华为 CANN 算子开发全解析:从执行模型到工程化落地的深度实践指南
在大模型时代,AI 基础设施不再以纯硬件算力为核心竞争力,真正决定训练与推理效率的,是算力能否被充分释放。而在华为 Ascend 处理器体系中,这一切的底层基础能力都通过 CANN(Compute Architecture for Neural Networks)提供的算子机制得以构建。算子不仅是算力的最小调度单元,更是模型图编译、跨设备调度、内存布局优化以及融合策略的核心。
华为 CANN 算子开发全解析:从执行模型到工程化落地的深度实践指南
在大模型时代,AI 基础设施不再以纯硬件算力为核心竞争力,真正决定训练与推理效率的,是算力能否被充分释放。而在华为 Ascend 处理器体系中,这一切的底层基础能力都通过 CANN(Compute Architecture for Neural Networks)提供的算子机制得以构建。算子不仅是算力的最小调度单元,更是模型图编译、跨设备调度、内存布局优化以及融合策略的核心。
过去,大部分开发者把 CANN 算子理解为“写 Kernel”,但随着 CANN Runtime、Graph Engine(GE)、TBE/Ascend C、AutoTune、AutoFuse 等模块不断完善,算子早已演进为一个涵盖编译、执行、调度、并发、分布式一致性的复杂系统。本文试图从体系结构、执行模型、开发路径和优化策略等多个视角,梳理一次真正“体系化”的 CANN 算子开发全流程。
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
一、CANN 中算子的角色:不仅仅是运算单元
算子在传统意义上承担的是数学运算的职责,例如矩阵乘加、卷积、激活函数等。而在 Ascend CANN 中,它至少承担三层职责: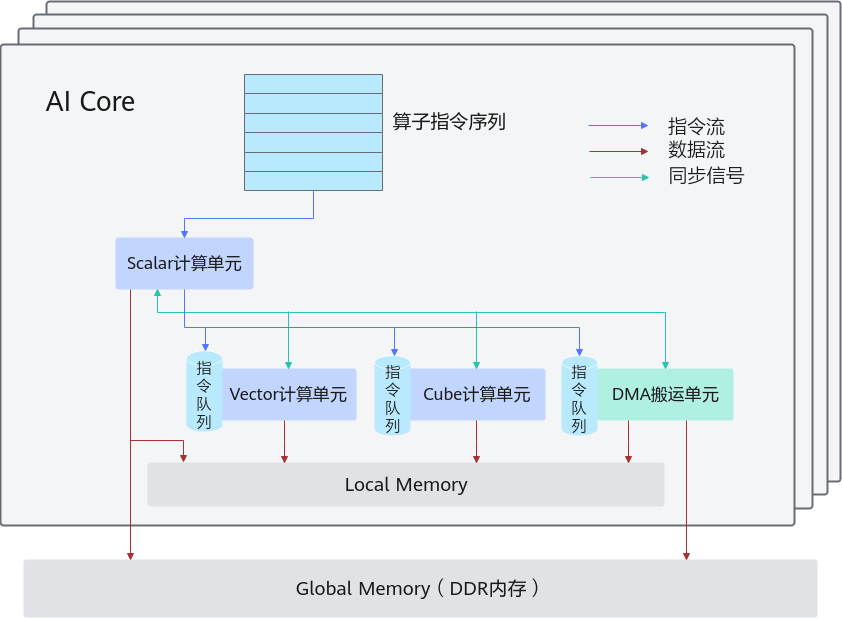
1. 模型图编译中的基本构件
图编译器会将前端框架(TensorFlow、PyTorch、MindSpore 等)的计算图转换为 CANN 的 IR,每个 IR 节点都直接或间接映射到算子。算子的属性决定了图分割是否可行、算子能否跨设备调度、内存规划是否有效。
2. 运行时执行的调度粒度
Ascend 的 AI Core 并不是简单执行 Kernel,而是依据 Tiling 策略、Pipeline 调度策略和 SPMD 模型,对算子执行进行精细化控制。
算子组织了:
- 内存分配/复用方式
- AI Core 与 CPU 协同模式
- 缓存/UB(Unified Buffer)访问模式
- 单算子多并发线程(block)的执行方式
3. 性能优化的中心载体
融合、AI Core 状态控制、Prefetch 机制、流水线优化、AutoTune 搜索,都依赖算子接口和算子属性。
因此,一个“算子”在 CANN 中的意义几乎等同于 GPU 世界里的 CUDA Kernel + 计算图节点 + 调度指令的组合。
二、CANN 的执行模型:SPMD + AI Core 的并行计算哲学
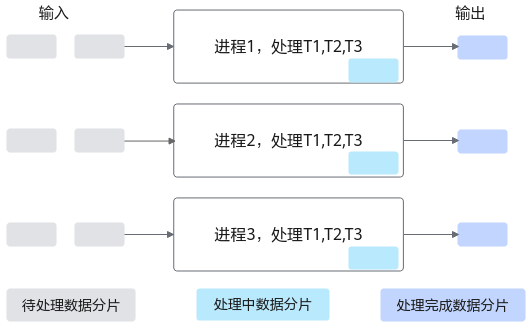
Ascend C算子开发的核心思想是 SPMD(Single Program Multiple Data),即所有 Core 执行同一段算子代码,但根据自身 ID(block_id)处理不同数据区间。
1. Why SPMD?
SPMD 可以最大化硬件利用率,因为:
- 程序无需多版本维护(高可维护性)
- 数据域分片可由编译器统一决定(优化空间大)
- AI Core 数量多、结构统一,非常适合 SPMD 模型
2. SPMD 中的数据切片策略
CANN 将数据划分为多个 tile,每个 tile 被一个 Core 处理。关键难点在于“tile 的大小与访问模式要满足 AI Core 对对齐、访存、流水线的要求”。
例如:
- GEMM 的 tile 通常是 MK-KM 格式
- 卷积算子的 tile 受 HWC/NCHW 布局影响
- Softmax 的 tile 则常基于行维度切分
开发者只需要遵守算子访存逻辑,其余由 Tiling 算法自动生成。
3. PipeLine 机制
AI Core 的 Pipeline 大体分为三段:
- Load:从 GM(Global Memory)搬运到 UB
- Compute:执行数学运算
- Store:将结果写回 GM
一个优秀算子应保证三者尽可能并行,形成如下流水:
Load → Compute → Store
↳ Load → Compute → Store
↳ Load → Compute → Store
算子性能是否达到峰值,很大程度取决于此。
三、CANN 中算子的分类与系统位置
一个完整 CANN 算子体系一般包含:
1. TBE/Ascend C 算子(AI Core 侧)
负责高性能数学计算,是最重要的部分。
2. CPU 算子(Host 侧)
用于非密集型计算、内存管理、数据准备工作。
3. 融合算子(Composite)
由多个基础算子按 Fusion 规则组合而成,可以减少 GM 访存。
4. AutoFuse 自动融合算子
由编译器借助策略搜索生成,不需要手写。
5. 图层算子(Graph-Level)
用于处理大算子、中间张量布局等任务。
不同类型算子参与模型编译的不同阶段,从 OP 原型、图构建、算子调度、Kernel 编译,到最终执行,形成完整链路。
四、算子开发的工程化流程:从规格到 Kernel 调度
在实际工程项目中,一个算子的开发流程远比写 Kernel 要复杂。
下面以AI Core 基础算子开发为例,梳理完整流程。
1. 定义算子规格(OP Spec)
包括:
- 输入、输出张量格式(Shape、DType、Format)
- 支持的动态 shape 范围
- 广播/对齐/对称性约束
- 算子属性(属性参数,例如 axis)
这一步影响到框架适配和图编译。
2. Tiling 设计
Tiling 是算子性能的灵魂,它定义:
- 一个 Core 要处理多少数据
- 每次从 GM 读取多少
- UB 需要多少空间
- AI Core 的并行程度
Tiling 通常由编译器自动生成,但在某些算子(如卷积、GEMM)中需要手写算法逻辑高阶优化。
3. Kernel 编写(Ascend C)
Ascend C 脚本控制:
- 数据搬运(Load/Store)
- 计算核使用(如 Vector Engine、Scalar Engine)
- UB 资源分配
- 并行 block 的执行顺序
示例伪代码(非文档、非真实 API,只为表达 Ascend C 风格):
__kernel__ void AddKernel(__gm__ float* x, __gm__ float* y, __gm__ float* out, int n) {
int core_id = get_block_id();
int start = core_id * TILE_SIZE;
int end = min(start + TILE_SIZE, n);
__ub__ float buf_x[TILE_SIZE];
__ub__ float buf_y[TILE_SIZE];
for (int i = start; i < end; i += STEP) {
load(buf_x, x + i, STEP);
load(buf_y, y + i, STEP);
vadd(buf_x, buf_y, STEP);
store(out + i, buf_x, STEP);
}
}
虽然简单,但体现了 SPMD + Pipeline 模式。
4. Host 端适配(PyTorch/TensorFlow/MindSpore)
包括:
- 算子调用接口
- Shape 推导
- 算子属性解析
- 动态形状处理
- 算子注册
这一步决定模型是否能在框架侧正确调用算子。
5. 调试与 Profiling
CANN 提供全链路调试工具:
- CANN Profiler:核执行时间、访存、流水线
- Msprof:模型级性能分析
- Dump:中间 Tensor 数据检查
- Ascend CL:算子级功能验证
一篇优秀的算子文章必须强调:Kernel 正确 ≠ 算子正确,算子正确 ≠ 性能最高效。
五、性能优化:CANN 算子调优的系统方法论
算子的性能优化本质上分三层:
1. 内部优化:Kernel 层级
优化方向包括:
- 减少 GM 访存次数(融合、缓存复用)
- 减少 Load/Store 开销(对齐、向量长度)
- 提高 pipeline 并行深度
- 调整 Tile 大小以匹配 AI Core 执行引擎的最佳比例
- 尽量使用向量化指令(VEC)
很多高性能算子如 GEMM/Conv 的精华就在这里。
2. 算子间优化:融合(Fusion)
CANN 在融合方面非常强大,包括:
- AutoFuse 自动融合
- 手写 Composite Fusion(如 MatMul+Bias+Gelu)
- Buffer 重用策略(不落地)
融合可减少:
- 中间张量大小
- GM 访存次数
- 调度开销
其收益甚至大于单算子优化。
3. 图级优化
包括:
- Layout 转换(优化成 NCHW、ND、FRACTAL_Z 等)
- 重排算子顺序(算子调度优化)
- 使用更强并行(Tensor 并行、Pipeline 并行)
这是 CANN 编译器(GraphEngine)的价值所在。
六、工程实践:从单算子到大模型场景的深度应用
在大模型(LLM)场景中,算子不仅要快,还要“稳”。工程实践主要关注以下方面:
1. 动态 Shape 的复杂性
LLM 的 KV Cache 会在每个 Token 变化,算子必须支持动态形状的推导与编译。
2. 大规模计算下的并行一致性
多卡资源的 SP/N場合中,算子需要具备跨 Rank 的一致行为。
3. 内存复用与长序列推理
算子需要在 KV Cache 长序列下减少内存冗余。
4. AutoTune 与实际场景匹配
AutoTune 搜索维度包括:
- tile 大小
- 指令顺序
- 访存策略
- Block 与 ThreadMapping
很多场景下,AutoTune 能带来 30%+ 的收益。
七、总结:CANN 算子体系的根本价值
CANN 算子不是 CUDA Kernel 的简单平替,也不是一个数学库的集合,它是 Ascend 全栈算力体系的核心抽象层。通过统一的执行模型、成熟的 Tiling 策略、丰富的调试工具链以及工程化的架构体系,CANN 使得开发者能够充分释放 AI Core 的潜能。
在越来越重要的大模型推理与训练场景中,高质量算子已经成为决定系统性能与稳定性的关键。而理解 CANN 的算子执行模型、编译体系和优化策略,是掌握 Ascend 平台开发能力的关键一步。
未来,随着 AutoFuse、AutoTune 和分布式算子系统不断完善,CANN 将进一步从“手写算子”走向“自动生成算子”,使开发者把更多精力投入到模型创新,而非底层指令优化。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)