LightRAG实战基于v1.4.9.3&windows平台
本文介绍了LightRAG系统的本地部署方法及知识图谱构建应用。部署过程包括:1)源码安装LightRAG Core和Server;2)配置WebUI和API接口。在中医药知识图谱构建案例中,系统成功提取了淡竹叶、莲子等药材实体及其功效、应用等关系,并通过四种查询模式(naive/local/global/hybrid)验证了检索效果。知识图谱构建采用了标准化的实体关系提取指令,确保输出格式规范统
1.本地部署
1.1 基于源码(面向开发者)
拉取源码:
Release v1.4.9.3 · HKUDS/LightRAG
1) 安装 LightRAG Core
cd LightRAG
pip install -e .
2) 安装 LightRAG Server
LightRAG Server(LightRAG 服务器)旨在提供 Web 界面(Web UI)和编程接口(API)支持。Web 界面可实现文档索引、知识图谱探索功能,并提供一个简洁的检索增强生成(RAG)查询界面。LightRAG 服务器还提供与 Ollama 兼容的接口,其目的是将 LightRAG 模拟为 Ollama 聊天模型。这一设计能让 Open WebUI 等 AI 聊天机器人轻松接入 LightRAG。
cd LightRAG
cp env.example .env # Update the .env with your LLM and embedding configurations
# Build fornt-end artifacts
cd lightrag_webui
bun install --frozen-lockfile
bun run build
cd ..
lightrag-server
2.LightRAG项目实战--
2.1 源文本
中药药谱文本:
第一章 养生必先养五脏
养心
淡竹叶
《本草纲目》记载淡竹叶:“去烦热,利小便,清心。”
【药材档案】
别名:竹叶门冬青、迷身草、山鸡米、长竹叶、山冬、地竹、林下竹等。
来源:禾本科植物淡竹叶的干燥茎叶。
性味归经:甘、淡,寒。归心、胃、小肠经。
【传统功用】
1.清心泻火:用于心火口疮,心烦口渴。
2.利尿通淋:用于热淋涩痛,浮肿黄疸。
【药理作用】
解热;利尿;抑菌;升高血糖等。
【应用指南】治疗尿血
淡竹叶、白茅根各15克,水煎服,每日一剂。
治疗心火旺盛之暑热
淡竹叶、木通各12克,生地18克,甘草梢6克,水煎服。
莲子
《本草纲目》记载莲子:“交心肾,厚肠胃,固精气,强筋骨,补虚损,利耳目,除寒湿,止脾泄久痢,赤白浊,女人带下崩中诸血病。”
【药材档案】
别名:藕实、水芝丹、莲蓬子、莲实。
来源:睡莲科植物莲的干燥成熟种子。
性味归经:甘、涩,平。归脾、肾、心经。
【传统功用】
1.补脾,止泻:用于脾虚久泻、带下清稀等。
2.养心安神:用于气阴不足、心失所养、失眠多梦等。
【药理作用】
收敛;镇静;延缓衰老等。
【应用指南】治疗萎缩性胃炎
莲子、糯米各50克,红糖1匙。莲子用开水泡胀,削皮去心,倒入锅内,加水,小火先煮半小时备用。再将糯米洗净倒入锅内,加水,大火10分钟后倒入莲肉及汤,加糖,改用小火炖半小时即可。柏子仁
《本草纲目》记载柏子仁:“养心气,润肾燥,安魂定魄,益智宁神;烧沥,泽头发,治疥癣。”
【药材档案】
别名:柏实、柏子、柏仁、侧柏子。
来源:柏科植物侧柏的干燥成熟种仁。
性味归经:甘,平。归心、肾、大肠经。
【传统功用】
养心安神:用于心阴不足、心血亏虚、心神失养之失眠多梦、惊悸怔忡以及体虚多汗等。常配伍补气养血药。
【药理作用】
催眠。
【应用指南】治疗面色萎黄
柏子仁15克,粳米100克,蜂蜜25克,水600~800毫升。将柏子仁去尽皮壳,捣烂,粳米淘净,一起放入锅中,加水大火煮沸,再用小火熬至汤浓米烂即成。每日1~2次,趁温热时服食。粥中以柏子仁少佐蜂蜜,润肤泽面效果更好。
合欢皮
《本草纲目》记载合欢皮:“和血,消肿,止痛。”
【药材档案】
别名:夜合皮、合欢木皮。
来源:豆科植物合欢的干燥树皮。
性味归经:甘,平。归心、肝、肺经。
【传统功用】
1.解郁安神:用于忧郁气恼、烦闷不安等。
2.活血消肿:用于痈疽疮肿、外伤瘀肿等。
【药理作用】
镇静,催眠;抗生育;抗过敏;抗肿瘤。
【应用指南】治疗咳嗽兼有微热、肺痈
合欢皮手掌大1片,细切,以水3升,煮取1升,分3次服。
治疗骨折
合欢皮(去粗皮,取白皮,锉碎,炒令黄微黑色)120克,芥菜子(炒)30克。上药共为细末,酒调,临夜服;粗渣敷于患处。
2.2 配置API
以openai 标准的大模型api为例子,主要涉及 LLM 大模型 API 和 Embedding 模型 API。
import os
import asyncio
import inspect
import logging
import logging.config
from lightrag import LightRAG, QueryParam
from lightrag.llm.openai import openai_complete_if_cache
from lightrag.llm.ollama import ollama_embed
from lightrag.utils import EmbeddingFunc, logger, set_verbose_debug
from lightrag.kg.shared_storage import initialize_pipeline_status
from dotenv import load_dotenv
load_dotenv(dotenv_path=".env", override=False)
WORKING_DIR = "./dickens"
def configure_logging():
"""Configure logging for the application"""
# Reset any existing handlers to ensure clean configuration
for logger_name in ["uvicorn", "uvicorn.access", "uvicorn.error", "lightrag"]:
logger_instance = logging.getLogger(logger_name)
logger_instance.handlers = []
logger_instance.filters = []
# Get log directory path from environment variable or use current directory
log_dir = os.getenv("LOG_DIR", os.getcwd())
log_file_path = os.path.abspath(
os.path.join(log_dir, "lightrag_compatible_demo.log")
)
print(f"\nLightRAG compatible demo log file: {log_file_path}\n")
os.makedirs(os.path.dirname(log_dir), exist_ok=True)
# Get log file max size and backup count from environment variables
log_max_bytes = int(os.getenv("LOG_MAX_BYTES", 10485760)) # Default 10MB
log_backup_count = int(os.getenv("LOG_BACKUP_COUNT", 5)) # Default 5 backups
logging.config.dictConfig(
{
"version": 1,
"disable_existing_loggers": False,
"formatters": {
"default": {
"format": "%(levelname)s: %(message)s",
},
"detailed": {
"format": "%(asctime)s - %(name)s - %(levelname)s - %(message)s",
},
},
"handlers": {
"console": {
"formatter": "default",
"class": "logging.StreamHandler",
"stream": "ext://sys.stderr",
},
"file": {
"formatter": "detailed",
"class": "logging.handlers.RotatingFileHandler",
"filename": log_file_path,
"maxBytes": log_max_bytes,
"backupCount": log_backup_count,
"encoding": "utf-8",
},
},
"loggers": {
"lightrag": {
"handlers": ["console", "file"],
"level": "INFO",
"propagate": False,
},
},
}
)
# Set the logger level to INFO
logger.setLevel(logging.INFO)
# Enable verbose debug if needed
set_verbose_debug(os.getenv("VERBOSE_DEBUG", "false").lower() == "true")
if not os.path.exists(WORKING_DIR):
os.mkdir(WORKING_DIR)
async def llm_model_func(
prompt, system_prompt=None, history_messages=[], keyword_extraction=False, **kwargs
) -> str:
return await openai_complete_if_cache(
os.getenv("LLM_MODEL", "deepseek-chat"),
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key=os.getenv("LLM_BINDING_API_KEY") or os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("LLM_BINDING_HOST", "https://api.deepseek.com"),
**kwargs,
)
async def print_stream(stream):
async for chunk in stream:
if chunk:
print(chunk, end="", flush=True)
async def initialize_rag():
rag = LightRAG(
working_dir=WORKING_DIR,
llm_model_func=llm_model_func,
embedding_func=EmbeddingFunc(
embedding_dim=int(os.getenv("EMBEDDING_DIM", "1024")),
max_token_size=int(os.getenv("MAX_EMBED_TOKENS", "8192")),
func=lambda texts: ollama_embed(
texts,
embed_model=os.getenv("EMBEDDING_MODEL", "bge-m3:latest"),
host=os.getenv("EMBEDDING_BINDING_HOST", "http://localhost:11434"),
),
),
)
await rag.initialize_storages()
await initialize_pipeline_status()
return rag
async def main():
try:
# Clear old data files
files_to_delete = [
"graph_chunk_entity_relation.graphml",
"kv_store_doc_status.json",
"kv_store_full_docs.json",
"kv_store_text_chunks.json",
"vdb_chunks.json",
"vdb_entities.json",
"vdb_relationships.json",
]
for file in files_to_delete:
file_path = os.path.join(WORKING_DIR, file)
if os.path.exists(file_path):
os.remove(file_path)
print(f"Deleting old file:: {file_path}")
# Initialize RAG instance
rag = await initialize_rag()
# Test embedding function
test_text = ["This is a test string for embedding."]
embedding = await rag.embedding_func(test_text)
embedding_dim = embedding.shape[1]
print("\n=======================")
print("Test embedding function")
print("========================")
print(f"Test dict: {test_text}")
print(f"Detected embedding dimension: {embedding_dim}\n\n")
with open("./book.txt", "r", encoding="utf-8") as f:
await rag.ainsert(f.read())
# Perform naive search
print("\n=====================")
print("Query mode: naive")
print("=====================")
resp = await rag.aquery(
"What are the top themes in this story?",
param=QueryParam(mode="naive", stream=True),
)
if inspect.isasyncgen(resp):
await print_stream(resp)
else:
print(resp)
# Perform local search
print("\n=====================")
print("Query mode: local")
print("=====================")
resp = await rag.aquery(
"What are the top themes in this story?",
param=QueryParam(mode="local", stream=True),
)
if inspect.isasyncgen(resp):
await print_stream(resp)
else:
print(resp)
# Perform global search
print("\n=====================")
print("Query mode: global")
print("=====================")
resp = await rag.aquery(
"What are the top themes in this story?",
param=QueryParam(mode="global", stream=True),
)
if inspect.isasyncgen(resp):
await print_stream(resp)
else:
print(resp)
# Perform hybrid search
print("\n=====================")
print("Query mode: hybrid")
print("=====================")
resp = await rag.aquery(
"What are the top themes in this story?",
param=QueryParam(mode="hybrid", stream=True),
)
if inspect.isasyncgen(resp):
await print_stream(resp)
else:
print(resp)
except Exception as e:
print(f"An error occurred: {e}")
finally:
if rag:
await rag.finalize_storages()
if __name__ == "__main__":
# Configure logging before running the main function
configure_logging()
asyncio.run(main())
print("\nDone!")
也可以不用openai的格式,直接自己写基于request的大模型 api 接口,具体根据所使用的api交互形式。
import os
import asyncio
import inspect
import logging
import logging.config
import requests
import json
from lightrag import LightRAG, QueryParam
from lightrag.llm.openai import openai_complete_if_cache
from lightrag.llm.openai import openai_embed
from lightrag.utils import EmbeddingFunc, logger, set_verbose_debug
from lightrag.kg.shared_storage import initialize_pipeline_status
from dotenv import load_dotenv
load_dotenv(dotenv_path=".env", override=False)
WORKING_DIR = "LightRAG\myproject\demo\dickens"
# 配置您的API密钥
LLM_API_KEY = os.getenv("LLM_BINDING_API_KEY", "xxxxxxxxxxxxxxxxxxx") # 大模型API密钥
EMBEDDING_API_KEY = os.getenv("EMBEDDING_BINDING_API_KEY", "xxxxxxxxxxxxxxxxxxxxxx") # Embedding模型API密钥
# 大模型API配置
LLM_API_URL = os.getenv(
"LLM_BINDING_HOST",
"xxxxxxxxxxxxxxxxxxxxx大模型的调用APIxxxxxxxxxxx",
)
LLM_MODEL = os.getenv("LLM_MODEL", "模型名")
# Embedding模型API配置
EMBEDDING_API_URL = os.getenv(
"EMBEDDING_BINDING_HOST",
"xxxxxxxxxxxxxxxxxxxEmbedding_apixxxxxxxxxxxxxxx",
)
EMBEDDING_MODEL = "Embedding模型名"
def configure_logging():
"""Configure logging for the application"""
# Reset any existing handlers to ensure clean configuration
for logger_name in ["uvicorn", "uvicorn.access", "uvicorn.error", "lightrag"]:
logger_instance = logging.getLogger(logger_name)
logger_instance.handlers = []
logger_instance.filters = []
# Get log directory path from environment variable or use current directory
log_dir = os.getenv("LOG_DIR", os.getcwd())
log_file_path = os.path.abspath(os.path.join(log_dir, "lightrag_compatible_demo.log"))
print(f"\nLightRAG compatible demo log file: {log_file_path}\n")
os.makedirs(os.path.dirname(log_dir), exist_ok=True)
# Get log file max size and backup count from environment variables
log_max_bytes = int(os.getenv("LOG_MAX_BYTES", 10485760)) # Default 10MB
log_backup_count = int(os.getenv("LOG_BACKUP_COUNT", 5)) # Default 5 backups
logging.config.dictConfig(
{
"version": 1,
"disable_existing_loggers": False,
"formatters": {
"default": {
"format": "%(levelname)s: %(message)s",
},
"detailed": {
"format": "%(asctime)s - %(name)s - %(levelname)s - %(message)s",
},
},
"handlers": {
"console": {
"formatter": "default",
"class": "logging.StreamHandler",
"stream": "ext://sys.stderr",
},
"file": {
"formatter": "detailed",
"class": "logging.handlers.RotatingFileHandler",
"filename": log_file_path,
"maxBytes": log_max_bytes,
"backupCount": log_backup_count,
"encoding": "utf-8",
},
},
"loggers": {
"lightrag": {
"handlers": ["console", "file"],
"level": "INFO",
"propagate": False,
},
},
}
)
# Set the logger level to INFO
logger.setLevel(logging.INFO)
# Enable verbose debug if needed
set_verbose_debug(os.getenv("VERBOSE_DEBUG", "false").lower() == "true")
if not os.path.exists(WORKING_DIR):
os.mkdir(WORKING_DIR)
async def llm_model_func(prompt, system_prompt=None, history_messages=[], keyword_extraction=False, **kwargs) -> str:
"""
使用自定义API调用大模型
"""
headers = {"Content-Type": "application/json", "Authorization": f"Bearer {LLM_API_KEY}"}
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.extend(history_messages)
messages.append({"role": "user", "content": prompt})
payload = {
"model": LLM_MODEL,
"stream": False,
"temperature": 0.6,
"chat_template_kwargs": {"enable_thinking": True},
"messages": messages,
}
try:
response = requests.post(LLM_API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
if "choices" in result and len(result["choices"]) > 0:
return result["choices"][0]["message"]["content"]
else:
raise Exception("Invalid response format from LLM API")
except requests.exceptions.RequestException as e:
logger.error(f"LLM API调用失败: {e}")
raise
except json.JSONDecodeError as e:
logger.error(f"解析LLM响应JSON失败: {e}")
raise
except Exception as e:
logger.error(f"处理LLM响应时出错: {e}")
raise
async def embedding_func(texts):
"""
使用自定义API调用Embedding模型
"""
headers = {"Content-Type": "application/json", "Authorization": f"Bearer {EMBEDDING_API_KEY}"}
payload = {"model": EMBEDDING_MODEL, "input": texts}
try:
response = requests.post(EMBEDDING_API_URL, headers=headers, data=json.dumps(payload))
response.raise_for_status()
result = response.json()
if "data" in result and len(result["data"]) > 0:
# 提取嵌入向量
embeddings = [item["embedding"] for item in result["data"]]
import numpy as np
return np.array(embeddings, dtype=np.float32)
else:
raise Exception("Invalid response format from Embedding API")
except requests.exceptions.RequestException as e:
logger.error(f"Embedding API调用失败: {e}")
raise
except json.JSONDecodeError as e:
logger.error(f"解析Embedding响应JSON失败: {e}")
raise
except Exception as e:
logger.error(f"处理Embedding响应时出错: {e}")
raise
async def print_stream(stream):
async for chunk in stream:
if chunk:
print(chunk, end="", flush=True)
async def initialize_rag():
rag = LightRAG(
working_dir=WORKING_DIR,
llm_model_func=llm_model_func,
embedding_func=EmbeddingFunc(
embedding_dim=int(os.getenv("EMBEDDING_DIM", "4096")), # 修改为4096以匹配Qwen3-Embedding-8B模型
max_token_size=int(os.getenv("MAX_EMBED_TOKENS", "8192")),
func=embedding_func,
),
addon_params={
"language": "Simplified Chinese",
},
)
await rag.initialize_storages()
await initialize_pipeline_status()
return rag
async def main():
try:
# Clear old data files
# files_to_delete = [
# "graph_chunk_entity_relation.graphml",
# "kv_store_doc_status.json",
# "kv_store_full_docs.json",
# "kv_store_text_chunks.json",
# "vdb_chunks.json",
# "vdb_entities.json",
# "vdb_relationships.json",
# ]
# for file in files_to_delete:
# file_path = os.path.join(WORKING_DIR, file)
# if os.path.exists(file_path):
# os.remove(file_path)
# print(f"Deleting old file:: {file_path}")
# Initialize RAG instance
rag = await initialize_rag()
# Test embedding function
test_text = ["This is a test string for embedding."]
embedding = await rag.embedding_func(test_text)
embedding_dim = embedding.shape[1]
print("\n=======================")
print("Test embedding function")
print("========================")
print(f"Test dict: {test_text}")
print(f"Detected embedding dimension: {embedding_dim}\n\n")
with open("LightRAG\\myproject\\data\\book.txt", "r", encoding="utf-8") as f:
await rag.ainsert(f.read())
# Perform naive search
print("\n=====================")
print("Query mode: naive")
print("=====================")
resp = await rag.aquery(
"养心推荐哪几种草药?",
param=QueryParam(mode="naive", stream=True),
)
if inspect.isasyncgen(resp):
await print_stream(resp)
else:
print(resp)
# Perform local search
print("\n=====================")
print("Query mode: local")
print("=====================")
resp = await rag.aquery(
"养心推荐哪几种草药?",
param=QueryParam(mode="local", stream=True),
)
if inspect.isasyncgen(resp):
await print_stream(resp)
else:
print(resp)
# Perform global search
print("\n=====================")
print("Query mode: global")
print("=====================")
resp = await rag.aquery(
"养心推荐哪几种草药?",
param=QueryParam(mode="global", stream=True),
)
if inspect.isasyncgen(resp):
await print_stream(resp)
else:
print(resp)
# Perform hybrid search
print("\n=====================")
print("Query mode: hybrid")
print("=====================")
resp = await rag.aquery(
"养心推荐哪几种草药?",
param=QueryParam(mode="hybrid", stream=True),
)
if inspect.isasyncgen(resp):
await print_stream(resp)
else:
print(resp)
except Exception as e:
print(f"An error occurred: {e}")
finally:
if "rag" in locals():
await rag.finalize_storages()
if __name__ == "__main__":
# Configure logging before running the main function
configure_logging()
asyncio.run(main())
print("\nDone!")
知识图谱实体与关系提取指令解析:
提示词:
---Task---\nExtract entities and relationships from the input text to be processed.\n\n---Instructions---\n1. **Strict Adherence to Format:** Strictly adhere to all format requirements for entity and relationship lists, including output order, field delimiters, and proper noun handling, as specified in the system prompt.\n2. **Output Content Only:** Output *only* the extracted list of entities and relationships. Do not include any introductory or concluding remarks, explanations, or additional text before or after the list.\n3. **Completion Signal:** Output `<|COMPLETE|>` as the final line after all relevant entities and relationships have been extracted and presented.\n4. **Output Language:** Ensure the output language is Simplified Chinese. Proper nouns (e.g., personal names, place names, organization names) must be kept in their original language and not translated.\n\n<Output>\n---Role---\nYou are a Knowledge Graph Specialist responsible for extracting entities and relationships from the input text.\n\n---Instructions---\n1. **Entity Extraction & Output:**\n * **Identification:** Identify clearly defined and meaningful entities in the input text.\n * **Entity Details:** For each identified entity, extract the following information:\n * `entity_name`: The name of the entity. If the entity name is case-insensitive, capitalize the first letter of each significant word (title case). Ensure **consistent naming** across the entire extraction process.\n * `entity_type`: Categorize the entity using one of the following types: `Person,Creature,Organization,Location,Event,Concept,Method,Content,Data,Artifact,NaturalObject`. If none of the provided entity types apply, do not add new entity type and classify it as `Other`.\n * `entity_description`: Provide a concise yet comprehensive description of the entity's attributes and activities, based *solely* on the information present in the input text.\n * **Output Format - Entities:** Output a total of 4 fields for each entity, delimited by `<|#|>`, on a single line. The first field *must* be the literal string `entity`.\n * Format: `entity<|#|>entity_name<|#|>entity_type<|#|>entity_description`\n\n2. **Relationship Extraction & Output:**\n * **Identification:** Identify direct, clearly stated, and meaningful relationships between previously extracted entities.\n * **N-ary Relationship Decomposition:** If a single statement describes a relationship involving more than two entities (an N-ary relationship), decompose it into multiple binary (two-entity) relationship pairs for separate description.\n * **Example:** For \"Alice, Bob, and Carol collaborated on Project X,\" extract binary relationships such as \"Alice collaborated with Project X,\" \"Bob collaborated with Project X,\" and \"Carol collaborated with Project X,\" or \"Alice collaborated with Bob,\" based on the most reasonable binary interpretations.\n * **Relationship Details:** For each binary relationship, extract the following fields:\n * `source_entity`: The name of the source entity. Ensure **consistent naming** with entity extraction. Capitalize the first letter of each significant word (title case) if the name is case-insensitive.\n * `target_entity`: The name of the target entity. Ensure **consistent naming** with entity extraction. Capitalize the first letter of each significant word (title case) if the name is case-insensitive.\n * `relationship_keywords`: One or more high-level keywords summarizing the overarching nature, concepts, or themes of the relationship. Multiple keywords within this field must be separated by a comma `,`. **DO NOT use `<|#|>` for separating multiple keywords within this field.**\n * `relationship_description`: A concise explanation of the nature of the relationship between the source and target entities, providing a clear rationale for their connection.\n * **Output Format - Relationships:** Output a total of 5 fields for each relationship, delimited by `<|#|>`, on a single line. The first field *must* be the literal string `relation`.\n * Format: `relation<|#|>source_entity<|#|>target_entity<|#|>relationship_keywords<|#|>relationship_description`\n\n3. **Delimiter Usage Protocol:**\n * The `<|#|>` is a complete, atomic marker and **must not be filled with content**. It serves strictly as a field separator.\n * **Incorrect Example:** `entity<|#|>Tokyo<|location|>Tokyo is the capital of Japan.`\n * **Correct Example:** `entity<|#|>Tokyo<|#|>location<|#|>Tokyo is the capital of Japan.`\n\n4. **Relationship Direction & Duplication:**\n * Treat all relationships as **undirected** unless explicitly stated otherwise. Swapping the source and target entities for an undirected relationship does not constitute a new relationship.\n * Avoid outputting duplicate relationships.\n\n5. **Output Order & Prioritization:**\n * Output all extracted entities first, followed by all extracted relationships.\n * Within the list of relationships, prioritize and output those relationships that are **most significant** to the core meaning of the input text first.\n\n6. **Context & Objectivity:**\n * Ensure all entity names and descriptions are written in the **third person**.\n * Explicitly name the subject or object; **avoid using pronouns** such as `this article`, `this paper`, `our company`, `I`, `you`, and `he/she`.\n\n7. **Language & Proper Nouns:**\n * The entire output (entity names, keywords, and descriptions) must be written in `Simplified Chinese`.\n * Proper nouns (e.g., personal names, place names, organization names) should be retained in their original language if a proper, widely accepted translation is not available or would cause ambiguity.\n\n8. **Completion Signal:** Output the literal string `<|COMPLETE|>` only after all entities and relationships, following all criteria, have been completely extracted and outputted.\n\n---Examples---\n<Input Text>\n```\nwhile Alex clenched his jaw, the buzz of frustration dull against the backdrop of Taylor's authoritarian certainty. It was this competitive undercurrent that kept him alert, the sense that his and Jordan's shared commitment to discovery was an unspoken rebellion against Cruz's narrowing vision of control and order.\n\nThen Taylor did something unexpected. They paused beside Jordan and, for a moment, observed the device with something akin to reverence. \"If this tech can be understood...\" Taylor said, their voice quieter, \"It could change the game for us. For all of us.\"\n\nThe underlying dismissal earlier seemed to falter, replaced by a glimpse of reluctant respect for the gravity of what lay in their hands. Jordan looked up, and for a fleeting heartbeat, their eyes locked with Taylor's, a wordless clash of wills softening into an uneasy truce.\n\nIt was a small transformation, barely perceptible, but one that Alex noted with an inward nod. They had all been brought here by different paths\n```\n\n<Output>\nentity<|#|>Alex<|#|>person<|#|>Alex is a character who experiences frustration and is observant of the dynamics among other characters.\nentity<|#|>Taylor<|#|>person<|#|>Taylor is portrayed with authoritarian certainty and shows a moment of reverence towards a device, indicating a change in perspective.\nentity<|#|>Jordan<|#|>person<|#|>Jordan shares a commitment to discovery and has a significant interaction with Taylor regarding a device.\nentity<|#|>Cruz<|#|>person<|#|>Cruz is associated with a vision of control and order, influencing the dynamics among other characters.\nentity<|#|>The Device<|#|>equiment<|#|>The Device is central to the story, with potential game-changing implications, and is revered by Taylor.\nrelation<|#|>Alex<|#|>Taylor<|#|>power dynamics, observation<|#|>Alex observes Taylor's authoritarian behavior and notes changes in Taylor's attitude toward the device.\nrelation<|#|>Alex<|#|>Jordan<|#|>shared goals, rebellion<|#|>Alex and Jordan share a commitment to discovery, which contrasts with Cruz's vision.)\nrelation<|#|>Taylor<|#|>Jordan<|#|>conflict resolution, mutual respect<|#|>Taylor and Jordan interact directly regarding the device, leading to a moment of mutual respect and an uneasy truce.\nrelation<|#|>Jordan<|#|>Cruz<|#|>ideological conflict, rebellion<|#|>Jordan's commitment to discovery is in rebellion against Cruz's vision of control and order.\nrelation<|#|>Taylor<|#|>The Device<|#|>reverence, technological significance<|#|>Taylor shows reverence towards the device, indicating its importance and potential impact.\n<|COMPLETE|>\n\n\n<Input Text>\n```\nStock markets faced a sharp downturn today as tech giants saw significant declines, with the global tech index dropping by 3.4% in midday trading. Analysts attribute the selloff to investor concerns over rising interest rates and regulatory uncertainty.\n\nAmong the hardest hit, nexon technologies saw its stock plummet by 7.8% after reporting lower-than-expected quarterly earnings. In contrast, Omega Energy posted a modest 2.1% gain, driven by rising oil prices.\n\nMeanwhile, commodity markets reflected a mixed sentiment. Gold futures rose by 1.5%, reaching $2,080 per ounce, as investors sought safe-haven assets. Crude oil prices continued their rally, climbing to $87.60 per barrel, supported by supply constraints and strong demand.\n\nFinancial experts are closely watching the Federal Reserve's next move, as speculation grows over potential rate hikes. The upcoming policy announcement is expected to influence investor confidence and overall market stability.\n```\n\n<Output>\nentity<|#|>Global Tech Index<|#|>category<|#|>The Global Tech Index tracks the performance of major technology stocks and experienced a 3.4% decline today.\nentity<|#|>Nexon Technologies<|#|>organization<|#|>Nexon Technologies is a tech company that saw its stock decline by 7.8% after disappointing earnings.\nentity<|#|>Omega Energy<|#|>organization<|#|>Omega Energy is an energy company that gained 2.1% in stock value due to rising oil prices.\nentity<|#|>Gold Futures<|#|>product<|#|>Gold futures rose by 1.5%, indicating increased investor interest in safe-haven assets.\nentity<|#|>Crude Oil<|#|>product<|#|>Crude oil prices rose to $87.60 per barrel due to supply constraints and strong demand.\nentity<|#|>Market Selloff<|#|>category<|#|>Market selloff refers to the significant decline in stock values due to investor concerns over interest rates and regulations.\nentity<|#|>Federal Reserve Policy Announcement<|#|>category<|#|>The Federal Reserve's upcoming policy announcement is expected to impact investor confidence and market stability.\nentity<|#|>3.4% Decline<|#|>category<|#|>The Global Tech Index experienced a 3.4% decline in midday trading.\nrelation<|#|>Global Tech Index<|#|>Market Selloff<|#|>market performance, investor sentiment<|#|>The decline in the Global Tech Index is part of the broader market selloff driven by investor concerns.\nrelation<|#|>Nexon Technologies<|#|>Global Tech Index<|#|>company impact, index movement<|#|>Nexon Technologies' stock decline contributed to the overall drop in the Global Tech Index.\nrelation<|#|>Gold Futures<|#|>Market Selloff<|#|>market reaction, safe-haven investment<|#|>Gold prices rose as investors sought safe-haven assets during the market selloff.\nrelation<|#|>Federal Reserve Policy Announcement<|#|>Market Selloff<|#|>interest rate impact, financial regulation<|#|>Speculation over Federal Reserve policy changes contributed to market volatility and investor selloff.\n<|COMPLETE|>\n\n\n<Input Text>\n```\nAt the World Athletics Championship in Tokyo, Noah Carter broke the 100m sprint record using cutting-edge carbon-fiber spikes.\n```\n\n<Output>\nentity<|#|>World Athletics Championship<|#|>event<|#|>The World Athletics Championship is a global sports competition featuring top athletes in track and field.\nentity<|#|>Tokyo<|#|>location<|#|>Tokyo is the host city of the World Athletics Championship.\nentity<|#|>Noah Carter<|#|>person<|#|>Noah Carter is a sprinter who set a new record in the 100m sprint at the World Athletics Championship.\nentity<|#|>100m Sprint Record<|#|>category<|#|>The 100m sprint record is a benchmark in athletics, recently broken by Noah Carter.\nentity<|#|>Carbon-Fiber Spikes<|#|>equipment<|#|>Carbon-fiber spikes are advanced sprinting shoes that provide enhanced speed and traction.\nentity<|#|>World Athletics Federation<|#|>organization<|#|>The World Athletics Federation is the governing body overseeing the World Athletics Championship and record validations.\nrelation<|#|>World Athletics Championship<|#|>Tokyo<|#|>event location, international competition<|#|>The World Athletics Championship is being hosted in Tokyo.\nrelation<|#|>Noah Carter<|#|>100m Sprint Record<|#|>athlete achievement, record-breaking<|#|>Noah Carter set a new 100m sprint record at the championship.\nrelation<|#|>Noah Carter<|#|>Carbon-Fiber Spikes<|#|>athletic equipment, performance boost<|#|>Noah Carter used carbon-fiber spikes to enhance performance during the race.\nrelation<|#|>Noah Carter<|#|>World Athletics Championship<|#|>athlete participation, competition<|#|>Noah Carter is competing at the World Athletics Championship.\n<|COMPLETE|>\n\n\n\n---Real Data to be Processed---\n<Input>\nEntity_types: [Person,Creature,Organization,Location,Event,Concept,Method,Content,Data,Artifact,NaturalObject]\nText:\n```\n
处理的文本内容:
\n```\n第一章 养生必先养五脏\n\n 养心\n\n 淡竹叶\n\n《本草纲目》记载淡竹叶:“去烦热,利小便,清心。”\n\n【药材档案】\n别名:竹叶门冬青、迷身草、山鸡米、长竹叶、山冬、地竹、林下竹等。\n来源:禾本科植物淡竹叶的干燥茎叶。\n性味归经:甘、淡,寒。归心、胃、小肠经。\n【传统功用】\n1.清心泻火:用于心火口疮,心烦口渴。\n2.利尿通淋:用于热淋涩痛,浮肿黄疸。\n【药理作用】\n解热;利尿;抑菌;升高血糖等。\n【应用指南】\n\n治疗尿血\n\n淡竹叶、白茅根各15克,水煎服,每日一剂。\n\n治疗心火旺盛之暑热\n\n淡竹叶、木通各12克,生地18克,甘草梢6克,水煎服。\n\n\n\n 莲子\n\n《本草纲目》记载莲子:“交心肾,厚肠胃,固精气,强筋骨,补虚损,利耳目,除寒湿,止脾泄久痢,赤白浊,女人带下崩中诸血病。”\n\n【药材档案】\n别名:藕实、水芝丹、莲蓬子、莲实。\n来源:睡莲科植物莲的干燥成熟种子。\n性味归经:甘、涩,平。归脾、肾、心经。\n【传统功用】\n1.补脾,止泻:用于脾虚久泻、带下清稀等。\n2.养心安神:用于气阴不足、心失所养、失眠多梦等。\n【药理作用】\n收敛;镇静;延缓衰老等。\n【应用指南】\n\n治疗萎缩性胃炎\n莲子、糯米各50克,红糖1匙。莲子用开水泡胀,削皮去心,倒入锅内,加水,小火先煮半小时备用。再将糯米洗净倒入锅内,加水,大火10分钟后倒入莲肉及汤,加糖,改用小火炖半小时即可。\n\n\n\n 柏子仁\n\n《本草纲目》记载柏子仁:“养心气,润肾燥,安魂定魄,益智宁神;烧沥,泽头发,治疥癣。”\n\n【药材档案】\n别名:柏实、柏子、柏仁、侧柏子。\n来源:柏科植物侧柏的干燥成熟种仁。\n性味归经:甘,平。归心、肾、大肠经。\n【传统功用】\n养心安神:用于心阴不足、心血亏虚、心神失养之失眠多梦、惊悸怔忡以及体虚多汗等。常配伍补气养血药。\n【药理作用】\n催眠。\n【应用指南】\n\n治疗面色萎黄\n\n柏子仁15克,粳米100克,蜂蜜25克,水600~800毫升。将柏子仁去尽皮壳,捣烂,粳米淘净,一起放入锅中,加水大火煮沸,再用小火熬至汤浓米烂即成。每日1~2次,趁温热时服食。粥中以柏子仁少佐蜂蜜,润肤泽面效果更好。\n\n\n\n 合欢皮\n\n《本草纲目》记载合欢皮:“和血,消肿,止痛。”\n\n【药材档案】\n别名:夜合皮、合欢木皮。\n来源:豆科植物合欢的干燥树皮。\n性味归经:甘,平。归心、肝、肺经。\n【传统功用】\n1.解郁安神:用于忧郁气恼、烦闷不安等。\n2.活血消肿:用于痈疽疮肿、外伤瘀肿等。\n【药理作用】\n镇静,催眠;抗生育;抗过敏;抗肿瘤。\n【应用指南】\n\n治疗咳嗽兼有微热、肺痈\n\n合欢皮手掌大1片,细切,以水3升,煮取1升,分3次服。\n\n治疗骨折\n合欢皮(去粗皮,取白皮,锉碎,炒令黄微黑色)120克,芥菜子(炒)30克。上药共为细末,酒调,临夜服;粗渣敷于患处。\n```
大模型对提示词的反馈
好的,我现在需要处理用户提供的输入文本,并从中提取实体和关系。首先,我要仔细阅读用户提供的指令和示例,确保理解所有的要求和格式规范。用户的目标是构建知识图谱,因此需要准确识别实体及其之间的关系,并按照指定的格式输出。
首先,我需要分析输入文本的内容。用户提供的文本是关于中医养生的章节,主要介绍了四种药材:淡竹叶、莲子、柏子仁和合欢皮。每种药材都有其来源、性味归经、传统功用、药理作用以及应用指南。此外,章节标题为“第一章 养生必先养五脏”,其中提到养心,这可能是一个关键概念。
接下来,按照指令中的步骤进行实体提取。根据用户提供的实体类型列表,我需要识别出符合这些类型的实体。可能的实体包括药材名称(如淡竹叶、莲子等)、书籍名称(如《本草纲目》)、病症名称(如心火口疮、尿血)、治疗方法(如水煎服、治疗萎缩性胃炎的方子)以及概念(如养心、清心泻火等)。
在提取实体时,需要注意保持实体名称的原始形式,尤其是专有名词,比如药材名称和书籍名称。例如,“淡竹叶”应该作为实体名称,而《本草纲目》则需要保持原样。同时,要确保实体类型正确,比如药材档案中的来源可能归类为Artifact或Concept,但根据示例中的类似情况,可能更适合归类为Concept或Artifact。
然后,处理关系提取。需要识别实体之间的直接关系,例如药材与其传统功用之间的关系,或者药材与治疗方法之间的应用关系。例如,淡竹叶用于治疗尿血,因此存在“治疗”或“用于”的关系。同时,注意分解N元关系为二元关系,例如一个药材可能有多个传统功用,每个功用都需要单独列出与药材的关系。
需要特别注意避免重复的关系,并确保所有关系都是直接且明确的。例如,淡竹叶的“清心泻火”和“利尿通淋”是两个不同的传统功用,应分别作为不同的关系存在。
在输出格式方面,必须严格按照用户提供的格式,使用正确的字段分隔符<|#|>,并且关系中的关键词需要用逗号分隔,不能使用分隔符。同时,所有内容必须使用简体中文,专有名词保留原样,如“淡竹叶”不翻译。
需要验证每个实体的类型是否正确,例如“莲子”属于药材,类型应为Artifact或Concept,但根据示例中的类似情况,可能更适合归类为Artifact。而“养心”作为章节中的概念,类型应为Concept。
最后,确保所有关系描述清晰,并且按照重要性排序。例如,治疗具体病症的关系可能比药理作用更重要,因此应优先列出。同时,检查是否有遗漏的实体或关系,确保所有信息都被正确提取。
在完成实体和关系的提取后,需要以<|COMPLETE|>作为结尾,确保没有额外的文本或说明。整个过程需要仔细检查,确保符合用户的所有格式和内容要求,避免任何格式错误或内容遗漏。
输出提取的实体、实体关系
entity<|#|>第一章 养生必先养五脏<|#|>Concept<|#|>第一章 养生必先养五脏是文本的主题章节,强调五脏养护对养生的重要性。
entity<|#|>养心<|#|>Concept<|#|>养心是养生的重要组成部分,通过特定药材实现心的调养。
entity<|#|>淡竹叶<|#|>Artifact<|#|>淡竹叶是一种药材,具有清心泻火、利尿通淋等功效。
entity<|#|>《本草纲目》<|#|>Content<|#|>《本草纲目》是记载淡竹叶药用价值的典籍,描述其去烦热、利小便、清心的作用。
entity<|#|>心火口疮<|#|>Concept<|#|>心火口疮是淡竹叶传统用于治疗的病症,表现为心烦口渴。
entity<|#|>热淋涩痛<|#|>Concept<|#|>热淋涩痛是淡竹叶用于治疗的病症,伴随浮肿黄疸症状。
entity<|#|>莲子<|#|>Artifact<|#|>莲子是一种药材,主要用于补脾止泻、养心安神。
entity<|#|>脾虚久泻<|#|>Concept<|#|>脾虚久泻是莲子传统用于治疗的病症,常伴随带下清稀。
entity<|#|>失眠多梦<|#|>Concept<|#|>失眠多梦是莲子用于治疗的症状,归因于气阴不足。
entity<|#|>柏子仁<|#|>Artifact<|#|>柏子仁是一种药材,具有养心安神、润肾燥的功效。
entity<|#|>心阴不足<|#|>Concept<|#|>心阴不足是柏子仁用于治疗的病症,表现为失眠多梦、体虚多汗。
entity<|#|>合欢皮<|#|>Artifact<|#|>合欢皮是一种药材,用于解郁安神、活血消肿。
entity<|#|>忧郁气恼<|#|>Concept<|#|>忧郁气恼是合欢皮治疗的病症,表现为烦闷不安。
entity<|#|>骨折<|#|>Concept<|#|>骨折是合欢皮传统用于治疗的病症,通过外敷和内服相结合。relation<|#|>第一章 养生必先养五脏<|#|>养心<|#|>养生主题, 五脏关联<|#|>养心是五脏养生的重要组成部分。
relation<|#|>淡竹叶<|#|>心火口疮<|#|>药材应用, 清心泻火<|#|>淡竹叶用于治疗心火口疮。
relation<|#|>淡竹叶<|#|>热淋涩痛<|#|>药材应用, 利尿通淋<|#|>淡竹叶用于治疗热淋涩痛。
relation<|#|>莲子<|#|>脾虚久泻<|#|>药材应用, 补脾止泻<|#|>莲子用于治疗脾虚久泻。
relation<|#|>莲子<|#|>失眠多梦<|#|>药材应用, 养心安神<|#|>莲子用于治疗失眠多梦。
relation<|#|>柏子仁<|#|>心阴不足<|#|>药材应用, 养心安神<|#|>柏子仁用于治疗心阴不足。
relation<|#|>合欢皮<|#|>忧郁气恼<|#|>药材应用, 解郁安神<|#|>合欢皮用于治疗忧郁气恼。
relation<|#|>合欢皮<|#|>骨折<|#|>药材应用, 创伤治疗<|#|>合欢皮用于治疗骨折。
<|COMPLETE|>
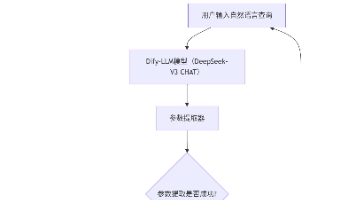
生成的知识图谱可视化: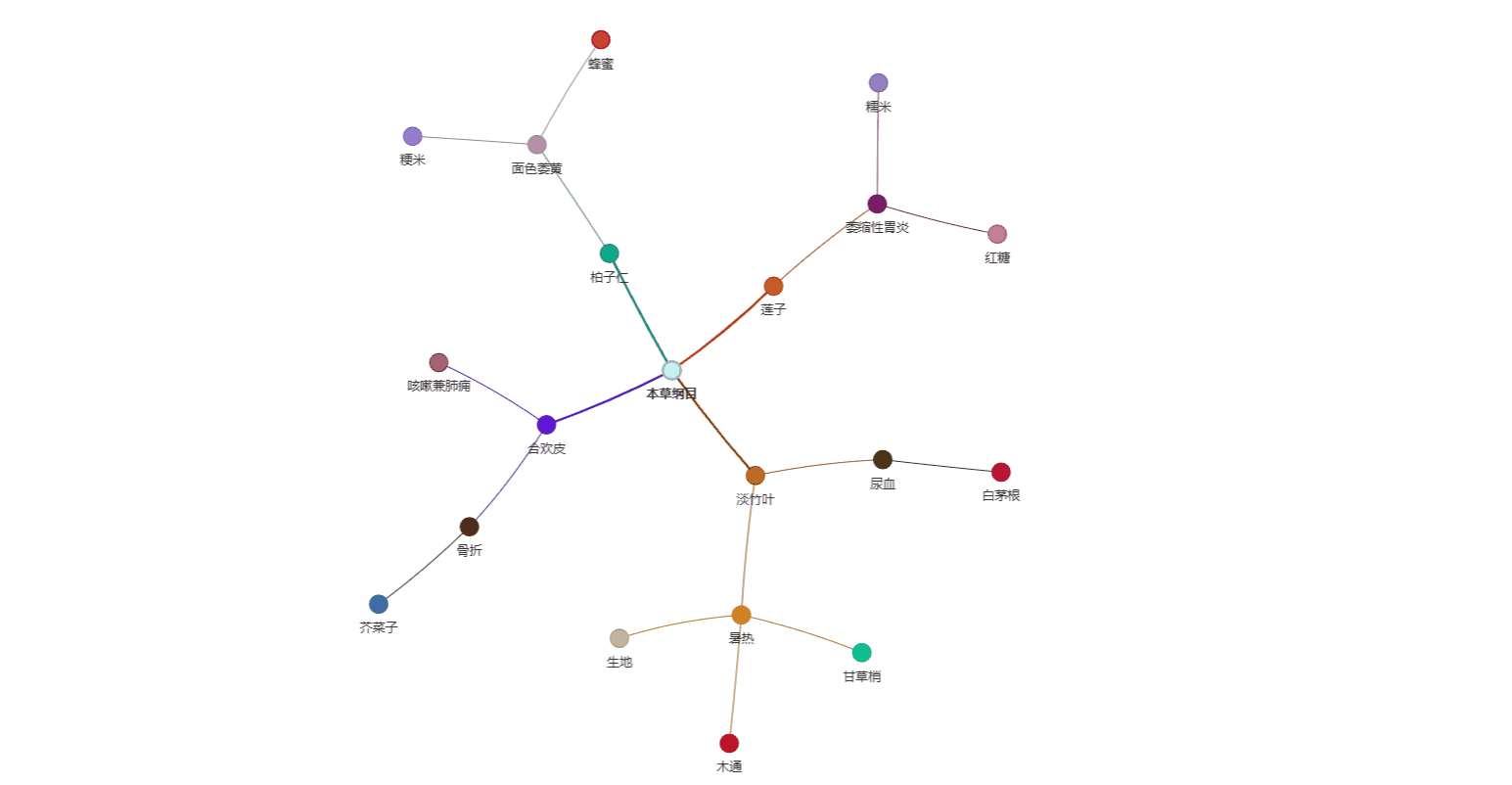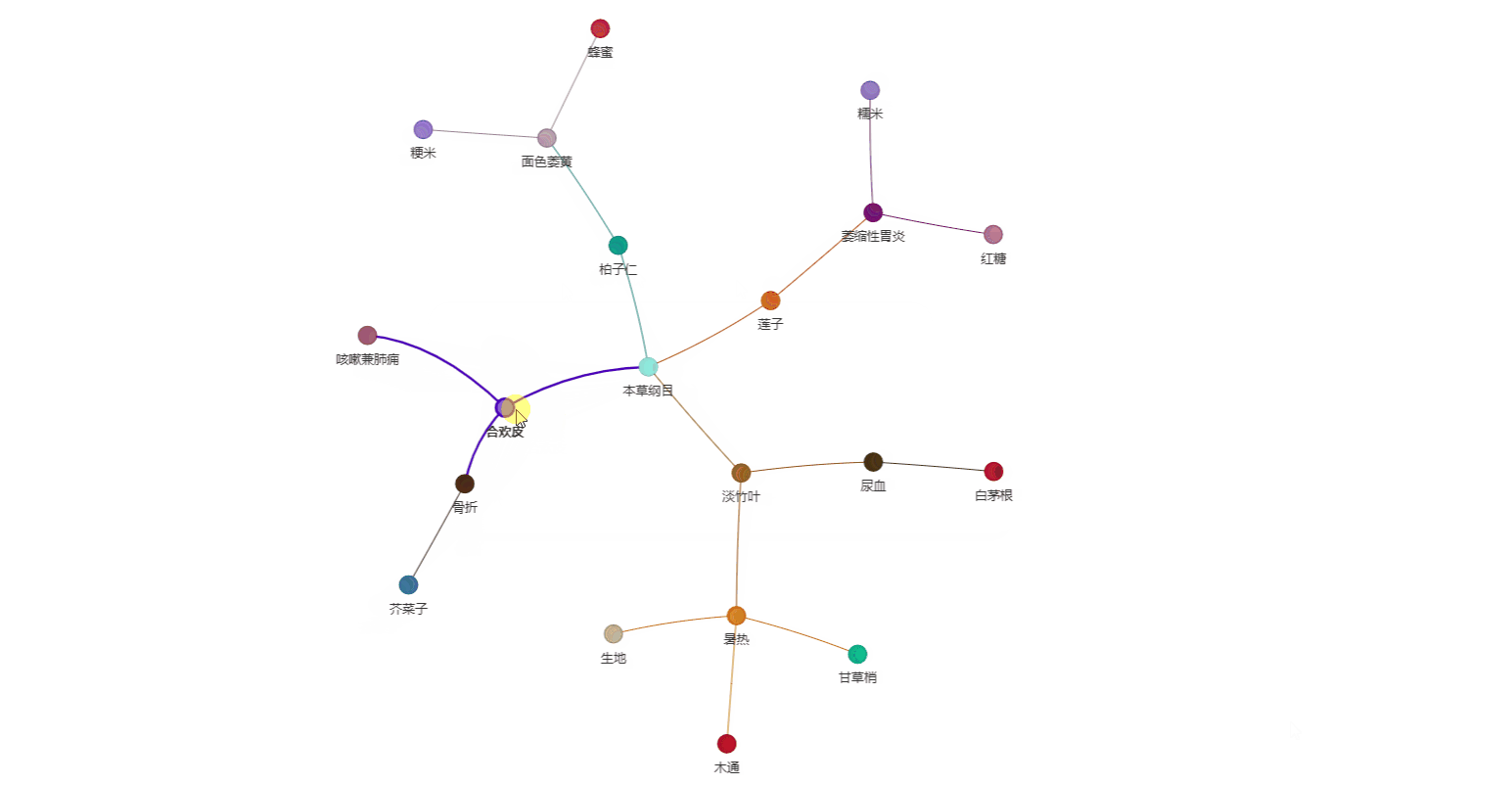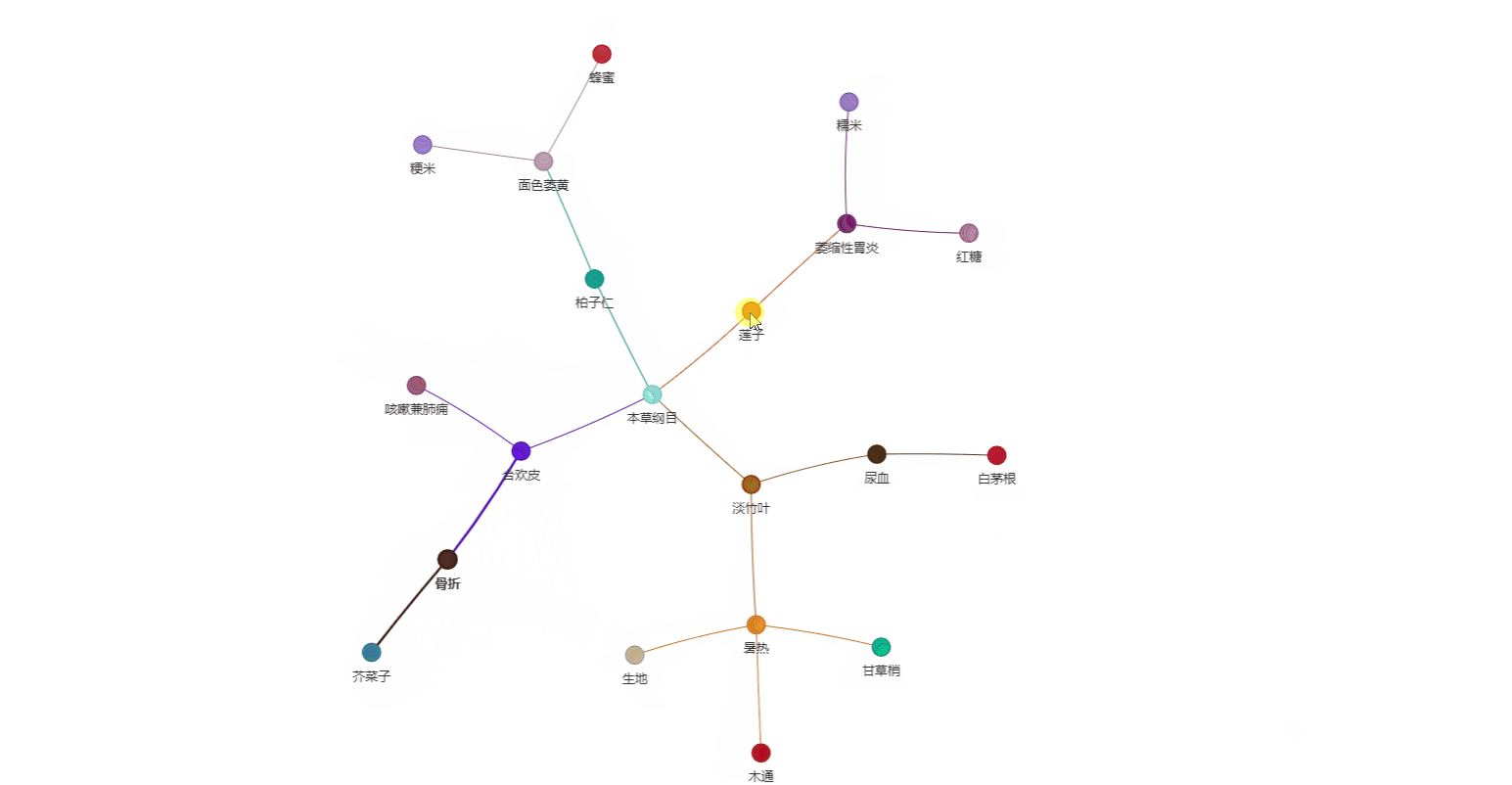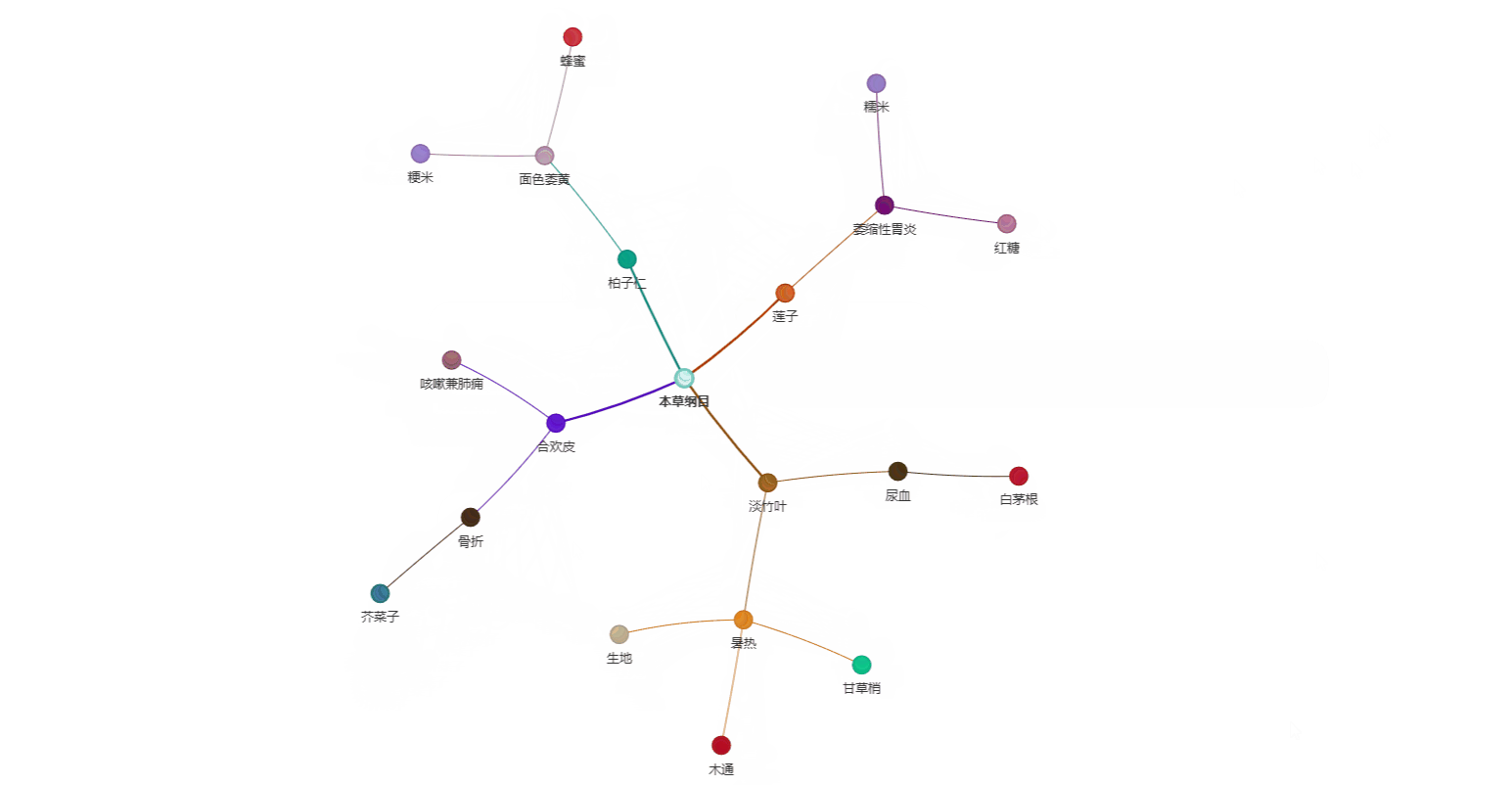
输出的回答
=====================
Query mode: naive
=====================
INFO: Naive query: 1 chunks (chunk_top_k: 10)
WARNING: Rerank is enabled but no rerank model is configured. Please set up a rerank model or set enable_rerank=False in query parameters.
INFO: Final context: 1 chunks
根据《本草纲目》及传统中医理论,以下是推荐的养心草药及其关键功效:
### 1. **淡竹叶**
- **功效**:清心泻火、利尿通淋
- **应用**:
- 治疗心火旺盛(配木通、生地)
- 缓解暑热心烦、口疮
- **特点**:性寒,归心经,适合热证烦躁(《本草纲目》载其“去烦热,清心”)。
### 2. **莲子**
- **功效**:补脾止泻、养心安神
- **应用**:
- 改善失眠多梦、心肾不交
- 辅助治疗脾虚久泻(如莲子糯米粥)
- **特点**:甘平,归心脾肾经,兼具滋补与安神作用。
### 3. **柏子仁**
- **功效**:养心安神、润燥
- **应用**:
- 调理心血亏虚之失眠、惊悸
- 改善面色萎黄(柏子仁粥佐蜂蜜)
- **特点**:甘平质润,尤宜阴血不足所致心神不宁。
### 4. **合欢皮**
- **功效**:解郁安神、活血消肿
- **应用**:
- 缓解忧郁烦闷、情绪不畅
- 辅助治疗肺痈、骨折外伤
- **特点**:归心肝经,长于疏肝解郁以宁心。
### 注意事项
- **辨证使用**:淡竹叶偏清热,莲子/柏子仁偏补益,合欢皮重情绪调节。
- **配伍建议**:如心火盛配淡竹叶+生地,虚烦失眠用莲子+柏子仁。
**References**
[DC] unknown_source
=====================
Query mode: local
=====================
INFO: == LLM cache == saving: local:keywords:c3d395b4a684806ef2b52f8df30f2635
INFO: Process 33296 building query context...
INFO: Query nodes: 人参, 丹参, 五味子, 黄芪, 当归, top_k: 40, cosine: 0.2
INFO: Local query: 14 entites, 13 relations
INFO: Truncated KG query results: 14 entities, 13 relations
INFO: KG related chunks: 1 from entitys, 1 from relations
WARNING: Rerank is enabled but no rerank model is configured. Please set up a rerank model or set enable_rerank=False in query parameters.
INFO: Final context: 14 entities, 13 relations, 1 chunks
根据提供的知识库,以下是几种推荐用于养心的草药及其主要功效:
### 1. 淡竹叶
- **功效**:清心泻火、利尿通淋
- **应用**:用于心火口疮、心烦口渴等症状。可配伍白茅根治疗尿血,或与木通、生地、甘草梢配伍治疗心火旺盛之暑热。
- **来源**:《本草纲目》记载其“去烦热,利小便,清心”。
### 2. 莲子
- **功效**:补脾止泻、养心安神
- **应用**:用于脾虚久泻、失眠多梦等症状。可配伍糯米和红糖治疗萎缩性胃炎。
- **来源**:《本草纲目》记载其“交心肾,厚肠胃,固精气”。
### 3. 柏子仁
- **功效**:养心安神
- **应用**:用于心阴不足、失眠多梦、惊悸怔忡等症状。可配伍粳米和蜂蜜治疗面色萎黄。
- **来源**:《本草纲目》记载其“养心气,润肾燥,安魂定魄”。
### 4. 合欢皮
- **功效**:解郁安神、活血消肿
- **应用**:用于忧郁气恼、烦闷不安等症状。可配伍芥菜子治疗骨折。
- **来源**:《本草纲目》记载其“和血,消肿,止痛”。
### References
1. [KG] unknown_source
2. [DC] unknown_source
=====================
Query mode: global
=====================
INFO: == LLM cache == saving: global:keywords:a3e0c74adc78b55edf8873194bcf38a2
INFO: Process 33296 building query context...
INFO: Query edges: 养心, 草药推荐, 中医养生, top_k: 40, cosine: 0.2
INFO: Global query: 14 entites, 13 relations
INFO: Truncated KG query results: 14 entities, 13 relations
INFO: KG related chunks: 1 from entitys, 1 from relations
WARNING: Rerank is enabled but no rerank model is configured. Please set up a rerank model or set enable_rerank=False in query parameters.
INFO: Final context: 14 entities, 13 relations, 1 chunks
根据提供的知识库,以下是几种推荐用于养心的中药材及其主要功效:
### 1. 淡竹叶
- **功效**:清心泻火、利尿通淋
- **应用**:治疗心火口疮、心烦口渴、热淋涩痛
- **配伍**:常与甘草梢、木通、生地配伍治疗心火旺盛之暑热;与白茅根配伍治疗尿血
### 2. 莲子
- **功效**:补脾止泻、养心安神
- **应用**:治疗脾虚久泻、失眠多梦
- **配伍**:与糯米、红糖配伍治疗萎缩性胃炎
### 3. 柏子仁
- **功效**:养心安神
- **应用**:治疗心阴不足、失眠多梦、惊悸怔忡
- **配伍**:与粳米、蜂蜜配伍治疗面色萎黄
### 4. 合欢皮
- **功效**:解郁安神、活血消肿
- **应用**:治疗忧郁气恼、烦闷不安
- **配伍**:与芥菜子配伍治疗骨折
这些草药均被记载于《本草纲目》中,具有明确的养心功效和临床应用指南。
#### References
1. [KG] unknown_source
2. [DC] unknown_source
=====================
Query mode: hybrid
=====================
INFO: == LLM cache == saving: hybrid:keywords:7789f168338a7880a0716713b8b720f6
INFO: Process 33296 building query context...
INFO: Query nodes: 人参, 丹参, 五味子, 黄芪, 当归, top_k: 40, cosine: 0.2
INFO: Local query: 14 entites, 13 relations
INFO: Query edges: 养心, 草药推荐, 中医养生, top_k: 40, cosine: 0.2
INFO: Global query: 14 entites, 13 relations
INFO: Truncated KG query results: 14 entities, 13 relations
INFO: KG related chunks: 1 from entitys, 1 from relations
WARNING: Rerank is enabled but no rerank model is configured. Please set up a rerank model or set enable_rerank=False in query parameters.
INFO: Final context: 14 entities, 13 relations, 1 chunks
根据提供的知识库,以下是几种推荐用于养心的草药及其主要功效:
### 1. 淡竹叶
- **功效**:清心泻火、利尿通淋
- **应用**:治疗心火口疮、心烦口渴、热淋涩痛
- **配伍**:可与木通、生地、甘草梢配伍治疗心火旺盛之暑热;与白茅根配伍治疗尿血
- **典籍记载**:《本草纲目》记载其“去烦热,利小便,清心”
### 2. 莲子
- **功效**:补脾止泻、养心安神
- **应用**:治疗脾虚久泻、失眠多梦
- **配伍**:与糯米、红糖配伍治疗萎缩性胃炎
- **典籍记载**:《本草纲目》记载其“交心肾,厚肠胃,固精气”
### 3. 柏子仁
- **功效**:养心安神
- **应用**:治疗心阴不足、失眠多梦、惊悸怔忡
- **配伍**:与粳米、蜂蜜配伍治疗面色萎黄
- **典籍记载**:《本草纲目》记载其“养心气,润肾燥,安魂定魄”
### 4. 合欢皮
- **功效**:解郁安神、活血消肿
- **应用**:治疗忧郁气恼、烦闷不安
- **配伍**:与芥菜子配伍治疗骨折
- **典籍记载**:《本草纲目》记载其“和血,消肿,止痛”
### References
1. [KG] unknown_source
2. [DC] unknown_sourceINFO: Successfully finalized 10 storages
Done!
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)