使用 Elastic Agent Builder 和 GPT-OSS 构建一个用于 HR 的 AI agent
本文介绍了如何使用Elastic Agent Builder和GPT-OSS构建一个本地化HR AI助手。通过LM Studio运行GPT-OSS模型,并结合Elastic Cloud部署,可以创建一个能够回答员工数据查询的AI代理,同时确保数据不离开本地环境。文章详细说明了五个实施步骤:配置LM Studio、部署本地Elastic、创建OpenAI连接器、上传员工数据以及构建测试AI代理。该方
作者:来自 Elastic Tomás Murúa

发现如何使用 Elastic Agent Builder 和 GPT-OSS 构建一个可以回答关于你员工 HR 数据的自然语言查询的 AI agent。
更多阅读:
Agent Builder 现在作为技术预览提供。通过 Elastic Cloud Trial 开始使用,并在此查看 Agent Builder 的文档。
介绍
这篇文章将向你展示如何使用 GPT-OSS 和 Elastic Agent Builder 构建一个用于 HR 的 AI agent。这个 agent 可以在不将数据发送到 OpenAI、Anthropic 或任何外部服务的情况下回答你的问题。
我们将使用 LM Studio 在本地运行 GPT-OSS,并将其连接到 Elastic Agent Builder。
在本文结束时,你将拥有一个自定义的 AI agent,它可以回答关于你员工数据的自然语言问题,同时保持对你的信息和模型的完全控制。
先决条件
本文章你需要:
- Elastic Cloud 托管的 9.2、serverless 或本地部署
- 建议 32GB RAM 的机器(运行 GPT-OSS 20B 最低 16GB)
- 安装了 LM Studio
- 安装了 Docker Desktop
为什么使用 GPT-OSS?
使用本地 LLM,你可以控制将其部署在自己的基础设施里,并微调它以符合你的需求。所有这些都能保持你与模型共享的数据的控制权,而且当然,你不需要向外部提供商支付许可费用。
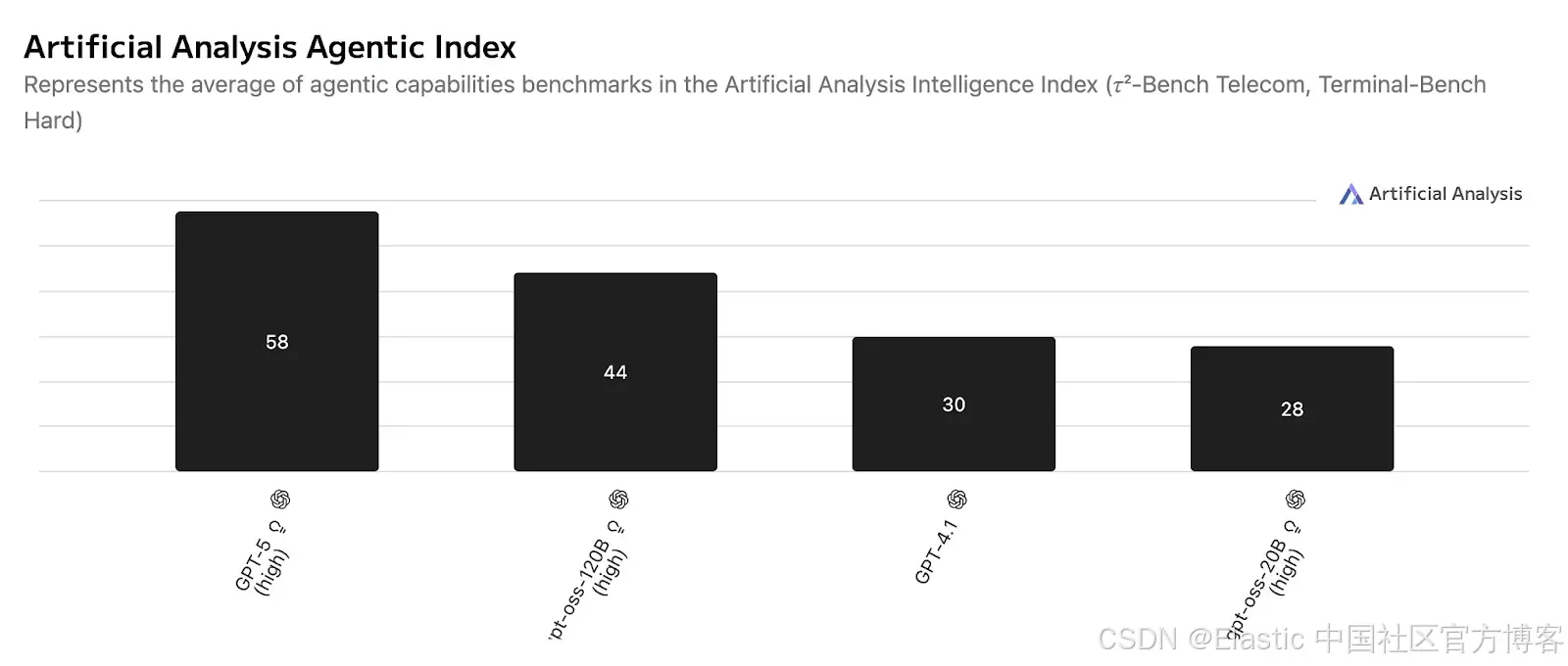
OpenAI 在 2025 年 8 月 5 日发布了 GPT-OSS,作为其对开放模型生态系统承诺的一部分。
这个拥有 20B 参数的模型提供:
- 工具使用能力
- 高效推理
- 兼容 OpenAI SDK
- 兼容 agentic workflows
基准比较:
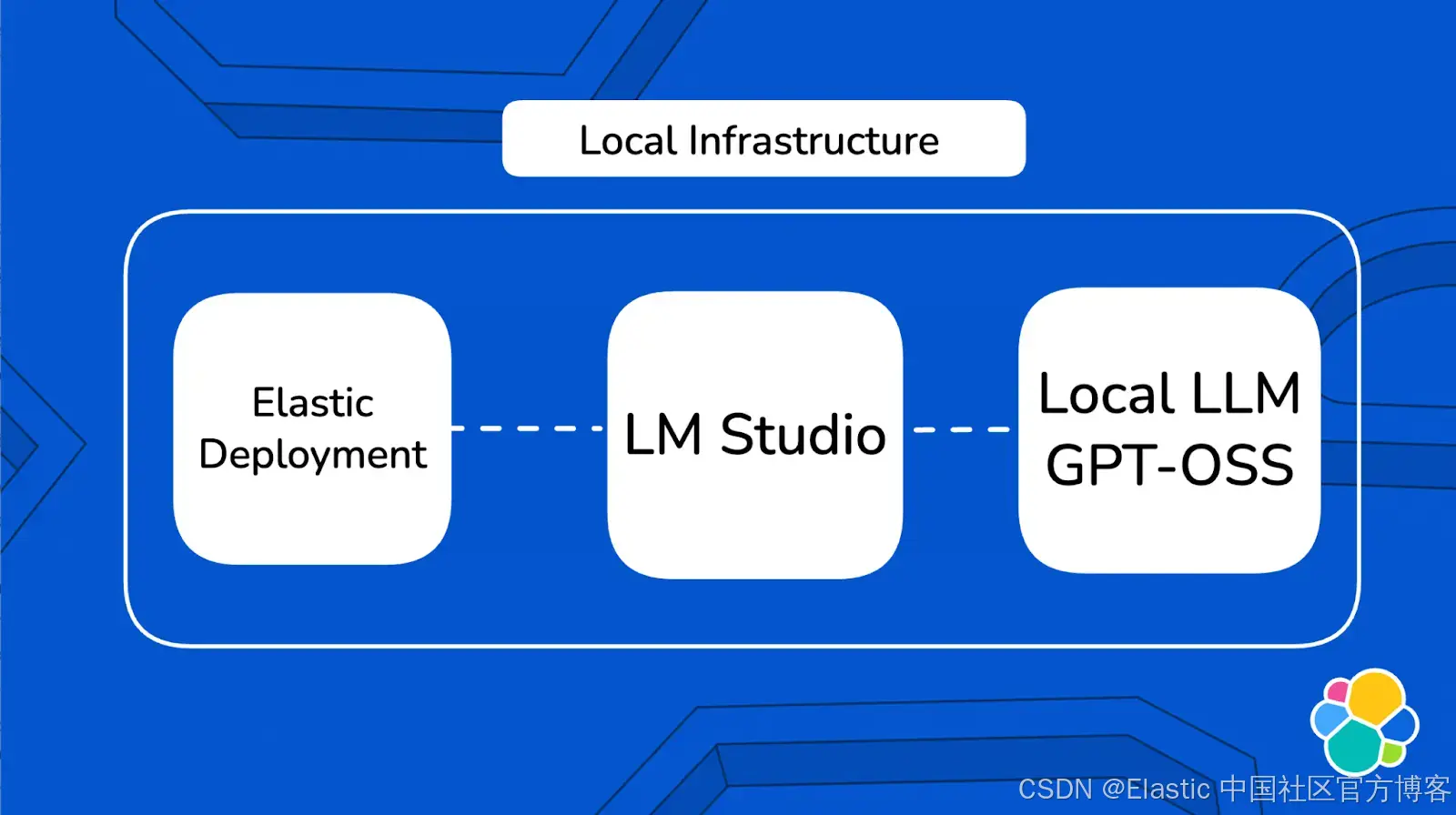
解决方案架构
整个架构完全在你的本地机器上运行。Elastic(运行在 Docker 中)通过 LM Studio 直接与你的本地 LLM 通信,Elastic Agent Builder 使用这个连接来创建可以查询你员工数据的自定义 AI agent。
更多详情请参考这个文档。
为 HR 构建 AI agent:步骤
我们将把实现分成 5 个步骤:
- 配置 LM studio 使用本地模型
- 使用 Docker 部署本地 Elastic
- 在 Elastic 中创建 OpenAI connector
- 把员工数据上传到 Elasticsearch
- 构建并测试你的 AI Agent
步骤 1:使用 GPT-OSS 20B 配置 LM Studio
LM Studio 是一个用户友好的应用程序,允许你在本地电脑上运行大型语言模型。它提供一个兼容 OpenAI 的 API 服务器,使它能轻松集成到 Elastic 等工具中,而不需要复杂的设置过程。更多细节请参考 LM Studio Docs。
首先,从官方网站下载并安装 LM Studio。安装完成后,打开应用程序。
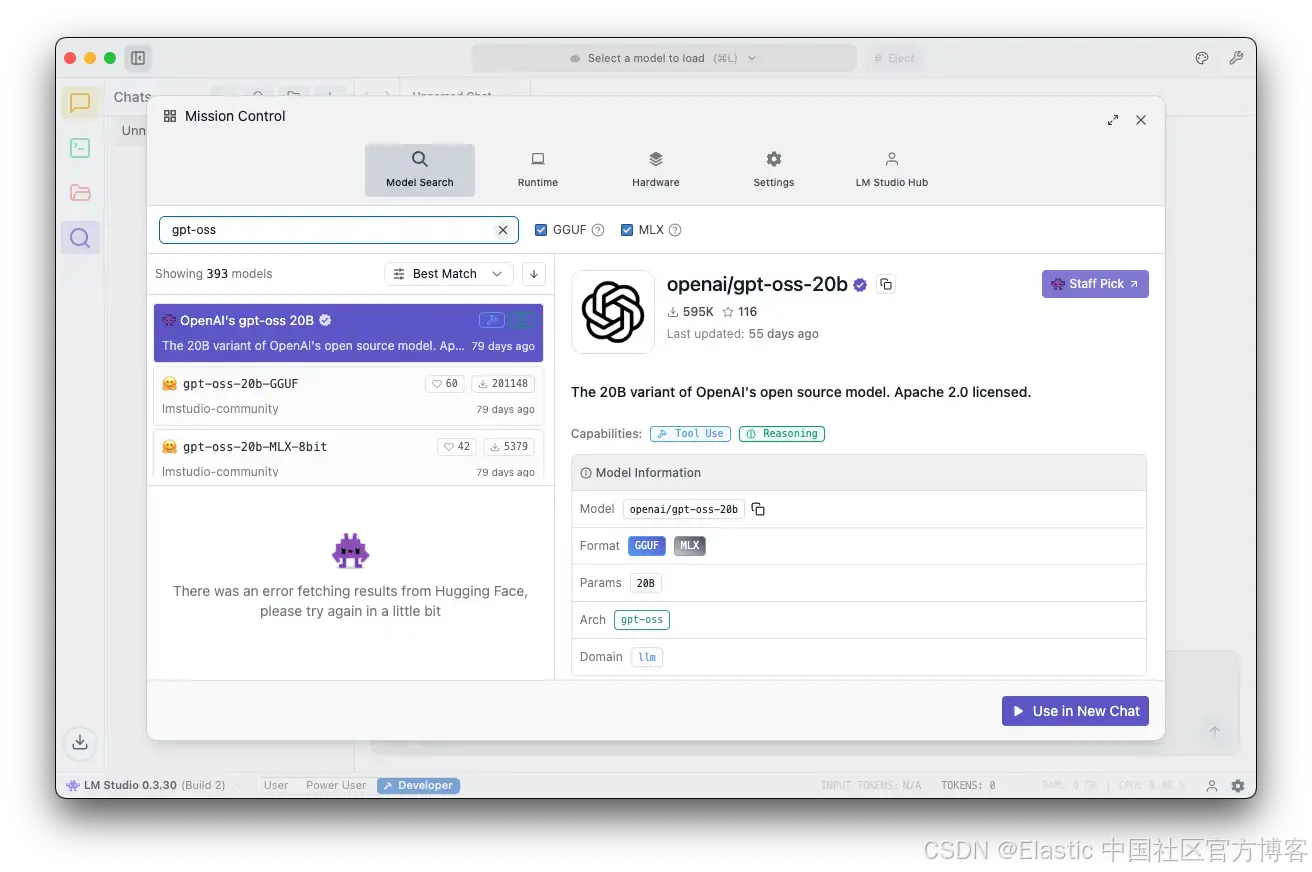
在 LM Studio 界面中:
- 进入搜索标签并搜索 “GPT-OSS”
- 选择来自 OpenAI 的 openai/gpt-oss-20b
- 点击下载
这个模型的大小大约为 12.10GB。下载时间取决于你的网络速度,可能需要几分钟。
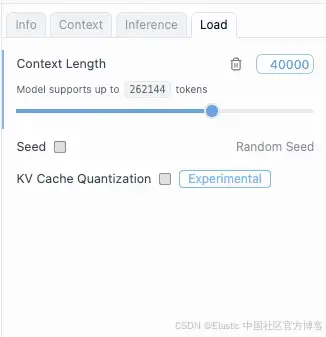
模型下载完成后:
- 进入本地服务器(local server)标签
- 选择 openai/gpt-oss-20b
- 使用默认端口 1234
- 在右侧面板进入 Load 并将 Context Length 设置为 40K 或更高
-
点击 Start Server
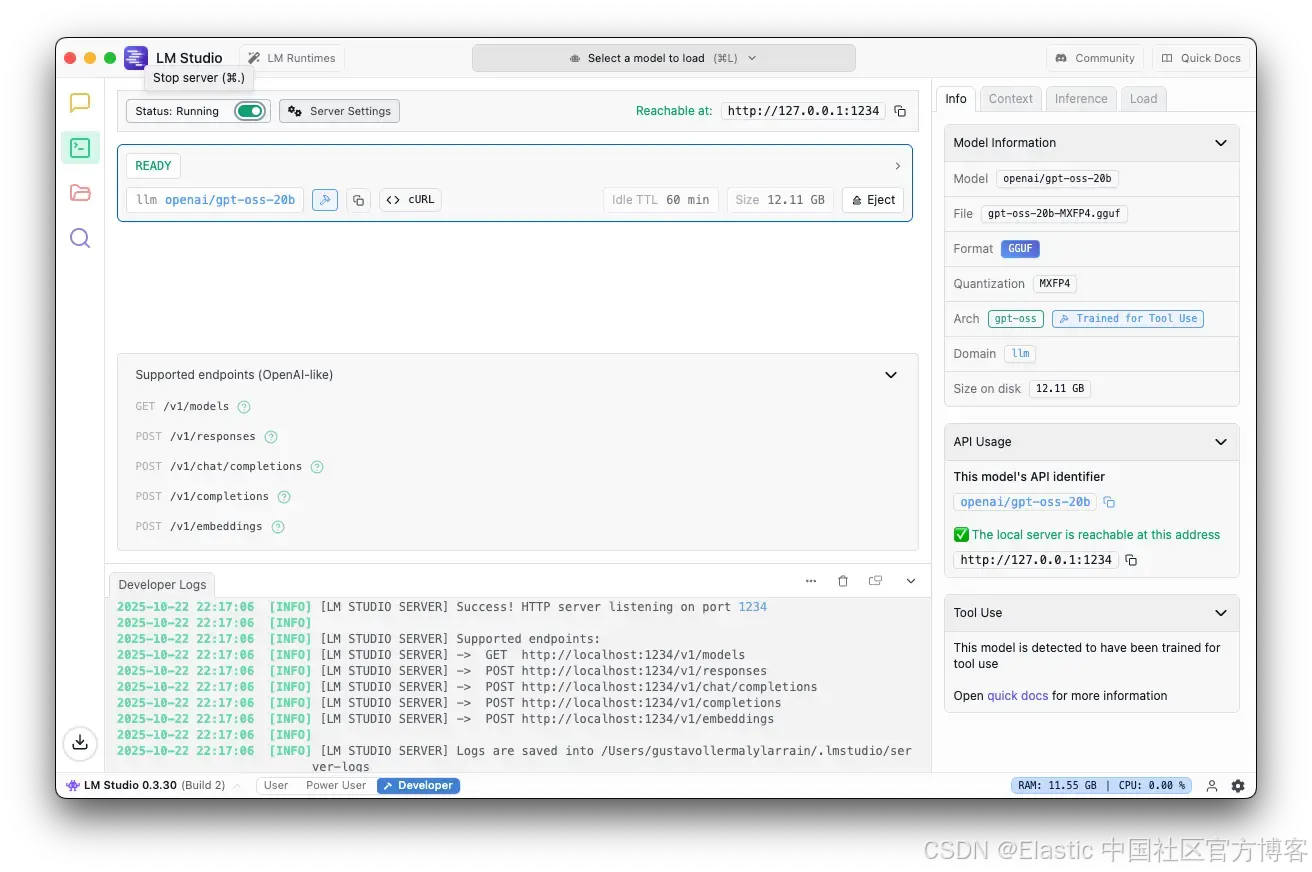
如果服务器正在运行,你应该会看到这个。
[LM STUDIO SERVER] Success! HTTP server listening on port 1234
[LM STUDIO SERVER] Supported endpoints:
[LM STUDIO SERVER] -> GET http://localhost:1234/v1/models
[LM STUDIO SERVER] -> POST http://localhost:1234/v1/responses
[LM STUDIO SERVER] -> POST http://localhost:1234/v1/chat/completions
[LM STUDIO SERVER] -> POST http://localhost:1234/v1/completions
[LM STUDIO SERVER] -> POST http://localhost:1234/v1/embeddings
Server started.步骤 2:使用 Docker 部署本地 Elastic
现在我们将使用 Docker 在本地设置 Elasticsearch 和 Kibana。Elastic 提供了一个方便的脚本来处理整个设置过程。更多详情请参考官方文档。
运行 start-local 脚本
在终端中执行以下命令:
curl -fsSL https://elastic.co/start-local | sh这个脚本将会:
- 下载并配置 Elasticsearch 和 Kibana
- 使用 Docker Compose 启动两个服务
- 自动激活 30 天 Platinum 试用许可
预期输出
等待以下消息出现,并保存显示的密码和 API key;你将需要它们来访问 Kibana:
🎉 Congrats, Elasticsearch and Kibana are installed and running in Docker!
🌐 Open your browser at http://localhost:5601
Username: elastic
Password: KSUlOMNr
🔌 Elasticsearch API endpoint: http://localhost:9200
🔑 API key: cnJGX0pwb0JhOG00cmNJVklUNXg6cnNJdXZWMnM4bncwMllpQlFlUTlWdw==
Learn more at https://github.com/elastic/start-local访问 Kibana
打开你的浏览器并访问:
http://localhost:5601使用终端输出中获得的凭据登录。
启用 Agent Builder
登录 Kibana 后,导航到 Management > AI > Agent Builder 并激活 Agent Builder。
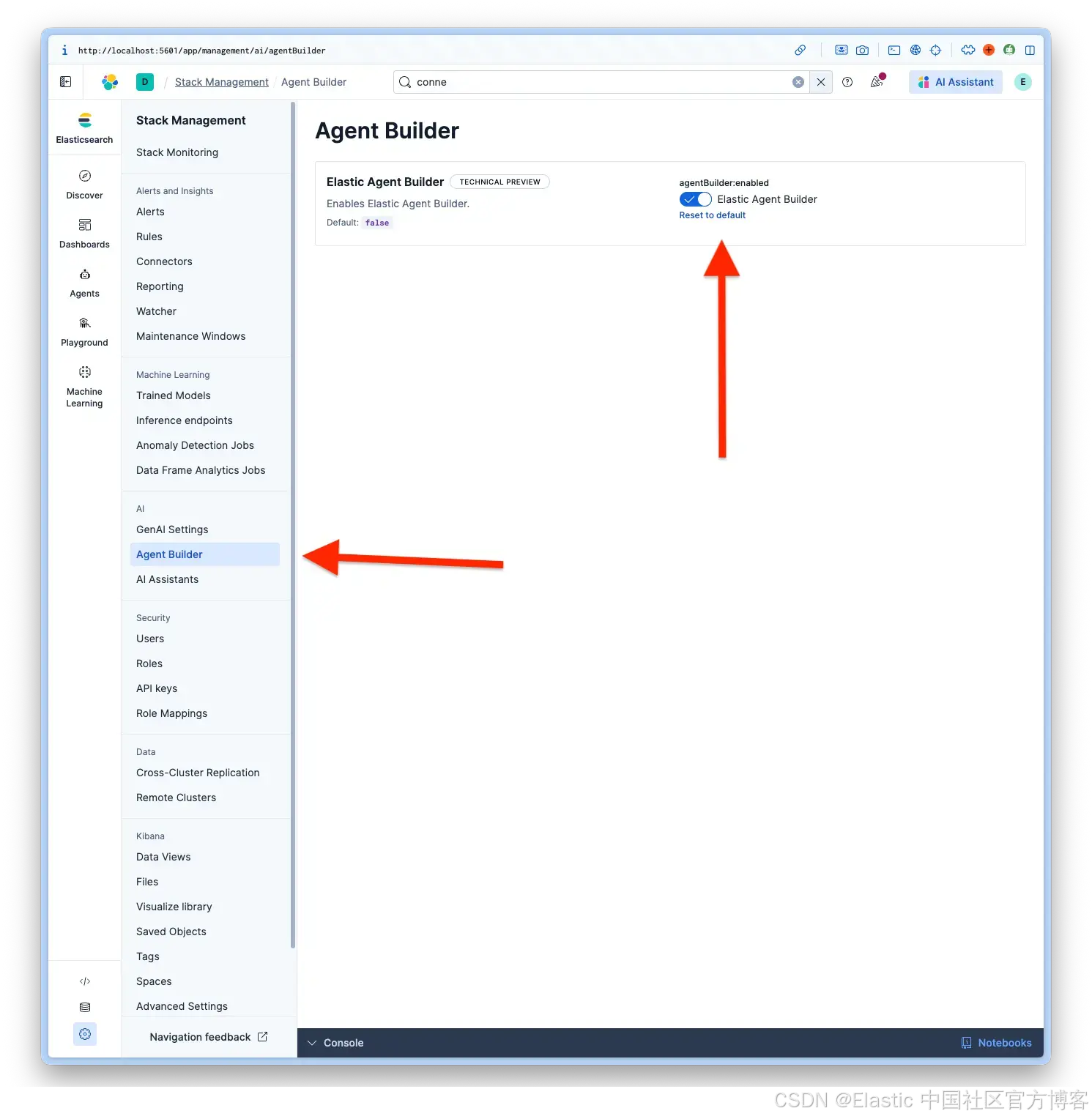
步骤 3:在 Elastic 中创建 OpenAI connector
现在我们将配置 Elastic 使用你的本地 LLM。
访问 Connectors
- 在 Kibana 中:
- 进入 Project Settings > Management
- 在 Alerts and Insights 下,选择 Connectors
- 点击 Create Connector
配置 connector
从 connector 列表中选择 OpenAI。LM Studio 使用 OpenAI SDK,因此兼容。
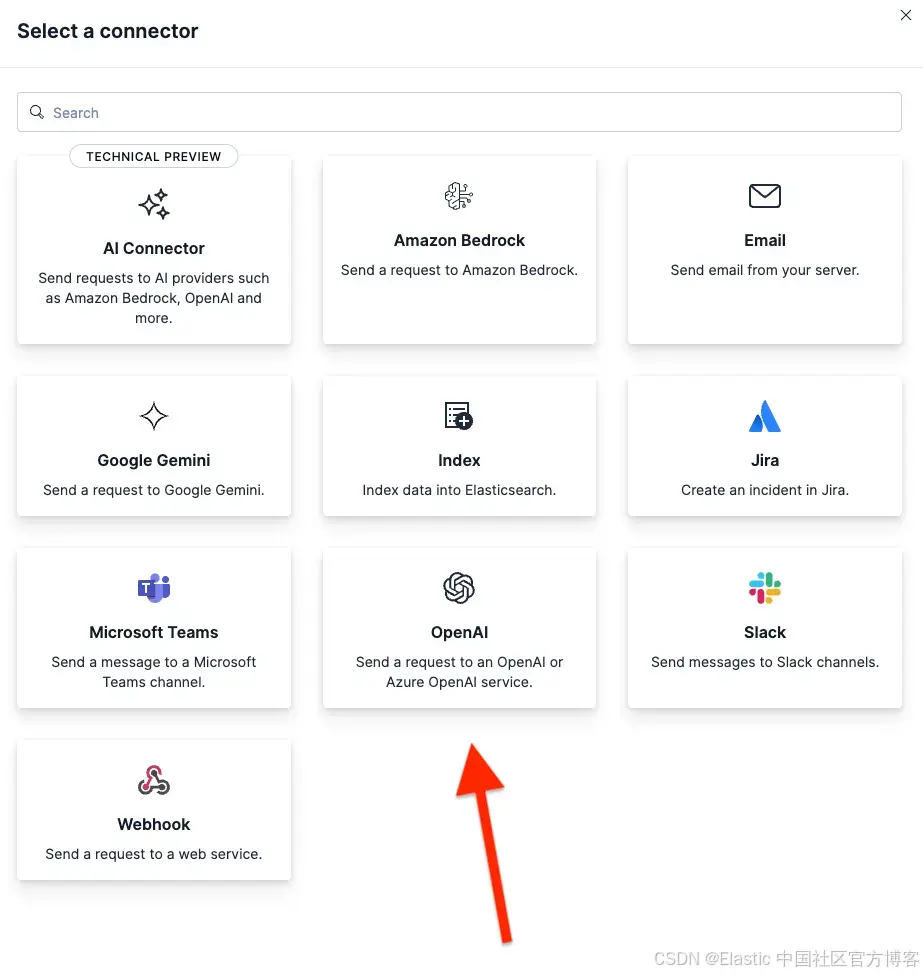
填写以下字段:
- Connector name:LM Studio - GPT-OSS 20B
- Select an OpenAI provider:Other (OpenAI Compatible Service)
- URL:http://host.docker.internal:1234/v1/chat/completions
- Default model:openai/gpt-oss-20b
- API Key:testkey-123(任意文本都可以,因为 LM Studio Server 不需要认证)
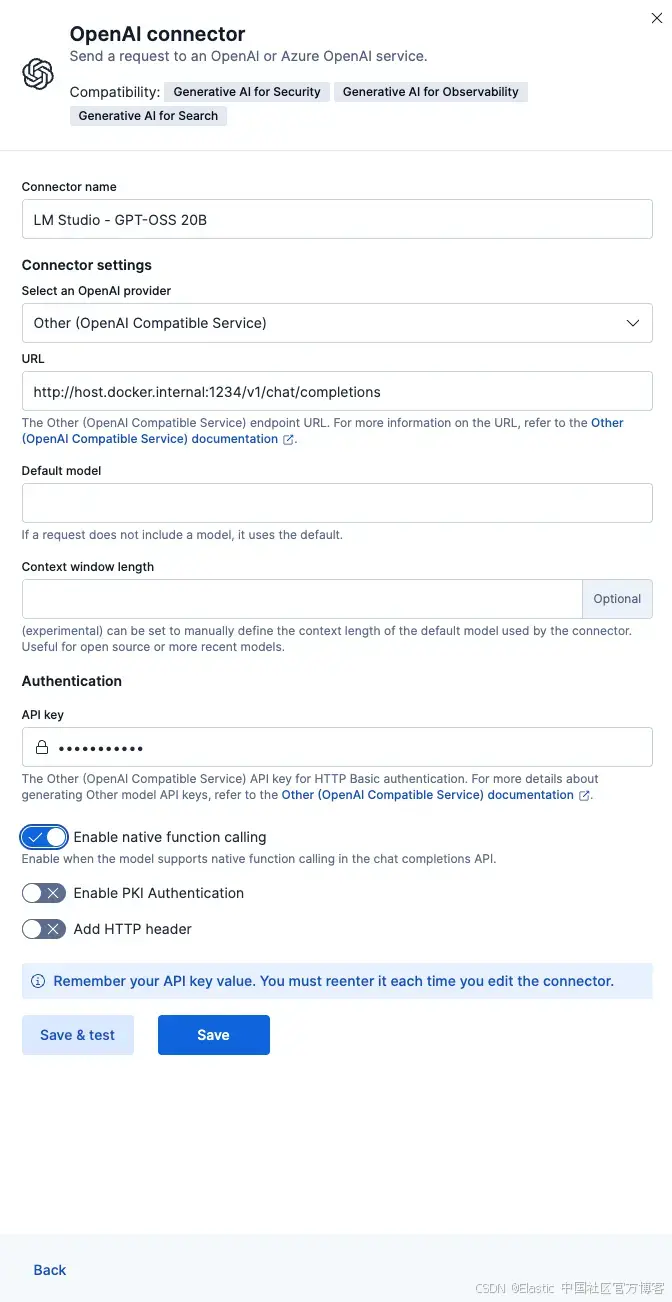
完成配置后,点击 Save & test。
重要提示:打开 “Enable native function calling”;这是 Agent Builder 正常工作的必要条件。如果不启用,你会收到 No tool calls found in the response 错误。
测试连接
Elastic 会自动测试连接。如果配置正确,你会看到如下成功消息:
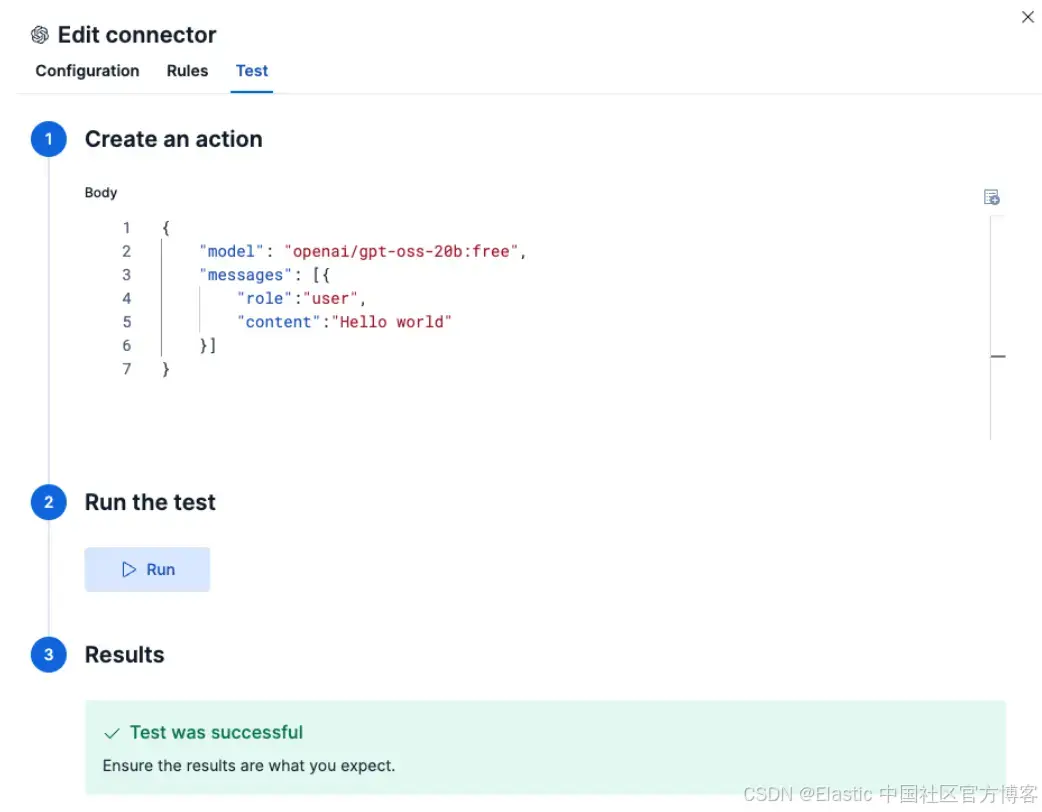
响应:
{
"status": "ok",
"data": {
"id": "chatcmpl-flj9h0hy4wcx4bfson00an",
"object": "chat.completion",
"created": 1761189456,
"model": "openai/gpt-oss-20b",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! 👋 How can I assist you today?",
"reasoning": "Just greet.",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 69,
"completion_tokens": 23,
"total_tokens": 92
},
"stats": {},
"system_fingerprint": "openai/gpt-oss-20b"
},
"actionId": "ee1c3aaf-bad0-4ada-8149-118f52dad757"
}步骤 4:将员工数据上传到 Elasticsearch
现在我们将上传 HR 员工数据集,以演示 agent 如何处理敏感数据。我生成了一个具有以下结构的虚拟数据集。
数据集结构
{
"employee_id": "0f4dce68-2a09-4cb1-b2af-6bcb4821539b",
"full_name": "Daffi Stiebler",
"email": "lscutchings0@huffingtonpost.com",
"date_of_birth": "1975-06-20T15:39:36Z",
"hire_date": "2025-07-28T00:10:45Z",
"job_title": "Physical Therapy Assistant",
"department": "HR",
"salary": "108455",
"performance_rating": "Needs Improvement",
"years_of_experience": 2,
"skills": "Java",
"education_level": "Master's Degree",
"manager": "Carl MacGibbon",
"emergency_contact": "Leigha Scutchings",
"home_address": "5571 6th Park"
}创建带映射的索引
首先,创建一个带有正确映射的索引。注意,我们在一些关键字段中使用了 semantic_text 字段;这使我们的索引具备语义搜索能力。
PUT hr-employees
{
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"employee_id": {
"type": "keyword"
},
"full_name": {
"type": "text",
"copy_to": "employee_semantic"
},
"email": {
"type": "keyword"
},
"date_of_birth": {
"type": "date",
"format": "iso8601"
},
"hire_date": {
"type": "date",
"format": "iso8601"
},
"job_title": {
"type": "text",
"copy_to": "employee_semantic"
},
"department": {
"type": "text",
"copy_to": "employee_semantic"
},
"salary": {
"type": "double"
},
"performance_rating": {
"type": "text",
"copy_to": "employee_semantic"
},
"years_of_experience": {
"type": "long"
},
"skills": {
"type": "text",
"copy_to": "employee_semantic"
},
"education_level": {
"type": "text",
"copy_to": "employee_semantic"
},
"manager": {
"type": "text",
"copy_to": "employee_semantic"
},
"emergency_contact": {
"type": "keyword"
},
"home_address": {
"type": "keyword"
},
"employee_semantic": {
"type": "semantic_text"
}
}
}
}使用 Bulk API 创建索引
将数据集复制并粘贴到 Kibana 的 Dev Tools 中,然后执行:
POST hr-employees/_bulk
{"index": {}}
{"employee_id": "57728b91-e5d7-4fa8-954a-2384040d3886", "full_name": "Filide Gane", "email": "vhallahan1@booking.com", "job_title": "Business Systems Development Analyst", "department": "Marketing", "salary": "$52330.27", "performance_rating": "Meets Expectations", "years_of_experience": 12, "skills": "Java", "education_level": "Bachelor's Degree", "date_of_birth": "2000-02-07T16:49:32Z", "hire_date": "2023-11-07T13:03:16Z", "manager": "Freedman Kings", "emergency_contact": "Vilhelmina Hallahan", "home_address": "75 Dennis Junction"}
{"index": {}}
{"employee_id": "...", ...}验证数据
运行查询以验证:
GET hr-employees/_search步骤 5:构建并测试你的 AI agent
配置完成后,是时候使用 Elastic Agent Builder 构建自定义 AI agent 了。更多详情请参考 Elastic 文档。
添加 connector
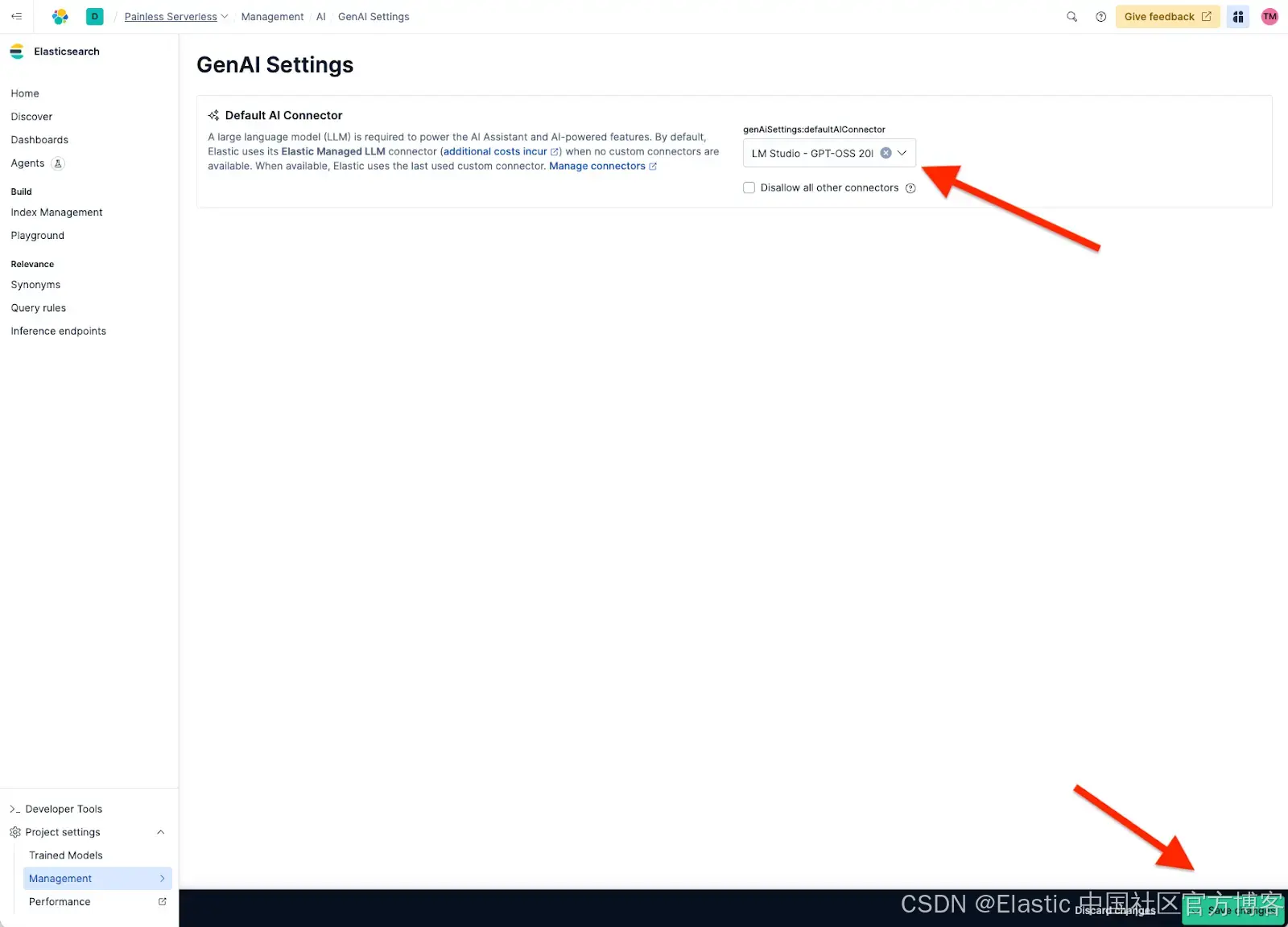
在创建新 agent 之前,我们必须将 Agent Builder 设置为使用我们自定义的 connector,即 LM Studio - GPT-OSS 20B,因为默认的是 Elastic Managed LLM。为此,进入 Project Setting > Management > GenAI Settings,选择我们创建的 connector,然后点击 Save。
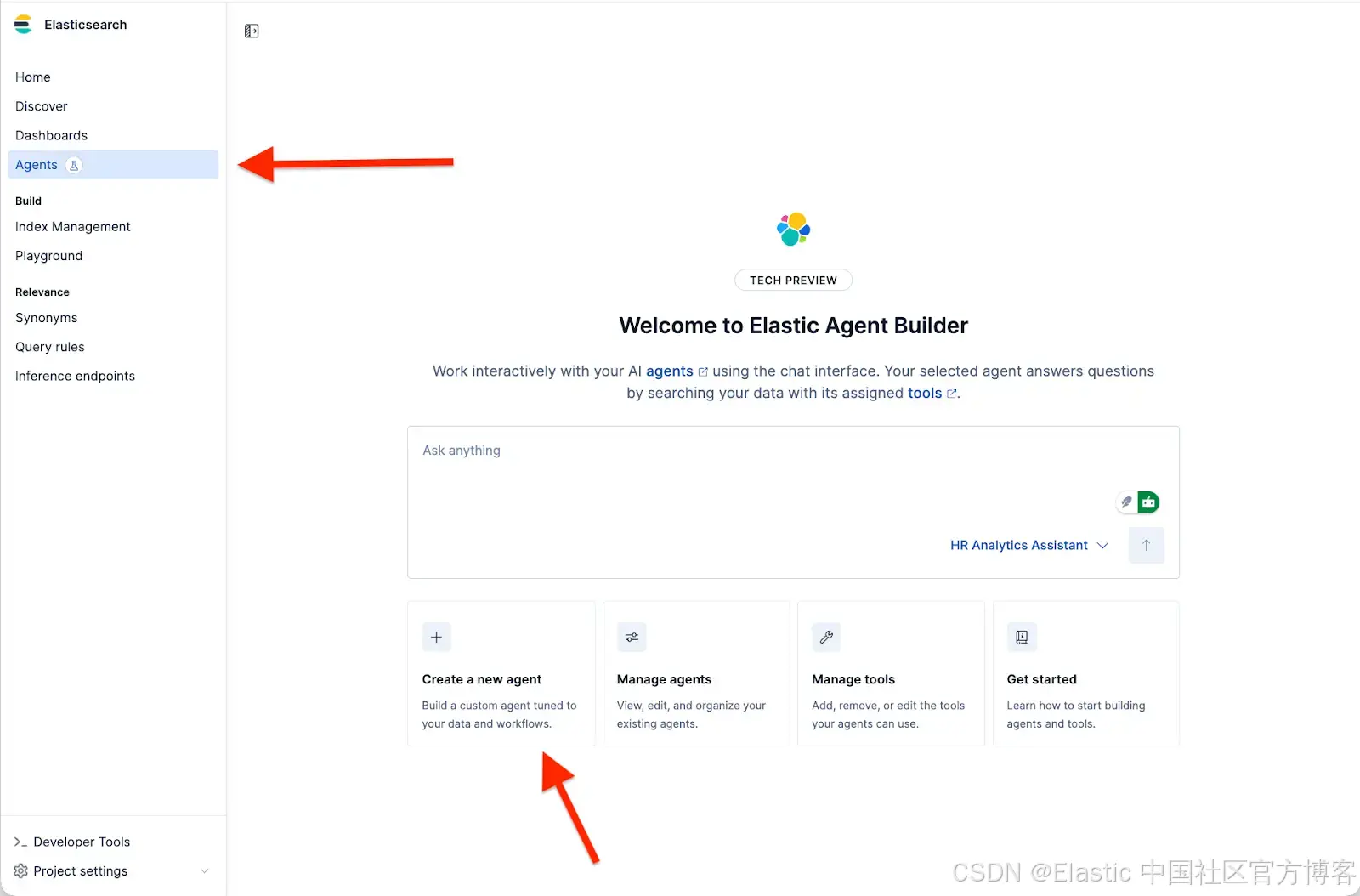
访问 Agent Builder
- 进入 Agents
- 点击 Create a new agent
配置 agent
创建新 agent 时,必填字段有 Agent ID、Display Name 和 Display Instructions。
但还有更多自定义选项,比如 Custom Instructions,用于指导你的 agent 如何行为和与工具交互,类似于系统提示,但针对我们的自定义 agent。Labels 用于组织 agent,Avatar color 和 Avatar symbol。
基于数据集,我为我们的 agent 选择的设置如下:
- Agent ID:
hr_assistant - Custom instructions:
You are an HR Analytics Assistant that helps answer questions about employee data.
When responding to queries:
- Provide clear, concise answers
- Include relevant employee details (name, department, salary, skills)
- Format monetary values with currency symbols
- Be professional and maintain data confidentiality- Labels:
Human ResourcesandGPT-OSS - Display name:
HR Analytics Assistant - Display description:
A specialized AI assistant for Human Resources that helps analyze employee data, compensation, performance metrics, and talent management. Ask questions about employees, departments, salaries, or performance analytics.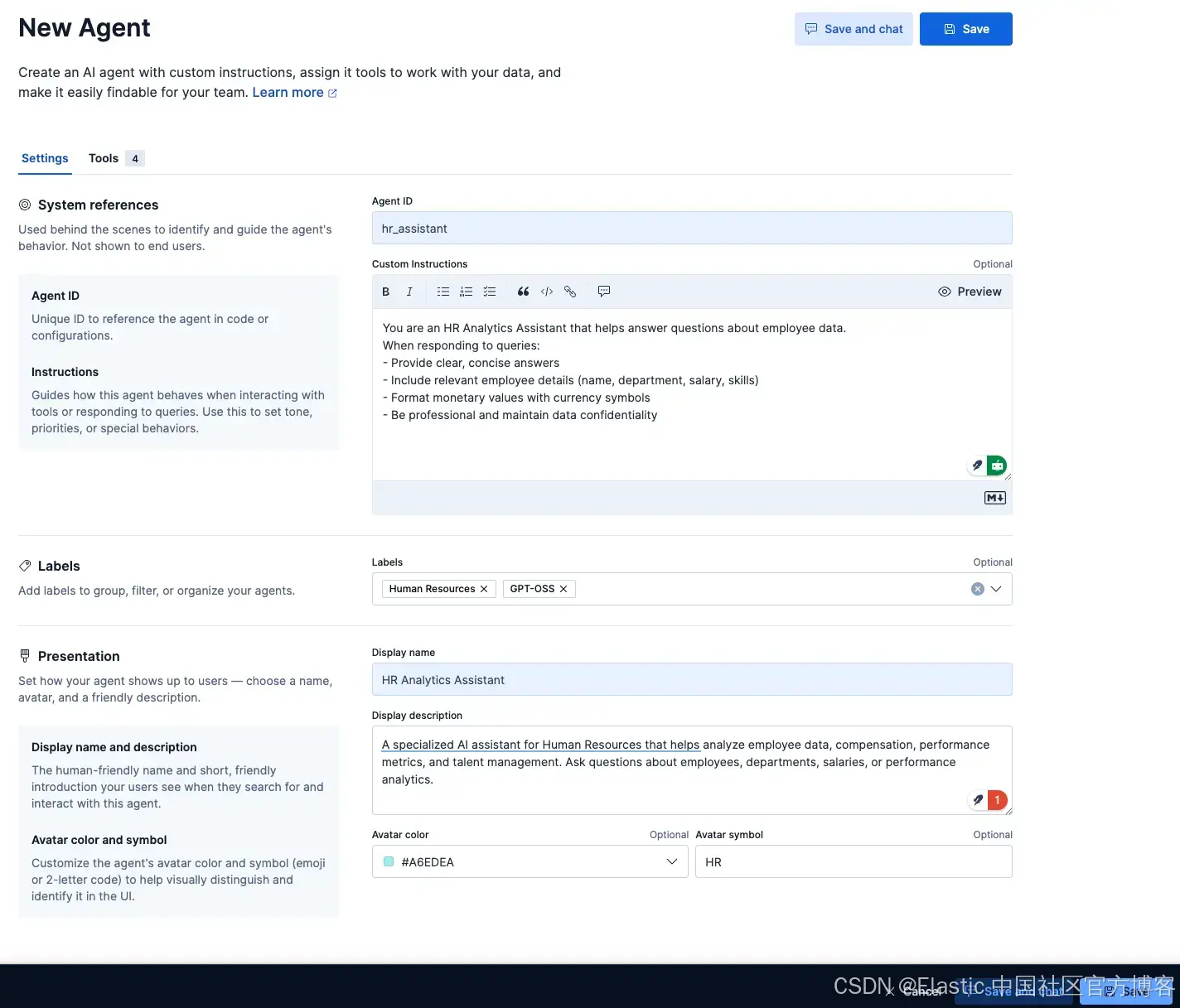
数据全部配置好后,我们可以点击 Save 保存新 agent。
测试 agent
现在你可以用自然语言提问关于员工数据的问题,GPT-OSS 20B 会理解意图并生成相应的回答。
Prompt:
Which employee is the one with the highest salary in the hr-employees index?Answer:

Agent 流程如下:
-
使用 GPT-OSS connector 理解你的问题
-
生成相应的 Elasticsearch 查询(使用内置工具或自定义 ES|QL)
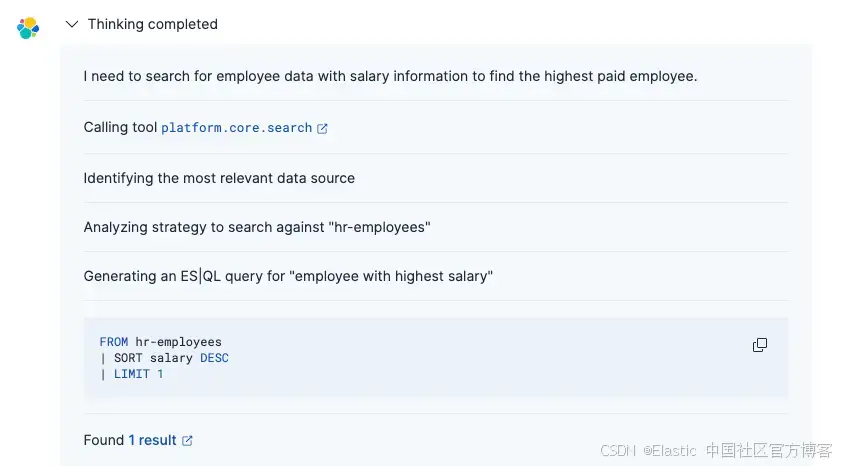
-
检索匹配的员工记录
-
以自然语言和合适的格式呈现结果
与传统的词汇搜索不同,由 GPT-OSS 驱动的 agent 能理解意图和上下文,使得查找信息无需知道精确字段名或查询语法更容易。有关 agent 思考过程的更多详情,请参考本文。
结论
在本文中,我们使用 Elastic 的 Agent Builder 构建了一个自定义 AI agent,连接到本地运行的 OpenAI GPT-OSS 模型。通过在本地部署 Elastic 和 LLM,这种架构允许你利用生成式 AI 功能,同时完全控制你的数据,而无需将信息发送到外部服务。
我们以 GPT-OSS 20B 进行实验,但 Elastic Agent Builder 官方推荐的模型请参考此处。如果需要更高级的推理能力,还有 120B 参数版本,在复杂场景下表现更好,但需要更高配置的本地机器运行。更多详情请参考官方 OpenAI 文档。
原文:https://www.elastic.co/search-labs/blog/build-an-ai-agent-hr-elastic-agent-builder-gpt-oss

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)