结合多模型内容风险检测过滤的大模型内容围栏系统
博特智能提出通过多模型风险识别对风险内容检测过滤,主要利用不同模型对风险敏感度的不同和关键词库等技术实现风险内容的分类过滤,实现对风险内容的多元化风险判断,保障生成式人工智能大模型输入和输出内容的安全性、合规性。基于“宪法式”对于与对话治理方式,能够通过设定的规则、规范让模型在对话中自行对内容进行价值判定、修正或拒绝,以实现明确的目标导向的自我约束和安全性提升。如果安全进行信息内容输出。3.2 如
- 现状及背景
近年来,以大型语言模型(Large Language Models, LLMs)为代表的人工智能技术取得了突破性进展,并在各行各业展现出巨大的应用潜力。然而,LLM在带来便利的同时,其内生的安全风险也日益凸显。
基于人类对模型输出进行评分,训练奖励模型(Reward Model, RM),再用强化学习(常用 PPO)优化原始模型策略,使生成结果更符合人类偏好与安全规范。
- Deep Reinforcement Learning from Human Preferences(Christiano P F, Leike J, Brown T, et al. Deep reinforcement learning from human preferences[J]. Advances in neural information processing systems, 2017, 30.)确立了通过人类偏好进行强化学习的基本思路,为后续工作提供有力的学术支撑。
- Training language models to follow instructions(Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in neural information processing systems, 2022, 35: 27730-27744.)将RLHF用于提升语言对遵循指令的能力,是InstructGPT等系列的工作核心方法论。
该方式能显著提升模型对指令的遵循度和安全性,但是成本高、数据质量的参差不齐和多样性对模型的结果影响较大,且仍然被对抗性提示绕过。
基于“宪法式”对于与对话治理方式,能够通过设定的规则、规范让模型在对话中自行对内容进行价值判定、修正或拒绝,以实现明确的目标导向的自我约束和安全性提升。
- Constitutional ai: Harmlessness from ai feedback(Bai Y, Kadavath S, Kundu S, et al. Constitutional ai: Harmlessness from ai feedback[J]. arXiv preprint arXiv:2212.08073, 2022.)实现在对话框架内以“宪法性原则”进行治理输出,降低风险内容的生成概率,提升对敏感信息的自我约束能力。
该方式通过宪法式对齐具有更高的可解释性与可控性,且对跨领域、跨语言的适用性更具鲁棒性,但宪法条款的设计、更新与覆盖范围依然是挑战,且需要与人类偏好数据共同作用以避免过度保守。
综上所述,现有的人工智能风险拦截存在着:
- 对齐成本高、数据依赖强:RLHF/DRLHF 需要高质量的人工标注数据与持续的人类评审,成本高且难以规模化覆盖所有场景。
- 泛化与鲁棒性不足:对抗性提示、提示注入、跨领域/跨语言场景下的鲁棒性仍不足,容易被“绕道”或“ Jailbreak”式攻击击穿围栏。
- 评估体系的挑战:当前缺乏全面、客观、可重复的评估基准,难以量化衡量围栏在不同域、不同用户群体中的有效性与副作用(如过度保守导致输出可用性下降)。
- 可解释性与透明度不足:多层治理链条实现复杂,外部很难稳定地解释输出为何被拒绝、被修正,影响用户信任与合规审计的可追溯性。
- 代价与性能折衷:引入多层筛选、RM、PPO 更新等会带来系统延迟、算力成本和部署复杂度,需在安全性与性能之间进行权衡。
- 构建与维护难度:持续更新宪法条款、风险分类、以及对新兴领域(如隐私保护、版权合规、数据来源透明度)的适配,要求高水平的工程与治理能力。
- 博特智能的解决方案
博特智能提出通过多模型风险识别对风险内容检测过滤,主要利用不同模型对风险敏感度的不同和关键词库等技术实现风险内容的分类过滤,实现对风险内容的多元化风险判断,保障生成式人工智能大模型输入和输出内容的安全性、合规性。
系统方案:
- 本系统构建多模型组合方式,形成多模型内容过滤规则,包括:
- 风险词库构建:通过对风险词库和风险提示词库构建,形成外层拦截体系,保证对内容的初次风险判别。
- 风险规则构建:通过对风险敏感模型和风险宽松模型的组合形成包括:宽松拦截模式、较宽松拦截模式、严格拦截模式、较严格拦截模式四种不同的风险规则,保障在不同拦截规则下,能够对风险内容进行有效处理。
- 本系统构建全模型网关配置方式,形成一次配置多次控制方式,包括:
- 网关配置:通过配置防护模型的访问方式和请求内容、响应内容的格式,即可无缝实现内容安全过滤。
- 服务监控配置:通过对网关的监控实时处理风险内容的识别和拦截分布,以及实现风险内容管理。
- 本系统的风险拦截实施方案如下:
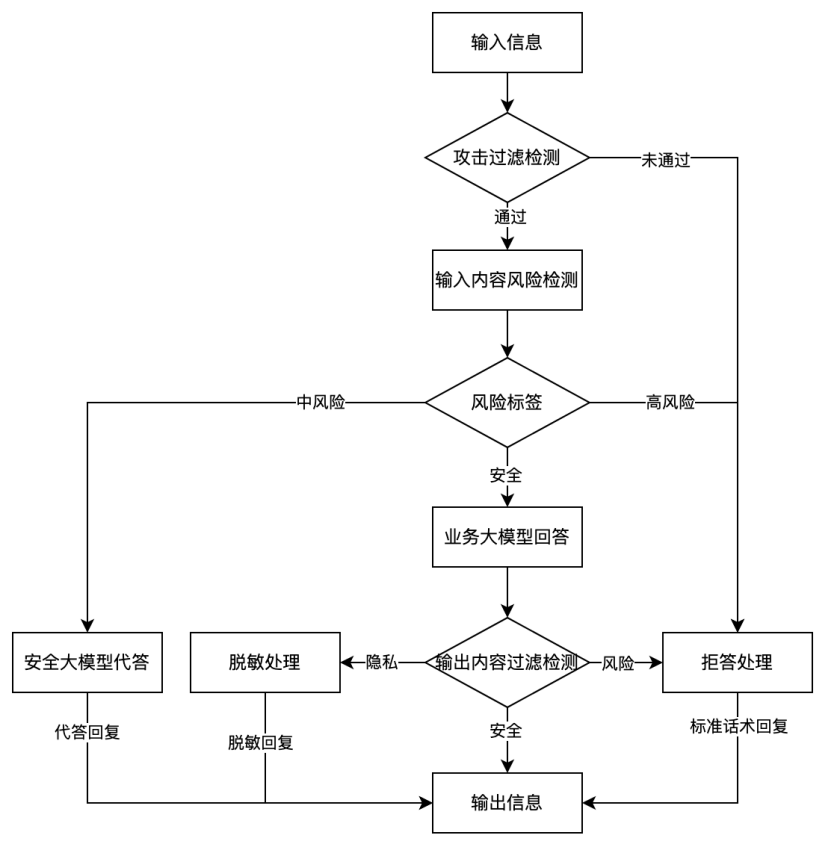
具体如下:
通过配置完成的网关接收人工智能的须过滤的内容,对内容进行处理操作。
3.1 用户输入内容,通过攻击过滤模型,检测是否存在攻击风险
3.2 如果通过,则对风险内容进行检测,返回对应的风险标签。如果不通过对业务方进行拒答处理。
3.3 风险标签中对于中风险内容,实现安全模型代答回复。对于高风险内容实现拒答处理。如果安全,则实现业务模型回答。
3.4 对业务模型回答的内容实现风险过滤,如果存在敏感信息进行脱敏处理。如果存在风险内容,进行拒答回复。如果安全进行信息内容输出。
- 本系统构建多模型组合方式,形成多模型内容过滤规则,包括:
- 风险词库构建:通过对风险词库和风险提示词库构建,形成外层拦截体系,保证对内容的初次风险判别。
- 风险规则构建:通过对风险敏感模型和风险宽松模型的组合形成包括:宽松拦截模式、较宽松拦截模式、严格拦截模式、较严格拦截模式四种不同的风险规则,保障在不同拦截规则下,能够对风险内容进行有效处理。
- 本系统构建全模型网关配置方式,形成一次配置多次控制方式,包括:
- 网关配置:通过配置防护模型的访问方式和请求内容、响应内容的格式,即可无缝实现内容安全过滤。
- 服务监控配置:通过对网关的监控实时处理风险内容的识别和拦截分布,以及实现风险内容管理。
- 本系统的风险拦截实施方案如下:
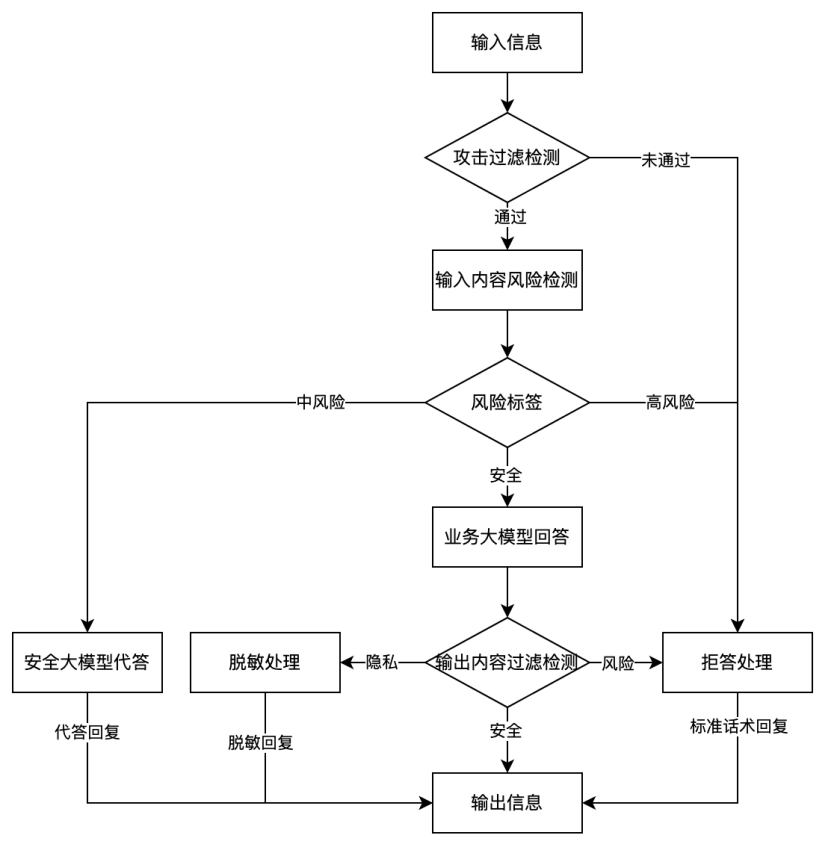 具体如下:
具体如下:
通过配置完成的网关接收人工智能的须过滤的内容,对内容进行处理操作。
3.1 用户输入内容,通过攻击过滤模型,检测是否存在攻击风险
3.2 如果通过,则对风险内容进行检测,返回对应的风险标签。如果不通过对业务方进行拒答处理。
3.3 风险标签中对于中风险内容,实现安全模型代答回复。对于高风险内容实现拒答处理。如果安全,则实现业务模型回答。
3.4 对业务模型回答的内容实现风险过滤,如果存在敏感信息进行脱敏处理。如果存在风险内容,进行拒答回复。如果安全进行信息内容输出。
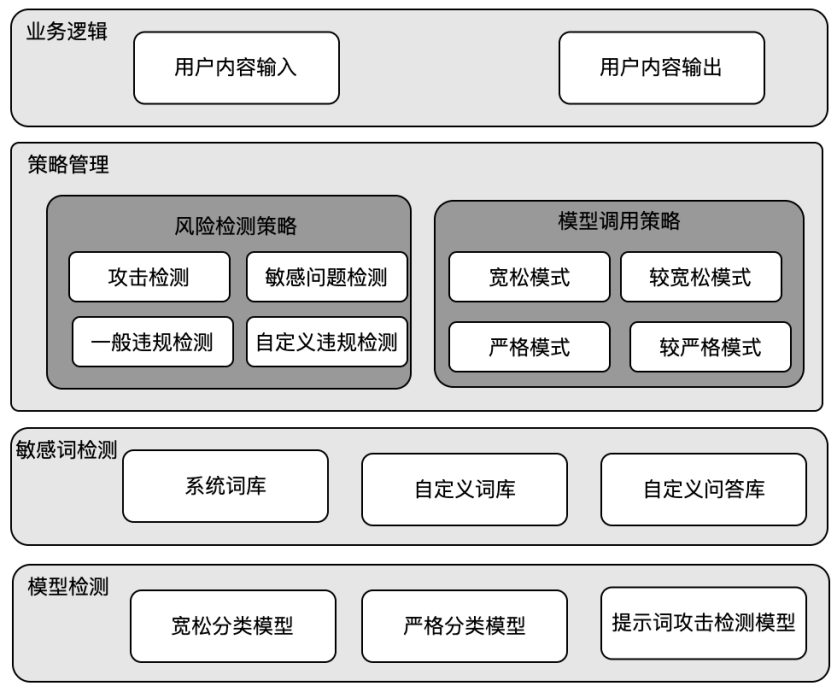
图1 系统架构
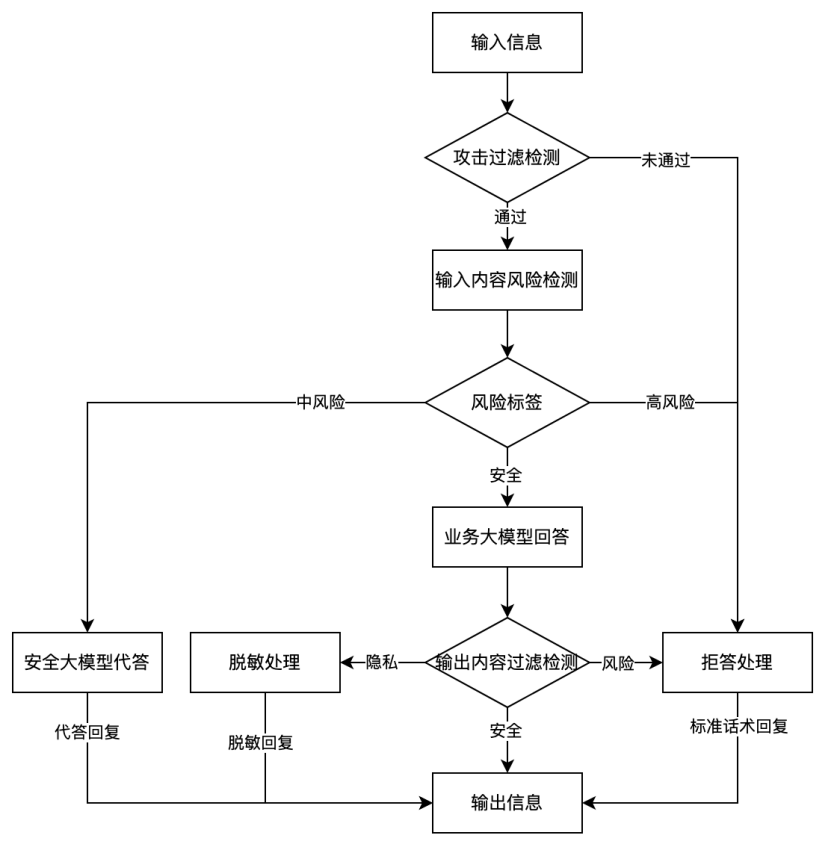 图2 风险内容过滤流程
图2 风险内容过滤流程

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)