深入华为 CANN算子-AI Core 架构与算子执行模型的系统性解析(训练营深度理论篇)
本文试图从程序员视角出发,将华为 Ascend AI Core 的核心计算机制、数据路径、不同架构上的行为特征进行系统解释,并结合大量细节讨论,让开发者不仅“知道如何写算子”,而且“知道算子为什么要这么写”、“代码背后硬件实际做了什么”、“性能为什么会差一个量级”。这篇文章会比常规文档更深入,也更强调算子执行本质的理解。
深入华为 CANN算子-AI Core 架构与算子执行模型的系统性解析(训练营深度理论篇)
在昇腾 CANN 的算子开发体系中,硬件架构并不是背景知识,而是所有编程模型、调度方式、性能优化策略的起点。算子开发不是单纯调用 API,而是在利用硬件资源完成一次微型的“编译–调度–执行”过程。因此,理解 AI Core 的结构、数据流、存储层次,以及不同架构形态带来的编程差异,是每一个算子开发者必须具备的基本功。
本文试图从程序员视角出发,将华为 Ascend AI Core 的核心计算机制、数据路径、不同架构上的行为特征进行系统解释,并结合大量细节讨论,让开发者不仅“知道如何写算子”,而且“知道算子为什么要这么写”、“代码背后硬件实际做了什么”、“性能为什么会差一个量级”。这篇文章会比常规文档更深入,也更强调算子执行本质的理解。
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
一、AI Core 的角色:不仅是算力单元,而是一个紧凑的计算系统
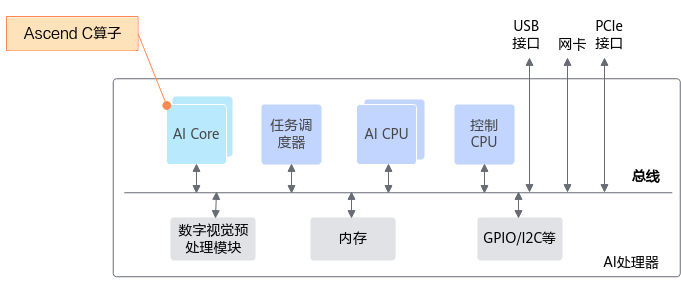
Ascend 芯片中的 AI Core,看似是一个功能单元,但在算子开发的视角,它更像一个针对深度学习计算高度优化的微型处理器集群。它具有自己的指令集、自主执行流、专用计算模块、分层存储体系、内部数据搬运网络,以及可以并行调度不同计算单元的控制机制。
算子在 AI Core 中执行时,本质上是以下几个子系统同时协作完成:
- Scalar 子系统负责控制执行流程、发射指令、初始化变量、推进循环和触发同步;
- Vector 子系统负责进行高吞吐的向量级逐元素计算,例如常见的 Add、Mul、Exp 等;
- Cube 子系统则负责深度学习的核心——矩阵乘,几乎所有卷积、全连接等算子都依赖它;
- MTE 搬运子系统决定算子之间的数据供给是否充足;
- UB、L0A/L0B/L0C、L1 等存储系统决定数据是否能及时供给给 Cube 和 Vector。
只有当所有单元同时高效工作,算子性能才能逼近理论上限。单纯提升计算能力无法带来性能飞跃,因为深度学习算子通常受制于访存和数据搬运。理解这一点,意味着理解算子优化的核心命脉。
二、架构的两种形态:耦合架构与分离架构的深层差异
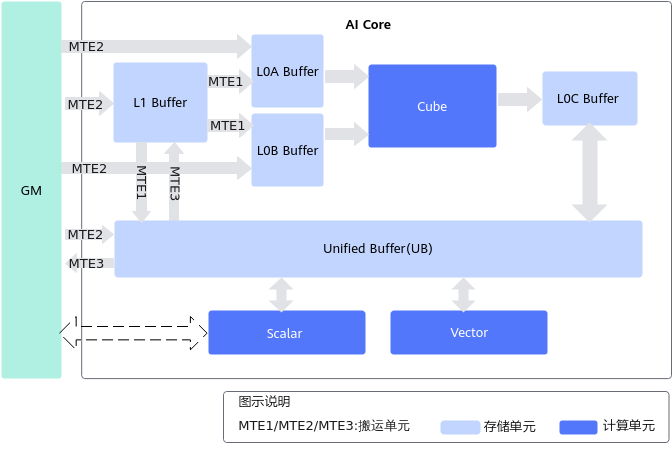
与很多传统处理器不同,Ascend 的 AI Core 并非固定架构,而是随着产品演进演化出两种不同的形态:耦合式架构与分离式架构。这两种架构在程序执行方式、数据流管理方式、Cube 与 Vector 的调度能力等方面都有本质差异,决定了算子需要采用不同的调度策略。
耦合架构:单核同时具备 Cube/Vector/Scalar
耦合架构是主流 Ascend AI Core 的设计形态,它将矩阵计算单元(Cube)、向量单元(Vector)、标量单元(Scalar)和搬运单元(MTE)整合在一个统一的 AI Core 中。这意味着:
- 数据在核内流动,延迟极低;
- 向量和矩阵计算在硬件层面共享存储层次,包括 L0A/L0B/L0C、UB、L1 等;
- Scalar 支配着整个核的所有资源调度。
对初学者而言,耦合架构的编程体验更自然,因为所有单元都在统一结构中,结构简单、逻辑清晰。但是,从高性能算子开发视角看,耦合架构的限制也明显:
- Cube 与 Vector 存在抢资源问题;
- 同一套 UB、同一套 L1 可能导致访存冲突;
- 调度时间窗口有限。
换句话说,一个优秀的算子必须尽可能避免不同计算单元的争用,把资源利用率推到极限。
分离架构:AIC(矩阵核)与 AIV(向量核)完全分开
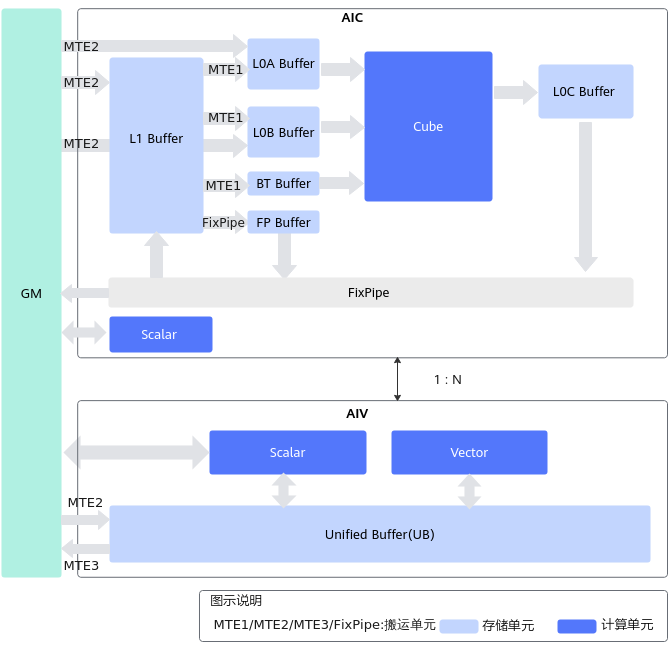
随着模型规模扩大,矩阵计算和向量计算的比例不断变化,新一代 A2 系列采用了分离式 AI Core 设计。AIC 专注矩阵计算,AIV 专注向量计算,两者各自拥有:
- 独立的 Scalar;
- 独立的 MTE;
- 独立的指令执行流;
- 各自的编译与调度空间。
这使得 Cube 计算与 Vector 计算可以真正并行,而不是在同核抢占资源。为了支持两核之间协作,系统在 GM 和 L1 之间增加了:
- Bias Table Buffer(BT Buffer)
- FixPipe Buffer(FP Buffer)
使一些中间参数(如偏置、量化参数、激活参数)能在两个核之间流动时不需要在大存储中来回扫描。
分离架构最大的意义在于允许开发者把算子拆分为矩阵路径与向量路径两个执行流程,通过并行调度把硬件效率推向另一种层级。
三、数据流设计是算子的核心:理解“数据在哪里”比“计算做什么”更重要
一个算子在执行时,会在 GM、L2、L1、L0/UB 之间不断搬运数据。算子的性能本质上是由数据能多快地进入计算单元决定的,而不是由计算量决定的。
如果要用一句话总结 Ascend 算子的性能原则,那就是:
Cube 和 Vector 不是算子性能瓶颈,数据搬运才是。
因此理解数据在系统中的流向,是算子优化的第一步。
四、Vector 与 Cube 的数据流:两条互不相同的高速通路
Ascend 的数据通路不是统一的,而是为不同类型的计算建立了不同的高速路径。
Vector 数据流:GM → UB → Vector → UB → GM
向量计算的所有输入/输出都必须位于 UB 中,而且对齐严格:
- 首地址需要 32 Byte 对齐;
- 操作长度也必须满足同样的对齐要求;
- 不能直接从 GM 或 L1 访问数据。
因此在设计 Vector 调度时要尽可能减少 UB 分段,将向量逻辑整合为批量操作。
Cube 数据流:GM → L1 → L0A/L0B → Cube → L0C → FixPipe → GM 或 L1
Cube 对存储的要求更复杂:
- A 矩阵一定来自 L0A;
- B 矩阵一定来自 L0B;
- 运算结果写入 L0C;
- L1 是 Cube 上最重要的 preload/cache 层;
- FixPipe 可能对中间结果进行量化/激活等处理。
这一整套路径意味着 Cube 算子性能高度依赖:
- Tile 尺寸设计是否合适;
- L1 是否高效复用;
- MTE 是否做到 Pipe 并行;
- L0A/L0B/L0C 的排布是否满足 block align。
五、理解三大计算单元:Scalar、Vector、Cube 的真正规则
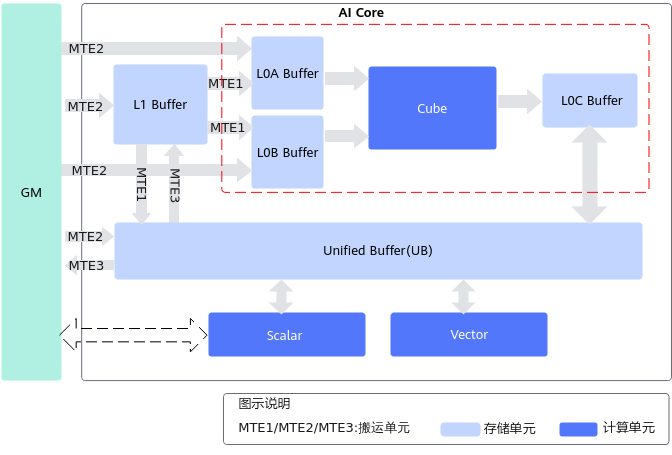
算子的执行是通过这三大计算单元完成的:
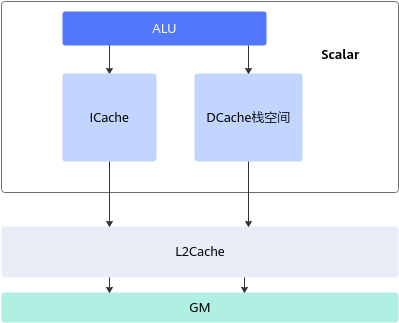
Scalar 是整个算子的控制器
Scalar 执行:
- 流程控制(循环、跳转)
- 参数计算
- Cube、Vector 指令的发射
- 同步机制
Scalar 类似一个轻量 CPU,但性能不强,因此算子开发中必须遵守:
- 尽量减少分支(if/else)
- 尽量减少标量变量运算
- 尽可能让指令缓存(ICache)命中
- 尽可能让数据缓存(DCache)命中
即:算子不是写得越复杂越好,而是越“简单可预测”越好。
Vector 执行并行逐元素计算
Vector 最强大的地方是:
- 它能把一次指令扩展成大量元素运算;
- 支持按步长遍历(跨步向量);
- 可对 UB 中的任意连续数据执行操作。
它特别适合 LayerNorm、Softmax 中前几步这样的逐元素计算,也适合激活函数、归一化等基础操作。
向量计算的瓶颈永远在 UB,而不是向量单元本身。
Cube 是深度学习性能的决定性单元
所谓“深度学习加速器”,本质就是“一个为矩阵乘优化的芯片”。Cube 的性能决定了大部分深度学习算子的整体吞吐。
Cube 计算的运行方式涉及:
- block 划分(M、N、K)
- L0 数据加载的 tile 化
- L1 → L0A/L0B 的预加载
- 预取流水(preload pipeline)
- L0C 的结果合并与写回
Cube 编程的关键点在于保证每次 Cube 指令都吃饱数据。任何阻塞都会引起整个流水线 stall。
六、算子执行模型的核心:并行流水,而不是顺序执行
很多初学者写算子的时候,会把算子逻辑写成顺序动作:
- 从 GM 读数据
- 把数据搬到 UB/L0
- 执行 Vector/Cube
- 写回 GM
但真正的高性能算子绝不是这么执行的。
实际上,一个算子在硬件上是以多条流水线同时推进的:
- 当第 k 次计算在 Cube 上进行时
- 第 k+1 次的数据搬运正在 MTE 上发生
- 第 k+2 次的 tile 初始参数正在 Scalar 中准备
换句话说:
Cube、Vector、MTE、Scalar 都必须一直忙着,而不能互相等待。
所以高性能算子开发的终极目标是:
构建真正的“计算–搬运–预取”三流水机制,让硬件永不空转。
做到这一点会使算子性能比 naive 写法高一个数量级。
七、深入理解架构是写好算子的必要条件,而不是可选项
许多开发者以为“算子开发就是调用 tik 接口或 ascendc API”,但实际上性能差的算子与性能好的算子差距可能是 5~20 倍,而差距的来源几乎全部来自开发者是否理解硬件架构。
理解:
- Cube、Vector、Scalar 的边界;
- UB/L1/L0 的限制;
- MTE 的吞吐;
- 对齐要求;
- 耦合 vs 分离架构的差异;
- 数据流设计;
- 挂起与流水的原理;
这些不是理论知识,而是每一个算子性能的根源。
只有理解了这些,你才能:
- 写出高性能矩阵算法
- 写出高吞吐的向量计算
- 设计合理的流水调度
- 构建高效 tile 划分
- 避免 cache miss、L0 冲突、UB 溢出
- 真正触达 Ascend 芯片的峰值算力
在整个算子开发与优化的实践过程中,我们可以看到,CANN 的设计理念始终围绕“算子高效执行”展开:从前端算子抽象,到中端图优化,再到后端 Kernel 级别的精细调度,每一层都服务于极致性能的目标。借助 Kernel 直调工程、AutoFuse 自动融合、异构并行调度等能力,开发者不仅能够快速实现定制算子,也能够以可控的方式深度挖掘昇腾 AI Core 的计算潜力。算子开发不再只是硬件驱动的被动适配,而逐渐演化为一种体系化的工程能力——它要求开发者理解编译链路、算子语义、计算图、内存模型与并行执行机制,也要求在真实业务中不断迭代、验证与优化。掌握这一套方法论,意味着你能够把模型性能真正“压榨到物理极限”,并以工程化方式构建面向未来的大规模 AI 算力应用。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)