java后端工程师+AI大模型进修ing(研一版‖day54)
java随笔录——全文索引——ESAI随探录——RNN的重要参数,RNN的输入和输出代码随想录——回溯算法
今日总结
- java随笔录——全文索引——ES
- AI随探录——RNN的重要参数,RNN的输入和输出
- 代码随想录——回溯算法
目录
详细内容
java随笔录
全文索引——ES
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
要做一个搜索模块,首先你要知道索引数据从哪来,其次再去写一些搜索的功能。项目先要创建索引,再要实现搜索。利用elasticsearch作为索引及搜索服务。
索引相当于MySQL中的表,Elasticsearch与MySQL之间概念的对应关系见下表: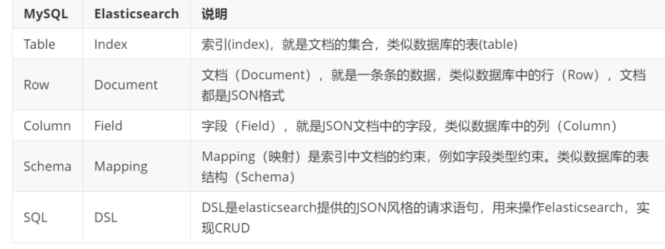
课程信息索引同步
通过向索引中添加信息最终实现了搜索,我们发现信息是先保存在关系数据库中,而后再写入索引,这个过程是将关系数据中的数据同步到elasticsearch索引中的过程,可以简单成为索引同步。
通常项目中使用elasticsearch需要完成索引同步,索引同步的方法很多:
1、针对实时性非常高的场景需要满足数据的及时同步,可以同步调用,或使用Canal去实现。
1)同步调用即在向MySQL写数据后远程调用搜索服务的接口写入索引,此方法简单但是耦合代码太高。
2)可以使用一个中间的软件canal解决耦合性的问题,但存在学习与维护成本。
canal主要用途是基于 MySQL 数据库增量日志解析,基于mysql的binlog技术实现数据同步,并能提供增量数据订阅和消费,实现将MySQL的数据同步到消息队列、Elasticsearch、其它数据库等,应用场景十分丰富。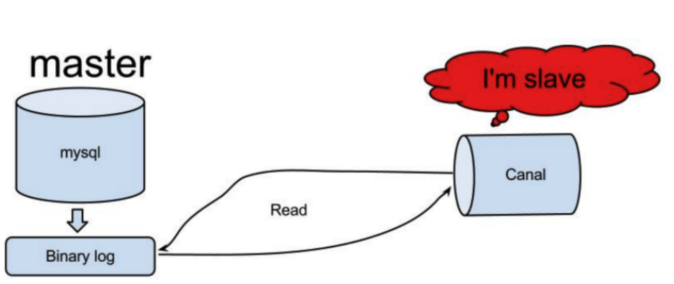
2、当索引同步的实时性要求不高时可用的技术比较多,比如:MQ、Logstash、任务调度等。
MQ:向mysql写数据的时候向mq写入消息,搜索服务监听MQ,收到消息后写入索引。使用MQ的优势是代码解耦,但是需要处理消息可靠性的问题有一定的技术成本,做到消息可靠性需要做到生产者投递成功、消息持久化以及消费者消费成功三个方面,另外还要做好消息幂等性问题。
增删改索引的代码如下
public Boolean addCourseIndex(String indexName,String id,Object object) {
String jsonString = JSON.toJSONString(object);
IndexRequest indexRequest = new IndexRequest(indexName).id(id);
//指定索引文档内容
indexRequest.source(jsonString,XContentType.JSON);
//索引响应对象
IndexResponse indexResponse = null;
try {
indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("添加索引出错:{}",e.getMessage());
e.printStackTrace();
XueChengPlusException.cast("添加索引出错");
}
String name = indexResponse.getResult().name();
System.out.println(name);
return name.equalsIgnoreCase("created") || name.equalsIgnoreCase("updated");
}
@Override
public Boolean updateCourseIndex(String indexName,String id,Object object) {
String jsonString = JSON.toJSONString(object);
UpdateRequest updateRequest = new UpdateRequest(indexName, id);
updateRequest.doc(jsonString, XContentType.JSON);
UpdateResponse updateResponse = null;
try {
updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("更新索引出错:{}",e.getMessage());
e.printStackTrace();
XueChengPlusException.cast("更新索引出错");
}
DocWriteResponse.Result result = updateResponse.getResult();
return result.name().equalsIgnoreCase("updated");
}
@Override
public Boolean deleteCourseIndex(String indexName,String id) {
//删除索引请求对象
DeleteRequest deleteRequest = new DeleteRequest(indexName,id);
//响应对象
DeleteResponse deleteResponse = null;
try {
deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("删除索引出错:{}",e.getMessage());
e.printStackTrace();
XueChengPlusException.cast("删除索引出错");
}
//获取响应结果
DocWriteResponse.Result result = deleteResponse.getResult();
return result.name().equalsIgnoreCase("deleted");
}AI随探录
RNN的重要参数
1. input_size:每个时间步驶入特征的维度(词向量的维度)
2.hidden_size:隐藏状态的维度
3.num_layers:RNN层数,默认为1
4.nonlinearity:激活函数,‘tanh默认’huozhe‘relu’
5.bias:是否使用偏置项
6.batch_first:输入张量是否是(batch,seq,feature),默认是false(seq,batch,feature)
7.dropout:除了最后一层外,其余层之间的dropout概率。进行随机失活,防止过拟合
RNN的输入和输出
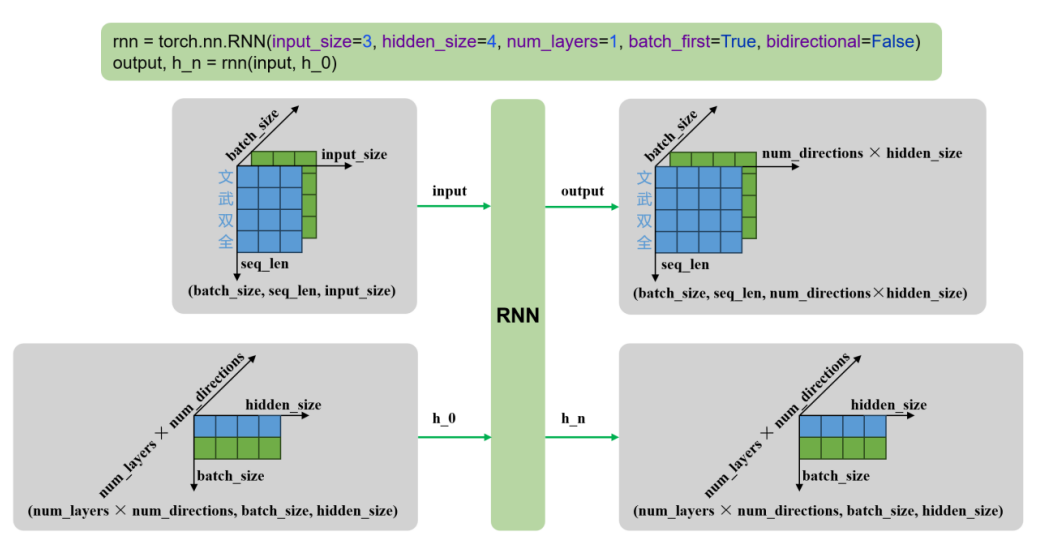
示例代码
rnn = torch.nn.RNN()
output, h_n = rnn(input, h_0)|
输 入 |
input |
输入序列,形状为(seq_len, batch_size, input_size),如果 batch_first=True,则为 (batch_size, seq_len, input_size) |
|
h_0 |
可选,初始隐藏状态,形状为 (num_layers × num_directions, batch_size, hidden_size) |
|
|
输 出 |
output |
RNN层的输出,包含最后一层每个时间步的隐藏状态,形状为 (seq_len, batch_size, num_directions × hidden_size ),如果如果 batch_first=True,则为(batch_size, seq_len, num_directions × hidden_size ) |
|
h_n |
最后一个时间步的隐藏状态,包含每一层的每个方向,形状为 (num_layers × num_directions, batch_size, hidden_size) |
以单层单向举例如下
代码随想录
回溯算法
回溯与递归是相辅相成的,主要又递归就会有回溯。递归函数下面就是我们回溯的过程。
回溯法是一个纯暴力的搜索
回溯法解决的问题
回溯算法的模版
//回溯算法的返回值一般都是void
void backtracking(参数) {
if (终⽌条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩⼦的数量就是集合的⼤⼩)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}例题
给定两个整数
n和k,返回范围[1, n]中所有可能的k个数的组合。你可以按 任何顺序 返回答案。
示例 1:
输入:n = 4, k = 2 输出: [ [2,4], [3,4], [2,3], [1,2], [1,3], [1,4], ]示例 2:
输入:n = 1, k = 1 输出:[[1]]提示:
1 <= n <= 201 <= k <= n
class Solution {
List<List<Integer>> result = new ArrayList<>();
LinkedList<Integer> path = new LinkedList<>();
public List<List<Integer>> combine(int n, int k) {
combine(n, k , 1);
return result;
}
void combine(int n, int k, int startindex) {
if(path.size() == k){
result.add(new ArrayList<>(path));
if(startindex > n)
return;
return;
}
for(int i = startindex; i <= n; i++) {
path.add(i);
combine(n,k,i+1);
path.removeLast();
}
}
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)