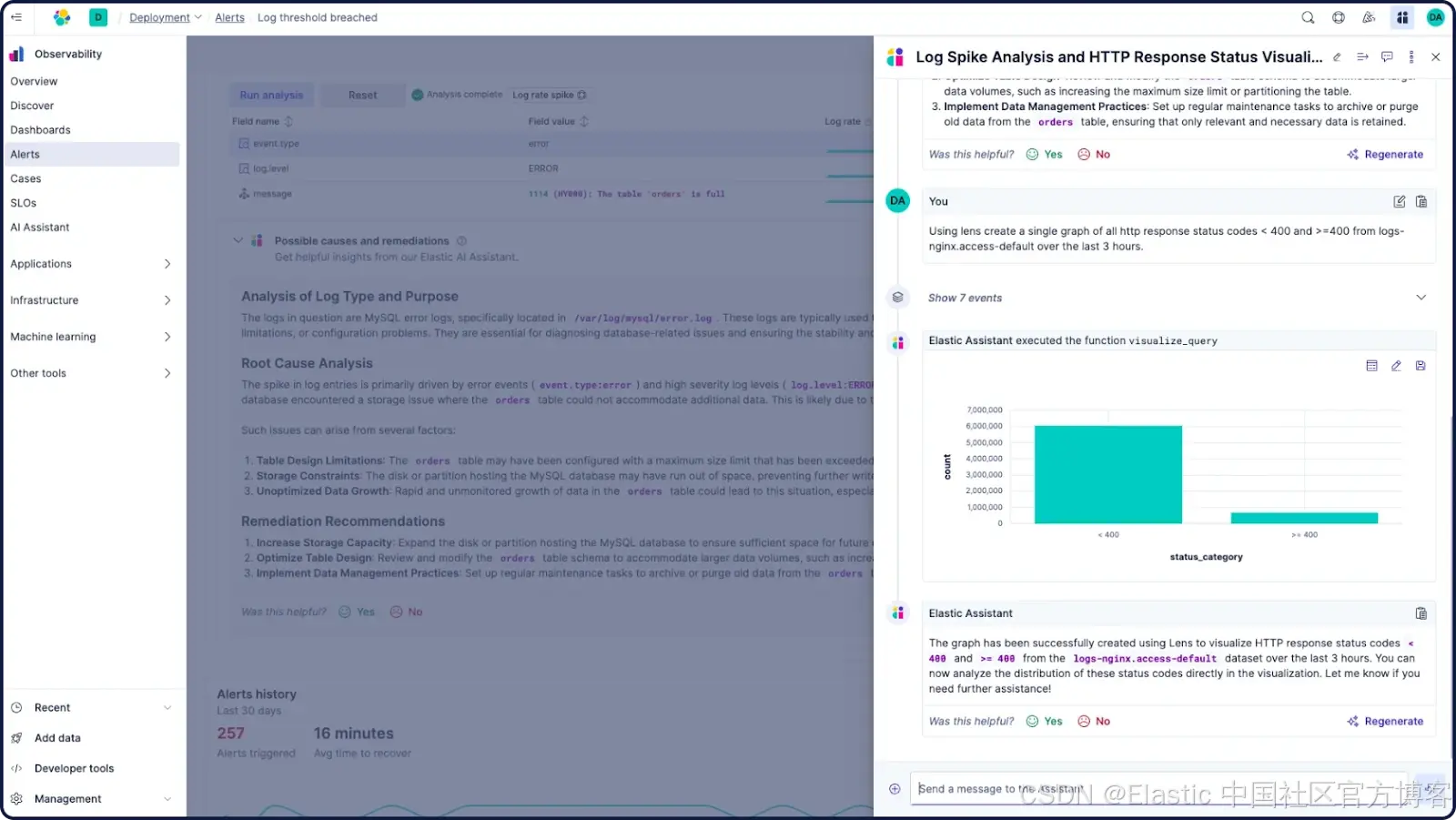
使用 Streams 的智能日志分类
这是 AIOps 在日志数据上大放异彩的地方。Streams 使用机器学习算法自动分类和分组相似的日志模式,大幅降低噪声。系统不再需要手动解析数百万条日志,而是自动识别常见结构、分组相关事件,并突出最重要的类别。
日志本质上是非结构化的,使其在大规模下难以分析。Streams 将混乱的日志流整理成有组织、可查询的模式。你可以立即看到 80% 的错误集中在三个类别中,帮助你优先决定修复重点。这种方法帮助你减少噪声并加速分析,让团队更快地依据洞察采取行动。
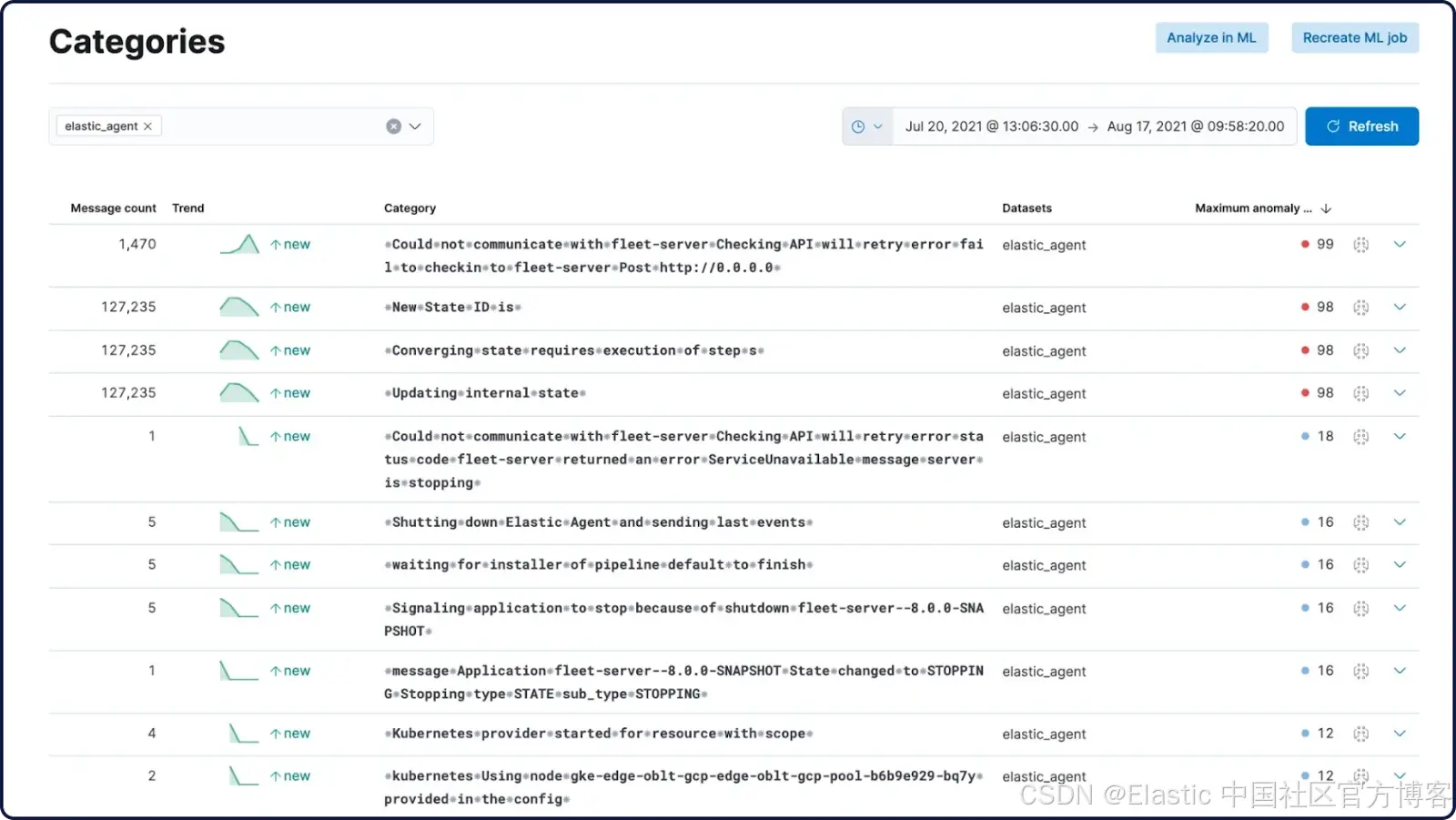
多维异常检测
异常检测现在会同时检查日志、指标和 traces 之间的关系。响应时间的轻微上升可能不会单独触发告警,但当它与异常日志模式和内存消耗变化相关联时,系统会将其识别为早期预警信号。
日志包含大量指标和 traces 无法捕捉的上下文信息:stack traces、user IDs、transaction 细节、错误消息等。通过将日志异常与其他信号关联,能获得系统中发生情况的完整图景。这种整体视图让团队能够更早发现问题,并理解它们在整个 stack 上的完整影响。
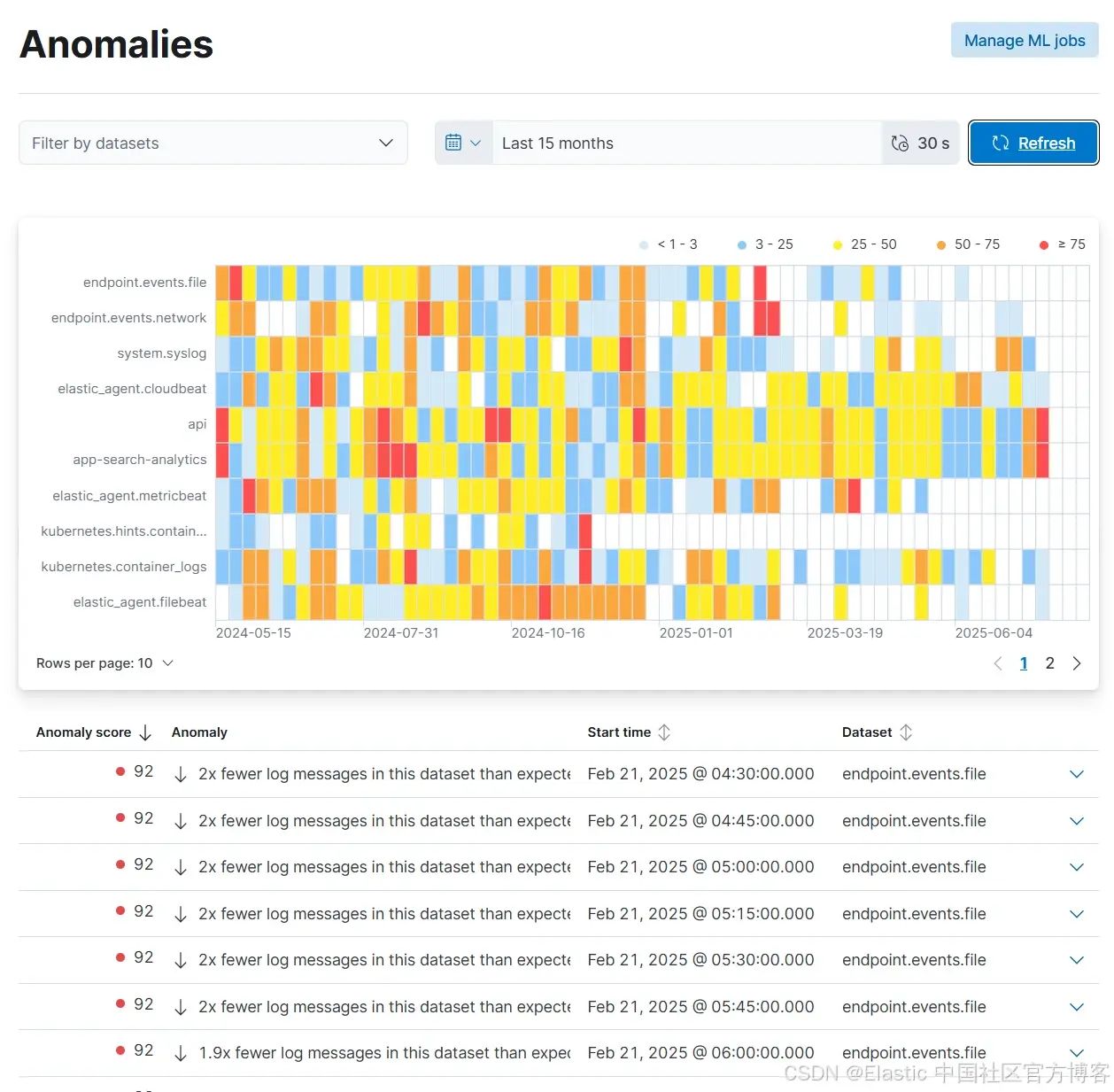
增强型根因分析由 Significant events 驱动
当问题发生时,Elastic 的 Streams 会通过 AI 辅助的日志解析和生成 “Significant events” 来加速根因分析。Significant event 查询可以由 AI 或手动定义,取决于你是否知道自己在寻找哪些日志。接着,Elastic 的 AIOps 会使用这些事件,以及经过增强的日志数据结合分布式 tracing,在整个 stack 中追踪问题。系统能够将失败的事务与特定日志条目、部署事件和基础设施变更相关联。这能帮助你理解不仅是哪里坏了,还包括为什么坏、什么时候坏。
Streams 会在几秒钟内跨你的整个分布式系统快速、自动地分析日志,获取相关日志条目,例如 stack traces、state 信息、错误消息等。过去需要数小时手动调查和推理的事情现在自动完成,让你和团队摆脱繁琐的排查工作,实现更快的故障解决。
日志实战:真实世界的影响
让我们看看这些能力在实际中是如何协同工作的。假设你的支付处理服务出现间歇性失败 —— 只有 0.5% 的交易出现问题,但已经足以让团队担忧。传统监控显示整体 “基本正常”,但客户仍在投诉。
没有 Streams 时,SRE 可能会先跑一些宽泛的查询,手动筛选成千上万条日志,难以将所有线索串联起来,最终无法理解错误与近期系统变更之间的关联。
有了 Elastic Streams 和 AIOps,这些潜在问题会被即时缓解:
- Streams 自动解析支付服务,将连接超时加入新的 Significant events 类别
- 使用 Streams 的日志速率分析发现,这类 Significant events 在过去一个月持续增长,从少量出现逐渐变为大量
- Elastic 内置的异常检测将这些 Significant events 与部署数据关联,识别它们出现在最近一次负载均衡配置之后
- 根因分析通过之前增强的日志追踪受影响的事务,精准定位数据库连接池设置在峰值负载下过于严格
原本需要 4–8 小时的手动日志分析,现在几分钟即可完成,Elastic 自动突出显示讲述完整故事的相关日志条目。这就是 AIOps 和 Streams 在日志智能中的力量。
统一日志智能的力量
Elastic 的优势在于把日志视为可观测性策略中的优先项。Elastic 提供全面的日志摄取,集中来自基础设施各处的 PB 级日志,并允许灵活的解析和增强。平台使用专门为日志模式设计的机器学习模型,而不是为日志分析“硬改”的通用算法。
日志不是孤立存在的,因此 Elastic 会将日志与 metrics、traces 以及业务事件关联,以提供完整上下文。而由于日志量可能非常大,Elastic 的分层存储方式允许你保留多年的日志,用于合规和历史分析,同时避免高成本。
为什么日志比以往任何时候都更重要
日志成为高效 AIOps 的基石,有三个关键原因。
首先,日志捕获 metrics 无法提供的信息。metric 告诉你 CPU 已达到 80%,但日志会告诉你是哪一个进程在消耗资源,以及为什么会这样。这个细节对理解问题原因至关重要。
其次,日志提供业务上下文。错误消息包含用户 ID、transaction 详情和业务逻辑失败,帮助你理解客户影响。当你排查问题时,知道哪些客户受影响、他们试图做什么,对确定响应优先级极其重要。
第三,日志实现真正的根因分析。stack traces、错误消息和应用状态都在日志中,这些信息是理解每次事故 “为什么” 的关键。如果没有这些信息,团队只能猜测根因,而不是明确识别和修复。
在 2025 年获胜的团队不是只监控 metrics,而是从日志规模化提取智能,把运营数据转化为可执行洞察。
立即升级你的日志策略
每一个团队花在手动翻日志上的小时,都是本可以用来创新的时间。每一个本可通过智能日志分析提前预防的事故,都意味着技术债和业务风险。
Elastic Observability 提供解锁日志智能的基础能力。通过自动分类、异常检测和 ML 驱动分析,你可以立即看到价值。查看这篇最新文章,今天就开始使用 Elastic Streams 和 Observability 吧!
原文:https://www.elastic.co/observability-labs/blog/modern-aiops-elastic-observability

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)