AI论文整理:GoogLeNet - Going Deeper with Convolutions
本文提出了名为Inception的深度卷积神经网络架构,其具体实现版本GoogLeNet(22层深)在2014年ImageNet大规模视觉识别挑战赛(ILSVRC14)中刷新分类和检测任务的state-of-the-art。该架构核心是通过精心设计的Inception模块(整合1×1、3×3、5×5卷积及3×3最大池化,利用1×1卷积实现维度缩减以控制计算量)提升计算资源利用率,在保持15亿次乘加
论文标题:《Going Deeper with Convolutions》
下载链接:https://arxiv.org/pdf/1409.4842.pdf
1. 一段话总结
本文提出了名为Inception的深度卷积神经网络架构,其具体实现版本GoogLeNet(22层深)在2014年ImageNet大规模视觉识别挑战赛(ILSVRC14)中刷新分类和检测任务的state-of-the-art。该架构核心是通过精心设计的Inception模块(整合1×1、3×3、5×5卷积及3×3最大池化,利用1×1卷积实现维度缩减以控制计算量)提升计算资源利用率,在保持15亿次乘加操作的推理计算预算下,既增加网络深度和宽度,又避免过拟合与计算浪费;训练中引入辅助分类器增强梯度传播与正则化,最终GoogLeNet在ILSVRC14分类任务中取得6.67%的top-5错误率(无外部数据),检测任务中获得43.9%的mAP,且参数数量比Krizhevsky等人2012年的获胜模型少12倍。
2. 思维导图(mindmap)
## 核心主题:GoogLeNet(Inception架构)
### 一、研究背景与动机
- 传统CNN问题:增大尺寸导致参数激增(过拟合)、计算资源浪费
- 理论依据:Arora等人稀疏网络理论(聚类高相关神经元)、Hebbian原理
- 实际需求:移动/嵌入式计算对效率(功耗、内存)的要求
### 二、核心架构设计
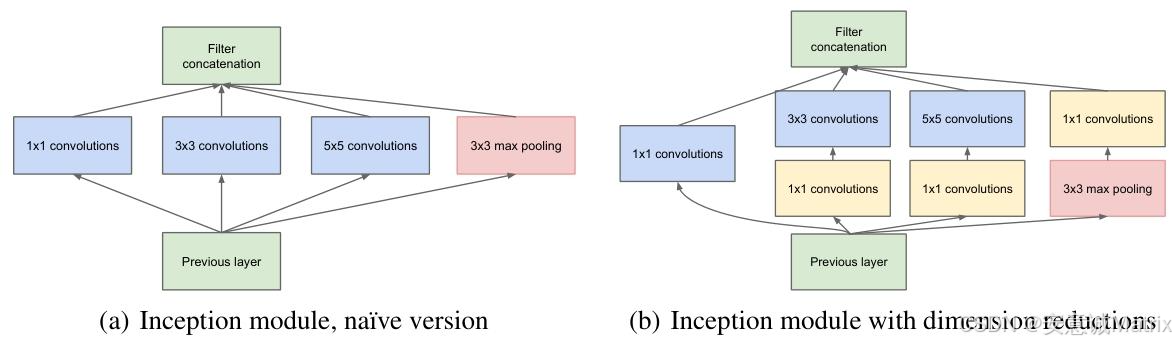
- 1. Inception模块
- 朴素版:1×1卷积、3×3卷积、5×5卷积、3×3 max pooling(输出拼接)
- 优化版:1×1卷积前置(维度缩减,降低3×3/5×5卷积计算量)
- 2. GoogLeNet细节
- 网络深度:22层(含参数层)/27层(含池化层)
- 输入:224×224 RGB图像(均值减法)
- 关键层:7×7卷积(输出64通道)、3×3 max pooling、多组Inception模块(3a/3b、4a-4e、5a-5b)
- 辅助分类器:连接Inception 4a/4d,训练时加权(0.3)贡献损失,推理时丢弃
- 输出层:7×7 avg pooling + 40% dropout + 线性层(1000类)+ softmax
### 三、训练方法论
- 框架:DistBelief分布式系统(CPU实现)
- 优化器:异步SGD(动量0.9)、Polyak平均(最终模型)
- 学习率:固定调度(每8轮下降4%)
- 数据增强:8%-100%面积随机裁剪、3/4-4/3宽高比、 photometric扭曲、随机插值(双线性/面积/最近邻/立方)
### 四、ILSVRC14实验结果
- 1. 分类任务
- 无外部数据:top-5错误率6.67%(排名1st)
- 优化手段:7模型集成、144种裁剪(4尺度×3方位×6 crop×2镜像)、softmax概率平均
- 性能拆解:1模型144裁剪(7.89%)、7模型144裁剪(6.67%)
- 2. 检测任务
- 方法:R-CNN框架+Inception分类器、Selective Search+MultiBox(提升召回率)
- 结果:mAP 43.9%(6模型集成,无上下文模型/边界框回归)
### 五、结论与意义
- 验证稀疏架构的近似实现(密集组件)在视觉任务的有效性
- 兼顾精度与效率,为后续稀疏网络自动化设计提供方向
3. 详细总结
1. 引言(Introduction)
- 研究背景:2012-2014年深度学习(尤其CNN)推动图像识别/检测进步,核心是架构创新而非仅依赖硬件/数据;移动计算要求算法高效(功耗、内存)。
- 核心贡献:提出Inception架构,其实现版本GoogLeNet(ILSVRC14参赛模型)参数比Krizhevsky 2012年模型少12倍,且精度更高;计算预算控制在15亿次乘加操作(推理时),确保实际应用价值。
- 命名来源:结合Lin等人“Network in Network”与“we need to go deeper”网络迷因,“deep”既指“Inception模块”的新组织层级,也指网络深度增加。
2. 相关工作(Related Work)
| 相关方向 | 代表工作 | 与Inception/GoogLeNet的关联 |
|---|---|---|
| 传统CNN | LeNet-5(LeCun)、Krizhevsky 2012模型 | 基础架构(卷积+池化+全连接),Inception在此基础上优化结构 |
| 多尺度处理 | Serre等人(灵长类视觉皮层模型,固定Gabor滤波器) | Inception借鉴多尺度思想,但滤波器均为学习得到,且网络更深(22层) |
| 网络增强 | Network in Network(Lin等人) | 采用1×1卷积提升表征能力,Inception进一步将1×1卷积用于维度缩减,解决计算瓶颈 |
| 目标检测 | R-CNN(Girshick等人) | GoogLeNet检测方案基于R-CNN,优化区域提议(Selective Search+MultiBox)与分类器(Inception) |
3. 动机与高层考量(Motivation)
- 传统CNN的两大缺陷:
- 过拟合风险:增大网络尺寸(深度/宽度)导致参数激增,若训练数据有限(如ImageNet细分类别),过拟合严重。
- 计算浪费:卷积层串联时,滤波器数量均匀增加会导致计算量二次增长,且部分权重接近零,资源利用率低。
- 解决方案思路:
- 理论方向:从全连接转向稀疏连接(模仿生物系统,符合Arora等人理论:高相关神经元聚类形成下一层单元)。
- 工程妥协:现有硬件对稀疏数据计算低效(查表/缓存命中开销大),故用密集组件近似稀疏结构(如Inception模块聚类高相关特征通道)。
4. 架构细节(Architectural Details)
- Inception模块核心逻辑:
- 多尺度特征融合:视觉信息需在不同尺度处理后聚合,故模块包含1×1(小尺度)、3×3(中尺度)、5×5(大尺度)卷积,及3×3 max pooling(保留空间信息)。
- 维度缩减关键:1×1卷积前置(如3×3卷积前用1×1卷积减少输入通道),例:若输入通道数为192,用64个1×1卷积降维后,3×3卷积计算量从192×k×3×3降至64×k×3×3(k为输出通道),大幅降低计算成本。
- Inception网络通用结构:堆叠Inception模块,间隔插入 stride=2 的max pooling层(减半特征图分辨率);低层仍用传统卷积(内存效率考虑),高层引入Inception模块。
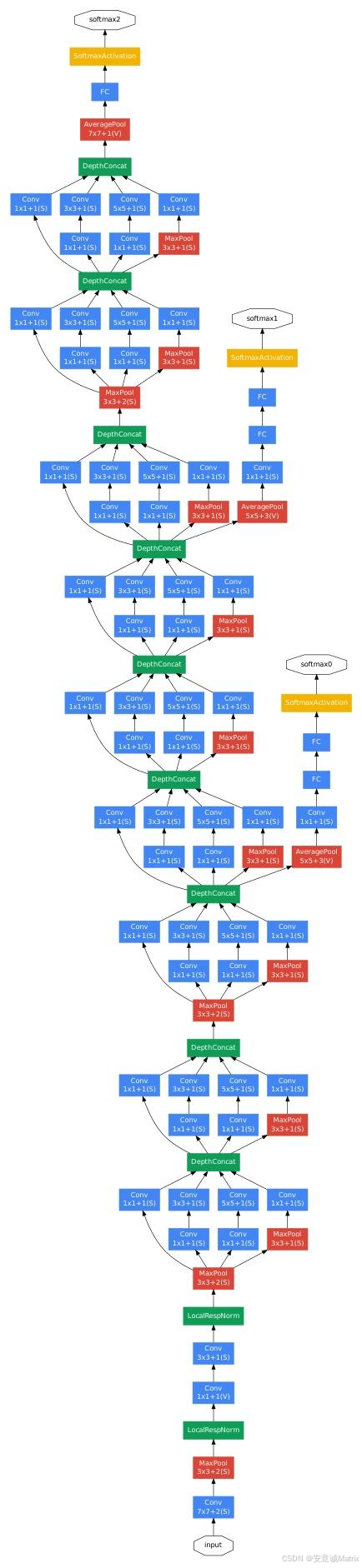
5. GoogLeNet具体结构(表1简化)
| 层类型 | patch尺寸/步长 | 输出尺寸 | 关键参数(#滤波器) | 计算量(ops) |
|---|---|---|---|---|
| 卷积 | 7×7 / 2 | 112×112×64 | - | 34M |
| max pool | 3×3 / 2 | 56×56×64 | - | - |
| 卷积 | 3×3 / 1 | 56×56×192 | 1×1 reduce:64;3×3:192 | 360M |
| max pool | 3×3 / 2 | 28×28×192 | - | - |
| Inception (3a) | - | 28×28×256 | 1×1:64;3×3 reduce:96/3×3:128;5×5 reduce:16/5×5:32;pool proj:32 | 128M |
| Inception (3b) | - | 28×28×480 | 1×1:128;3×3 reduce:128/3×3:192;5×5 reduce:32/5×5:96;pool proj:64 | 304M |
| max pool | 3×3 / 2 | 14×14×480 | - | - |
| Inception (4a-4e) | - | 14×14×(512-832) | 通道数逐步提升至832 | 73M-170M |
| max pool | 3×3 / 2 | 7×7×832 | - | - |
| Inception (5a-5b) | - | 7×7×(832-1024) | 最终输出1024通道 | 54M-71M |
| avg pool | 7×7 / 1 | 1×1×1024 | - | - |
| dropout (40%) | - | 1×1×1024 | - | - |
| 线性层 | - | 1×1×1000 | 参数1000K | 1M |
| softmax | - | 1×1×1000 | - | - |
-
辅助分类器结构(训练专用):
- 5×5 avg pool(步长3)→ 4×4×512(4a)/4×4×528(4d);
- 1×1卷积(128滤波器,ReLU);
- 全连接层(1024单元,ReLU);
- 70% dropout;
- 线性层(1000类,softmax);
- 损失权重:0.3(叠加至总损失)。
-
网络整体结构:
6. 训练方法论(Training Methodology)
- 硬件/框架:DistBelief分布式系统(仅CPU),若用高端GPU训练,可在1周内收敛(内存为主要限制)。
- 数据增强策略:
- 空间增强:随机裁剪(图像面积8%-100%,宽高比3/4-4/3)、水平镜像;
- photometric增强:参考Andrew Howard方法(抑制过拟合);
- 插值方式:随机选择双线性、面积、最近邻、立方(等概率)。
7. ILSVRC14分类任务结果
- 竞赛背景:1000类,120万训练图、5万验证图、10万测试图,评价指标为top-1准确率/top-5错误率。
- 关键结果对比(表2):
| 团队 | 年份 | 排名 | top-5错误率 | 是否用外部数据 |
|---|---|---|---|---|
| SuperVision | 2012 | 1st | 16.4% | 否 |
| Clarifai | 2013 | 1st | 11.7% | 否 |
| VGG | 2014 | 2nd | 7.32% | 否 |
| GoogLeNet | 2014 | 1st | 6.67% | 否 |
- 性能拆解(表3,验证集):
| 模型数量 | 裁剪数量 | 计算成本 | top-5错误率 | 相对基础提升 |
|---|---|---|---|---|
| 1 | 1 | 1 | 10.07% | 基础 |
| 1 | 10 | 10 | 9.15% | -0.92% |
| 1 | 144 | 144 | 7.89% | -2.18% |
| 7 | 1 | 7 | 8.09% | -1.98% |
| 7 | 10 | 70 | 7.62% | -2.45% |
| 7 | 144 | 1008 | 6.67% | -3.45% |
8. ILSVRC14检测任务结果
-
竞赛背景:200类,需输出边界框,评价指标mAP(边界框重叠≥50%为正确)。
-
GoogLeNet检测方案:
- 区域提议:Selective Search(超像素尺寸×2,减少提议数)+ MultiBox(新增200提议),覆盖度从92%→93%,提议数为R-CNN的60%;
- 分类器:Inception架构(6模型集成);
- 未用技术:边界框回归(时间限制)、上下文模型。
-
关键结果对比(表4):
| 团队 | 年份 | 排名 | mAP | 外部数据 | 集成方式 |
|---|---|---|---|---|---|
| UvA-Euvision | 2013 | 1st | 22.6% | 无 | Fisher vectors |
| Deep Insight | 2014 | 3rd | 40.5% | ImageNet 1k | 3 CNN |
| CUHK DeepID-Net | 2014 | 2nd | 40.7% | ImageNet 1k | CNN |
| GoogLeNet | 2014 | 1st | 43.9% | ImageNet 1k | 6 CNN |
9. 结论(Conclusions)
- 核心结论:用密集组件近似最优稀疏结构(Inception模块)是提升视觉CNN性能的可行方案,兼顾精度(分类/检测state-of-the-art)与效率(低计算/参数)。
- 未来方向:基于Arora等人理论,探索自动化设计更稀疏、更精细的网络结构。
4. 关键问题
问题1:Inception架构通过哪些核心设计解决了传统CNN在“增大网络规模”时面临的过拟合与计算浪费问题?
答案:
- 解决计算浪费:通过1×1卷积前置的Inception模块,在多尺度特征提取(1×1/3×3/5×5卷积+3×3池化)前用1×1卷积缩减特征通道数,降低后续大尺寸卷积(3×3/5×5)的计算量(例:192通道输入经64个1×1卷积降维后,3×3卷积计算量大幅减少),实现“增宽/加深网络但计算量可控”,符合15亿次乘加的推理预算。
- 避免过拟合:
- 稀疏结构近似:基于Arora等人理论,通过Inception模块聚类高相关神经元,模拟稀疏连接,减少冗余参数(GoogLeNet参数比Krizhevsky 2012模型少12倍);
- 正则化手段:训练中引入辅助分类器(连接Inception 4a/4d,损失加权0.3)增强梯度传播、抑制过拟合,同时使用40% dropout与 photometric数据增强。
问题2:GoogLeNet在ILSVRC14分类任务中取得6.67% top-5错误率(无外部数据),其测试阶段的关键优化策略是什么?这些策略如何影响性能?
答案:
测试阶段的核心优化策略及性能影响如下(基于验证集数据):
- 多模型集成:独立训练7个GoogLeNet模型(仅差异为采样方法与图像输入顺序),通过集成降低模型方差。单模型144裁剪时top-5错误率为7.89%,7模型集成后降至6.67%,相对提升2.18%。
- 密集图像裁剪:采用144种裁剪方式(4个尺度:短边256/288/320/352;3个方位:左/中/右(横图)或上/中/下(竖图);6个crop:4角+中心+整图缩放;2种镜像),覆盖图像多尺度与多视角信息。单模型从1种裁剪(10.07%)增至144种(7.89%),相对提升2.18%。
- 概率平均融合:对多裁剪、多模型的softmax概率进行平均(而非max pooling),进一步整合多源信息,是实现6.67%错误率的关键融合方式。
问题3:GoogLeNet中的“辅助分类器”设计初衷是什么?其结构与训练逻辑如何适配这一初衷?
答案:
- 设计初衷:解决深层网络(22层)的梯度消失问题,同时增强正则化以抑制过拟合。深层网络中,反向传播时梯度易在浅层衰减,导致低层特征学习不充分;辅助分类器通过在网络中间层(Inception 4a/4d)引入监督信号,增强梯度传播至浅层的强度,同时为模型提供额外正则化。
- 结构与训练逻辑适配:
- 结构适配:辅助分类器采用“小而深”的子网络(5×5 avg pool→1×1卷积降维→全连接层→dropout→线性层),既能适配中间层(4a/4d)的特征尺寸(4×4×512/528),又能独立完成分类任务,提供有效监督;
- 训练逻辑适配:训练时辅助分类器的损失按0.3的权重叠加至总损失(避免其主导主分类器学习),推理时丢弃(不影响最终预测),既实现梯度增强与正则化,又不增加推理成本。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 17
17 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)