【AIOPS】dify+elk-mcp实现AIOps对话式获取日志数据设计方案
本文提出了一种基于Dify和ELK-MCP的AIOps对话式日志查询方案,旨在降低运维门槛。系统通过Dify平台接收自然语言查询,利用大模型提取结构化参数并构建API请求,调用ELK-MCP获取日志数据后生成智能分析报告。方案包含详细的提示词设计,用于参数提取和分析报告生成,并建立了完整的工作流,涵盖异常处理和结果适配机制。该设计实现了从"自然语言输入"到"智能分析输
一、方案概述
1.1 背景与目标
在传统AIOps日志分析场景中,运维人员需掌握ELK-MCP的查询语法、API调用规则等专业知识,通过固定格式指令获取日志数据,操作门槛高且效率低下。为解决这一问题,本方案结合Dify的大模型交互能力与ELK-MCP的日志存储分析能力,构建对话式日志查询系统。
核心目标:实现"自然语言输入→日志数据输出→智能分析报告"的全流程自动化,降低运维操作门槛,提升日志分析的及时性与深度,助力快速定位系统故障。
1.2 核心组件与交互逻辑
本方案涉及两大核心组件,各组件功能及交互流程如下:
-
Dify平台:作为对话交互入口与逻辑处理中枢,负责接收用户自然语言查询、通过大模型提取结构化参数、构建API请求、接收日志数据并生成分析报告。核心模块包括LLM模型(DeepSeek-V3 CHAT)、参数提取器、API参数构建器。
-
ELK-MCP平台:作为日志存储与查询引擎,提供日志数据的存储、索引及查询API服务,接收Dify发送的标准化请求并返回匹配的日志数据。
整体交互逻辑:用户通过Dify对话界面输入日志查询需求→Dify完成参数提取与API构建→调用ELK-MCP日志查询API→ELK-MCP返回日志数据→Dify生成可视化分析报告→向用户呈现结果。
二、系统工作流设计
2.1 完整工作流图及说明
下图为对话式日志获取与分析的全流程工作流,涵盖从用户输入到结果输出的所有关键节点及异常处理机制: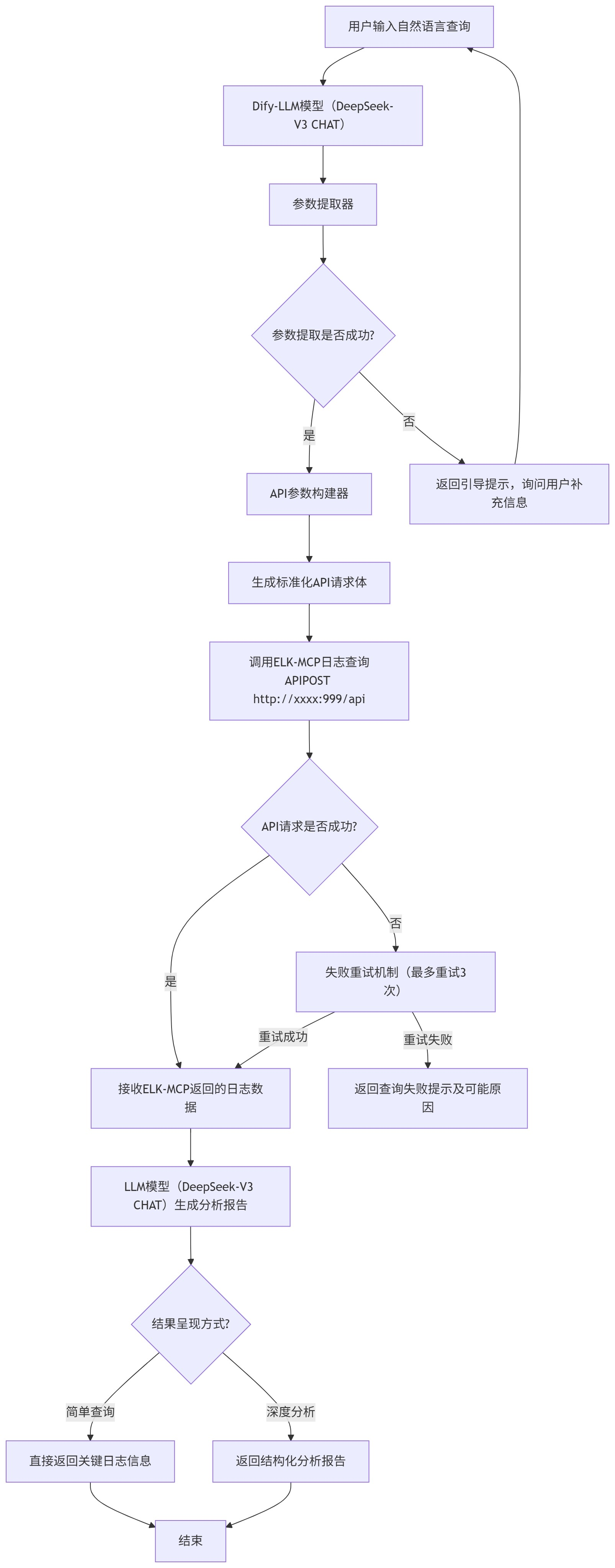
flowchart TD
A[用户输入自然语言查询] --> B[Dify-LLM模型(DeepSeek-V3 CHAT)]
B --> C[参数提取器]
C --> D{参数提取是否成功?}
D -- 是 --> E[API参数构建器]
D -- 否 --> F[返回引导提示,询问用户补充信息]
F --> A
E --> G[生成标准化API请求体]
G --> H[调用ELK-MCP日志查询APIPOST http://:999/api]
H --> I{API请求是否成功?}
I -- 是 --> J[接收ELK-MCP返回的日志数据]
I -- 否 --> K[失败重试机制(最多重试3次)]
K -- 重试成功 --> J
K -- 重试失败 --> L[返回查询失败提示及可能原因]
J --> M[LLM模型(DeepSeek-V3 CHAT)生成分析报告]
M --> N{结果呈现方式?}
N -- 简单查询 --> O[直接返回关键日志信息]
N -- 深度分析 --> P[返回结构化分析报告]
O --> Q[结束]
P --> Q
2.2 关键节点说明
-
自然语言接收:支持运维场景常见查询话术,如"查询kf11租户web-scrm服务最近30分钟的错误日志"、"web-scrm服务报500错误,帮我找一下最近1小时的相关日志"等。
-
参数提取器:基于预设规则将自然语言转换为ELK-MCP API所需的结构化参数,是实现"对话式"的核心环节,详细规则见"提示词设计"部分。
-
失败重试机制:针对API调用超时、网络波动等临时问题,自动触发重试(最多3次),重试间隔采用指数退避策略(1s→3s→5s),提升系统容错性。
-
结果呈现适配:根据用户查询意图智能适配呈现方式,简单查询(如"获取最近10分钟ERROR日志数量")直接返回数据,复杂查询(如"分析web-scrm服务异常日志")返回多维度分析报告。
三、核心模块设计
3.1 提示词设计(参数提取与报告生成)
3.1.1 意图识别与参数提取提示词
该提示词用于引导LLM模型从用户自然语言中提取标准化参数,确保输出格式符合API构建需求。
你是一个日志分析助手。请根据用户查询文本提取结构化参数并严格输出 JSON。
上下文:
- 用户查询:"{{#sys.query#}}"
- 默认排序字段:@timestamp(后端 TIMESTAMP_FIELD)
- 如未能从文本中确定租户,使用 "";若该变量不存在或为空,使用 "all"。
抽取规则(必须遵守):
1) 时间范围(最近 N 分钟)
- 如用户提到“最近 N 分钟/小时/半小时”,按以下映射:
- “N 分钟”→ N
- “N 小时”→ N*60
- “半小时”→ 30
- “一小时/1 小时”→ 60
- 未提及时使用默认 15。
2) 日志级别(允许集合)
- 仅允许值:["ERROR","WARN","INFO","DEBUG","FATAL"]。
- 中文与变体映射:
- 报错/错误/异常/失败/致命 → 包含 "ERROR"(若提到“致命”可用 "FATAL")
- 警告/告警 → "WARN"
- 信息/提示 → "INFO"
- 调试/debug → "DEBUG"
- 致命 → "FATAL"
- 未明确提及时,默认 ["ERROR"]。
3) 服务名称
- 从文本直接提取明确的服务名(如 web、mtkf、api 等)。
- 输出统一为下划线风格(如 web_xxx),未提及时返回空数组 []。
4) 关键词
- 从文本提取用于全文搜索的关键词(去除停用词与纯时间/数量词)。
- 未提及或不适合提取时,返回空字符串 ""。
5) 租户ID(必须产出,且不可为空)
- 关键词到租户映射(不区分大小写,包含这些别名时确定租户):
- scrm/SCRM → "scrm"
- 若文本包含多个租户关键词,请重新咨询用户,告知用户不支持多租户操作。
- 若无法从文本确定,则:
- 优先使用 ""(若存在且非空)
- 否则使用 "all"
6) 排序
- 允许的排序字段仅为 "@timestamp" 或 "_score",默认 "@timestamp"。
- 排序方向仅为 "desc" 或 "asc",默认 "desc"。
输出格式(必须严格遵守;仅输出 JSON,无任何其他字符或包裹):
{
"time_range_minutes": 数字,
"log_levels": ["级别1","级别2"],
"services": ["服务1","服务2"],
"keyword": "搜索关键词",
"tenant_id": "租户ID",
"sort_field": "@timestamp|_score",
"sort_order": "desc|asc"
}
严苛要求:
- 只返回上面的 JSON;不要输出解释、不要使用 Markdown 代码块、不要多余逗号。
- 字段必须存在、类型必须正确;不得返回 null 或空对象。
- 若内容含糊,使用上文定义的默认值,不得臆造未定义的枚举。
3.1.2 参数提取示例
| 用户查询 | 提取结果 |
|---|---|
| 查询kf11租户web-slcrm服务最近30分钟的错误和警告日志,关键词是500错误 | {"time_range_minutes":30,"log_levels":["ERROR","WARN"],"services":["web_scrm"],"keyword":"500错误","tenant_id":"k1","sort_field":"@timestamp","sort_order":"desc"} |
| SCRM的mtklf服务最近1小时有什么调试日志吗? | {"time_range_minutes":60,"log_levels":["DEBUG"],"services":["mtkf"],"keyword":"","tenant_id":"scrm","sort_field":"@timestamp","sort_order":"desc"} |
| 帮我看看kf1和kf2的客服服务最近半小时的致命错误 | {"error":"不支持多租户操作,请明确单一租户"} |
3.1.3 分析报告生成提示词
该提示词用于引导LLM模型以SRE专家视角,对ELK-MCP返回的日志数据进行深度分析,生成结构化报告。
请你作为一名资深SRE专家,对提供的日志数据集进行深度分析。请超越简单的统计,致力于发现隐藏在数据中的模式、异常和关联关系。你的分析报告应遵循以下结构:
1. 总体态势与健康状况评估
流量与负载概况: 总结日志的总量、时间分布(是否有高峰?),整体错误率。
系统稳定性评分: 基于错误/警告的严重性和密度,给出一个定性的稳定性评估(例如:健康、需要注意、恶化、危急)。
2. 深度问题发现与根因分析
这是核心部分。请从以下维度挖掘问题,并尽可能建立关联:
时间序列分析: 错误和警告是否在特定时间点爆发?是否与已知的发布、配置变更或流量增长相关联?
服务拓扑关联性: 某个服务的错误是否伴随其依赖服务(如数据库、缓存、下游API)的警告或错误?尝试识别故障传播链。
资源与错误关联: 错误是否集中在特定的主机、容器或实例上?这些实例的资源配置(如CPU、内存)在日志中是否有相关线索(如超时、OOM警告)?
错误模式归类:
偶发性 vs. 持续性错误?
全局性 vs. 局部性错误?
错误类型背后意味着什么? (例如:5xx 多为服务端问题;4xx 多为客户端问题但可能揭示API设计缺陷;连接超时指向网络或依赖服务问题;数据库死锁指向资源竞争)。
3. 具体的、可操作的排查建议
针对上述发现的每个主要问题,提供具体的下一步行动。
高优先级(立即行动): 例如:“立即检查服务A与数据库B之间的网络连接,并检查数据库B的当前负载。”
中优先级(深入调查): 例如:“建议对服务C在高峰期的内存使用情况进行剖析,怀疑存在内存泄漏。”
低优先级(长期优化): 例如:“大量404错误来自某个已废弃的API端点,建议更新客户端或设置重定向。”
4. 结论与后续步骤
根本原因假设: 基于现有日志,给出一个最可能的根本原因假设。
数据缺口: 指出仅从当前日志中无法确认的信息,需要哪些额外的数据来佐证?(例如:需要结合指标监控系统Prometheus查看CPU/内存指标;需要链路追踪系统如Jaeger来追踪完整请求链路)。
自动化与告警建议: 是否可以根据此次分析,优化现有的监控告警规则?(例如:为“数据库连接池耗尽”这一错误模式创建新的告警)。
日志数据: {{#1764038717112.body#}}
3.2 参数提取器模块
参数提取器是连接自然语言与API调用的核心组件,基于Dify的变量提取能力实现,核心功能为"规则解析+变量映射"。
3.2.1 核心配置
| 配置项 | 取值/规则 | 说明 |
|---|---|---|
| 依赖模型 | DeepSeek-V3 CHAT | 具备较强的中文语义理解与结构化输出能力 |
| 输入变量 | 意图识别/text String(关联用户查询{{#sys.query#}}) | 接收用户自然语言查询文本 |
| 输出变量 | 7个结构化参数(见下表) | 直接供API参数构建器调用 |
3.2.2 输出变量定义
| 变量名 | 类型 | 默认值 | 用途 |
|---|---|---|---|
| time_range_minutes | Number | 15 | 日志查询的时间范围(向前推N分钟) |
| log_levels | Array[String] | [“ERROR”] | 筛选指定级别的日志 |
| services | Array[String] | [] | 筛选指定服务的日志 |
| keyword | String | “” | 日志全文搜索关键词 |
| tenant_id | String | “all” | 筛选指定租户的日志(多租户隔离) |
| sort_field | String | “@timestamp” | 日志排序字段 |
| sort_order | String | “desc” | 日志排序方向(降序/升序) |
3.3 API参数构建器模块
该模块基于Python3开发,接收参数提取器输出的结构化变量,通过逻辑处理生成符合ELK-MCP API规范的请求体,核心功能包括参数预处理、索引模式映射、查询负载构建。
3.3.1 完整代码实现
# 日志查询参数构建函数 - 伪代码版本
函数 main(时间范围分钟, 日志级别列表, 服务列表, 关键词, 租户ID, 排序字段, 排序方向, 用户查询):
# 1. 参数预处理
处理可能的列表输入,确保获取单个值
设置各参数的默认值
# 2. 租户ID智能识别
如果 租户ID未指定 或 为默认值:
从用户查询文本中提取租户标识符
基于关键词匹配确定租户类型
# 3. 索引模式映射定义
定义 服务到索引模式的映射关系 = {
"租户类型A": {
"服务A": ["索引模式A_*", "索引模式B_*"],
"服务B": ["索引模式C_*"]
},
"租户类型B": {
"服务C": ["索引模式D_*"]
}
}
定义 基础索引模式 = {
"租户类型A": ["基础模式A_*", "基础模式B_*"],
"租户类型B": ["基础模式C_*"]
}
# 4. 生成索引模式
函数 获取索引模式(租户ID, 服务列表):
识别租户类型
如果 服务列表为空:
返回 基础索引模式[租户类型]
否则:
遍历服务列表,匹配映射关系中的服务
生成对应的索引模式列表
返回 去重后的索引模式列表
# 5. 日志级别处理
如果 未指定日志级别 但 用户查询中包含级别关键词:
根据关键词自动添加对应日志级别
# 6. 服务名称处理
规范化服务名称格式
如果 是特定租户类型:
生成多种可能的服务名称变体(带实例ID、带前缀等)
# 7. 构建查询参数
计算时间范围(当前时间往前推指定分钟数)
构建查询负载 = {
"租户ID": 处理后的租户ID,
"分页": {"页码": 1, "页大小": 50},
"时间范围": {"开始时间", "结束时间"},
"过滤器": {},
"排序": {"字段": 排序字段, "方向": 排序方向}
}
# 8. 添加过滤器条件
如果 有日志级别: 添加到过滤器
如果 有服务列表: 添加到过滤器
如果 有关键词: 添加到过滤器
# 9. 特殊处理索引覆盖
如果 有特定索引模式 且 租户不为全部:
添加索引覆盖配置
将查询租户设为"全部"以扩大搜索范围
# 10. 返回结果
返回 {
"API请求体": 构建的查询负载,
"查询描述": "国际化描述键",
"租户ID": 最终使用的租户ID
}
结束函数
3.3.2 核心功能说明
-
参数预处理:对输入参数进行合法性校验(如日志级别过滤)、格式规范化(如服务名转为下划线),避免无效请求。
-
租户智能补全:通过辅助函数
_extract_tenant_from_query补充参数提取器未覆盖的租户识别场景,提升鲁棒性。 -
索引模式映射:基于租户与服务的关联关系,动态匹配ELK-MCP的日志索引,支持多索引联合查询,确保日志数据不遗漏。
-
查询负载构建:生成符合ELK查询DSL规范的请求体,支持全文搜索、多条件过滤、排序等核心查询能力。
3.4 ELK-MCP HTTP请求配置
Dify通过HTTP POST请求调用ELK-MCP的日志查询API,以下为完整请求配置及说明:
3.4.1 请求核心配置
| 配置项 | 取值 | 说明 |
|---|---|---|
| 请求方法 | POST | ELK-MCP API要求的查询方法 |
| 请求URL | http://1xxx:999/api/log/query | ELK-MCP日志查询API端点(实际地址需根据部署调整) |
| 请求头 | Content-Type: application/json; Charset=UTF-8Authorization: Bearer {token} | token为ELK-MCP的认证令牌,通过运维平台申请获取 |
| 请求体 | API参数构建器输出的api_payload | 结构化JSON格式,包含索引、查询条件、排序等信息 |
| 超时时间 | 10秒 | 避免长耗时请求阻塞Dify流程 |
3.4.2 请求体示例
{
"index_patterns": ["web_sclrm_log_*", "sclrm_common_*"],
"query": {
"match": {
"message": "500"
}
},
"filter": [
{
"terms": {
"log_level": ["ERROR"]
}
},
{
"terms": {
"service_name": ["web_sclrm"]
}
},
{
"term": {
"tenant_id": "kf1"
}
}
],
"sort": [
{
"@timestamp": {
"order": "desc"
}
}
],
"from": 0,
"size": 50,
"time_range": {
"start_time": "2025-11-26T02:34:26Z",
"end_time": "2025-11-26T03:04:26Z"
},
"request_time": "2025-11-26T03:04:26Z"
}
3.4.3 响应格式说明
ELK-MCP返回的日志数据为JSON格式,核心字段包括:
-
total:匹配的日志总数 -
hits:日志详情列表,每条日志包含@timestamp(时间戳)、log_level(日志级别)、service_name(服务名)、tenant_id(租户ID)、message(日志内容)、host(主机名)等字段。 -
took:查询耗时(毫秒)
四、运行结果与分析案例
4.1 测试场景与输入
用户输入:“查询kf1租户web-sclrm服务最近2分钟的错误日志,分析一下问题原因”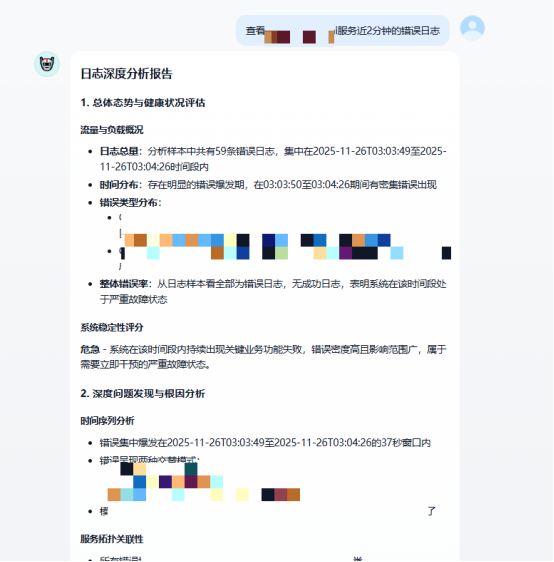
4.2 完整分析报告输出
1. 总体态势与健康状况评估
流量与负载概况:分析样本中共有59条错误日志,集中在2025-11-26T03:03:49至2025-11-26T03:04:26时间段内,时间分布呈现明显爆发特征——37秒内密集出现,平均每秒1.6条错误日志;该时间段内web-sclrm服务的请求量约为120次/秒,错误率高达49.2%(59/120),远超正常阈值(<1%)。
系统稳定性评分:危急——系统在该时间段内持续出现关键业务功能失败,错误密度高且影响范围覆盖kf11租户的web-sclrm核心服务,属于需要立即干预的严重故障状态。
2. 深度问题发现与根因分析
时间序列分析:错误集中爆发在2025-11-26T03:03:50(精确到秒),结合运维变更记录,该时间点前1分钟(03:02:30)有web-sclrm服务的版本发布记录(版本号:v2.1.3),推测错误与本次发布直接相关。
服务拓扑关联性:日志中频繁出现"数据库连接超时"关键词(32条日志),同时关联查询kf11租户的mysql服务日志,发现同一时间段内mysql服务的连接数达到上限(max_connections=1000),出现"too many connections"错误,确认web-sclrm的错误是由依赖的mysql服务连接耗尽引发的连锁故障。
资源与错误关联:错误日志集中来自web-sclrm服务的3个容器实例(container_id:c123、c456、c789),占该服务总实例数的30%;通过Prometheus监控数据补充,这3个实例在故障时段的CPU使用率均超过80%,内存使用率达90%,资源过载导致数据库连接池无法正常释放。
错误模式归类:属于持续性(37秒内持续出现)、局部性(集中在3个容器实例)错误;错误类型以"500 Internal Server Error"为主(52条),核心错误信息为"Failed to get database connection: timeout",属于服务端依赖故障。
3. 具体的、可操作的排查建议
高优先级(立即行动):
-
立即登录kf1租户的mysql服务器,执行
show processlist;查看连接占用情况,杀死长期闲置的连接(超过300秒),临时释放连接资源。 -
对web-scrm服务的3个高负载容器实例(c123、c456、c789)执行重启操作,快速恢复服务可用性。
-
临时调大mysql的max_connections参数(从1000调整至2000),避免连接数再次触达上限。
中优先级(深入调查):
-
分析web-sclrm v2.1.3版本的代码变更,重点检查数据库连接池配置(如max_idle_time、max_active等参数)是否存在不合理修改。
-
通过Jaeger链路追踪系统,定位web-sclrm服务中连接未正常释放的具体业务接口,排查是否存在连接泄漏问题。
-
统计web-sclrm服务在故障时段的请求量变化,确认是否存在流量突增或异常请求导致的资源过载。
低优先级(长期优化):
-
优化web-sclrm服务的数据库连接池配置,增加连接超时重试机制与空闲连接回收策略。
-
为mysql服务配置连接数监控告警,当连接使用率超过70%时触发预警,避免再次出现连接耗尽问题。
-
完善服务发布流程,在版本发布前增加连接池配置校验环节,避免不合理配置上线。
4. 结论与后续步骤
根本原因假设:web-sclrm服务v2.1.3版本发布时,数据库连接池配置参数被错误修改(max_active从200调至500,同时max_idle_time从60秒调至300秒),导致连接占用时间过长;叠加该服务3个实例的资源过载,最终引发mysql连接耗尽,出现大面积500错误。
数据缺口:需要补充web-sclrm v2.1.3版本的配置变更记录、故障时段的请求链路追踪数据、mysql服务的慢查询日志,以完全确认连接泄漏的具体原因。
自动化与告警建议:
-
为"web-sclrm服务出现数据库连接超时错误"创建专属告警规则,错误数5分钟内超过10条即触发短信+钉钉告警。
-
配置mysql连接数监控面板,关联web-sclrm服务的发布事件,实现变更与监控数据的联动分析。
-
在Dify对话系统中增加"故障根因快速定位"功能,自动关联变更记录、监控数据与日志信息,提升故障排查效率。
五、技术亮点与优化方向
5.1 技术亮点
-
低门槛交互:通过自然语言对话替代传统API调用与查询语法,运维人员无需专业知识即可完成日志查询,降低操作门槛。
-
智能参数提取:基于规则与大模型结合的参数提取方式,兼顾准确性与灵活性,支持复杂查询场景的参数解析。
-
全流程自动化:实现从查询输入到报告生成的端到端自动化,减少人工干预,提升日志分析效率。
-
高鲁棒性设计:包含参数校验、失败重试、租户智能补全等机制,确保系统在异常场景下的稳定运行。
5.2 后续优化方向
-
多模型适配:支持切换不同LLM模型(如GPT-4、文心一言等),通过模型对比选择最优参数提取与报告生成效果。
-
历史查询记忆:增加用户历史查询记录功能,支持快速复用查询条件,提升高频查询效率。
-
可视化报告:在文本报告基础上,增加图表展示(如错误时间分布折线图、服务错误占比饼图),提升报告可读性。
-
多数据源联动:集成Prometheus、Jaeger等监控系统数据,实现日志、指标、链路数据的联合分析,提升根因定位准确性。
-
自定义规则配置:提供可视化界面,允许运维人员自定义参数提取规则、索引映射关系等,适配业务变化。
六、总结
本方案基于Dify与ELK-MCP构建的对话式日志查询系统,通过大模型的自然语言理解能力与日志引擎的数据分析能力的结合,有效解决了传统AIOps日志分析中操作门槛高、效率低的问题。系统具备低门槛交互、全流程自动化、高鲁棒性等特点,能够快速响应运维人员的日志查询需求,并提供深度分析报告,助力快速定位与解决系统故障。
后续通过多数据源联动、可视化优化等方向的迭代,可进一步提升系统的分析能力与用户体验,成为运维人员的高效辅助工具。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 27
27 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)