DevRel 通讯 — 2025 年 11 月
Elastic 9.2版本发布,带来多项创新功能:1) Agentic工作流AI支持在Kibana中创建智能agent处理Elasticsearch数据;2) Streams功能通过AI自动解析和结构化日志数据;3) DiskBBQ技术实现向量搜索的磁盘存储优化。平台亮点包括ES|QL增强、时间序列查询优化和Discover改进。团队还提供了免费在线培训资源,并分享了多篇技术博客和视频教程,涵盖上
作者:来自 Elastic DevRel team

来自 Elastic DevRel 团队的问候!在本期通讯中,我们将介绍 Elastic 9.2、免费的按需培训、最新博客和视频,以及即将举行的活动。
有什么新内容?
Elastic 9.2 刚刚发布,这是一个重要版本:
- Kibana 中的 Agentic 工作流
- AI 辅助日志 pipeline
- 新的磁盘向量索引
- Discover 中的体验优化
Elastic Agent Builder:在 Kibana 中的 Chat、工具和 agents
启动 AI agent,它们可以在你的 Elasticsearch 数据上聊天,并调用你定义的工具,如 ES|QL、内置工具如 list indices 和 get mapping。你可以创建工具,将它们组合成 agent,然后与自定义 agent 或默认 agent 对话。部分功能为技术预览,并隐藏在 flags 后。
为什么你会关心:这是一个原生、基于标准(Model Context Protocol 或 MCP)的方法,可以在不依赖临时方案的情况下构建面向任务的 agent。
POST kbn://api/agent_builder/tools
{
"id": "news_on_asset",
"type": "esql",
"description": "Find news for a ticker",
"configuration": {
"query": "FROM financial_news | WHERE MATCH(entities, ?symbol) | limit 5",
"params": { "symbol": { "type":"keyword" } }
}
}将其接入 agent 并在 Kibana 中与其聊天:
POST kbn://api/agent_builder/converse
{ "input": "What news about DIA?", "agent_id": "custom_agent" }或者,将其接入你的 MCP client,如 Claude Desktop、Cursor 和 VS Code。
{
"mcpServers": {
"elastic-agent-builder": {
"command": "npx",
"args": [
"mcp-remote",
"${KIBANA_URL}/api/agent_builder/mcp",
"--header",
"Authorization:${AUTH_HEADER}"
],
"env": {
"KIBANA_URL": "${KIBANA_URL}",
"AUTH_HEADER": "ApiKey ${API_KEY}"
}
}
}
}更多信息,请参阅文档。
Streams:自组织的 AI 辅助日志
Streams 使用 AI 解析和结构化原始日志,对其进行分区,并呈现 Significant Events,让你从最相关的信号开始调查。它可与 OpenTelemetry、Elastic Agent、Filebeat、Logstash、Fluentd 等配合使用。你也可以直接流式传输到 /logs 端点,实现无 agent 摄取。功能包括:
- 日志解析与结构化:将日志行转换为结构化、可查询的数据。Streams 使用 AI 自动发现模式、提取字段并对日志进行分区,在调查开始前减少噪声。
- Significant Events:从日志中开始调查。Significant Events 自动标记需要关注的信号,如错误、异常或证书到期,让你专注于重要内容。
- 无 agent 摄取(这里的 agent 指的是摄入数据的 Elastic agent,而不是智能体):从任何来源、OpenTelemetry、Fluentd 或通过 Elastic 一键集成摄取日志。你可以直接流式传输到 /logs 端点 —— 无需 agent。
所有功能均由 agentic AI 提供支持。在 Elastic 中,agentic 工作流组织日志、呈现重要事件并指导调查。它们与基于你的知识库和运行手册的组织上下文、快速 ES|QL 查询以及机器学习结合使用。
OTel 快速提示(processor 和 exporter 草图):
processors:
transform/logs-streams:
log_statements:
- context: resource
statements:
- set(attributes["elasticsearch.index"], "logs")
exporters:
otlp/ingest:
endpoint: ${env:ELASTIC_OTLP_ENDPOINT}
headers:
Authorization: ApiKey ${env:ELASTIC_API_KEY}
service:
pipelines:
logs:
receivers: [filelog]
processors: [batch, transform/logs-streams]
exporters: [elasticsearch, debug]DiskBBQ:向量搜索,但 RAM 更轻松
DiskBBQ 是 HNSW 在压缩向量上的 kNN 的磁盘替代方案。它将向量保存在磁盘上,在保持大数据集召回率和速度的同时,最小化 RAM 需求。可通过 index_options.type=bbq_disk 按字段启用。
{
"mappings": {
"properties": {
"image-vector": {
"type": "dense_vector",
"dims": 512,
"similarity": "l2_norm",
"index_options": { "type": "bbq_disk" }
}
}
}
}9.2 平台亮点
- ES|QL Smart Lookup Joins
- ES|QL 时间序列
- Discover 中的 Smart enrichment
- Background search(技术预览)
- Discover Tabs
ES|QL Smart Lookup Joins:在多个字段和表达式(<、>、!=)上匹配,并从查找(lookup)索引中进行 enrich,即使跨远程集群也可。
FROM logs-*, remote:logs-*
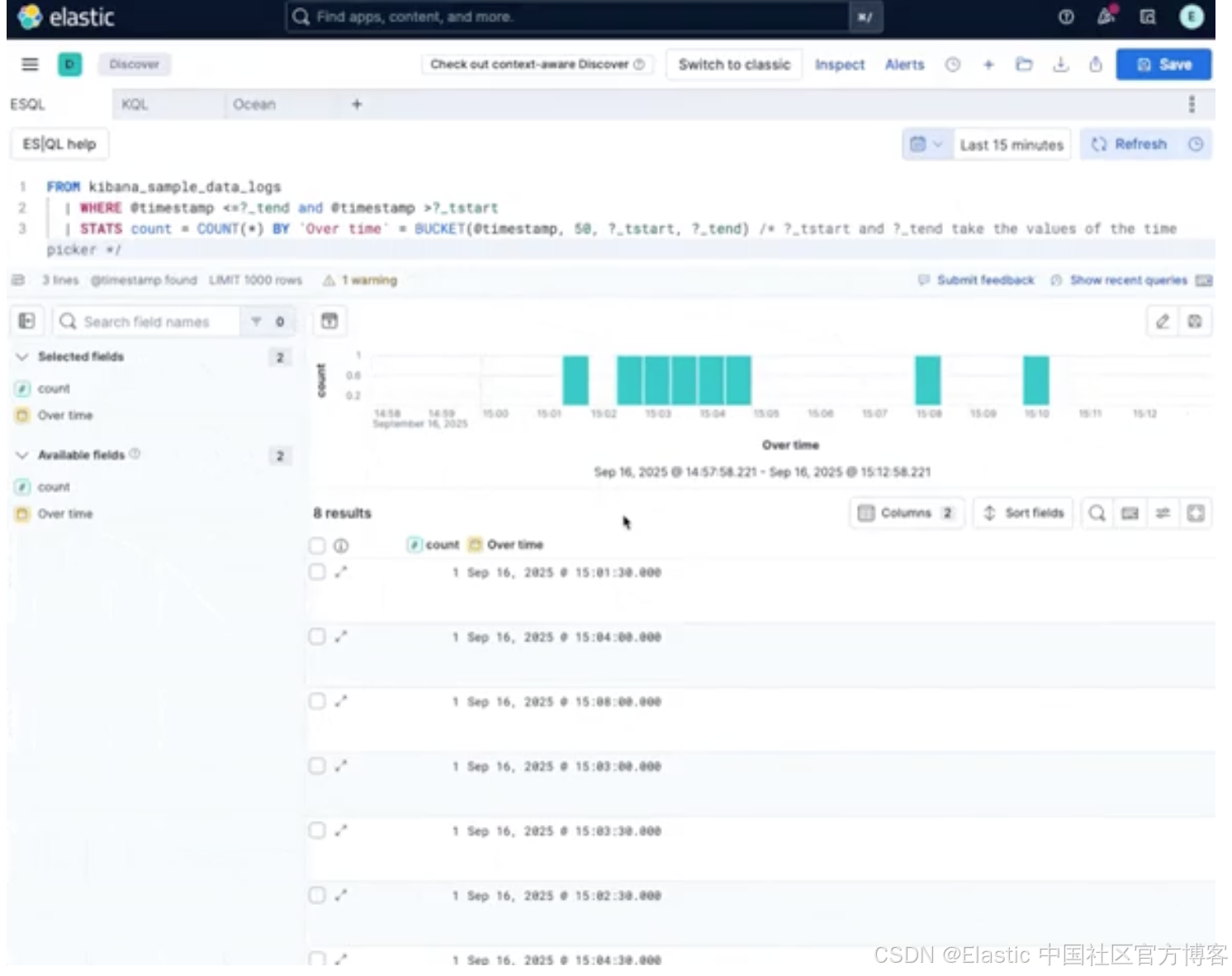
| LOOKUP JOIN lookup_index ON left_field1 > right_field1 AND left_field2 <= right_field2ES|QL 时间序列:原生 RATE、*_OVER_TIME、TBUCKET、TS 让时间序列查询更直接。
TS k8s
| STATS max_rate=MAX(RATE(network.total_bytes_in)) BY time_bucket = TBUCKET(5minute)Discover 中的 Smart enrichment:在探索时内联运行 LOOKUP JOIN。
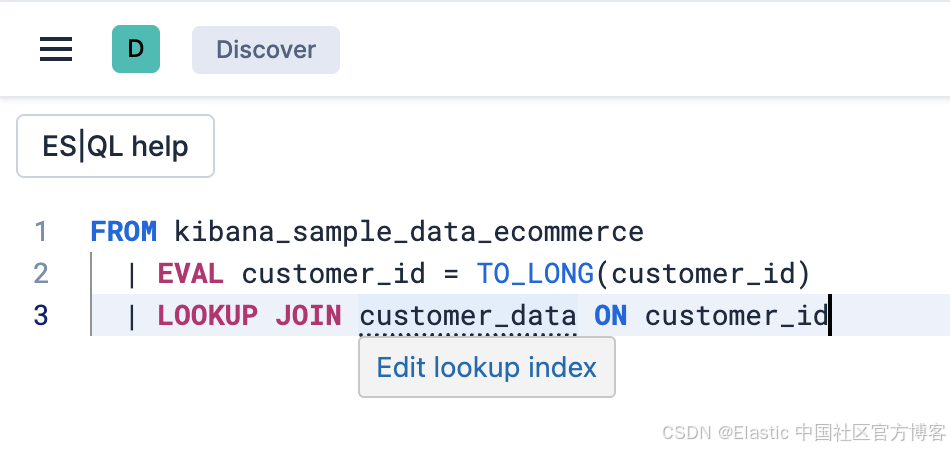
Background search(技术预览):在 Discover 中将长 ES|QL、KQL 或 DSL 查询作为异步任务启动,并在完成时收到通知。
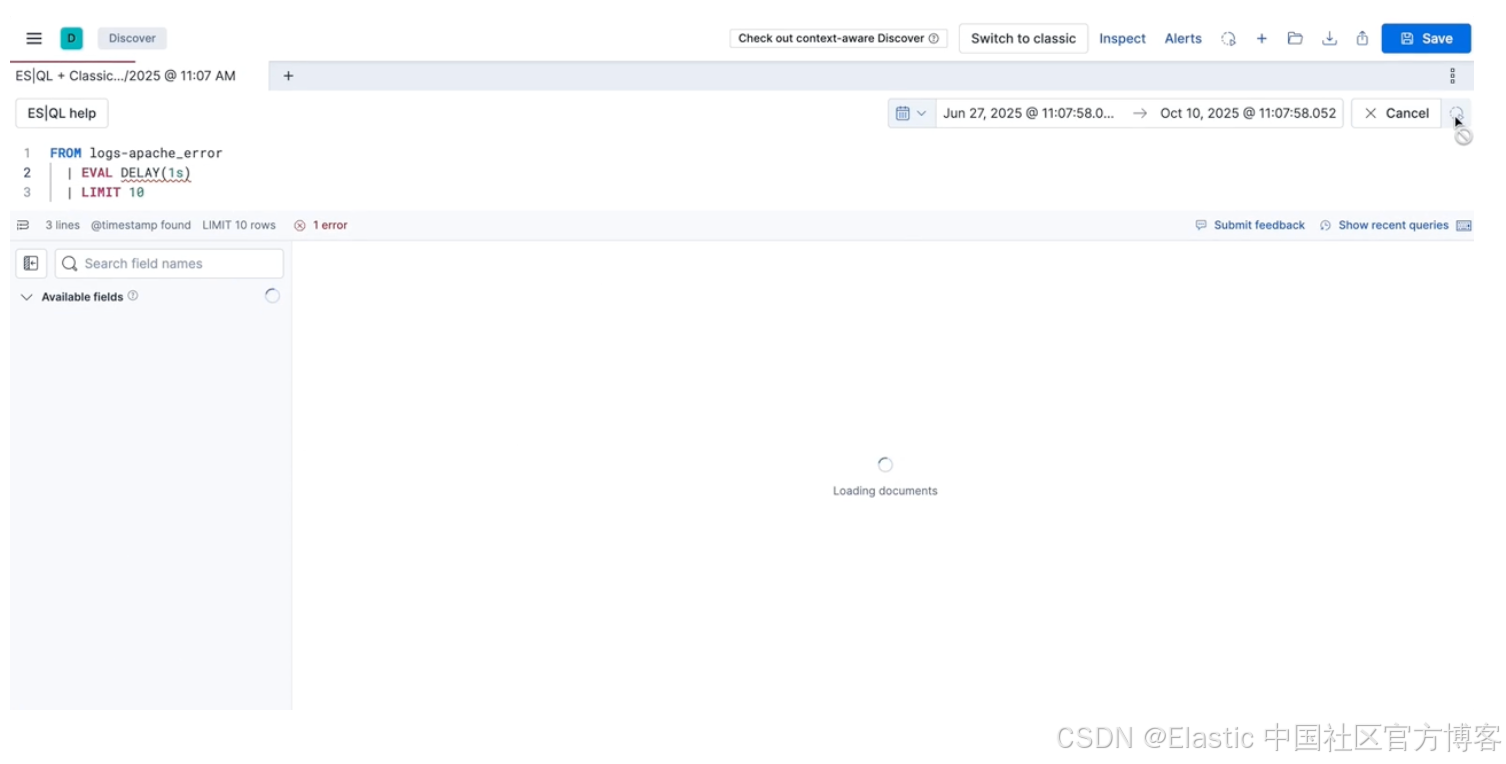
Discover Tabs:Painless 上下文切换和并排比较。
博客、视频和有趣的链接
- 按需 Elastic 培训:登录或注册后任选一个 Elastic 培训课程,然后选择课程类型 “On-Demand” 即可免费启动。
- 上下文工程:跟 Ugo Sangiorgi 学习如何在 Elasticsearch 中使用 Mistral Chat completions 来为大语言模型(LLM)回复提供上下文基础。与 Joseph McElroy 一起探索相关性在 AI agent 的上下文工程中的影响。
- Streams:Bahubali Shetti 和 Luca Wintergerst 介绍用于可观测性的 Streams。Kevin Lacabane 探索 Streams 如何简化 Elasticsearch 中的保留管理。
- Agentic AI:跟 Enrico Zimuel 和 Florian Bernd 一起学习如何使用 Microsoft Agent Framework 和 Elasticsearch 在 Python 和 .NET 中构建一个简单的 agentic 应用。
- 多语言 embeddings:了解如何部署一个 e5 多语言 embedding 模型用于向量搜索和跨语言检索,并与 Quynh Nguyen 一起提升其相关性。
- 安全:Charles Davison 利用 Automatic Migration for Dashboards 加速 SIEM 迁移。Brixton Pizzuti 使用 AI 驱动的威胁狩猎提升公共部门的网络防御。
看看这些视频:
- 由 Iulia Feroli 撰写的 Introducing Elastic Agent Builder: 为你的 agents 提供最佳上下文和工具
- 如何使用 OpenTelemetry 和 Elastic 可观测性对前端 web 应用进行检测,作者 Carly Richmond
- 如何使用 Elasticsearch Synonym API 提高搜索准确性,作者 Tomás Murúa
- Search AI with autotune:展示 agentic search O11y autotune,作者 James Williams
社区精选博客和项目:
- 使用 Elasticsearch 查询电子健康记录,作者 Joey Whelan
- Elasticsearch 中的范围查询和查询范围,作者 Tomasz Dzierżanowski
- Elasticsearch:掌握索引、分析器和混合搜索,作者 IBM Developer
我们希望在舞台上有一个良好的 Elastic Community 代表。即使你的想法还不成熟,也请提交 —— 我们很乐意与你一起迭代。
加入你本地的 Elastic User Group 分会,获取即将举行的活动的最新消息!你也可以在 Meetup.com 和 Luma 上找到我们。如果你有兴趣在 meetup 上做演讲,请发送邮件至 meetups@elastic.co。
本文中描述的任何功能或特性的发布和时间由 Elastic 全权决定。任何当前不可用的功能或特性可能无法按时交付,甚至可能无法交付。
原文:https://www.elastic.co/blog/devrel-newsletter-november-2025

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)