阿里云渠道商:如何选择高性价比阿里云GPU配置?
阿里云GPU实例提供从入门级到高性能的完整产品矩阵,可帮助企业优化30%-50%的AI计算成本。其三大核心优势包括:1)精准匹配业务需求的实例规格选择;2)灵活计费模式(抢占式实例成本低至20%);3)弹性伸缩能力节省30%闲置成本。典型配置方案覆盖中小企业开发、互联网推理服务和科研训练等场景,建议通过性能测试确定基准配置,并定期优化资源。科学的GPU选型可显著提升资源利用率,避免过度配置或性能不
一、引言
在AI项目落地过程中,GPU资源配置不当是导致成本失控和项目延期的主要原因。据统计,超过40%的AI项目在GPU资源上存在过度配置或配置不足的问题,导致资源浪费或性能瓶颈。阿里云提供从入门级到超高性能的完整GPU产品矩阵,通过科学的选型方法,企业可在保证业务性能的同时,将GPU计算成本优化30%-50%。本文将从业务场景出发,系统化解析高性价比GPU配置的选择策略。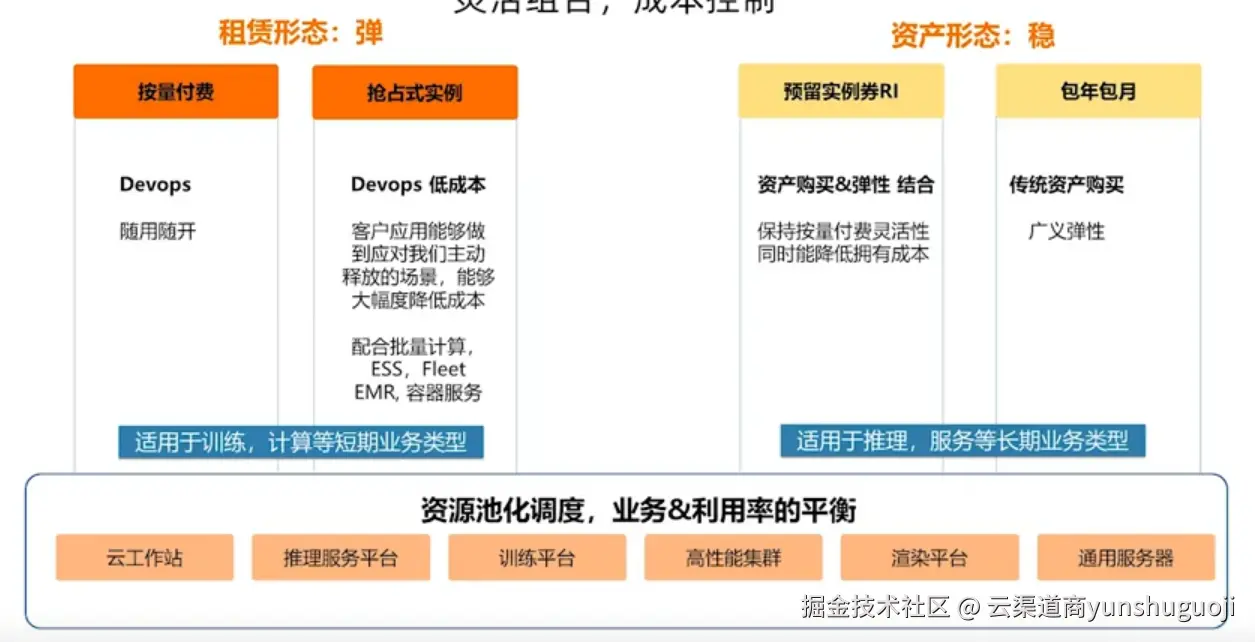
二、阿里云GPU实例概述
阿里云GPU实例基于异构计算架构,提供全面的GPU加速能力,主要分为三大系列:实例类型矩阵:
|
实例系列 |
代表型号 |
GPU配置 |
核心优势 |
性价比指数 |
|
虚拟化型 |
vgn6i/vgn7i |
T4/A10 |
轻量级推理、图形工作站 |
五颗星 |
|
独享型 |
gn7i/gn7 |
A10/A100 |
深度学习训练、HPC |
四颗星 |
|
高性能计算型 |
scc/gn |
V100/A100 |
大规模分布式训练 |
三颗星 |
关键技术创新:
弹性GPU:支持GPU资源的按需分配和灵活调整
CPFS并行文件系统:为大规模训练提供高吞吐数据访问
RoCE网络:实现低延迟的GPU间通信
三、高性价比配置的核心优势
1. 精准的性能价格匹配
通过实例规格族的精细划分,用户可根据工作负载特征选择最合适的配置,避免"大马拉小车"或性能瓶颈。例如,对于推理场景,选择T4实例可比A100实例成本降低70%,同时满足业务需求。
2. 灵活的计费模式
阿里云提供按量付费、包年包月、抢占式实例等多种计费方式,用户可根据业务稳定性需求灵活选择。抢占式实例价格最低可达按量付费的20%,适合容错性高的批处理任务。
3. 弹性伸缩能力
基于弹性伸缩服务(ESS),GPU资源可根据负载动态调整,实现真正的按需使用。在流量波谷时段自动释放资源,可节省30% 以上的闲置成本。
四、高性价比配置选择流程
1. 业务需求分析
工作负载特征进行评估
性能指标量化:
计算密度:FP16/FP32/TF32计算需求
显存需求:模型参数+激活函数所需的显存大小
通信需求:多卡或多机通信带宽要求
IO性能:训练数据读取的吞吐量需求
2. 实例规格选择策略
训练场景选型指南:
小规模训练(预算敏感型):
推荐配置:gn6i(T4显卡)或gn7i(A10显卡)
适用场景:BERT-base、ResNet-50等中等规模模型
成本优势:单实例成本控制在5-10元/小时以内
大规模训练(性能优先型):
推荐配置:gn7(A100显卡)或scc(V100显卡)
适用场景:LLaMA、GPT等大语言模型训练
性能优势:支持NVLink高速互联,多卡效率提升40%
推理场景选型指南:
高并发推理:
推荐配置:vgn7i(虚拟化A10)多实例集群
优化策略:模型量化(INT8)+动态批处理
成本效益:通过自动伸缩应对流量波动
低延迟推理:
推荐配置:gn7i(A10)独享实例
性能要求:P99延迟<100ms
部署方案:模型预热+请求队列优化
3. 存储与网络配置
存储优化策略:
高性能需求:ESSD PL3云盘,提供最高100万IOPS
大容量需求:OSS+CPFS并行文件系统,支持PB级存储
成本优化:根据数据访问频率配置存储分层
网络优化方案:
节点间通信:RoCE网络实现微秒级延迟
数据加载:内网带宽最大化配置,避免IO瓶颈
成本控制:通过内网传输避免公网流量费用
4. 成本优化技巧
计费模式根据需要选择
资源利用率提升:
监控指标:GPU利用率、显存使用率、功率消耗
优化工具:使用NVIDIA Nsight Systems进行性能分析
最佳实践:通过梯度累积增大有效batch size
五、典型应用场景配置方案
|
场景 |
推荐配置 |
|
中小企业AI模型开发 场景特征:预算有限,需要快速验证算法可行性 |
实例规格:gn6i-vws(T4显卡,4核16GB) 存储配置:500GB ESSD云盘 网络配置:内网带宽5Gbps |
|
互联网公司推理服务 场景特征:流量波动大,要求高可用和弹性伸缩 |
实例规格:vgn7i集群(A10虚拟化) 弹性策略:基于QPS的自动伸缩 负载均衡:SLB+多可用区部署 成本优化:基础资源包年+峰值资源按量 |
|
科研机构大规模训练 场景特征:计算密集型,需要极致性能 |
实例规格:gn7(8卡A100) 存储方案:CPFS并行文件系统 网络优化:100Gbps RoCE网络 任务调度:弹性高性能计算E-HPC集群 |
六、总结
先用按量实例进行性能测试,确定基准配置,然后从基础配置开始,根据监控数据逐步优化,在使用中每季度回顾资源配置,根据业务变化进行调整。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)