AI论文整理:VideoCAD: A Large-Scale Video Dataset for Learning UI Interactions and 3D Reasoning from CAD
为解决现有UI交互数据集在专业工程工具(如CAD)中缺乏长时序、3D推理能力的问题,MIT团队提出VideoCAD——首个大规模CAD UI交互数据集,包含41,005个带精细标注的合成视频,时间跨度较其他数据集最高达20倍,且需3D空间推理与精确像素级交互;基于该数据集,团队开发了( transformer架构模型),在CAD动作预测任务上超越VPT等基线模型,命令准确率达98.08%,长序列任
VideoCAD 论文下载地址: https://arxiv.org/pdf/2505.24838.pdf
这是发表在 arXiv 上的原始 PDF 版本,DOI 为:https://doi.org/10.48550/arXiv.2505.24838
1. 一段话总结
为解决现有UI交互数据集在专业工程工具(如CAD)中缺乏长时序、3D推理能力的问题,MIT团队提出VideoCAD——首个大规模CAD UI交互数据集,包含41,005个带精细标注的合成视频,时间跨度较其他数据集最高达20倍,且需3D空间推理与精确像素级交互;基于该数据集,团队开发了VideoCADFormer( transformer架构模型),在CAD动作预测任务上超越VPT等基线模型,命令准确率达98.08% ,长序列任务性能提升超20%;同时构建VIDEOCAD VQA基准(含1,200个多选择题),发现现有多模态LLM在CAD领域的3D推理(如挤压次数估计准确率仅47%)和时间序列理解(如帧排序准确率36%)存在显著短板;该数据集为AI驱动的CAD自动化、UI导航研究提供关键基准。
2. 思维导图(mindmap)
## 核心主题:VideoCAD数据集及CAD领域AI研究
- 一、研究背景与动机
- 1. 现有UI数据集局限:聚焦移动/网页、短时序、无3D推理
- 2. CAD工具痛点:操作复杂、需长时序交互与3D建模
- 3. 技术缺口:缺乏大规模CAD UI视频标注数据集
- 二、VideoCAD数据集
- 1. 生成Pipeline
- 从DeepCAD序列转换为OnShape UI指令
- 规则机器人执行(Selenium+PyAutoGUI,64个云VM)
- 屏幕录制(60 FPS)与动作日志
- 质量控制(DINOv2余弦相似度,阈值0.7)
- 2. 构成与统计
- 41,005个视频,62.0%重建成功率
- 时间跨度:186个UI动作/任务
- 标注:低级别UI动作(点击、移动)+ 高级别建模操作(挤压)
- 3. 核心优势
- 规模:仅次于AITW,是中位数数据集的50倍
- 时序:186个UI动作,4倍于次优数据集WebLinx
- 能力需求:支持3D推理+精确像素级(xy)交互
- UI复杂度:平均6,740个元素,是Web数据集的6倍
- 三、VideoCADFormer模型
- 1. 架构设计
- 输入:目标CAD图像+过去UI帧+过去动作+时序嵌入
- 视觉编码:ViT编码器(分别处理CAD/UI图像)
- 解码器:因果Transformer(含因果掩码+窗口掩码)
- 输出:命令预测头+参数预测头
- 2. 评估结果
- 命令准确率:98.08%(超VPT的96.25%)
- 参数准确率:82.35%(超VPT的78.72%)
- 几何保真度:Chamfer成功率37.5%(超VPT的27.0%)
- 四、VIDEOCAD VQA基准
- 1. 设计内容
- 1,200个多选择题,覆盖11类任务(挤压计数、帧排序等)
- 基于VideoCAD视频与动作日志自动生成
- 2. LLM表现
- 优势任务:平面识别(GPT-4.1达87%)、孔洞检测(92%)
- 短板任务:对称检测(18.5%)、帧排序(36%)、挤压计数(47%)
- 五、局限性与未来工作
- 1. 局限性:合成数据无人类变异性、仅支持sketch-extrude、单一平台OnShape
- 2. 未来工作:加入人类演示、扩展装配/高级功能、多CAD平台支持
- 六、结论
- VideoCAD填补CAD UI交互数据集空白
- VideoCADFormer为长时序CAD动作预测提供SOTA方案
- VIDEOCAD VQA揭示LLM在工程领域的3D推理短板
3. 详细总结
1. 研究背景与动机
现有AI驱动的UI代理研究存在显著局限,难以支撑专业CAD工具的自动化需求:
- UI数据集局限:主流数据集(如MiniWob++、RICO、WebShop)聚焦移动/网页应用,任务时序短(平均3.6-43个UI动作)、无3D空间推理需求,且无需精确像素级(xy)交互;
- CAD工具复杂性:专业CAD软件(如OnShape)需长时序结构化操作(多步骤草图+挤压)、3D几何约束推理,人类熟练掌握需数年,自动化难度高;
- 数据缺口:行为克隆在机器人操作、游戏领域已验证有效性,但CAD UI领域缺乏大规模、带视频标注的高质量数据集,导致AI方法难以泛化。
2. VideoCAD数据集:大规模CAD UI交互基准
2.1 数据集生成Pipeline
VideoCAD通过自动化流程生成,确保高保真度与一致性,具体步骤如下:
- CAD序列来源:基于DeepCAD数据集(含178K人类创建的参数化CAD模型),提取其构建序列(草图+挤压操作);
- UI指令转换:将DeepCAD序列映射为OnShape(浏览器端专业CAD平台)可执行的UI指令,涵盖草图平面定义、几何图元绘制(线/弧/圆)、挤压参数设置;
- 规则机器人执行:
- 采用混合机器人框架:Selenium(DOM级自动化,如打开菜单)+ PyAutoGUI(像素级交互,如绘制曲线);
- 部署于64个Google云VM,录制分辨率60 FPS,日志记录每个UI动作的帧索引(亚秒级对齐);
- 成功率:71,424次尝试中成功重建44,292个CAD模型,重建率62.0% ;
- 人类启发式优化:加入随机动作延迟(0.2-0.5s)、表面随机选点、小特征缩放,提升数据真实性;
- 质量控制:
- 用DINOv2视觉嵌入计算生成模型与人类参考模型的余弦相似度,丢弃低于阈值(0.7)的样本;
- 最终保留41,005个有效视频,总录制时长超118天(一周内完成)。
2.2 数据集构成与统计
- 核心内容:每个样本含3部分——①目标CAD等轴测图(3×224×224);②全分辨率视频(1600×1000,60 FPS);③时序对齐的动作元组(鼠标/键盘操作);
- 动作类型:低级别UI动作(MoveTo、PressKey、Scroll、Type、Click)与高级别CAD操作(草图绘制、挤压);
- 关键分布:动作序列长度集中于多挤压任务,鼠标坐标呈均匀分布,常用按键(如Tab、Enter)频率最高。
2.3 与现有UI数据集的对比
VideoCAD在规模、复杂度、能力需求上全面领先,具体对比如下:
| Environment | # Samples | Time Horizon(UI动作数) | 3D Reasoning | Precise Elements | Avg. # Elements |
|---|---|---|---|---|---|
| MiniWoB++ | 125 | 3.6 | ✗ | ✗ | 28 |
| WebShop | 12,000 | 11.3 | ✗ | ✗ | 38 |
| WebLinx | 2,337 | 43 | ✗ | ✗ | 1,849 |
| GUI-WORLD | 12,379 | 10.97 | ✓ | ✓ | – |
| VideoCAD | 41,005 | 186 | ✓ | ✓ | 6,740 |
- 关键优势:①时间跨度是次优数据集(WebLinx)的4倍,最高达其他数据集的20倍;②唯一同时支持3D推理与精确像素交互的数据集;③UI元素数量是Web数据集(如Mind2Web)的6倍。
3. VideoCADFormer:长时序CAD动作预测模型
3.1 模型设计目标
将CAD构建建模为序列决策过程:模型观察UI帧与目标CAD图,预测低级别UI动作,以复现目标3D模型,核心挑战是长时序依赖与3D空间推理。
3.2 核心架构
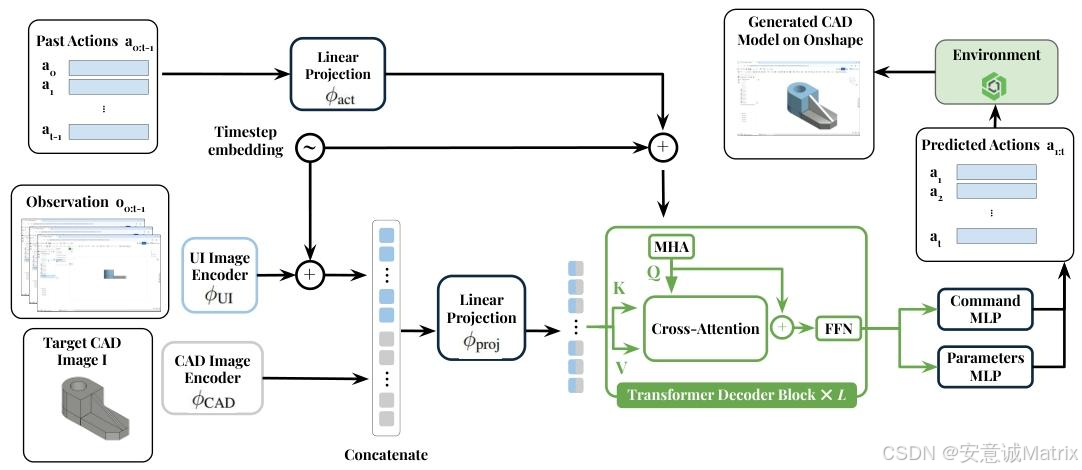
- 输入表示:
- 视觉输入:目标CAD图像(224×224×1,灰度)+ 过去k帧UI图像(224×224×1);
- 动作输入:过去k个动作序列(固定7D向量,含命令类型与参数,未使用字段填-1);
- 时序嵌入:每个输入附加时间戳嵌入,捕捉时序信息;
- 视觉编码:
- 用ViT编码器分别处理目标CAD图像与UI帧,输出嵌入向量;
- 融合CAD嵌入与UI帧嵌入,通过线性投影得到视觉记忆向量(ztimagez_{t}^{image}ztimage);
- 动作嵌入:过去动作通过线性投影+时序嵌入,得到动作嵌入向量(zτactz_{\tau}^{act}zτact);
- Transformer解码器:
- L层因果Transformer,含因果掩码(防止未来信息泄露)与窗口掩码(聚焦近期上下文);
- 输入:动作嵌入(目标序列)+ 视觉记忆(源序列),输出隐藏状态(HtH_tHt);
- 动作预测头:
- 命令预测头:输出5类命令(MoveTo/PressKey等)的概率分布(c^t\hat{c}_tc^t);
- 参数预测头:输出6个参数(x/y坐标、按键索引等)的多分类结果(p^t\hat{p}_tp^t),基于命令类型掩码无效参数。
3.3 评估指标
- 命令/参数准确率:μcmd\mu_{cmd}μcmd(正确预测命令的比例)、μparam\mu_{param}μparam(命令正确前提下,参数预测准确率);
- 闭环执行性能:全序列 autoregressive 预测中,完全匹配 ground truth 的动作比例;
- 几何保真度:执行预测动作生成CAD模型,计算与ground truth的双向Chamfer距离(CD) ,CD<0.02视为成功,统计无效样本率(建模失败)。
3.4 实验结果
对比VPT(Minecraft行为克隆SOTA)、Pix2Act、Pearce et al.基线模型,VideoCADFormer表现最优:
| 方法 | μcmd\mu_{cmd}μcmd (%) | μparam\mu_{param}μparam (%) | 完美预测动作率(%)- 均值 | 完美预测动作率(%)- 长序列 | 成功重建率(%) | 平均CD |
|---|---|---|---|---|---|---|
| Pix2Act | 20.44 | 2.61 | 2.84 | 3.60 | – | – |
| Pearce et al. | 42.60 | 0.55 | 0.68 | 0.51 | – | – |
| VPT | 96.25 | 78.72 | 83.81 | 80.12 | 27.0 | 0.0484 |
| VideoCADFormer | 98.08 | 82.35 | 87.54 | 85.46 | 37.5 | 0.0390 |
- 关键结论:VideoCADFormer在长时序任务(200+ UI动作)中优势更显著,证明其对3D推理与长依赖的建模能力;几何保真度提升10.5个百分点,说明动作预测精度直接转化为CAD建模质量。
4. VIDEOCAD VQA:CAD领域3D推理基准
4.1 基准设计
- 目标:评估多模态LLM的CAD视频理解与3D空间推理能力;
- 内容:从VideoCAD生成1,200个多选择题,覆盖11类任务(如下表);
- 生成方式:基于ground truth UI日志与CAD几何自动生成,确保问题与答案的准确性。
4.2 LLM评估结果
对GPT-4.1、Claude-3.7、Qwen2.5-VL等模型进行0-shot评估,结果如下(部分关键任务):
| 评估任务 | GPT-4.1 (%) | Claude-3.7 (%) | Qwen2.5-VL (%) | 随机基线 (%) |
|---|---|---|---|---|
| 挤压次数估计 | 47.0 | 37.5 | 47.0 | 21.4 |
| 视频帧排序(3帧) | 36.0 | 23.0 | 32.5 | 17.4 |
| 草图识别 | 62.0 | 48.5 | 43.5 | 21.5 |
| 对称检测 | 18.5 | 19.0 | 12.0 | 12.5 |
| 平面识别 | 87.0 | 86.5 | 86.0 | 34.0 |
- 关键发现:现有LLM在3D几何推理(对称检测)与时间序列理解(帧排序)上存在显著短板,仅在简单任务(平面识别)中表现较好;即使是GPT-4.1,核心CAD任务准确率仍低于50%,无法胜任CAD UI代理角色。
5. 局限性与未来工作
5.1 现有局限性
- 数据局限性:所有轨迹由规则机器人生成,缺乏人类操作的时序变异性、错误修正与策略多样性;
- 功能局限性:仅覆盖“草图-挤压” workflow,未包含倒角、扫描、放样等高级CAD操作;
- 平台局限性:仅支持OnShape,泛化到其他CAD平台(如Fusion 360、FreeCAD)未验证;
- 评估局限性:几何保真度评估仅基于100个测试序列,全规模验证成本高。
5.2 未来工作方向
- 整合人类演示数据(如YouTube CAD教程);
- 扩展数据集至装配体建模与高级CAD功能;
- 支持多CAD平台,提升模型泛化性;
- 为每个CAD目标收集多轨迹数据,捕捉用户操作差异;
- 引入“逐挤压文本提示”,实现人类与CAD AI代理的自然交互。
6. 研究结论
- VideoCAD填补了专业工程工具UI交互数据集的空白,为CAD自动化、AI UI导航提供关键基准;
- VideoCADFormer验证了transformer架构在长时序、3D推理CAD动作预测中的有效性,为后续研究提供SOTA baseline;
- VIDEOCAD VQA揭示了现有多模态LLM在工程领域的核心短板,明确了未来3D推理与视频理解研究的方向;
- 该研究连接计算机视觉、强化学习与CAD建模,为开发“感知-动作-推理”一体化的专业软件AI代理奠定基础。
4. 关键问题与答案
问题1:VideoCAD数据集相比现有UI交互数据集,在支撑专业CAD任务上的核心优势是什么?
答案:VideoCAD的核心优势体现在4个维度,精准匹配专业CAD任务的复杂性需求:
- 规模与时序长度:含41,005个标注视频,规模是中位数UI数据集(如WebArena,812个样本)的50倍;任务时间跨度达186个UI动作,是次优数据集WebLinx(43个动作)的4倍,最高为其他数据集的20倍,可支撑长时序CAD建模;
- 3D推理需求:是少数需模型处理3D几何约束的数据集(仅与GUI-WORLD同为√),契合CAD工具的3D空间推理本质;
- 精确元素交互:要求模型通过xy像素坐标操作画布(如绘制曲线),而非依赖DOM选择器,匹配CAD操作的精确性需求(其他多数数据集为✗);
- UI复杂度:平均含6,740个UI元素,是Web数据集(如Mind2Web,1,135个元素)的6倍,还原专业CAD软件的复杂界面环境。
问题2:VideoCADFormer在实现高精度CAD动作预测时,有哪些关键设计,其性能相比基线模型有何提升?
答案:VideoCADFormer的关键设计与性能提升如下:
- 核心设计:
- 多模态输入融合:通过ViT编码器分别处理目标CAD图像与过去UI帧,结合时序嵌入,同时捕捉全局目标与局部进度;
- 因果Transformer解码器:引入因果掩码(防止未来信息泄露)与窗口掩码(聚焦近期上下文),有效建模长时序依赖;
- 命令-参数分离预测:基于命令类型动态掩码无效参数,提升参数预测精度;
- 性能提升:
- 命令准确率达98.08% ,较基线模型VPT(96.25%)提升1.83个百分点;
- 参数准确率达82.35% ,较VPT(78.72%)提升3.63个百分点;
- 长序列(200+ UI动作)完美预测率达85.46% ,较VPT(80.12%)提升5.34个百分点;
- 几何重建成功率达37.5% ,较VPT(27.0%)提升10.5个百分点,平均Chamfer距离从0.0484降至0.0390,建模精度显著提升。
问题3:VIDEOCAD VQA基准揭示了现有多模态LLM在CAD领域的哪些核心短板?这些短板对CAD AI代理的开发有何启示?
答案:VIDEOCAD VQA基准揭示了LLM的2类核心短板,为CAD AI代理开发提供关键启示:
- 核心短板:
- 3D几何推理能力不足:在对称检测(GPT-4.1准确率18.5%)、挤压形状预测(27.0%)等任务中表现接近随机基线,无法精准理解CAD模型的空间结构;
- 时间序列理解薄弱:视频帧排序任务中,GPT-4.1准确率仅36%,Claude-3.7仅23%,难以还原CAD建模的时序逻辑(如草图绘制顺序);
- 精确数值推理欠缺:挤压次数估计任务中,主流LLM准确率低于50%(GPT-4.1 47%、Claude-3.7 37.5%),无法满足CAD参数化建模的精确性需求;
- 开发启示:
- 需设计针对CAD领域的3D几何预训练任务(如点云对齐、拓扑结构学习),而非依赖通用视觉预训练;
- 需强化LLM的时序建模能力,如引入CAD建模流程的结构化知识(如“草图→约束→挤压”的固定逻辑);
- 需结合符号化CAD数据(如参数化指令)与视觉信息,提升精确数值推理与动作规划能力,而非仅依赖纯视觉输入。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)