On the Constrained Time-Series Generation Problem
在计算效率方面,下表的实验结果表明,Guided-DiffTime相比Loss-DiffTime可减少高达92%的碳足迹,这一显著提升主要源于三个关键因素:彻底消除了重复训练的需求,通过DDIM加速方法大幅减少扩散步数,以及整体采样效率的优化提升。相比于需要针对每个新约束重新训练模型的方法,Guided-DiffTime在保持生成质量的同时,显著提升了使用的便捷性和效率,为约束时间序列生成技术的实
目录
1 研究背景与核心问题
1. 1 研究背景
合成时间序列(TS)在数据增强、罕见事件模拟、反事实场景构建等领域应用广泛。例如金融领域的市场压力测试场景生成、能源领域的能耗数据补全,均需合成数据同时满足真实性(与真实数据分布一致)和约束满足性(符合业务规则或物理定律)。
1.2 现有方法缺陷
当前时间序列生成模型的约束施加机制存在显著局限:1)约束施加方式较为低效,多通过损失惩罚或拒绝采样实现,难保证约束完全满足,且拒绝采样计算成本高;2)灵活性不足,新增约束往往需要重新训练模型,导致计算开销庞大且碳足迹显著;3)同时约束类型覆盖范围有限,难以同时支持多样化的约束需求。
1.3 核心目标
提出高效、可扩展的约束时间序列生成方法,在保证合成数据真实性的前提下,灵活适配各类约束,无需重复训练。
2 问题定义
2.1 输入与输出
输入:原始数据集(
,L 为序列长度,K 为特征数)和约束列表C;
输出:满足约束C且与D分布一致的合成时间序列。
2.2 约束类型分类
| 分类维度 | 类型说明 | 示例 |
|---|---|---|
| 约束强度 | 硬约束 | 必须满足(如股票数据中 High≥Close≥Low) |
| 软约束 | 优化目标(如趋势拟合、最小化 L2 距离) | |
| 作用范围 | 局部约束 | 单个/部分时间点(如第 10 个时刻值固定为 5) |
| 全局约束 | 全序列属性(如全局最小值位于第 15 时刻) | |
| 具体形式 | 趋势约束 | 序列需贴合给定趋势曲线 s |
| 固定点约束 | 特定位置值固定 | |
| 多元约束 | 多特征间关系(如 High 为最大值、Low 为最小值) |
3 核心方法详解
3.1 COP:约束优化方法
COP是一种传统约束优化方法。它将每个点作为决策变量,并从真实数据集中选取一个数据作为种子TS。它有两种用途,一是从种子TS开始生成新的数据,二是给其他模型的输出做“修正”(即微调)。它将目标函数定义为合成序列与种子TS的L2范数:
在做生成时,为了保持生成的多样性,训练目标是最大化目标函数;在做微调时,为了使其他模型生成的序列满足约束,训练目标是最小化目标函数以减小差异。
约束类型分为真实性约束和用户自定义约束。真实性约束(保证统计属性一致)的公式如下:
其中:
为计算序列属性的函数(比如自相关性);
是误差函数(比如 L2 范数);
为误差预算。
用户约束可以分为硬约束和软约束。硬约束包括等式约束和不等式约束,软约束的代表是趋势约束,公式如下:
其中:
s是约束目标序列
真实性项:,衡量合成序列
与真实序列
的相似度,距离越小真实性越强;
约束项:,s是约束目标(比如趋势序列),距离越小约束满足度越高;
是权重,调节真实性和约束满足度的优先级。
COP的优点是约束满足度高,真实性强;缺点在于计算成本高,依赖初始种子序列。
3.2 DiffTime:条件扩散模型基础方法
针对COP的缺陷,本文又提出了基础深度学习方法——基于扩散模型的DiffTime。DiffTime利用扩散模型隐式学习数据分布,通过条件生成直接支持趋势和固定点约束,避免COP方法中的显式定义所有数据属性。
3.2.1 模型架构
CSDI原本用于概率时序插补,其基于分数的扩散框架可灵活处理时序数据的动态特征并支持条件约束融入。此外,它的条件建模能力可直接迁移到趋势、固定点等约束场景,只需少量适配,就能快速实现约束时序生成,无需从零设计模型结构。DiffTime复用这一架构,减少了基础模块开发成本,模型的整体架构如下图所示:
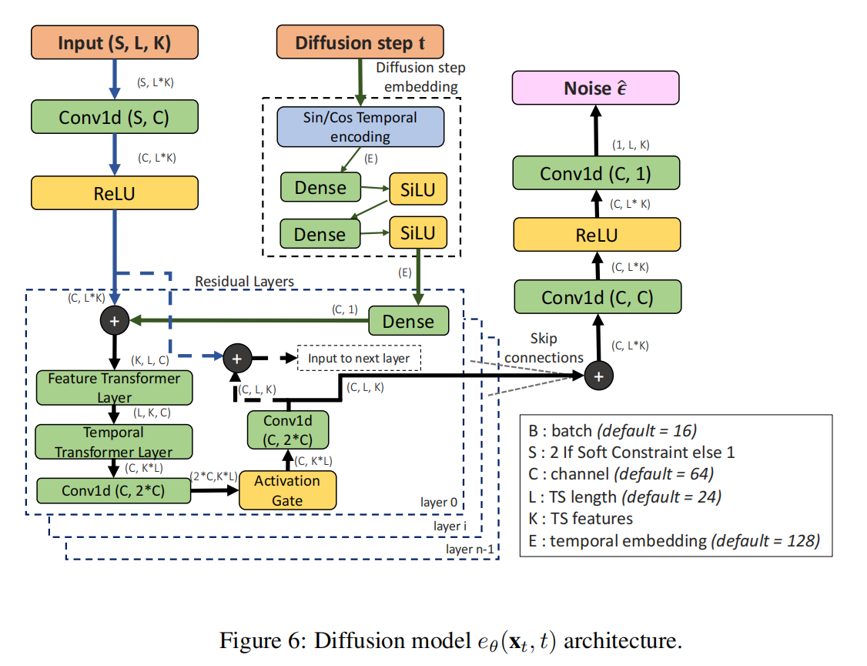
CSDI和DiffTime的主要对比如下表所示:
| 对比维度 | CSDI | DiffTime |
|---|---|---|
| 核心任务 | 概率性时间序列插补 | 带约束的全新时间序列生成 |
| 核心目标 | 利用观测数据估计缺失部分的分布,填补不完整时序 | 生成符合约束的高可信度时序,支持反事实场景构建 |
| 约束类型 | 观测值约束(隐含约束,基于已有数据片段) | 1. 软约束:趋势约束2. 硬约束:固定点约束 |
| 约束实现机制 | 将观测到的数据片段作为条件信息,输入去噪函数引导缺失值填补 | 1. 趋势约束:通过条件化扩散过程,将趋势序列s作为条件输入2. 固定点约束:扩散每步反向采样后,对约束点强制赋值 |
| 模型架构 | 基于Transformer的纯注意力架构,包含特征Transformer层和时间Transformer 层,专注全局依赖捕捉 | 卷积+Transformer混合架构:1. 一维卷积层捕捉局部依赖2. 自注意力机制处理全局依赖 |
| 训练策略 | 自监督训练:从完整数据中随机选择部分特征作为 "缺失值",其余作为观测值,学习数据内在结构 | 条件化训练:从真实时序中提取趋势作为条件信息,训练模型学习真实序列围绕趋势的波动模式 |
| 输入数据要求 | 输入为不完整时序(含观测值和缺失值标记) | 输入为随机噪声(生成种子)+ 约束条件(趋势序列 / 固定点集合) |
| 核心优势 | 1. 概率插补性能优异,误差显著低于传统方法2. 能捕捉数据内在依赖关系,插补结果贴合真实分布 | 1. 同时支持软 / 硬约束,约束满足度高2. 混合架构兼顾短期波动和长期趋势建模3. 生成时序多样性强 |
CSDI的辅助信息嵌入(如时间戳标记、特征类型编码、观测掩码嵌入)是为解决 “不规则观测时序的插补问题” 而设——通过额外元信息帮助模型定位缺失位置、区分特征属性、理解观测稀疏性,进而精准推断缺失值与观测值的关联。而DiffTime的核心目标是 “生成全新且满足约束的时序”,不存在 “观测/缺失” 的二元划分,也无需通过元信息锚定数据位置,因此这类辅助嵌入反而会成为冗余计算。
DiffTime将所有约束信息直接融入输入张量的通道维度:将与目标时序同形状的趋势序列s和带噪声的生成种子(随机噪声)在底层拼接,形成双通道输入(形状为 (Batch Size, 2, L, K))。这种设计让约束信息与带噪声的种子深度绑定,网络从去噪初始阶段就能感知约束方向,而非依赖外部辅助嵌入间接传递信息,契合 “约束引导生成” 的核心需求。
相比于CSDI基于Transformer的纯注意力架构,DiffTime使用一维卷积聚焦时间序列中相邻时间步的关联(如短期波动、局部趋势),并通过Transformer的自注意力机制建模时序中远距离时间步的关联(如年度周期性、长期趋势延续性)。
此外,它还做出了一项创新,即根据时间序列的波动性和长度调整卷积核的尺寸。对于波动剧烈且周期较短的序列(如长度为24的股票数据),只需要较小的卷积核(如2)即可;对于波动性弱且周期性长的序列(如正弦数据),需要更大的卷积核(如6)才能捕捉周期;对于波动剧烈且周期很长的序列(如长度为360的股票数据),则需要更大的卷积核(如24)。
3.2.2 趋势约束
趋势约束是一种软约束,它要求生成的时间序列在整体形态上逼近用户指定的趋势序列(其中
表示时间序列的样本空间)。DiffTime通过巧妙设计,使模型能够理解并学习“趋势” 这一概念。
在训练阶段,模型所学习的目标趋势s并非外部给定的抽象概念,而是直接从当前训练所用的真实时间序列中,通过低阶多项式插值计算得到。这一设计的深远用意在于,它迫使模型去学习的不是简单地复制一条曲线,而是理解真实序列与其平滑趋势s之间的关系,即序列围绕趋势的波动模式。
到了推理阶段,用户便可以自定义任意趋势s(如一条正弦波或抛物线),模型将利用其在训练中学到的“填充”能力,生成一条既贴合该新趋势s,又保持合理波动性的逼真序列。这种约束的“软”性体现在其优化目标上,即最小化生成序列与趋势s的L2距离,而非强制完全重合。
从数学上看,这一过程通过条件化扩散实现。模型的去噪函数在训练时不再只依赖于噪声数据
和步数 t,而是将趋势s作为条件信息一同输入。其训练目标遵循:
在反向生成过程的每一步,趋势s都参与指导生成方向,如下面公式所示:
3.2.3 固定点约束
与趋势约束的宏观引导不同,固定点约束是一种硬约束,它要求生成的时间序列在特定的时间点i和特征维度j上必须精确匹配预设值。DiffTime实现该约束的机制非常直接,它并不主要依赖于修改损失函数,而是采用了算法层面的强制干预。
在扩散模型的反向生成过程中(从到
),每一步生成
的通用过程可以表示为:
为了引入固定点约束,DiffTime在每一步得到后,会执行一个额外的步骤:对于约束集合R中的每一个固定点
,直接执行赋值操作
。这个操作的具体描述如算法7所示:

通过这种在每一步去噪迭代中都对中间结果进行“硬编码”,可以确保最终输出的序列
百分之百满足所有定点要求。模型会自适应地在约束点周围生成连贯且合理的序列值,从而在满足硬约束的同时,保持时间序列的整体真实性。
3.3 Loss-DiffTime:带约束惩罚的扩散模型
尽管DiffTime能够有效处理趋势和固定点约束,但其约束类型相对固定,无法灵活适应任意形式的用户定义约束。为了突破这一限制,本文提出了Loss-DiffTime方法,通过在扩散模型的训练目标中引入约束违反惩罚项,实现对任意可微约束的支持。
3.3.1 核心思想:约束的损失函数嵌入
Loss-DiffTime的核心创新在于将约束满足问题转化为优化问题。不同于DiffTime的条件生成机制,Loss-DiffTime在训练过程中通过在损失函数中增加惩罚项来“教导”模型生成符合约束的样本。其基本思想如下:
其中:
是标准的扩散模型去噪损失;
是约束违反惩罚项;
是约束权重超参数,用于平衡数据拟合与约束满足。
3.3.2 训练过程的特殊处理
Loss-DiffTime的训练需要解决一个关键技术挑战:扩散模型在训练时优化的是噪声预测损失,而约束通常定义在最终生成样本 上。
我们采用重参数化技巧来解决这一矛盾。在每一步训练中:
- 从噪声数据
预测噪声
- 通过去噪公式估计干净数据
:
- 在估计的
其中:
为惩罚权重;
为约束函数。
相比于DiffTime,Loss-DiffTime能处理任意可微的复杂约束,但它有两个主要问题:1)它将约束以惩罚项形式“硬编码”进模型参数,导致参数与特定约束深度绑定,致使任何约束变更都需重新训练;2) 扩散模型通常需要多个迭代步骤T,这会使生成过程变慢且成本高昂 。
3.4 Guided-DiffTime:梯度引导的扩散模型
3.4.1 方法概述与核心思想
Guided-DiffTime是本文提出的最具创新性的解决方案,它成功突破了Loss-DiffTime和DiffTime模型在新约束条件下需要重新训练的限制。该方法的核心思想是通过推理时梯度引导机制,将约束满足过程与模型参数学习完全解耦,实现真正的"一次训练,多约束推理"能力。
3.4.2 技术架构与工作原理
Guided-DiffTime基于Denoising Diffusion Implicit Models (DDIM)构建,采用非马尔可夫过程实现采样加速。DDIM是针对DDPM推理效率低的问题提出的改进算法。通过打破马尔可夫链约束实现了跳步采样,仅需少量迭代即可获得高质量结果。采样公式的推导过程如下:


其逆向过程可以表示为:
其中,通过设置,使得前向过程变为确定性,从而大幅减少扩散步数,提高生成效率,具体算法如下所示:

3.4.3 创新优势分析
Guided-DiffTime在约束时间序列生成领域实现了根本性的突破,其核心创新体现在训练与推理的彻底解耦。该方法在训练阶段让模型专注于学习真实时间序列的数据分布,完全不需要接触任何约束信息,从而建立了一个强大的基础生成模型。而在推理阶段,通过引入梯度引导机制,模型能够实时融入各种约束条件,实现前所未有的灵活适配能力。这种解耦设计使得同一个训练好的模型能够动态适应多种不同的约束要求,无需重新训练即可应对新的生成任务。
在计算效率方面,下表的实验结果表明,Guided-DiffTime相比Loss-DiffTime可减少高达92%的碳足迹,这一显著提升主要源于三个关键因素:彻底消除了重复训练的需求,通过DDIM加速方法大幅减少扩散步数,以及整体采样效率的优化提升。这种效率优势使得该方法在资源受限的环境下仍能高效运行,为实际部署提供了坚实保障。
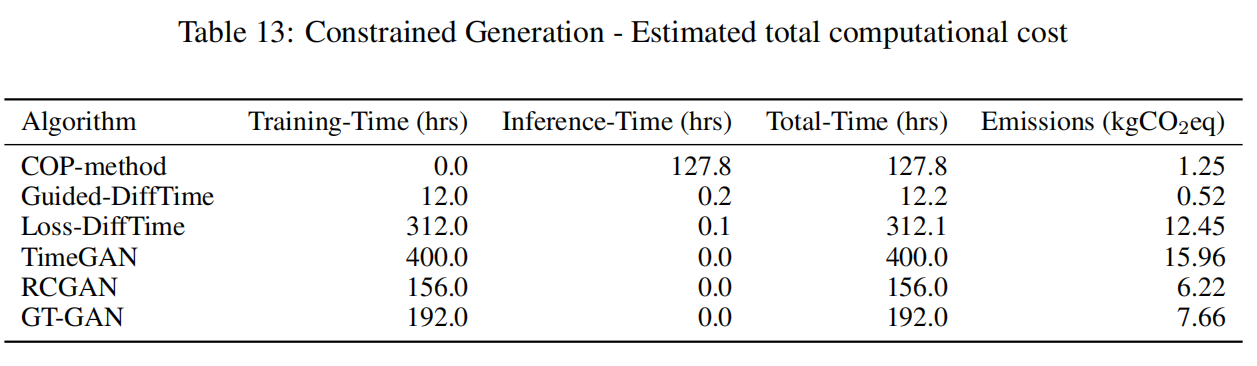
这种创新架构不仅解决了传统方法在新约束条件下需要重新训练的核心问题,还通过高效的推理机制实现了真正的“一次训练,多次约束推理”的目标。相比于需要针对每个新约束重新训练模型的方法,Guided-DiffTime在保持生成质量的同时,显著提升了使用的便捷性和效率,为约束时间序列生成技术的实际应用开辟了新的可能性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)