GPU 与 CPU 内部通道:结构、功能及优缺点全解析
CPU和GPU内部通道设计差异显著:CPU采用低延迟、灵活的多通道架构(指令/数据总线分离、缓存互联等),适合复杂逻辑调度,但带宽有限(1-2TB/s);GPU则通过高带宽并行通道(寄存器堆互联、SM互联网络等)实现10-20TB/s吞吐量,专为海量并行计算优化。CPU通道占比15-20%芯片面积,GPU仅占8-12%。这种差异决定CPU擅长系统调度等通用任务,GPU则胜任AI训练等并行计算。多卡
CPU(中央处理器)和 GPU(图形处理器)的内部通道是芯片核心 “数据传输与控制枢纽”,直接决定运算效率 —— 本质上,这些通道是芯片内部不同组件(如核心、缓存、显存 / 内存控制器)之间的 “专用线路”,其设计差异完全适配两者的核心定位(CPU 侧重串行复杂逻辑,GPU 侧重并行海量计算)。

一、先明确核心前提:内部通道的设计逻辑
- CPU:需兼顾 “复杂逻辑调度” 和 “高效数据传输”,内部通道更注重 “低延迟、灵活适配多任务”(类似城市核心区的 “快速路 + 支路”,既要快,又要能连接多个目的地);
- GPU:需支撑 “海量并行计算”,内部通道更注重 “高带宽、高吞吐量”(类似城市间的 “高速公路集群”,主打批量数据快速运输,牺牲部分灵活性换效率)。
二、CPU 内部核心通道:类型、功能及优缺点
CPU 内部通道围绕 “控制单元(CU)、算术逻辑单元(ALU)、多级缓存(L1/L2/L3)、内存控制器” 展开,核心目标是 “让串行任务的指令和数据快速流转”。
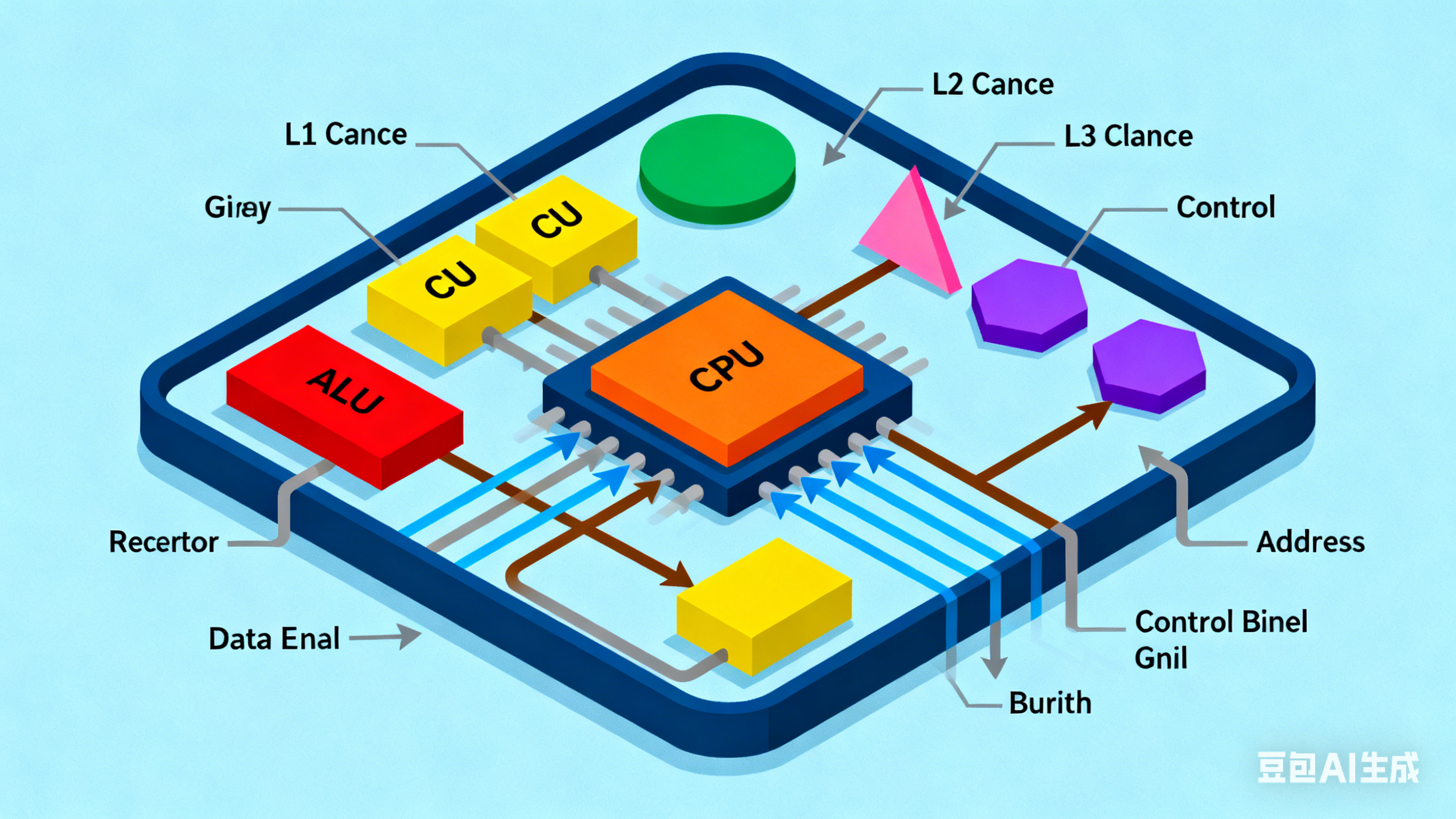
1. 核心通道类型及功能
| 通道类型 | 连接组件 | 核心功能 | 通俗类比 |
|---|---|---|---|
| 指令总线(Instruction Bus) | 控制单元 ↔ L1 指令缓存 ↔ 指令解码器 | 传输 CPU 要执行的指令(如加减运算、逻辑判断) | “指令快递专线”:只送 “操作命令” |
| 数据总线(Data Bus) | 算术逻辑单元(ALU) ↔ L1 数据缓存 ↔ L2 缓存 | 传输运算所需的数据(如变量、矩阵元素)和运算结果 | “数据运输专线”:只送 “运算原料和产物” |
| 缓存互联通道(Cache Coherence Bus) | 各核心的 L1/L2 缓存 ↔ 共享 L3 缓存 | 同步多核心缓存数据(避免多核心读取到不一致数据) | “缓存同步通道”:确保各核心 “信息统一” |
| 核心间互联(Inter-Core Interconnect,如 Intel UPI、AMD Infinity Fabric) | 多个 CPU 核心 ↔ 共享 L3 缓存 ↔ 内存控制器 | 多核心之间的数据交换、共享资源访问 | “核心间高速路”:让不同核心协同工作 |
| 内存控制器通道(Memory Controller Bus) | L3 缓存 ↔ 内存控制器 ↔ 外部内存(RAM) | 连接 CPU 与外部内存,传输批量数据 | “CPU 与内存的桥梁”:负责内外数据交换 |
2. CPU 内部通道的核心优缺点
优点:
- 低延迟优先:指令总线和数据总线采用 “短路径设计”,延迟极低(通常在 1-10ns 级别),适配 CPU 的串行任务(如逻辑判断、函数调用)—— 比如 CPU 执行 “if-else” 指令时,能快速从缓存读取指令和数据,无需等待;
- 灵活性强:支持 “指令与数据分离传输”(指令总线和数据总线独立),能适配复杂多任务场景(如同时运行办公软件、编程工具、浏览器),不同任务的指令和数据可并行传输,互不干扰;
- 缓存一致性保障:缓存互联通道通过 “缓存一致性协议”(如 MESI),确保多核心共享数据时的准确性 —— 比如多线程编程中,一个核心修改了变量,其他核心能快速获取最新值,避免计算错误;
- 兼容性广:通道设计适配通用计算需求,支持复杂指令集(x86、ARM),能处理各种类型的任务(从简单运算到复杂系统调度)。
缺点:
- 带宽相对较低:受限于核心数量(少而精)和功耗,CPU 内部通道的总带宽远低于 GPU(比如高端 CPU 内部带宽约 1-2TB/s,而 GPU 可达 10TB/s 以上),不适合海量数据并行传输;
- 成本高:低延迟和灵活性设计需要复杂的电路和协议支持(如缓存一致性协议),导致 CPU 芯片面积和功耗增加 —— 比如 Intel i9-14900K 的缓存互联通道占芯片面积的 15% 以上;
- 吞吐量有限:通道设计侧重 “单任务快速处理”,而非 “多任务批量处理”,当面对海量重复数据(如大模型矩阵运算)时,通道会成为瓶颈,无法充分利用硬件资源。
三、GPU 内部核心通道:类型、功能及优缺点
GPU 内部通道围绕 “流多处理器(SM,NVIDIA)/ 计算单元(CU,AMD)、共享内存、寄存器堆、显存控制器、张量核心 / 光线追踪核心” 展开,核心目标是 “让海量并行任务的数据流快速流转”。
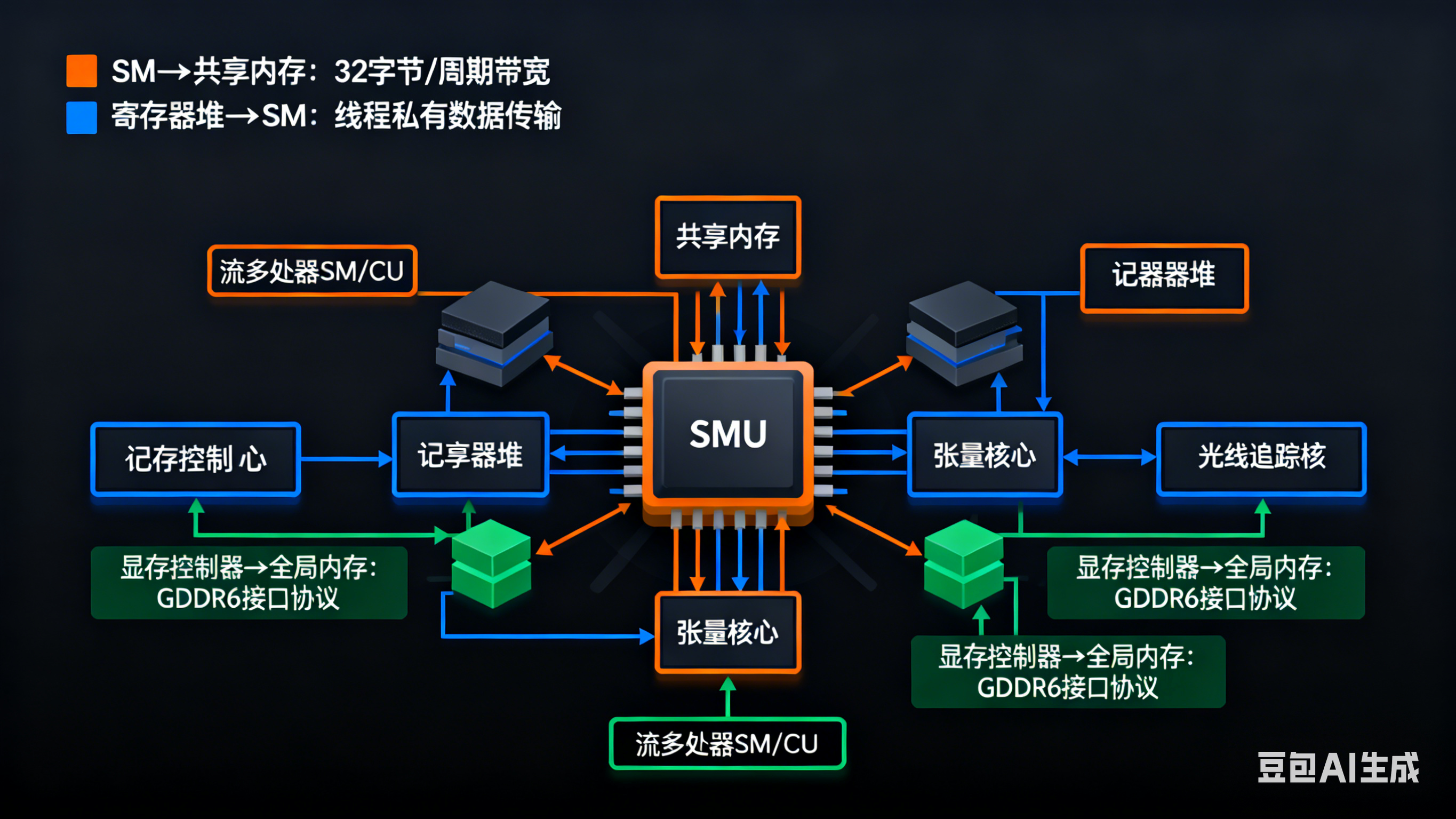
1. 核心通道类型及功能
| 通道类型 | 连接组件 | 核心功能 | 通俗类比 |
|---|---|---|---|
| 寄存器堆互联(Register File Interconnect) | 流处理器(SP) ↔ 寄存器堆 | 传输运算核心(SP)的临时数据(如并行计算的中间结果) | “运算核心的专属高速缓存通道”:速度最快、延迟最低 |
| 共享内存通道(Shared Memory Bus) | 同一 SM/CU 内的流处理器 ↔ 共享内存 | 同一计算单元内的流处理器共享数据(如同一批次的图像像素数据) | “小组内共享数据通道”:适配小规模并行协作 |
| SM/CU 互联网络(Inter-SM/CU Network,如 NVIDIA NVLink-On-Chip) | 多个 SM/CU ↔ 显存控制器 ↔ 外部显存(VRAM) | 不同计算单元之间的数据交换、批量数据传输到显存 | “计算单元集群高速路”:主打高带宽批量传输 |
| 专用核心通道(Specialized Core Bus) | SM/CU ↔ 张量核心 / 光线追踪核心 | 传输 AI 计算(矩阵运算)、光追计算的专用数据 | “专用任务专线”:适配 AI、光追等特定场景 |
| 显存控制器通道(VRAM Controller Bus) | 互联网络 ↔ 显存控制器 ↔ 外部显存(HBM3/GDDR7) | 连接 GPU 与外部显存,传输海量并行数据 | “GPU 与显存的超级桥梁”:带宽远超 CPU 内存通道 |
2. GPU 内部通道的核心优缺点
优点:
- 带宽极致高:通道设计主打 “吞吐量优先”,采用多通道并行、宽位宽设计(如 H100 的显存控制器通道位宽达 5120 位),内部总带宽可达 10-20TB/s(是高端 CPU 的 5-10 倍),能支撑数万流处理器同时读取数据;
- 并行优化好:寄存器堆互联和共享内存通道为 “海量并行” 量身定制 —— 比如一个 SM 包含 1024 个流处理器,寄存器堆通道能同时为所有流处理器提供数据,无明显瓶颈;
- 专用场景高效:专用核心通道直接连接张量核心 / 光追核心,无需经过通用通道中转,AI 训练 / 推理、光追渲染时的效率极高(如 H100 的张量核心通道能让 FP8 算力达 4PFLOPS);
- 成本效益高:通道设计牺牲部分灵活性(如简化缓存一致性协议),专注并行传输,相同芯片面积下能提供更高的带宽 —— 比如 GPU 芯片的通道电路占比仅 8-12%,但带宽是 CPU 的数倍。
缺点:
- 延迟较高:为追求高带宽,通道路径相对较长(如多 SM 之间的互联),延迟通常在 5-20ns 级别(是 CPU 内部通道的 2-5 倍),不适合串行复杂逻辑任务;
- 灵活性差:通道设计适配 “海量重复任务”,对复杂多任务(如同时运行 AI 训练、科学计算、图形渲染)的支持不足 —— 比如切换任务时,通道需要重新分配带宽,效率较低;
- 缓存一致性弱:GPU 的共享内存仅在单个 SM/CU 内同步,跨 SM/CU 的数据一致性需要软件层面优化(如手动同步),不像 CPU 那样自动保障 —— 这也是 GPU 不适合多线程复杂逻辑的原因之一;
- 专用性强:通道优化侧重并行计算和图形任务,对通用计算场景(如系统调度、复杂逻辑判断)的适配性差,无法替代 CPU 的内部通道。
四、CPU 与 GPU 内部通道核心差异对比表
| 对比维度 | CPU 内部通道 | GPU 内部通道 |
|---|---|---|
| 设计目标 | 低延迟、高灵活性、适配复杂多任务 | 高带宽、高吞吐量、适配海量并行任务 |
| 核心带宽 | 1-2TB/s(高端型号) | 10-20TB/s(高端型号,如 H100) |
| 延迟水平 | 1-10ns | 5-20ns |
| 缓存一致性 | 硬件自动保障(MESI 协议) | 仅单 SM/CU 内保障,跨单元需软件优化 |
| 通道类型 | 指令 / 数据分离、缓存互联、核心间互联 | 寄存器堆互联、共享内存通道、SM 互联网络 |
| 适配任务 | 系统调度、复杂逻辑、通用计算 | AI 训练 / 推理、科学计算、图形渲染 |
| 芯片面积占比 | 15-20%(复杂电路 + 协议) | 8-12%(简化设计,专注传输) |
| 功耗效率 | 低(高延迟设计功耗高) | 高(高带宽设计功耗比更优) |
五、结合科研 / 工作场景的关键结论
-
为什么 GPU 适合 AI 大模型训练?GPU 的 SM 互联网络 + 显存控制器通道提供极致带宽,能同时为数万流处理器传输模型参数和训练数据,解决 “海量数据并行读写” 的核心需求;而 CPU 内部通道带宽不足,即使核心数量增加,也无法支撑大规模并行数据传输。
-
为什么 CPU 不能替代 GPU 做并行计算?CPU 内部通道的低延迟设计导致带宽有限,且缓存一致性协议占用大量硬件资源 —— 如果用 CPU 做并行计算,通道会成为瓶颈,数万并行任务会因数据传输缓慢导致效率极低(类似用城市快速路运输万吨货物,不如高速公路集群高效)。
-
GPU 集群的通道优势?数据中心级 GPU(如 H100、昇腾 910B)的内部通道支持 “多卡互联”(如 NVLink、昇腾互联),跨 GPU 的通道带宽可达数百 GB/s,能让多卡协同训练时的数据传输无瓶颈 —— 这也是大模型训练必须用专业 GPU 集群的核心原因之一。
-
科研中需要关注的通道瓶颈?
- 训练大模型时:若 GPU 显存通道带宽不足(如用消费级 GDDR6 显存替代 HBM3),会导致数据传输速度跟不上计算速度,出现 “计算核心等数据” 的情况;
- 多卡并行时:跨 GPU 的通道(如 PCIe 5.0 vs NVLink)带宽差异会影响训练效率 ——NVLink 带宽是 PCIe 5.0 的 3-5 倍,能大幅缩短多卡数据同步时间。
注:多卡并行时的跨GPU通道
多卡并行场景中,跨 GPU 通道按应用范围可分为单机多卡通道和多机多卡通道两类,前者侧重近距离高带宽通信,后者主打大规模集群扩展,适配不同规模的并行计算需求。
- 单机多卡跨 GPU 通道这类通道主要用于单服务器内部多张 GPU 的互联,核心优势是传输距离短、延迟低,适配单机内模型并行、数据并行等场景。
- PCIe 总线:这是最基础且通用的跨 GPU 通道,依托主板原生的 PCIe 插槽实现 GPU 间通信,主流版本为 PCIe 4.0 和 5.0。其单通道单向带宽,PCIe 4.0 达 2GB/s,PCIe 5.0 达 4GB/s,主流 GPU 使用 x16 通道时,PCIe 4.0 x16 双向带宽为 64GB/s。它无需额外硬件,兼容性强,几乎所有 GPU 和主板都支持,但带宽有限,且数据传输可能需要 CPU 少量介入,适合中小规模模型的训练或推理任务,是无专用互联技术时的默认选择。
- NVLink:NVIDIA 推出的专有高速互连技术,专为 GPU 间高频通信设计,常见于 A100、H100 等高端数据中心 GPU。最新的 NVLink 4.0 单链路带宽达 100GB/s,单 GPU 支持多条链路,双 GPU 间双向带宽可轻松突破 300GB/s。它采用多通道全双工通信,支持多 GPU 网状拓扑,8 卡系统总带宽可达 4.8TB/s,能实现 GPU 间内存统一寻址,大幅降低梯度同步等场景的延迟,但缺点是仅适配 NVIDIA 高端 GPU,且需要主板支持,硬件成本较高。
- Infinity Fabric:AMD 针对自家 GPU 和 CPU 设计的互联技术,类似 NVIDIA 的 NVLink,用于实现 AMD GPU 之间及 GPU 与 CPU 的高速通信。该技术通过封装基板中的专用布线,缩短信号传输距离,减少延迟和信号衰减,适配 AMD 多 GPU 的单机并行场景,比如专业图形渲染和中小型科学计算,但生态适配性相较于 NVLink 弱,主要集中在 AMD 硬件体系内。
- SLI/CrossFire:两者分别是 NVIDIA 和 AMD 早期推出的多 GPU 渲染专用通道。SLI 需通过专用 SLI 桥连接,CrossFire 可通过数据线或 PCIe 连接,核心用于提升游戏、图形渲染的性能。不过这类技术已逐渐退出主流,仅支持有限的 GPU 配对,且对多任务并行计算适配性差,无法满足大模型训练等高频数据交互需求。
- 多机多卡跨 GPU 通道这类通道用于连接不同服务器节点上的 GPU,解决大规模集群中跨节点的 GPU 通信问题,核心追求高带宽、可扩展性和低延迟。
- RoCE:即基于融合以太网的 RDMA 技术,能在标准以太网框架下实现远程直接内存访问,允许 GPU 直接访问远程 GPU 内存,无需 CPU 参与数据传输。它支持 100Gbps + 速率,延迟低至微秒级,只需配备支持 RoCEv2 的专业交换机和智能网卡,就能构建大规模 GPU 集群,成本低于 InfiniBand,是多机多卡分布式训练的高性价比方案,可替代 InfiniBand 用于跨节点大模型推理部署。
- InfiniBand:一种原生支持 RDMA 的高性能互连技术,是大规模 GPU 集群的核心通道之一。它延迟极低、带宽高,比如 HDR InfiniBand 端口带宽可达 200Gb/s,且能减少 CPU 开销,数据传输稳定性强。该技术常被用于 xAI 等超大规模 AI 集群,不过它需要专用的 InfiniBand 适配器和交换机,硬件和部署成本较高,更适用于对延迟和带宽要求极致的超大规模模型训练场景。
- FSO(自由空间光通信):通过激光束在自由空间传输数据的跨节点 GPU 通信通道,理论带宽可达 100Gbps+,延迟与光纤相当。其优势是无需布线,适合快速部署和临时链路搭建,可作为跨机房 GPU 集群的冗余备份方案,但缺点是受天气影响大,雾、雨、沙尘会导致信号衰减,且需要高精度对准系统维持链路稳定,不适用于长期、稳定的大规模集群通信。
总结
CPU 和 GPU 的内部通道是 “因任务而生” 的设计:
- CPU 的通道像 “精密的城市交通网”,兼顾速度和灵活性,适合处理需要复杂调度的通用任务;
- GPU 的通道像 “高效的货运高速公路集群”,牺牲部分灵活性换极致吞吐量,适合处理海量并行的专用任务。
两者的通道设计没有 “优劣之分”,而是互补关系 —— 在科研和工作中,CPU 负责任务调度、数据预处理,GPU 负责并行计算,通道则是各自完成任务的 “核心枢纽”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 32
32 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)