AIGC(生成式AI)试用 42 -- 程序(Python + OCR)-4
(生成式AI)试用 42 -- 程序(Python + OCR)-4
个人理解:
- 思想 --> 讨论 --> 白板 --> 草图 --> 原型 --> 设计 --> 代码 --> 测试。。。。。。
- 敏捷过程中的产出有多少可以被AI识别、转换,促成最终产品以最短的时效提交客户?
有多少并不成熟的草稿可以被AI汇总、理解后生成标准的规格说明?
一直恐写文档的软件开发过程,是否能被AI所取代?我们只需要给出只言片语的思考
代码呢?AI辅助下的软件开发该如何演进? - AI对图片文字识别完整、正确 -- OCR专门程序还有必要么?
- AI对图片功能意图识别正确 -- 给的图片太简单了?还是AI大模型能感受到我最近的输入?
- 使用标准的WPS Officel打开界面,AI对图片内容的识别效果依然很Nice
- AI按图实现代码:
- GUI界面元素基本按原界面实现(区别:"图像显示" 标签,按钮配色)
- 核心功能"开始识别",部分代码需要手工调整(show_log, cls, ),这个问题在所有Python + OCR的尝试中均存在 -- 为什么? - AI大模型对图片的识别 + 代码实现基本满足要求 -- 如果新、旧对话不存在上下文的联系
- AI进一步降低了开发的门槛和难度,代码生成效率和效果,使不懂得代码的人士能快速通过AI辅助实现自己的想法,对于专业程序员是效率的极大提升
- 关于编码,专业的代码知识仍是必要且重要的,高质量的提问需要对前次结果进行分析、补充和强化不足 -- 也许下一版本的AI可以一次表现的更完美
- 也许 Python + OCR 这样的程序对AI来讲有点“简单”,需要设计一个更有难度的需求,来更深入的验证和学习AI大模型
给出需求,使用文心一言 / cursor + AI轻松开发,500+行代码,一次功能实现80%,二次功能实现100%。
虽仍有细节需不断打磨,但相比给出的需求,输出结果完全在可以接受的范围。
如果需求只是一份原型图(手绘?机绘?),AI会给出什么样的结果?
从 文心一言 换成 豆包,试试结果如何:重建对话
-- 提问 1-1:请识别上传图片中的元素列表,以界面位置、元素名、功能 形式输出
> 手绘图片中的文字识别准确 -- 要什么OCR,直接传图片给AI模型中就好了
> 在未给出背景说明的前提下,单凭一张手绘示意图对界面元素的意图方向识别正确
| 原型:
|
| 提问(Prompt):请识别上传图片中的元素列表,以界面位置、元素名、功能 形式输出 |
豆包 输出:
|
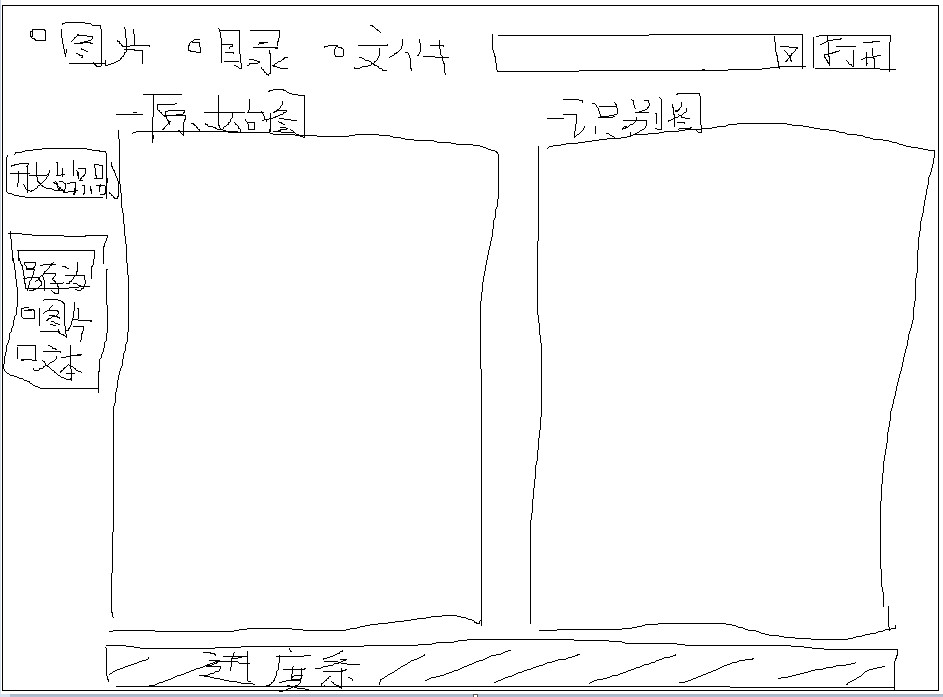
-- 提问 1-2:请识别上传图片中的元素列表,以界面位置、元素名、功能 形式输出
> 标准GUI程序程序界面:基本界面元素识别正确
> 界面标题未识别,但通过标题?对界面功能点的意识有识别
| 原型:
|
| 提问(Prompt):请识别上传图片中的元素列表,以界面位置、元素名、功能 形式输出 |
|
豆包 输出:
|
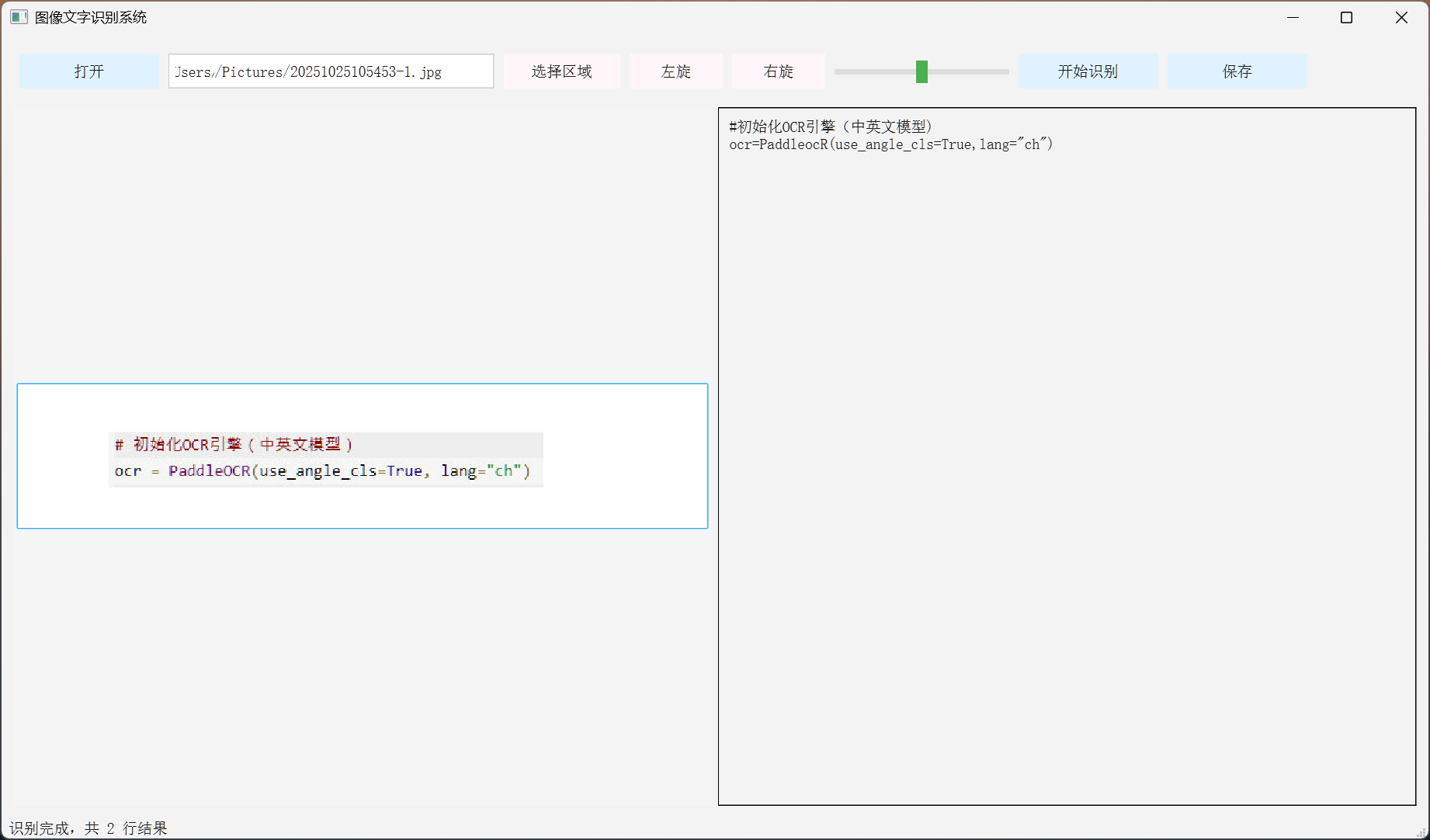
-- 提问 1-3:请识别上传图片中的元素列表,以界面位置、元素名、功能 形式输出
> WPS OfficeGUI程序打开界面:界面各功能元素识别正确
> 各元素功能意图识别基本正确
| 原型:
|
| 提问(Prompt):请识别上传图片中的元素列表,以界面位置、元素名、功能 形式输出 |
豆包 输出:
|
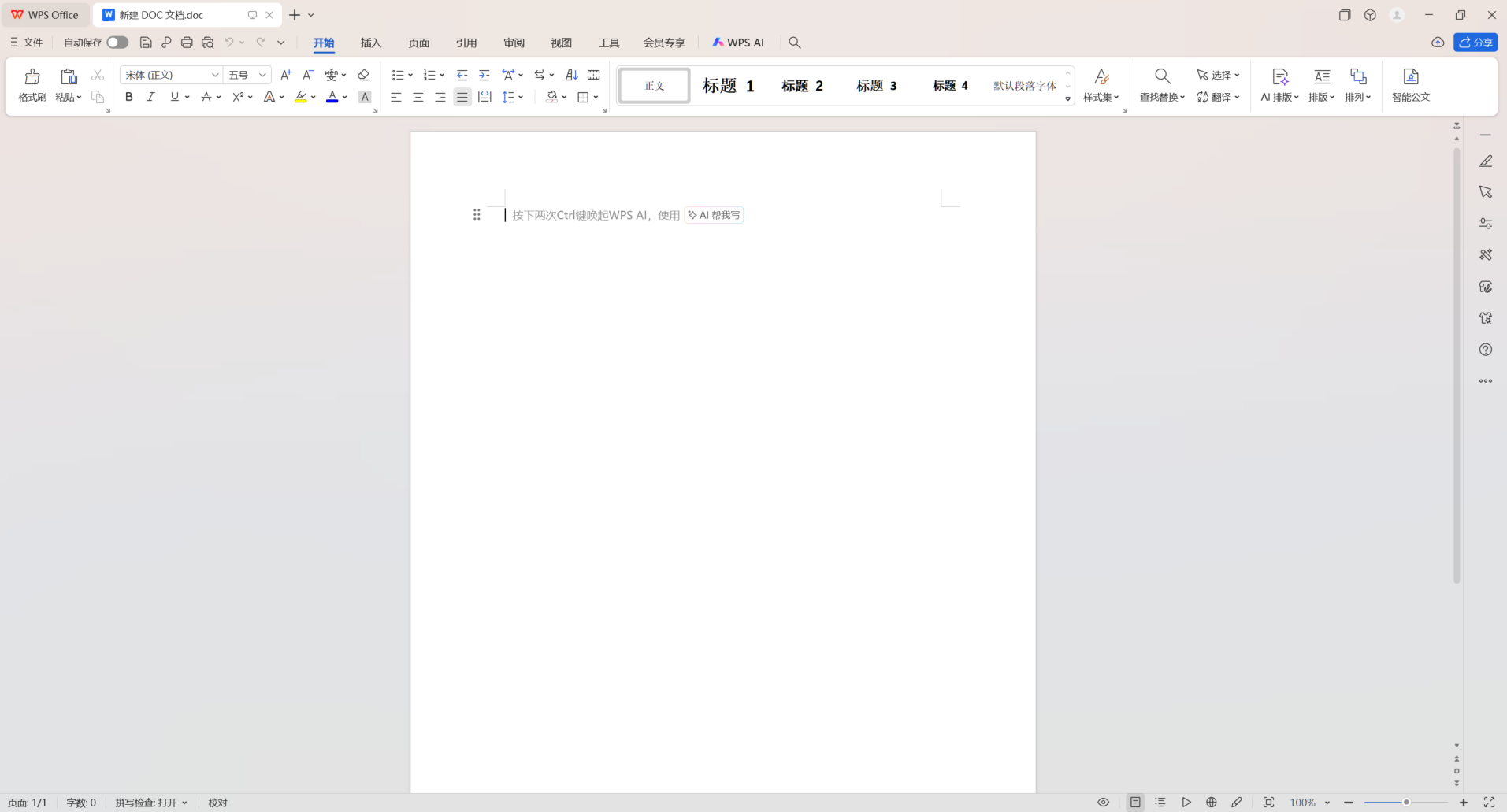
-- 提问 2-1:请根据上传图片使用python完成程序编码
> 系统默认使用TK完成GUI界面设计
> self.ocr.ocr(self.image_path) ##, cls=True),问题在目前OCR识别的所有尝试中均存在,文心一言/豆包/Cursor
> 文字识别结果中的 ['rec_texts'] 序列,问题在目前OCR识别的所有尝试中均存在,文心一言/豆包/Cursor
> 基本功能已实现,选择区域功能
| 原型:
|
| 提问(Prompt):请根据上传图片使用python完成程序编码 |
|
豆包 输出:
|

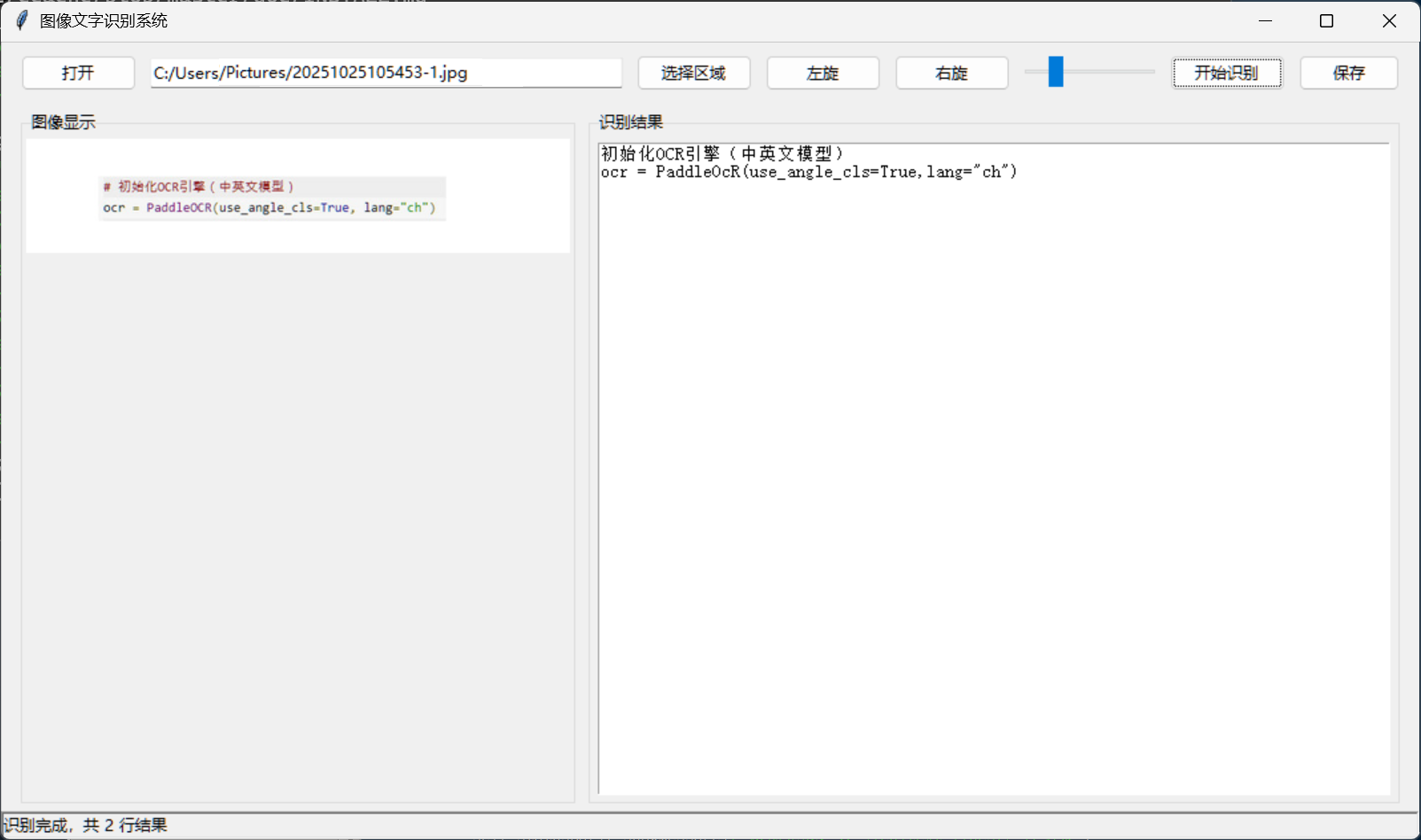
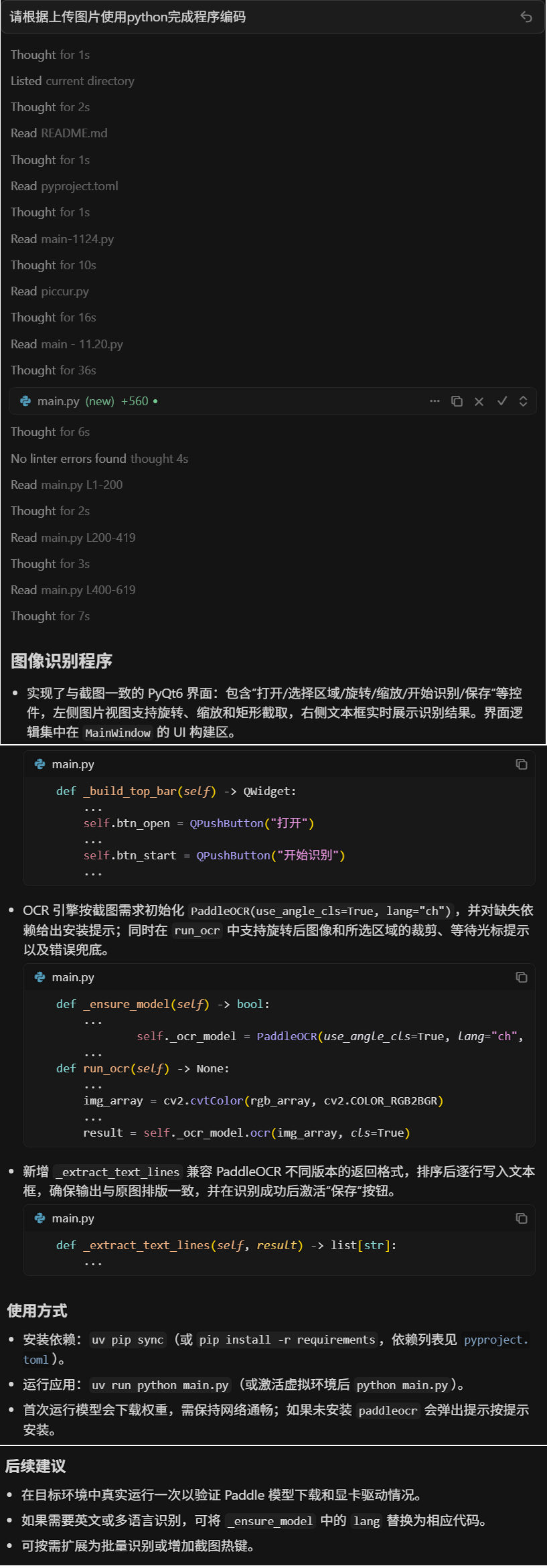
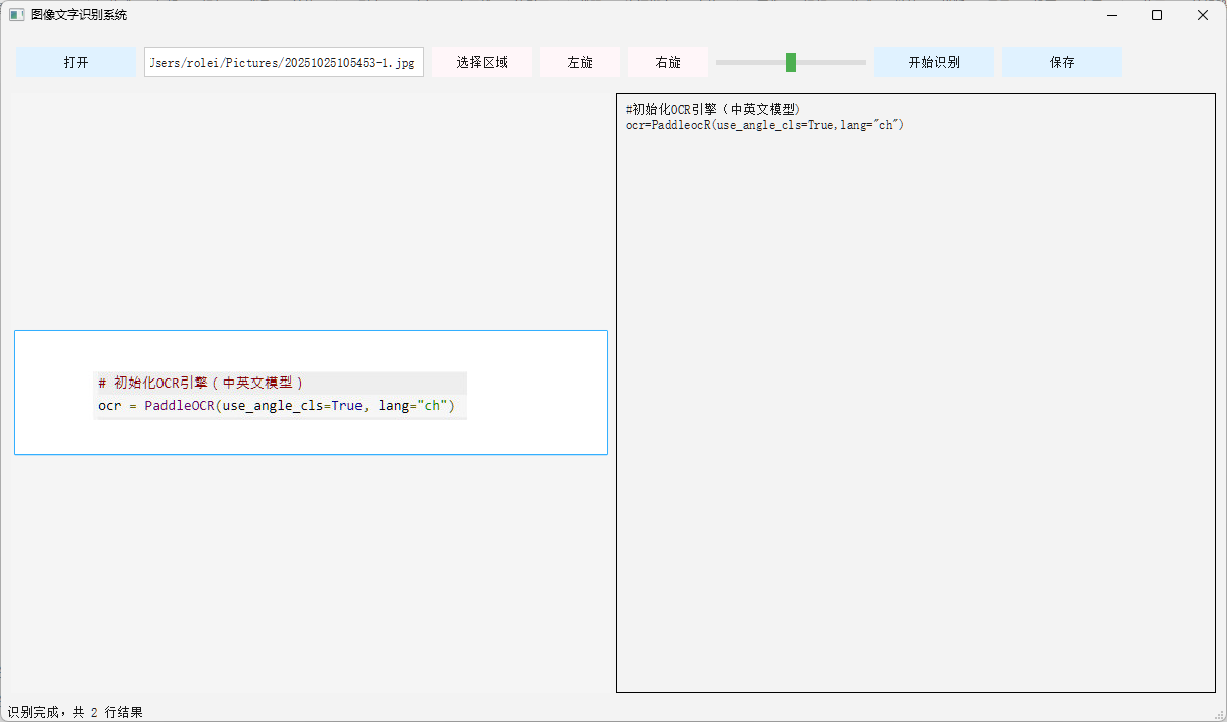
-- 提问 2-2:请根据上传图片使用python完成程序编码
> 原图是cursor画出来的,生成的GUI完全匹配图片输入
> "show_log" 问题依然存在
> "cls" 问题依然存在
> ['rec_texts'] 序列问题没了,cursor从之前的错误中学到了?
| 原型:
|
| 提问(Prompt):请根据上传图片使用python完成程序编码 |
|
Cursor 输出:
|
参考:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)