AAAI 2026|厦大提出NFA-ViT:实现局部图像篡改检测精准定位
本文提出BR-Gen数据集和NFA-ViT模型,针对AI生成图像中背景/场景等局部篡改检测难题。通过噪声引导注意力机制增强伪造特征传播,结合加权解码器提升定位精度。实验表明,该方法在BR-Gen数据集上F1达0.972,IoU达0.907,并展现强泛化能力。研究为局部伪造检测提供了新思路,但噪声提取质量对效果影响较大,未来需优化轻量化部署。
一、导读
如今,人工智能技术能够生成或修改图像,导致虚假图片泛滥,威胁信息真实性。现有检测方法主要针对整张伪造图片或物体级别的篡改,却难以识别对背景、天空等大面积场景区域的局部修改,导致检测效果不佳。
为了解决这一问题,本文提出了一个名为 BR-Gen 的大规模局部伪造图像数据集,并设计了 NFA-ViT 模型,通过噪声引导的注意力机制放大伪造痕迹。
实验表明,该方法在多种场景下均优于现有技术,显著提升了局部伪造检测的准确性和鲁棒性。
二、论文基本信息

-
论文标题:Zooming In on Fakes: A Novel Dataset for Localized AI-Generated Image Detection with Forgery Amplification Approach
-
作者姓名与单位:Lvpan Cai, Haowei Wang, Jiayi Ji 等,来自厦门大学、腾讯优图实验室、新加坡国立大学
-
发表日期与会议/期刊来源:AAAI 2026
-
项目地址:https://github.com/clpbc/BR-Gen
三、主要贡献与创新
-
提出BR-Gen数据集,覆盖背景与场景类局部伪造,弥补现有数据偏差。
-
设计NFA-ViT模型,利用噪声引导注意力机制增强伪造特征传播。
-
提出概率语义扰动方法,提升生成内容的语义多样性与一致性。
-
提出加权解码器,自适应融合多尺度特征以提升定位精度。
-
实验证明模型在多个基准数据集上具有强泛化能力。
四、研究方法与原理
NFA-ViT 的核心思路是:利用图像噪声特征引导视觉注意力,将局部伪造特征扩散至整张图像,从而增强检测能力。
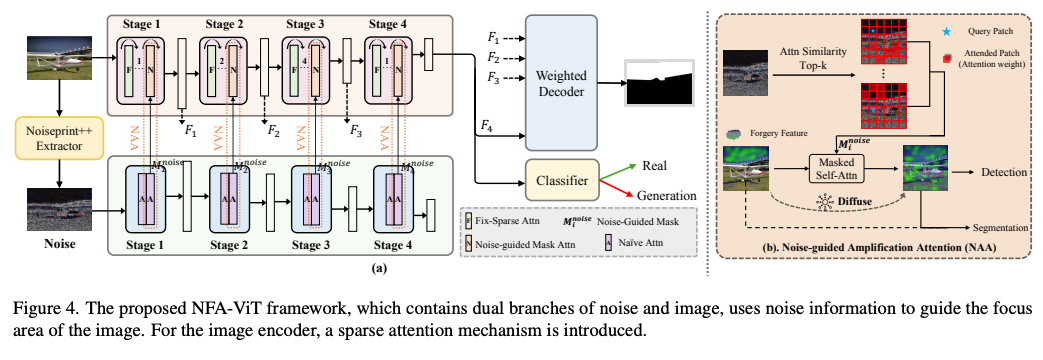
-
噪声提取:使用 Noiseprint++ 提取图像的噪声痕迹 。
-
噪声引导注意力(NAA):在图像分支中,利用噪声分支生成的注意力掩码 引导图像特征交互。具体地,噪声分支输出注意力矩阵:
从中选取最不相似的 个位置构成掩码 ,用于图像分支的特征融合:
-
加权解码器:对多层特征 进行加权融合,引入可学习参数 :
-
损失函数:结合分类与分割损失:
五、实验设计与结果分析
-
实验设置:使用 BR-Gen 数据集(15万张局部伪造图像),评测指标包括 Recall@50、F1、AUC、IoU。
-
跨域测试:在 BR-Gen 上测试现有模型,发现其性能显著下降,尤其对背景和场景类伪造检测效果差。
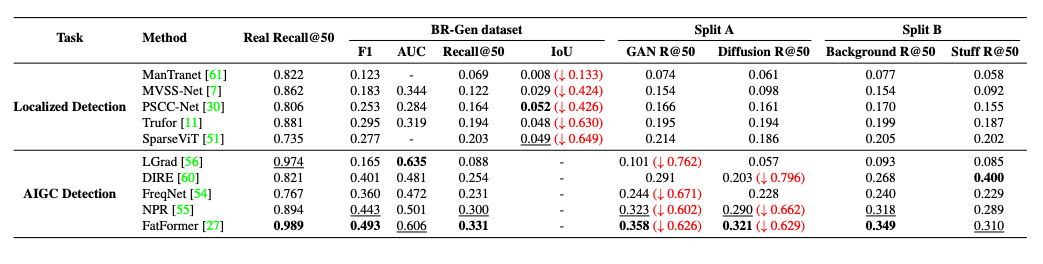
-
域内测试:在 BR-Gen 上训练后,NFA-ViT 在检测与定位任务上均最优,F1 达 0.972,IoU 达 0.907。
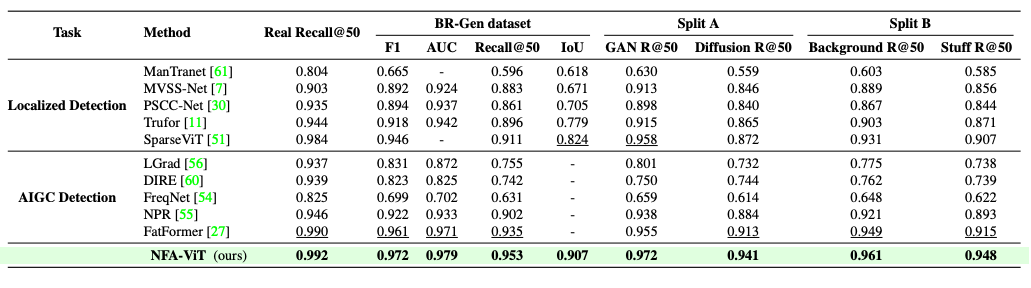
-
跨类型测试:NFA-ViT 在不同生成方法与掩码类型间表现出最强泛化能力。

-
泛化测试:在 CocoGLIDE、GRE 等外部数据集上,NFA-ViT 仍优于现有方法。

-
消融实验:验证了噪声引导注意力与加权解码器的有效性。

-
可视化对比:NFA-ViT 在定位伪造区域时更准确、边界更清晰。

六、论文结论与评价
-
总结本文提出了一个面向场景级局部伪造检测的数据集 BR-Gen 与噪声引导的检测模型 NFA-ViT,通过噪声特征增强伪造信号的传播,显著提升了检测与定位性能,并在多个基准测试中表现出强泛化能力。
-
评价该研究为局部伪造检测提供了更全面的数据基础与有效的技术路径,尤其适用于背景、场景等复杂区域的篡改识别。
不足之处在于数据生成流程依赖多个预训练模型,可能存在误差累积;此外,模型对噪声质量敏感,若噪声提取不准确可能影响检测效果。
未来可进一步优化噪声提取模块,并探索更轻量的检测架构以适应实际部署需求。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)