即插即用系列 | AAAI 2026 PartialNet:基于“部分注意力卷积”与“动态通道分割”的轻量级网络新标杆
论文名称:Partial Channel Network: Compute Fewer, Perform Better
论文原文 (Paper):https://arxiv.org/abs/2502.01303
代码 (code):https://github.com/haiduo/PartialNet
GitHub 仓库链接(包含论文解读及即插即用代码):https://github.com/AITricks/AITricks
哔哩哔哩视频讲解:https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
1. 核心思想
本文针对如何在减少参数量和 FLOPs 的同时提升网络精度和推理速度这一难题,提出了 Partial Channel Mechanism (PCM)。其核心思想是利用特征图通道间的冗余性,通过 Split 操作将通道分组,并对不同部分应用不同计算代价的算子(如卷积和注意力),从而在保持计算效率的同时增强特征交互。基于此,论文设计了 Partial Attention Convolution (PATConv) 和可学习的 Dynamic Partial Convolution (DPConv),构建了名为 PartialNet 的高效混合网络,在多个视觉任务上实现了更优的速度-精度权衡。
2. 背景与动机
-
文本角度总结:
设计高效神经网络一直是计算机视觉的热点。现有的方法(如 MobileNet, FasterNet)通过深度可分离卷积(DWConv)或部分卷积(PConv)来降低计算量。- DWConv 的问题:虽然 FLOPs 低,但内存访问频繁,导致实际推理吞吐量(Throughput)不高。
- PConv 的局限:FasterNet 使用 PConv 仅对部分通道进行卷积,虽然速度快,但忽略了未计算通道的特征交互潜力,导致精度受限。
- 本文动机:旨在挖掘所有通道的潜力,不再简单地“闲置”部分通道,而是用计算成本较低的 视觉注意力(Visual Attention) 来处理部分通道,用卷积处理另一部分,从而在不增加太多计算负担的前提下显著提升精度。
-
动机图解分析:
-
图 1 (Figure 1): 不同算子对比
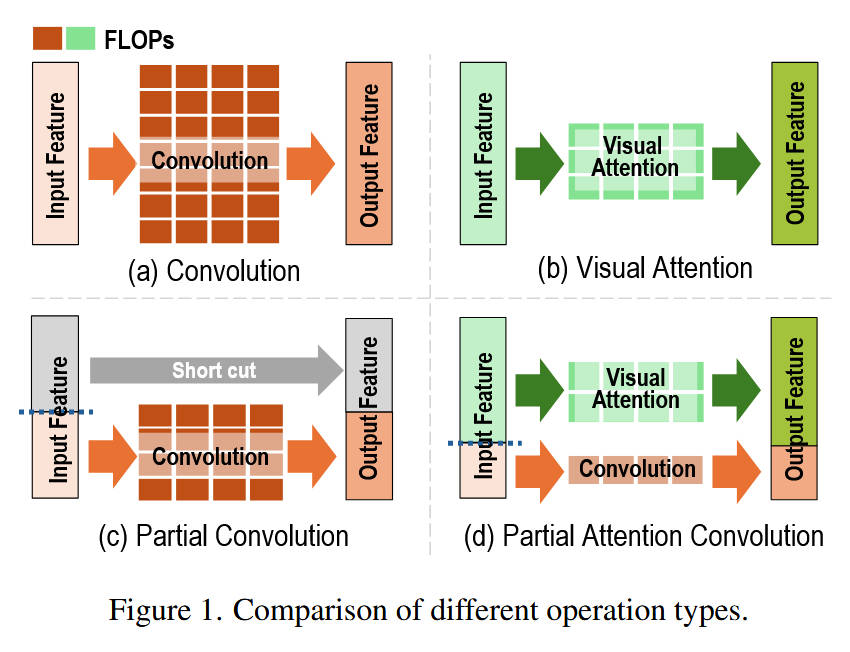
- (a) Convolution:标准卷积,计算密集,FLOPs 高(红色柱状条),特征提取能力强(橙色块),输出特征完整。
- (b) Visual Attention:视觉注意力,计算相对较轻(绿色柱状条),擅长捕获全局依赖,但缺乏局部归纳偏置。
- © Partial Convolution (PConv):仅对部分通道做卷积,另一部分直接通过(Identity)。FLOPs 最低,但“闲置”通道导致信息交互不足,精度受限。
- (d) Partial Attention Convolution (PATConv):本文提出的方案。将一部分通道用于卷积(保留局部性),另一部分通道用于视觉注意力(引入全局性)。不仅 FLOPs 依然较低(红+绿柱状条 < 标准卷积),而且充分利用了所有通道,实现了局部与全局特征的互补,解决了 PConv 精度不足的问题。
-
图 2 (Figure 2): 速度-精度权衡图

- 现象:该图展示了 ImageNet-1k 上各模型的 Top-1 准确率与吞吐量的关系。
- 分析:PartialNet(红色五角星)位于帕累托前沿的最上方,这意味着在相同的推理速度下,PartialNet 的精度显著高于 FasterNet、MobileNetV2 等经典模型;或者在相同精度下,其速度更快。这直观地证明了“部分卷积+部分注意力”策略的有效性。
-
3. 主要贡献点
-
[贡献点 1]:提出了部分通道机制 (PCM) 与 PATConv
创新性地将特征通道分组处理,一部分进行卷积,另一部分并行进行视觉注意力计算。这种并行设计打破了传统“卷积接注意力”(串行)的范式,在提升精度的同时利用硬件并行性提高了推理速度。 -
[贡献点 2]:设计了三种 PATConv 变体块
基于 PCM 思想,设计了三种具体的模块:- PAT_ch:结合 3 × 3 3\times3 3×3 卷积与高斯增强通道注意力,用于捕获全局空间信息。
- PAT_sp:结合 1 × 1 1\times1 1×1 卷积与空间注意力,高效混合通道信息。
- PAT_sf:结合卷积与自注意力(Self-Attention),用于在深层网络中扩展感受野。
-
[贡献点 3]:提出了动态部分卷积 (DPConv)
为了解决人工搜索最佳通道分割比例(Split Ratio, r p r_p rp)的困难,提出了一种可学习的机制。通过引入二值门控向量和 Gumbel-Softmax 技巧,让网络在训练过程中根据资源约束(如 FLOPs)自适应地学习每一层的最佳通道分割比例。
4. 方法细节
-
整体网络架构(对应 Figure 3):
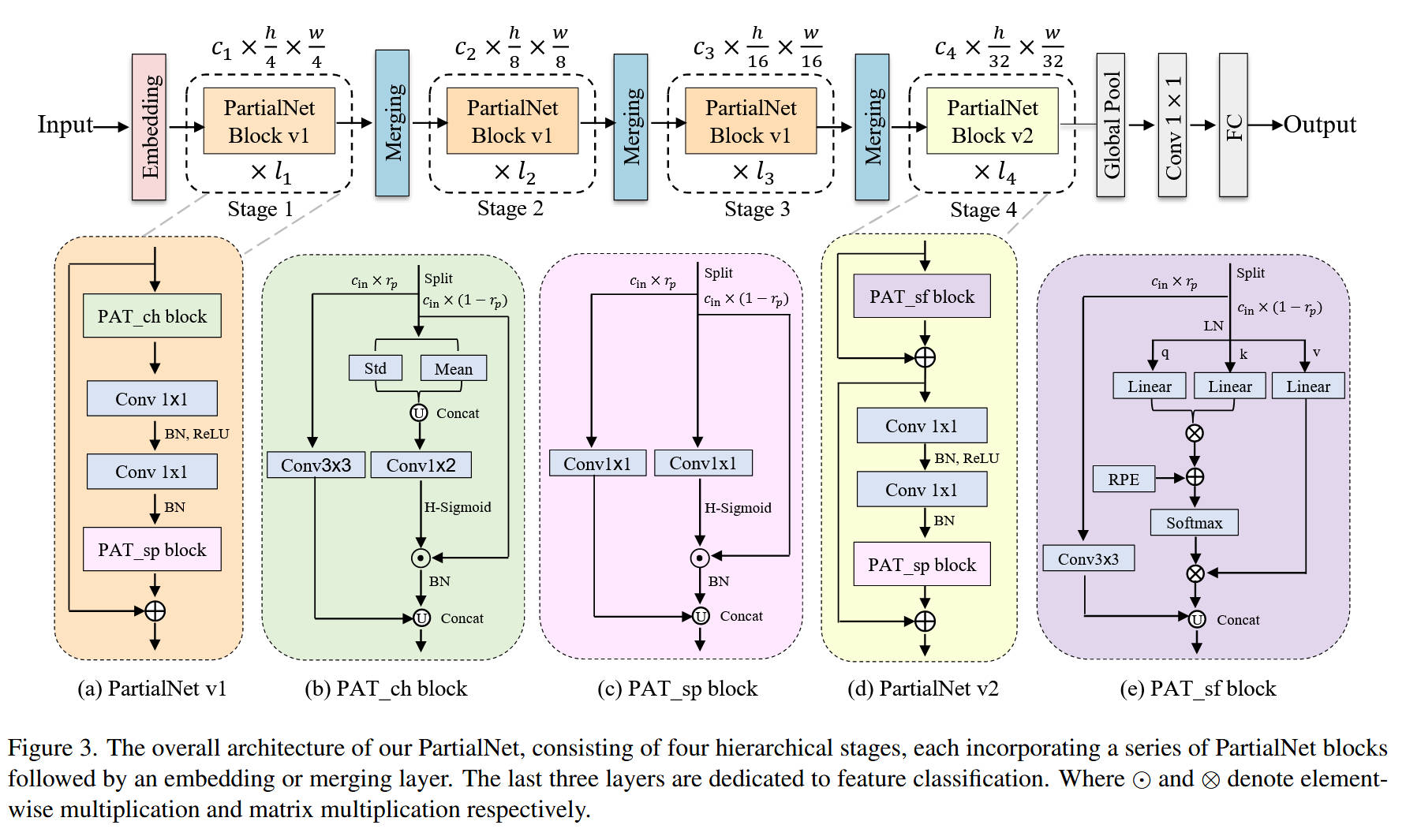
- 宏观结构:PartialNet 采用标准的 4 阶段(Stage)金字塔结构。
- Stem 层 (Embedding):通过 4 × 4 4\times4 4×4 卷积(步长 4)将图像快速下采样。
- Stage 1-3:堆叠 PartialNet Block v1。该 Block 包含两个核心子模块:PAT_ch(负责空间建模)和 PAT_sp(负责通道混合,替代 MLP 中的第一个 FC)。
- Stage 4:堆叠 PartialNet Block v2。考虑到深层特征图较小,引入计算量较大的 PAT_sf(自注意力)来替代 PAT_ch,以增强全局建模能力。
- Merging 层:在 Stage 之间使用 2 × 2 2\times2 2×2 卷积(步长 2)进行下采样。
-
核心创新模块详解:
-
模块 A:PAT_ch Block (Partial Channel-Attention Block)(对应 Figure 3b & 8a)
- 内部结构:用于空间特征提取。
- 数据流:
- Split:输入特征按比例 r p r_p rp 分为两部分。
- 卷积分支: c i n × r p c_{in} \times r_p cin×rp 的通道经过 3 × 3 3\times3 3×3 卷积,提取局部特征。
- 注意力分支:剩余 c i n × ( 1 − r p ) c_{in} \times (1-r_p) cin×(1−rp) 的通道进入 高斯通道注意力。先计算均值(Mean)和标准差(Std),拼接后通过 MLP(Conv1x2 -> ReLU -> Conv1x2)生成权重,再用 H-Sigmoid 激活并加权原特征。这比普通 SE-Net 多利用了方差信息。
- Concat & Fusion:两分支输出拼接,经过 BN 层,最后与残差连接相加。
- 设计目的:替代普通的 3 × 3 3\times3 3×3 卷积或 DWConv,同时引入局部和全局上下文,且计算量更低。
-
模块 B:PAT_sp Block (Partial Spatial-Attention Block)(对应 Figure 3c & 8b)
- 内部结构:用于通道混合(Channel Mixing),类似于 MLP 的扩展。
- 数据流:
- Split:输入特征按比例 r p r_p rp 分割。
- 卷积分支: r p r_p rp 部分经过 1 × 1 1\times1 1×1 卷积。
- 注意力分支:剩余部分经过 空间注意力。通过 1 × 1 1\times1 1×1 卷积压缩为单通道,H-Sigmoid 激活生成空间权重图,再对原特征加权。
- Concat & Fusion:拼接后经过 BN。
- 特殊设计:如图 8d 所示,在推理时,PAT_sp 中的 1 × 1 1\times1 1×1 卷积可以与 MLP 中的 1 × 1 1\times1 1×1 卷积融合(Re-parameterization),进一步减少层数和延迟。
-
模块 C:DPConv (Dynamic Partial Convolution)(对应 Figure 4)
- 内部结构:用于自适应确定 Split Ratio。
- 机制:
- 定义一个可学习的门控向量 g \mathbf{g} g。
- 利用 Kronecker 积生成掩码矩阵 U U U。
- 通过 U U U 对卷积核权重 W W W 进行掩码操作,从而动态决定哪些通道参与卷积,哪些通道“被修剪”或保留。
- 引入资源约束损失函数,平衡精度与计算量。
-
-
理念与机制总结:
- 核心理念:“分而治之,各取所长”。卷积擅长局部提取但计算重,注意力擅长全局建模但计算也重(对全通道而言)。PCM 机制将两者结合,让卷积只处理一部分通道(降低 FLOPs),让注意力处理另一部分通道(补充全局信息且维度较低),从而实现了 1+1 > 2 的效果。
- 并行优于串行:传统的“Conv -> Attention”是串行的,增加了网络深度和延迟。PATConv 采用并行结构,利用 GPU 的并行计算能力,掩盖了部分计算延迟。
-
图解总结:
- Figure 3 清晰地展示了 PartialNet 的层级结构以及三种 PAT 模块的内部细节。特别是 PAT_ch 和 PAT_sp 的并联双通路设计(左侧 Conv,右侧 Attention),直观地体现了 PCM 的核心思想。
- Figure 7 展示了 DPConv 学习到的不同层级的 r p r_p rp 分布。可以看到,网络倾向于在中间层使用较小的 r p r_p rp(更多注意力),而在首尾层使用较大的 r p r_p rp(更多卷积),这符合“首尾层特征提取更重要”的直觉。
5. 即插即用模块的作用
本文提出的模块具有很强的通用性,可作为即插即用组件优化其他模型:
-
PAT_ch 模块
- 适用场景:任何使用 3 × 3 3\times3 3×3 卷积 或 DWConv 进行空间特征提取的场景。
- 具体应用:
- 替换 ResNet/MobileNet 的 Block:直接替换 ResNet 的 BasicBlock 或 MobileNet 的 Inverted Residual Block 中的空间卷积层。能在降低 FLOPs 的同时提升精度(如论文 Table 5 所示,替换 ResNet50 和 MobileNetV2 后 Top-1 分别提升 1.5% 和 2.7%)。
- 检测/分割头:在 YOLO 或 Mask R-CNN 的 Head 部分,使用 PAT_ch 替代普通卷积,增强对多尺度特征的捕获能力。
-
PAT_sp 模块
- 适用场景:特征的 通道混合 (Channel Mixing) 阶段,即 MLP 或 1 × 1 1\times1 1×1 卷积层。
- 具体应用:
- 增强 MLP:在 ViT 或 CNN 的 MLP 层中,用 PAT_sp 替代第一个全连接层(FC1)。它引入了空间注意力,使得 MLP 不再仅仅是像素级的变换,而是具备了空间感知能力。
-
PAT_sf 模块 (Partial Self-Attention)
- 适用场景:深层网络的特征提取,或计算资源受限但需要全局感受野的场景。
- 具体应用:
- ViT 瘦身:在 Vision Transformer 的末端 Stage,用 PAT_sf 替代标准的 Multi-Head Self-Attention (MHSA)。由于只对部分通道计算 Attention,计算复杂度显著降低,适合在移动端部署 ViT。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。
6. 获取即插即用代码关注 【AI即插即用】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)